Follow our official account to discover the beauty of CV technology
This paper shares Tora: Trajectory-oriented Diffusion Transformer for Video Generation, where Alibaba proposes the trajectory-controlled DiT video generation model Tora.

- Paper link: https://arxiv.org/abs/2407.21705
- Project link: https://ali-videoai.github.io/tora_video/

Background
Video generation models have recently made significant progress. For example, OpenAI’s Sora and domestic models like Vidu and Keling utilize the extended characteristics of the Diffusion Transformer to meet various resolution, size, and duration prediction requirements, while also producing videos that better reflect the physical world.
Video generation technology requires creating consistent motion across a series of images, highlighting the importance of motion control. Currently, some excellent methods like DragNUWA and MotionCtrl have achieved trajectory-controlled video generation, but these methods are limited by traditional U-Net denoising models, mostly generating videos of 16 frames in length and fixed low resolution, making it difficult to handle long-distance trajectories.
Moreover, if the trajectories are too irregular or there is excessive deviation, these methods are prone to motion blur, appearance distortion, and unnatural movements like drifting and flickering.
To address these issues, Alibaba Cloud has proposed Tora, a trajectory-controlled video generation model based on the DiT architecture. Tora can generate videos of different resolutions and lengths based on any number of object trajectories, images, and text conditions, producing stable motion videos of up to 204 frames at 720p resolution. Notably, Tora inherits the scaling characteristics of DiT, resulting in smoother motion patterns that align better with the physical world.
Method Introduction
Tora Overall Structure
As shown in the figure below, Tora consists of a Spatial-Temporal Denoising Diffusion Transformer (ST-DiT), a Trajectory Extractor (TE), and a Motion-guidance Fuser (MGF).
The ST-DiT of Tora inherits the design of OpenSora v1.2, compressing the input video into Spacetime visual patches in the spatial and temporal dimensions, followed by noise prediction through alternating spatial transformer blocks and temporal transformer blocks.
To achieve user-friendly trajectory control, TE and MGF encode the user-provided trajectories into multi-level Spacetime motion patches, which are then seamlessly integrated into each DiT block through adaptive normalization layers to ensure the generated video motion aligns with the predefined trajectories.
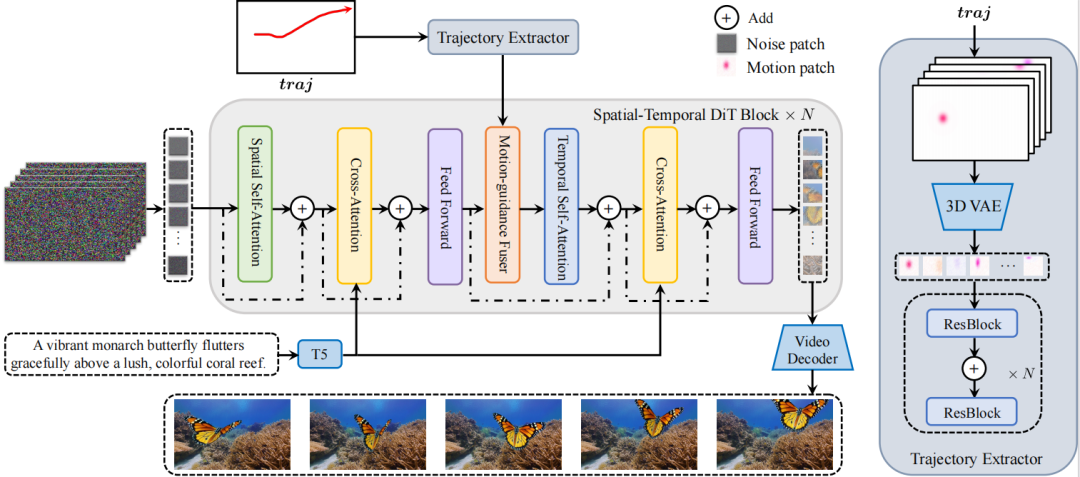
Trajectory Extractor
The technical report of Sora states that visual patches are a highly scalable and efficient representation. To represent high-dimensional video data as visual patches, Sora compresses the original video in both time and space. This is key to the DiT algorithm’s ability to generate longer videos than U-Net methods.
Existing U-Net methods often control motion trajectories by injecting motion vectors between two frames, with no latent embedding coding in the temporal domain, which is not applicable in the DiT architecture.
To pair motion trajectory information with visual patches, Tora’s trajectory extractor employs a 3D motion VAE, embedding trajectory vectors into the same latent space as visual patches, ensuring that motion information is preserved and transmitted between consecutive frames.
