
Reprinted from AI Technology Review

Human intelligence, encompassing consciousness, cognition, decision-making, and more, seems to have captivated philosophers since the dawn of recorded history. Similarly, since the birth of AI, scientists have been pondering: How can AI achieve human-like intelligence?
Recently, Professor Sepp Hochreiter, one of the founders of LSTM and the founder of the Austrian Institute of Artificial Intelligence Research (IARAI), who received the IEEE CIS Neural Networks Pioneer Award in 2021, shared his views on the current level of AI intelligence in the ACM Communications.
Professor Hochreiter pointed out that the current development of AI is aimed at achieving Broad AI. He emphasized that the combination of traditional logic-based symbolic AI and the existing data-driven neural AI into a bilateral AI is the most promising way to realize Broad AI.
1
Limitations of Existing Neural Networks
Deep neural networks are the mainstream implementation of AI today. Although they can achieve astonishing performance, they still have many shortcomings when compared to human intelligence. Professor Hochreiter cited criticisms of neural networks by cognitive scientist Gary Marcus from New York University, which include: (1) Neural networks are extremely data-hungry; (2) They have limited transferability and cannot effectively adapt to new tasks or data distributions; (3) They cannot adequately integrate world knowledge or prior knowledge.
Therefore, Professor Hochreiter warned that decision-makers are skeptical about the effectiveness of these models in real-world data applications, as real-world data is always changing, noisy, and sometimes scarce. In fact, in fields like healthcare, aviation, and autonomous driving, where demand is high but safety and interpretability are major considerations, the application of deep learning technology remains limited.
2
Broad AI
Nevertheless, Professor Hochreiter also pointed out that current AI is already attempting to overcome these limitations, with “Broad AI” as the new goal for AI.
What kind of system qualifies as Broad AI?
It differs from existing narrow AI, which is designed for specific tasks, and emphasizes skill acquisition and problem-solving capabilities (skill acquisition and problem solving). This perspective comes from François Chollet, an author at Google and Keras, who mentioned in a paper his definition of intelligence. Chollet believes that Broad AI, positioned at the second tier of intelligence (as shown in the diagram below), should possess the following key characteristics: knowledge transfer and interaction, robustness, abstraction and reasoning capabilities, and efficiency. Broad AI fully utilizes sensory perception and prior experiences and learned skills to successfully handle different tasks.
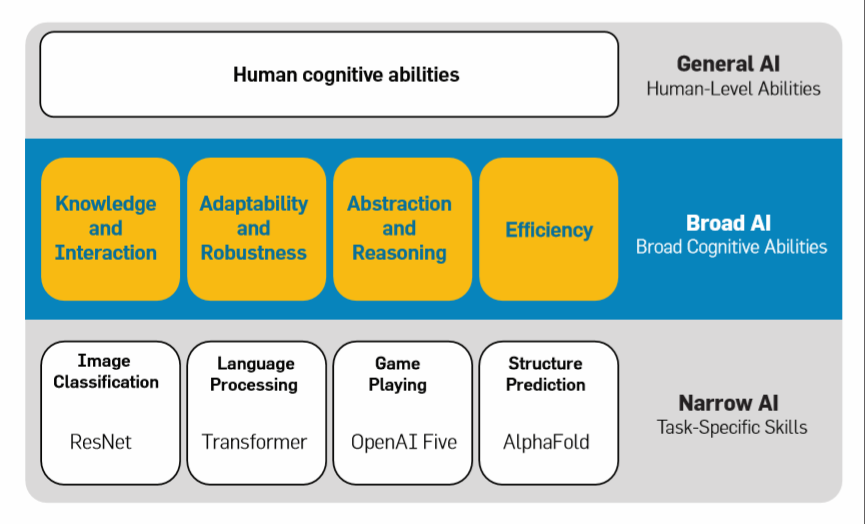
Caption: Different levels of AI corresponding to their capabilities
Professor Hochreiter believes that existing architectures, networks, or methods have reached the requirements of Broad AI to some extent. He cited the use of contrastive learning for self-supervised training to demonstrate transferability; the Modern Hopfield networks that fully leverage context and prior experience; and the neural-symbolic computing models that integrate knowledge and reasoning.
3
Transferability
One effective model learning method to enhance network transferability is few-shot learning. It can achieve good performance with only a small amount of training data, thanks to its existing “prior knowledge” or “experience.” This prior knowledge often benefits from pre-training tasks that involve large-scale data and foundation models. Such data is typically extracted using contrastive learning or self-supervised training to obtain useful representations. Once the pre-trained model is well-trained, the posterior knowledge acquired in that task becomes the prior knowledge for new downstream tasks, enabling the model to effectively transfer to new contexts, customers, products, processes, and data.
Professor Hochreiter specifically mentioned the contrastive learning pre-training method in the vision-language cross-modal field—CLIP. CLIP is a work published by OpenAI last year at ICML, using a simple pre-training task, namely image-text matching, to learn more powerful image representations through contrastive learning. This task was trained using 40 million image-text pairs collected from the internet.
