
Introduction
The main content of this article is poetry generation based on LSTM, which includes an introduction to the dataset, experimental code, and results. The experiment uses a Long Short-Term Memory (LSTM) deep learning model, trained for 10 epochs. During the testing process, poetry generation results are produced at each epoch, and as the epochs progress, the quality of the generated poetry improves. The poetry generation in this article includes random poetry generation and acrostic poetry generation.
1. Dataset Introduction
The dataset used in this experiment is stored in the file poems.txt, with each line containing a poem, separated by a “:”. The length of each poem varies.
The screenshot below shows the end of the file; from the line count, we can see that the file contains 43,030 poems, which is quite a large dataset.

In this experiment, not all poems in the dataset will be used; poems that are too long will be excluded in the code.
2. Experimental Code
1. Random Poetry Generation
The code for generating random poetry is as follows.
# Declaration: This code is not self-written, the source is provided at the end of the article
import math
import re
import numpy as np
import tensorflow as tf
from collections import Counter
DATA_PATH = 'poems.txt' # Dataset path
MAX_LEN = 64 # Set the maximum length of a single line of poetry
DISALLOWED_WORDS = ['(', ')', '(', ')', '__', '《', '》', '【', '】', '[', ']'] # Forbidden characters, poems containing these symbols will be ignored
BATCH_SIZE = 128
poetry = [] # Each poem corresponds to an element in the list
with open(DATA_PATH, 'r', encoding='utf-8') as f: # Read file data line by line, each line is a poem lines = f.readlines()
for line in lines: fields = re.split(r":|:", line) # Use regular expression to split title and content if len(fields) != 2: # If the split result is not two items, skip this abnormal data continue content = fields[1] # Extract the poetry content if len(content) > MAX_LEN - 2: # Exclude poems that are too long continue if any(word in content for word in DISALLOWED_WORDS): # Exclude poems containing forbidden characters continue poetry.append(content.replace('\n', '')) # Add the poetry to the list, one poem per line
MIN_WORD_FREQUENCY = 8 # Minimum word frequency
counter = Counter() # Count word frequency
for line in poetry: counter.update(line)
tokens = [token for token, count in counter.items() if count >= MIN_WORD_FREQUENCY] # Filter out low-frequency words
tokens = ["[PAD]", "[NONE]", "[START]", "[END]"] + tokens # Add special token marks: padding character mark, unknown word mark, start mark, end mark
word_idx = {} # Mapping from word to index
idx_word = {} # Mapping from index to word
for idx, word in enumerate(tokens): word_idx[word] = idx idx_word[idx] = word
class Tokenizer: """Tokenizer""" def __init__(self, tokens): self.dict_size = len(tokens) # Vocabulary size # Generate mapping relationship self.token_id = {} # Mapping from word to index self.id_token = {} # Mapping from index to word for idx, word in enumerate(tokens): self.token_id[word] = idx self.id_token[idx] = word
# The index of each special mark, convenient for use in other places self.start_id = self.token_id["[START]"] self.end_id = self.token_id["[END]"] self.none_id = self.token_id["[NONE]"] self.pad_id = self.token_id["[PAD]"]
def id_to_token(self, token_id): """Mapping from index to word""" return self.id_token.get(token_id)
def token_to_id(self, token): """Mapping from word to index""" return self.token_id.get(token, self.none_id) # If not in index, return [NONE]
def encode(self, tokens): """Token list: [START] index + index list + [END] index""" token_ids = [self.start_id, ] # Starting mark for token in tokens: token_ids.append(self.token_to_id(token)) # Convert word to index token_ids.append(self.end_id) # Ending mark return token_ids
def decode(self, token_ids): """Convert list of indices to list of words, removing start and end marks""" flag_tokens = {"[START]", "[END]"} tokens = [] for idx in token_ids: token = self.id_to_token(idx) if token not in flag_tokens: tokens.append(token) # Skip start and end marks return tokens
tokenizer = Tokenizer(tokens)
# Build dataset
class PoetryDataSet: """Ancient poetry dataset generator""" def __init__(self, data, tokenizer, batch_size): self.data = data self.total_size = len(self.data) self.tokenizer = tokenizer # Tokenizer for word to index self.batch_size = batch_size # Batch size self.steps = int(math.floor(len(self.data) / self.batch_size)) # Number of steps per epoch