To leverage existing 3D VAE weights, trajectory displacements are converted into the RGB domain using flow visualization methods, and Tora further introduces Gaussian filtering to RGB trajectory displacements to mitigate divergence issues. The RGB trajectory displacement maps will serve as input to the 3D motion VAE, generating motion patches.
Tora’s 3D motion VAE references Google’s Magvit-v2 architecture and eliminates the codebook compression design, extracting rich spatiotemporal motion patches through 3D causal convolutions.
As shown in the right side of the figure above, the trajectory extractor processes these motion patches through stacked convolutional blocks, extracting hierarchical motion features to capture more complex and detailed motion patterns.
Motion-guidance Fuser
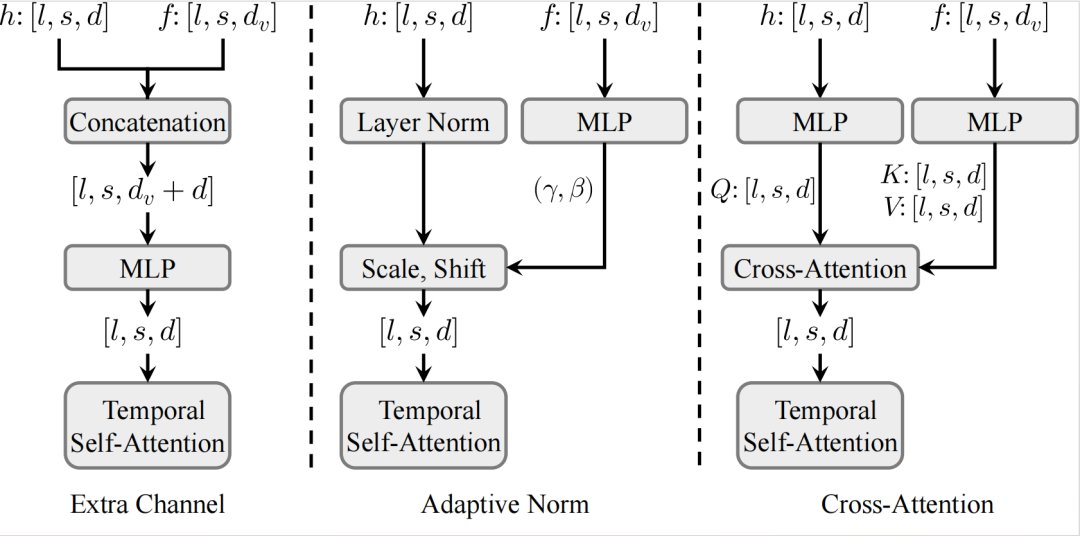
With motion features sharing the feature space with visual patches, the next step is to introduce multi-level motion features into the corresponding DiT blocks, ensuring that the generated motion follows the predefined trajectories without affecting the original visual quality.
Tora references various feature injection structures from transformers, as shown in the figure above. The Motion-guidance Fuser experiments with three architectures: additional channel connections, adaptive normalization, and cross-attention.
Experimental results show that adaptive normalization performs best in terms of visual quality and trajectory adherence, while also being the most computationally efficient. The adaptive normalization layer can dynamically adjust features based on diverse conditions (text & trajectories & images), ensuring temporal consistency in video generation. This is particularly important when injecting motion cues, effectively maintaining continuity and naturalness in the video’s motion.
Training Data Processing and Strategy
To train the Tora model, annotated videos with descriptions and motion trajectories are required. Tora improves upon the data processing pipeline of OpenSora to better capture object trajectories.
By combining motion segmentation results and flow scores, Tora removes instances primarily containing camera movement, thus enhancing the accuracy of tracking foreground object trajectories.
For videos with severe motion, considering the existence of significant optical flow deviations, they are retained with a probability of (1 − score/100). The filtered videos utilize PLLaVA13B to generate video descriptions. Tora’s training videos come from high-quality internet video datasets (such as Panda70M, pixabay, and MixKit) as well as internal company data.
To support any number of visual conditions, Tora randomly selects visual patches during training and removes noise processing on them. For motion condition training, Tora follows a two-stage training strategy from MotionCtrl and DragNUWA.
The first stage extracts dense optical flow from training videos for 2 epochs, providing rich information to accelerate the motion learning process.
The second stage randomly samples 1 to N target object trajectory samples based on motion segmentation results and flow scores, allowing flexible use of any trajectory for motion control.
Experiments
Implementation Details and Test Data
Tora is trained based on OpenSora v1.2 weights, using videos with resolutions ranging from 144p to 720p and frame counts from 51 to 204. To balance the training FLOP and required memory across different resolutions and frame counts, the batch size is adjusted from 1 to 25.