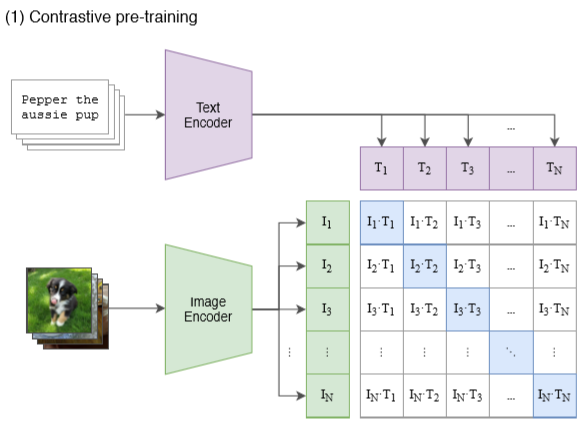
Caption: CLIP uses image-text matching for training
The surprising outcome is that it can achieve performance comparable to previous fully supervised methods on over 30 computer vision tasks without any additional data training, achieving remarkable “zero-shot learning”. As Professor Hochreiter praised, this high degree of transferability and robustness is a highly favored characteristic in industries that deal with real data.
In fact, since the invention of CLIP, many subsequent transfer learning works have been based on CLIP. It is not an exaggeration to say that it is an indispensable part of the unification of vision and language, somewhat akin to how Bert is to NLP tasks. Many contemporary methods of Prompt learning also draw inspiration from CLIP or operate within the CLIP framework.
4
Utilizing Experience
Broad AI should also fully utilize the context and prior experiences, which is closely related to memory. Professor Hochreiter, as one of the inventors of Long Short-Term Memory networks, is well-positioned to speak on this matter. In cognitive science, some scholars have proposed the concept of short-term memory, which describes how humans quickly transform stimuli, such as an image or a word, into an abstract conceptual category and associate it with information related to long-term memory. The process of “stimulus-conceptualization-association” occurs almost unconsciously but plays a crucial role in our understanding of everyday things and language communication.
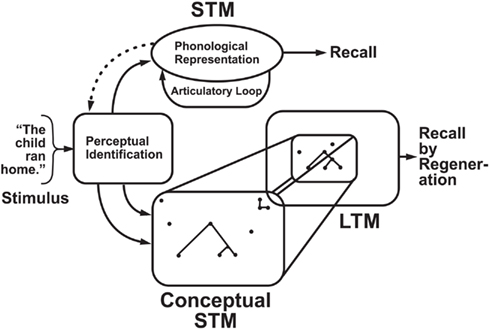
Caption: The cognitive process of “stimulus-conceptualization-association”
Regarding this, Hochreiter cited the work of Modern Hopfield networks (MHN), which was completed under his guidance. The Hopfield neural network was proposed as early as 1982; it is a neural network that combines storage systems and binary systems, simulating human memory models. MHN posits that the self-attention mechanism in Transformers is an update rule of Hopfield networks with continuous states and provides a new interpretation of self-attention from the perspective of Hopfield networks. The memory-related part of the explanation involves uncovering the covariance structure in the data, i.e., how features can co-occur in the data. MHN amplifies this co-occurrence. This correlation can be seen as triggering the associative parts of memory, thereby effectively utilizing existing knowledge.
Hochreiter pointed out that MHN can uncover rich correlations among data, a strength that can avoid the risk of “shortcut learning” that contemporary methods often encounter. “Shortcut learning” refers to when the features learned by a model are not genuinely used for decision-making but merely identify some special correlations, such as airplanes always appearing in the upper half of images, etc. (For more details, refer to AI Technology Review’s past introduction: Deep Learning Fails Due to “Shortcuts”)
5
Combining Neural and Symbolic Systems
Combining neural networks with symbolic systems can better facilitate AI models’ integration of world knowledge and abstract reasoning capabilities.
Rationalism-based symbolic systems rely on logic and symbolic representation, directly encoding human reasoning methods into machines. Their advantage lies in strong abstraction capabilities and achieving good results with relatively little data. However, due to the complexity and diversity of real-world knowledge and its unstructured nature, it is challenging to perfectly encode these into machine-readable rules.
On the other hand, empiricism-based neural networks directly use large amounts of data to implicitly (unsupervised) or explicitly (supervised) guide models to learn useful representations from the data without the need to design complex rules, achieving astonishing performance. However, neural networks also face challenges such as weak interpretability and data hunger.
Organically combining the two has been a frequent topic of contemplation among AI scholars. Interestingly, this can also be related to the historical debate between rationalism and empiricism in human history, which is similarly a contentious topic.
Professor Hochreiter believes that the graph neural networks (GNN), which have been developed for some time, represent this direction. This is also based on an opinion from a survey published at IJCAI’20, which classifies GNN as a type 1 neural-symbolic system. The paper argues that both seek rich vectorized representations of neural network inputs and use tree and graph structures to represent data and their relationships. Professor Hochreiter believes they perform well in dynamic interaction and reasoning, emphasizing molecular properties, social network modeling, and engineering predictions, among others.
Caption: GNN graph structure diagram
6
Conclusion
Hochreiter emphasized that achieving Broad AI requires the combination of neural-symbolic systems to reach a form of bilateral AI. AI researchers should also strive towards AI systems with stronger skill acquisition and problem-solving capabilities. He further envisioned that Europe has traditional advantages in both areas, thus should leverage these advantages and actively seek solutions for Broad AI.
References:
Hochreiter, Sepp. “Toward a broad AI.” Communications of the ACM 65.4 (2022): 56-57.
Chollet, F. On the Measure of Intelligence (2019); ArXiv:1911.01547.
Luís C. Lamb, Artur d’Avila Garcez, Marco Gori, Marcelo O.R. Prates, Pedro H.C. Avelar, and Moshe Y. Vardi. 2021. Graph neural networks meet neural-symbolic computing: a survey and perspective. In IJCAI’20. Article 679, 4877–4884.

Scan to Join Us
Individual Membership: 1000 RMB/session (5 years)
Student Membership: 50 RMB/session (5 years)
Lifetime Membership: 2000 RMB