def pad_line(self, line, length, padding=None): """Align single line data""" if padding is None: padding = self.tokenizer.pad_id padding_length = length - len(line) if padding_length > 0: return line + [padding] * padding_length else: return line[:length]
def __len__(self): return self.steps
def __iter__(self): np.random.shuffle(self.data) # Shuffle the data # Iterate through one epoch, one batch at a time for start in range(0, self.total_size, self.batch_size): end = min(start + self.batch_size, self.total_size) data = self.data[start:end] max_length = max(map(len, data)) # Map the provided function to the specified sequence batch_data = [] for str_line in data: encode_line = self.tokenizer.encode(str_line) # Encode each line of poetry and pad pad_encode_line = self.pad_line(encode_line, max_length + 2) # Add 2 because tokenizer.encode adds START and END batch_data.append(pad_encode_line)
batch_data = np.array(batch_data) yield batch_data[:, :-1], batch_data[:, 1:] # yield features and labels
def generator(self): while True: yield from self.__iter__()
dataset = PoetryDataSet(poetry, tokenizer, BATCH_SIZE) # Initialize PoetryDataSet
# Build model
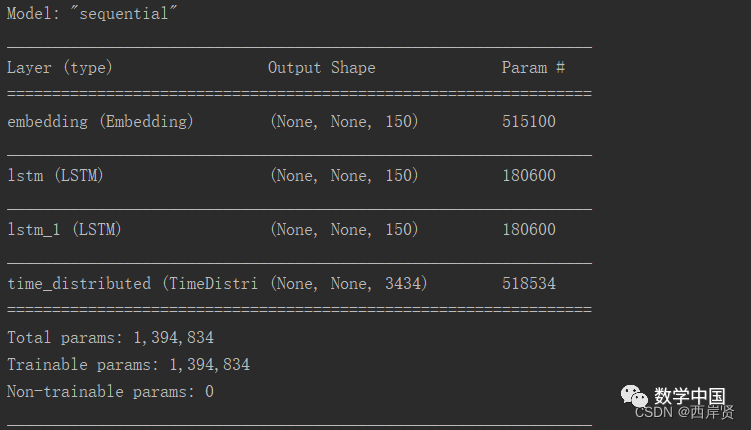
model = tf.keras.Sequential([ # Word embedding layer tf.keras.layers.Embedding(input_dim=tokenizer.dict_size, output_dim=150), tf.keras.layers.LSTM(150, dropout=0.5, return_sequences=True), # First LSTM layer tf.keras.layers.LSTM(150, dropout=0.5, return_sequences=True), # Second LSTM layer # Use TimeDistributed to apply Dense operation to each time step's output, i.e., softmax activation tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(tokenizer.dict_size, activation='softmax')), ])
model.summary()
model.compile( optimizer=tf.keras.optimizers.Adam(), # Use Adam optimizer loss=tf.keras.losses.sparse_categorical_crossentropy # Sparse categorical cross-entropy )
model.fit_generator(dataset.generator(), steps_per_epoch=dataset.steps, epochs=10)
# Prediction
token_ids = [tokenizer.token_to_id(word) for word in ["月", "光", "静", "谧"]] # Convert words to indices
result = model.predict([token_ids, ]) # Make prediction
print(result)
print(result.shape)
def predict(model, token_ids): """Select a word from the top 100 probabilities (in a probabilistic manner) and return the index of a word, excluding [PAD][NONE][START]""" # Predict the probability distribution of each word # 0 means predict the first sample of the input # -1 means only predict the latest word # 3: means don't include the first few markers _probas = model.predict([token_ids, ])[0, -1, 3:] # Sort by probability in descending order, take the top 100 p_args = _probas.argsort()[-100:][::-1] # Get the indices p = _probas[p_args] # Find the specific probability values based on the indices p = p / sum(p) # Normalize operation target_index = np.random.choice(len(p), p=p) # Sample one based on probability # Since we removed the first few markers during prediction, we need to add 3 to the index to get the actual index in the tokenizer dictionary return p_args[target_index] + 3
token_ids = tokenizer.encode("清风明月")[:-1]
while len(token_ids) < 13: target = predict(model, token_ids) # Predict the word index token_ids.append(target) # Save the result if target == tokenizer.end_id: break
print("".join(tokenizer.decode(token_ids)))
def generate_random_poem(tokenizer, model, text=""): """Generate a random poem tokenizer: Tokenizer model: Ancient poetry model text: Initial string of the poem, defaults to empty Returns a string of an ancient poem """ token_ids = tokenizer.encode(text)[:-1] # Convert the initial string to token_ids and remove the end mark [END] while len(token_ids) < MAX_LEN: target = predict(model, token_ids) # Predict the word index token_ids.append(target) # Append the result if target == tokenizer.end_id: break return "".join(tokenizer.decode(token_ids))
# Save model and load
class ShowSaveCallback(tf.keras.callbacks.Callback): def __init__(self): super().__init__() self.loss = float("inf")
def on_epoch_end(self, epoch, logs=None): if logs['loss'] <= self.loss: # Keep the model with the lowest loss self.loss = logs['loss'] model.save("./rnn_model.h5") print() # Print the training results for i in range(5): print(generate_random_poem(tokenizer, model)) # Generate five random poems
# Start training
model.fit( dataset.generator(), steps_per_epoch=dataset.steps, epochs=10, callbacks=[ShowSaveCallback()] )
