
Source | Zhihu
Author | DengBoCong
Link | https://www.zhihu.com/question/439243827/answer/1685085848
Editor | Machine Learning Algorithms and Natural Language Processing WeChat Account
This article is for academic sharing. If there is an infringement, please contact us to delete it.
I wrote a lot specifically for this question (I also learned and thought a lot myself), hoping to help you. If you like it, please support us with a like, and let’s learn and improve together!
LSTM and Transformer are both mainstream feature extraction structures used in many fields, each with its strengths and weaknesses. Therefore, the scope of this question is quite broad. I personally believe that it is meaningful to discuss based on specific research fields. We need to discuss whether a feature extractor is suitable for the characteristics of the problem domain, as currently many model improvements are actually aimed at making them better match the characteristics of domain problems.
I personally focus on the field of NLP dialogue systems, so I will share my practical experiences with LSTM (RNN structure) and Transformer based on the dialogue system field for your reference!
Why Has LSTM (RNN) Been So Popular in NLP?
The RNN structure has gained popularity in the NLP field for a reason. The main reason is that the RNN structure is inherently suitable for solving NLP problems. The input in NLP is often an indefinite-length linear sequence of sentences, and the RNN itself is a network structure that can accept indefinite-length inputs and transmit information linearly from front to back. Moreover, to address the gradient explosion and long-range information disappearance problems of standard RNNs, LSTM was born, introducing three gates that are very effective in capturing long-distance features. It is precisely because RNNs are particularly suitable for the linear sequence application scenarios in NLP that they have become so popular in the NLP community.
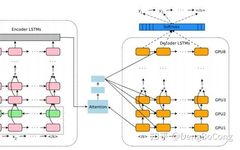
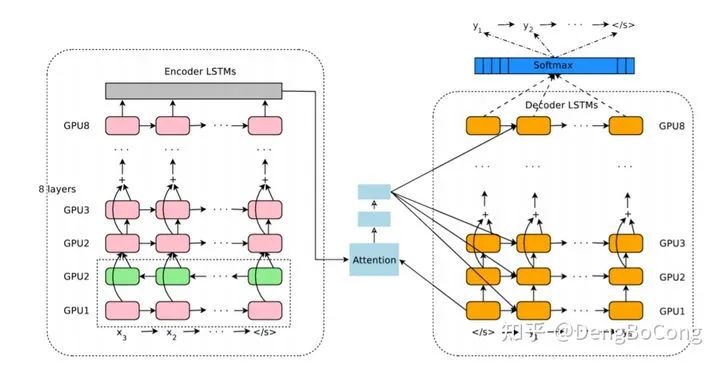
Especially with the support of various Attention mechanisms, RNNs frequently appear in various SOTA models in NLP. By stacking networks to increase depth and introducing the Encoder-Decoder framework, these technological advancements have greatly expanded the capabilities and application effects of RNNs. A typical example is Google NMT, structured as follows:
-
Paper Link
The NMT structure includes bidirectional RNNs, multi-layer unidirectional RNNs, attention mechanisms, and Encoder-Decoder structures. It is this structure that makes NMT perform remarkably well. Here is a paper discussing the hyperparameters in an Ablation experiment, which I previously researched and summarized. You can check it out to understand the sensitivity of the RNN structure to hyperparameters (the original link is in the article).
https://zhuanlan.zhihu.com/p/328801239
In summary, the RNN structure performs very well for linear sequences.
Main Pain Points of LSTM (RNN) and Solutions?
Slow! I previously wrote a seq2seq dialogue model using LSTM and used it in LAS, but the large number of parameters made the training speed painfully slow, what a complaint! You can refer to my GitHub for related models:
https://github.com/DengBoCong/nlp-paper
The advantages of RNNs in NLP are obvious, but there is also a significant drawback: the sequential dependency structure of RNNs is quite unfriendly for large-scale parallel computing. In other words, RNNs are difficult to achieve efficient parallel computing capabilities. The rise of deep learning is largely due to the support of GPU hardware environments, while RNNs, due to their inherent structural issues (the hidden state at time T relies on the hidden state at time T-1), cannot fully utilize the parallel computing capabilities of hardware, which is a very significant problem!
In contrast, Transformers do not have this sequential dependency issue, so parallel computing capabilities are not a problem for the two. Operations at each time step can be computed in parallel.
Of course, many experts are researching optimizations for RNN structures, trying to modify RNNs to enable parallel computing capabilities, mainly in the following two ways:
Parallel Computing Between Hidden Units
A representative method is the SRU method proposed in the paper “Simple Recurrent Units for Highly Parallelizable Recurrence.” The essential improvement is that in a multi-layer RNN structure, the dependency between hidden layers is changed from fully connected to Hadamard product, allowing the hidden unit at time T to depend only on the corresponding unit at time T-1. This allows for parallel computation between hidden units while still collecting information sequentially. Thus, its parallelism occurs between hidden units, not between different time steps.