The training process is divided into two stages, first using dense optical flow for 2 epochs of training, followed by 1 epoch of fine-tuning with sparse optical flow.
During inference, 185 long video clips containing diverse motion trajectories and scenes were selected as a new benchmark for evaluating motion controllability.
Comparison Experimental Results
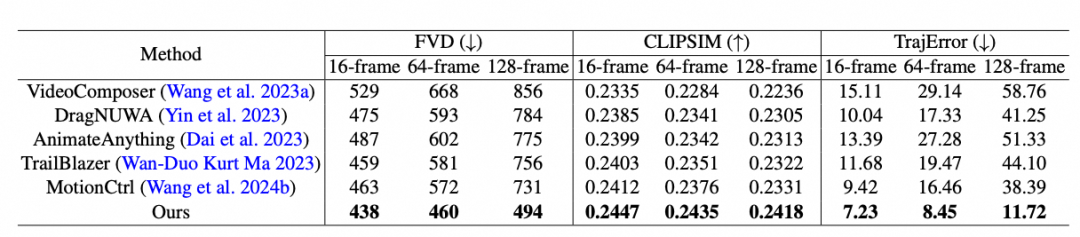
The author team compared Tora with current popular motion-guided video generation methods, evaluating it under 16, 64, and 128 frame settings, with all video resolutions set to 512×512 for fair comparison. The test trajectories are segmented according to the number of video frames.
Most U-Net based methods adopt a sequential inference approach, where the last frame generated from the previous batch serves as the condition for the current batch. In the commonly used 16-frame setting for U-Net, MotionCtrl and DragNUWA align well with the provided trajectories but still fall short of Tora. As the number of frames increases, U-Net based methods suffer from severe error accumulation, leading to deformation, blurriness, or object disappearance in subsequent sequences.
In contrast, Tora, due to its integration of the scaling capability of transformers, demonstrates high robustness against changes in frame counts, producing smoother motion that adheres better to the laws of the physical world. In the 128-frame test, Tora’s trajectory accuracy surpasses other methods by 3 to 5 times.
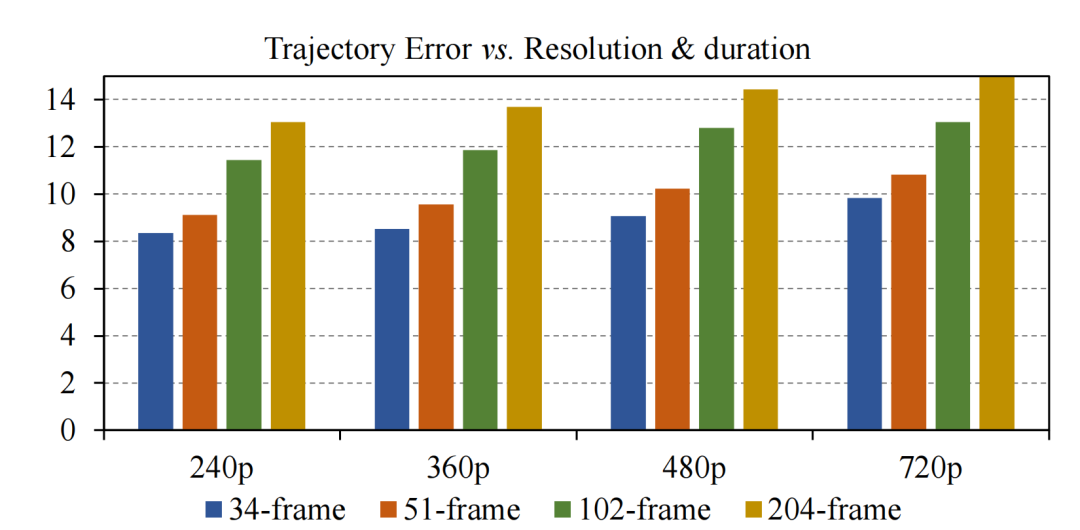
The author team provides an analysis of trajectory errors for Tora at different resolutions and durations, showing that Tora only exhibits gradually increasing errors as duration increases, which aligns with the trend of DiT models where quality declines as videos are extended, indicating that Tora maintains effective trajectory control over longer periods.
More Experimental Results
The video below shows the effect of a single trajectory corresponding to multiple text instances in a 16:9 size.
The video below shows the effect of a single trajectory corresponding to multiple text instances in a 9:16 size and a single image corresponding to multiple trajectories in a 1:1 size.
For the latest AI progress reports, please contact: [email protected]
END
Welcome to join the ‘Video Generation ‘ group chat👇 Please note: Generation