model = tf.keras.models.load_model("./rnn_model.h5") # Save training data
2. Acrostic Poetry Generation
The code for generating acrostic poetry is as follows.
# Declaration: This code is not self-written, the source is provided at the end of the article
import math
import re
import numpy as np
import tensorflow as tf
from collections import Counter
DATA_PATH = 'poems.txt' # Dataset path
MAX_LEN = 64 # Set the maximum length of a single line of poetry
DISALLOWED_WORDS = ['(', ')', '(', ')', '__', '《', '》', '【', '】', '[', ']'] # Forbidden characters, poems containing these symbols will be ignored
BATCH_SIZE = 128
poetry = [] # Each poem corresponds to an element in the list
with open(DATA_PATH, 'r', encoding='utf-8') as f: # Read file data line by line, each line is a poem lines = f.readlines()
for line in lines: fields = re.split(r":|:", line) # Use regular expression to split title and content if len(fields) != 2: # If the split result is not two items, skip this abnormal data continue content = fields[1] # Extract the poetry content if len(content) > MAX_LEN - 2: # Exclude poems that are too long continue if any(word in content for word in DISALLOWED_WORDS): # Exclude poems containing forbidden characters continue poetry.append(content.replace('\n', '')) # Add the poetry to the list, one poem per line
MIN_WORD_FREQUENCY = 8 # Minimum word frequency
counter = Counter() # Count word frequency
for line in poetry: counter.update(line)
tokens = [token for token, count in counter.items() if count >= MIN_WORD_FREQUENCY] # Filter out low-frequency words
tokens = ["[PAD]", "[NONE]", "[START]", "[END]"] + tokens # Add special token marks: padding character mark, unknown word mark, start mark, end mark
word_idx = {} # Mapping from word to index
idx_word = {} # Mapping from index to word
for idx, word in enumerate(tokens): word_idx[word] = idx idx_word[idx] = word
class Tokenizer: """Tokenizer""" def __init__(self, tokens): self.dict_size = len(tokens) # Vocabulary size # Generate mapping relationship self.token_id = {} # Mapping from word to index self.id_token = {} # Mapping from index to word for idx, word in enumerate(tokens): self.token_id[word] = idx self.id_token[idx] = word
# The index of each special mark, convenient for use in other places self.start_id = self.token_id["[START]"] self.end_id = self.token_id["[END]"] self.none_id = self.token_id["[NONE]"] self.pad_id = self.token_id["[PAD]"]
def id_to_token(self, token_id): """Mapping from index to word""" return self.id_token.get(token_id)
def token_to_id(self, token): """Mapping from word to index""" return self.token_id.get(token, self.none_id) # If not in index, return [NONE]
def encode(self, tokens): """Token list: [START] index + index list + [END] index""" token_ids = [self.start_id, ] # Starting mark for token in tokens: token_ids.append(self.token_to_id(token)) # Convert word to index token_ids.append(self.end_id) # Ending mark return token_ids
def decode(self, token_ids): """Convert list of indices to list of words, removing start and end marks""" flag_tokens = {"[START]", "[END]"} tokens = [] for idx in token_ids: token = self.id_to_token(idx) if token not in flag_tokens: tokens.append(token) # Skip start and end marks return tokens
tokenizer = Tokenizer(tokens)
# Build dataset
class PoetryDataSet: """Ancient poetry dataset generator""" def __init__(self, data, tokenizer, batch_size): self.data = data self.total_size = len(self.data) self.tokenizer = tokenizer # Tokenizer for word to index self.batch_size = batch_size # Batch size self.steps = int(math.floor(len(self.data) / self.batch_size)) # Number of steps per epoch
def pad_line(self, line, length, padding=None): """Align single line data""" if padding is None: padding = self.tokenizer.pad_id padding_length = length - len(line) if padding_length > 0: return line + [padding] * padding_length else: return line[:length]
def __len__(self): return self.steps
def __iter__(self): np.random.shuffle(self.data) # Shuffle the data # Iterate through one epoch, one batch at a time for start in range(0, self.total_size, self.batch_size): end = min(start + self.batch_size, self.total_size) data = self.data[start:end] max_length = max(map(len, data)) # Map the provided function to the specified sequence batch_data = [] for str_line in data: encode_line = self.tokenizer.encode(str_line) # Encode each line of poetry and pad pad_encode_line = self.pad_line(encode_line, max_length + 2) # Add 2 because tokenizer.encode adds START and END batch_data.append(pad_encode_line)