Using the optimization method for RNNs in Google NMT, simply put, in a multi-layer RNN structure, the LSTMs of different layers in the Encoder and Decoder run on different GPUs because the upper layer LSTM does not have to wait for the next layer’s neural network to finish computing before starting its work. Of course, the upper limit of parallelism in this method is limited, and the degree of parallelism depends on the number of hidden neurons, which is generally not very large, making it increasingly difficult to increase parallelism.
Cutting Time Step Dependencies for Parallel Computing
A representative method is the Sliced RNN mentioned in the paper “Sliced Recurrent Neural Networks.” As the name suggests, it achieves parallel computing by slicing time steps. To enable parallel computation between different time step inputs, Sliced RNN partially breaks the connections between hidden layers, but not completely, as that would essentially lose the ability to capture combined features. Therefore, it adopts a strategy of partial disconnection, for example, breaking every two time steps. For features that are slightly further apart, deeper layers are used to establish connections between long-distance features. The structure of Sliced RNN compared to ordinary RNN is shown below:
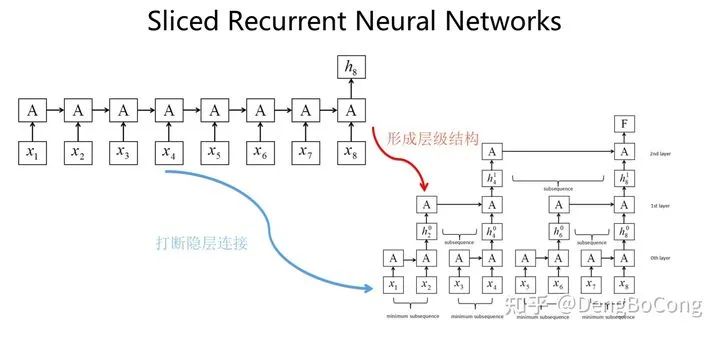
It really looks a bit like CNN; it seems that this modification is not really RNN anymore. The paper mentions that this RNN structure, similar to CNN, is 5-15 times faster than the GRU model, but still about 3 times slower than CNN models. I personally believe that, to some extent, this structure cannot be called a true RNN, as the fundamental feature of RNN is the connection between linear sequences. Sliced RNN merely attempts to maintain an RNN-like appearance, which undoubtedly slows down speed. Therefore, this is a dilemma; rather than doing this, it would be better to switch to another model directly.
Why is Transformer Powerful?
I won’t elaborate on the details of the Transformer model structure here. In the deep learning community, even if you haven’t used Transformer, you’ve probably heard of it so often that your ears have grown calluses. Its paper “Attention Is All You Need” can fulfill all your fantasies. The power of Transformer lies in its use of Self-attention and Multi-head Self-attention for semantic extraction (regarding the long-distance dependency feature issue in NLP sentences, Self-attention can inherently solve this problem, as when integrating information, the current word relates to any word in the sentence, thus accomplishing this task in one go). With the combination of sinusoidal position encoding to retain the relative positional information between input sentence words, this combination is incredibly powerful. Unlike RNNs which need to transmit through hidden node sequences, and unlike CNNs which need to increase network depth to capture long-distance features, the Transformer’s approach is significantly simpler and more intuitive.
Which to Choose: Transformer or RNN?
I cannot answer this question, just as I said at the beginning, it depends on specific task domains. Here, I will compare a few key points to help you make a better choice. The following data and conclusions are sourced from the paper “Why Self-Attention? A Targeted Evaluation of Neural Machine Translation Architectures,” which also includes a comparison with CNN.
Semantic Feature Extraction Ability
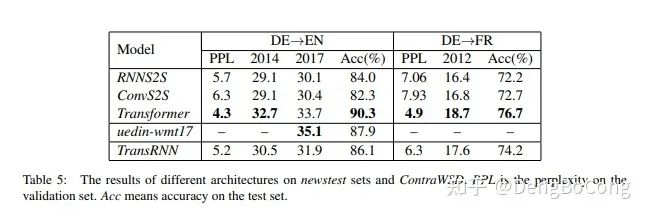
From the experiments, we can see that Transformer significantly outperforms RNN and CNN in this aspect (in tasks involving semantic capabilities such as WSD, Transformer exceeds RNN and CNN by about 4-8 absolute percentage points), while RNN and CNN perform similarly.
Long-Distance Feature Capture Ability
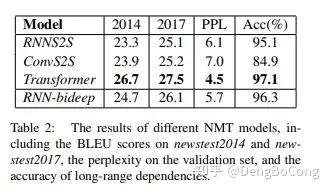
The CNN feature extractor is significantly weaker in this regard compared to RNN and Transformer. Transformer slightly outperforms RNN (especially when the subject-verb distance is less than 13), but at greater distances (subject-verb distance greater than 13), RNN slightly outperforms Transformer. Therefore, overall, it can be said that Transformer and RNN have similar capabilities in this regard, while CNN is significantly weaker than the two.