batch_data = np.array(batch_data) yield batch_data[:, :-1], batch_data[:, 1:] # yield features and labels
def generator(self): while True: yield from self.__iter__()
dataset = PoetryDataSet(poetry, tokenizer, BATCH_SIZE) # Initialize PoetryDataSet
# Build model
model = tf.keras.Sequential([ # Word embedding layer tf.keras.layers.Embedding(input_dim=tokenizer.dict_size, output_dim=150), tf.keras.layers.LSTM(150, dropout=0.5, return_sequences=True), # First LSTM layer tf.keras.layers.LSTM(150, dropout=0.5, return_sequences=True), # Second LSTM layer # Use TimeDistributed to apply Dense operation to each time step's output, i.e., softmax activation tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(tokenizer.dict_size, activation='softmax')), ])
model.summary()
model.compile( optimizer=tf.keras.optimizers.Adam(), # Use Adam optimizer loss=tf.keras.losses.sparse_categorical_crossentropy # Sparse categorical cross-entropy )
model.fit_generator(dataset.generator(), steps_per_epoch=dataset.steps, epochs=10)
# Prediction
token_ids = [tokenizer.token_to_id(word) for word in ["月", "光", "静", "谧"]] # Convert words to indices
result = model.predict([token_ids, ]) # Make prediction
print(result)
print(result.shape)
def predict(model, token_ids): """Select a word from the top 100 probabilities (in a probabilistic manner) and return the index of a word, excluding [PAD][NONE][START]""" # Predict the probability distribution of each word # 0 means predict the first sample of the input # -1 means only predict the latest word # 3: means don't include the first few markers _probas = model.predict([token_ids, ])[0, -1, 3:] # Sort by probability in descending order, take the top 100 p_args = _probas.argsort()[-100:][::-1] # Get the indices p = _probas[p_args] # Find the specific probability values based on the indices p = p / sum(p) # Normalize operation target_index = np.random.choice(len(p), p=p) # Sample one based on probability # Since we removed the first few markers during prediction, we need to add 3 to the index to get the actual index in the tokenizer dictionary return p_args[target_index] + 3
token_ids = tokenizer.encode("清风明月")[:-1]
while len(token_ids) < 13: target = predict(model, token_ids) # Predict the word index token_ids.append(target) # Save the result if target == tokenizer.end_id: break
print("".join(tokenizer.decode(token_ids)))
def generate_acrostic_poem(tokenizer, model, heads): """ Generate an acrostic poem tokenizer: Tokenizer model: Ancient poetry model heads: The heads of the acrostic poem Returns a string of an ancient poem """ token_ids = [tokenizer.start_id, ] # token_ids, only containing [START] index punctuation_ids = {tokenizer.token_to_id(","), tokenizer.token_to_id("。"} # Comma and period mark indices content = []
for head in heads: content.append(head) token_ids.append(tokenizer.token_to_id(head)) # Convert head to index and add to the list for prediction target = -1 while target not in punctuation_ids: # When encountering a comma or period, it indicates the end of the sentence, start the next sentence target = predict(model, token_ids) # Predict the word index # Since END may be predicted, add a check if target > 3: token_ids.append(target) # Save the result to token_ids, which will be used for the next prediction content.append(tokenizer.id_to_token(target))
return "".join(content)
# Save model and load
class ShowSaveCallback(tf.keras.callbacks.Callback): def __init__(self): super().__init__() self.loss = float("inf")
def on_epoch_end(self, epoch, logs=None): if logs['loss'] <= self.loss: # Keep the model with the lowest loss self.loss = logs['loss'] model.save("./rnn_model.h5") print() # Print the training results print(generate_acrostic_poem(tokenizer, model, '机器学习')) # Generate acrostic poem with 'Machine Learning' as the head print(generate_acrostic_poem(tokenizer, model, '神经网络')) # Generate acrostic poem with 'Neural Network' as the head
# Start training
model.fit( dataset.generator(), steps_per_epoch=dataset.steps, epochs=10, callbacks=[ShowSaveCallback()] )
model = tf.keras.models.load_model("./rnn_model.h5") # Save training data
3. Experimental Results
The results after running the code are shown below.
The training parameters are shown in the image below.
1. Random Poetry Generation Results
The random poetry generated in the first epoch is shown in the image below.

The random poetry generated in the second epoch is shown in the image below.

The random poetry generated in the third epoch is shown in the image below.

The random poetry generated in the fourth epoch is shown in the image below.

The random poetry generated in the fifth epoch is shown in the image below.

The random poetry generated in the sixth epoch is shown in the image below.

The random poetry generated in the seventh epoch is shown in the image below.

The random poetry generated in the eighth epoch is shown in the image below.

The random poetry generated in the ninth epoch is shown in the image below.

The random poetry generated in the tenth epoch is shown in the image below.

From the results of the generated random poetry, it can be seen that the generated random poetry includes five-character and seven-character poems, with four, six, and eight lines, which are consistent with the characteristics of poetry. The downside is that some of the generated poems are not very good, and the tonal correspondence and depiction of the mood in the poems are not very mature.
2. Acrostic Poetry Generation Results
Acrostic poems were generated starting with “Machine Learning” and “Neural Network”.
The acrostic poem generated in the first epoch is shown in the image below.

The acrostic poem generated in the second epoch is shown in the image below.

The acrostic poem generated in the third epoch is shown in the image below.

The acrostic poem generated in the fourth epoch is shown in the image below.

The acrostic poem generated in the fifth epoch is shown in the image below.

The acrostic poem generated in the sixth epoch is shown in the image below.

The acrostic poem generated in the seventh epoch is shown in the image below.

The acrostic poem generated in the eighth epoch is shown in the image below.

The acrostic poem generated in the ninth epoch is shown in the image below.

The acrostic poem generated in the tenth epoch is shown in the image below.

From the results of the generated acrostic poems, it can be seen that the generated acrostic poems include five-character and seven-character poems, with only four lines, as the acrostic words only have four characters, which is consistent with the characteristics of acrostic poems.
This article is sourced from the internet. If there is any infringement, please delete it immediately. Specific link https://blog.csdn.net/weixin_42570192/article/details/125409382