Comprehensive Feature Extraction Ability for Tasks
Here, I will use experimental data from the GPT paper:
-
Paper Link
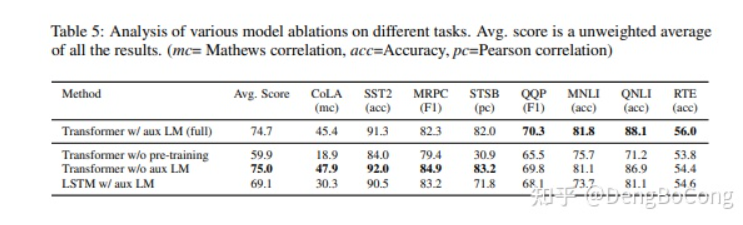
From the perspective of comprehensive feature extraction ability, Transformer significantly outperforms RNN and CNN, while RNN and CNN perform similarly. If one has to compare between the two, CNN usually performs slightly better than RNN.
Parallel Computing Ability and Running Efficiency
The following data comes from a paper that conducted experiments on machine translation, “Tensor2Tensor for Neural Machine Translation.”
-
Paper Link

The square term of self-attention is the length of the sentence, as each word needs to relate to any other word to compute attention, thus containing a square term of n, while the square term for RNNs and CNNs is the embedding size. Current commonly used embedding sizes range from 128 to 512, so in most tasks, the computational efficiency of self-attention is actually higher than that of RNNs and CNNs.
Conclusion
Through the above comparisons, don’t you feel that Transformer is indeed a great thing? In fact, it has been proven that Transformer is indeed a very good choice in most scenarios. The emergence of Transformer has opened up the territory originally occupied by RNNs. We cannot yet say that LSTM (RNN) has been replaced, as it has its own advantages, but we must admit that the trend is now leaning towards the ecosystem of Transformers. To give a personal example, in the dialogue system field, comparing Baidu’s SMN and DAM retrieval-based dialogue models, their structures are as follows:
-
SMN: Paper Reading Notes: SMN Retrieval-Based Multi-Turn Dialogue System

-
DAM: Paper Reading Notes: DAM Retrieval-Based Multi-Turn Dialogue System Using Transformer’s Encoder
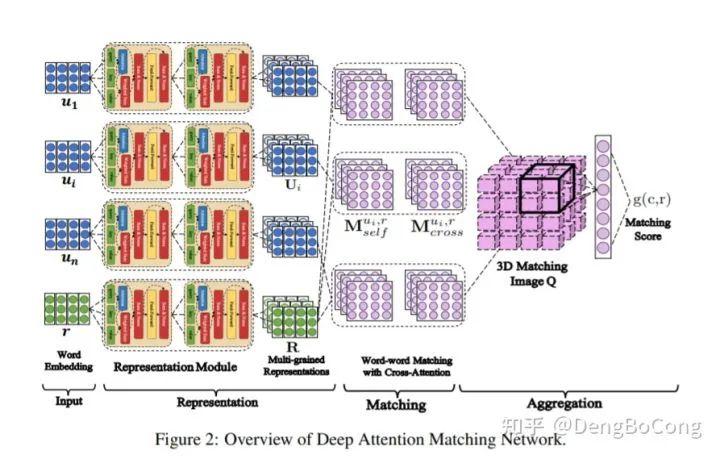
DAM was launched after SMN, and we will find that their structures look very similar at first glance. However, in multi-granularity text feature extraction, SMN uses GRU, while DAM uses the Transformer’s Encoder. Experimental results also prove that DAM is superior, isn’t this a trend among leading companies?
Download 1: Four Essentials
Reply “Four Essentials” in the backend of the Machine Learning Algorithms and Natural Language Processing WeChat account to obtain learning resources for TensorFlow, Pytorch, machine learning, and deep learning!
Download 2: Repository Address Sharing
Reply “Code” in the backend of the Machine Learning Algorithms and Natural Language Processing WeChat account to obtain 195 NAACL papers + 295 ACL 2019 papers with open-source code. The open-source address is as follows: https://github.com/yizhen20133868/NLP-Conferences-Code
Exciting news! The Machine Learning Algorithms and Natural Language Processing group has officially been established! There are plenty of resources in the group, and everyone is welcome to join and learn!
Extra benefits! Resources on deep learning and neural networks, official Chinese tutorials for Pytorch, data analysis using Python, machine learning study notes, official Chinese documentation for pandas, effective java (Chinese version), and 20 other welfare resources
How to obtain: After entering the group, open the group announcement to get the download link. Please modify the note when adding as [School/Company + Name + Direction].
For example — HIT + Zhang San + Dialogue System.
Please avoid adding if you are a micro-business. Thank you!
Recommended Reading:
Implementation of NCE-Loss in TensorFlow and word2vec
Overview of Multimodal Deep Learning: Network Structure Design and Modality Fusion Methods Summary
Awesome Adversarial Machine Learning Resource List