
First, let’s visually perceive the status of “Deep Learning”. The image below is a relationship diagram of AI, Machine Learning, and Deep Learning.
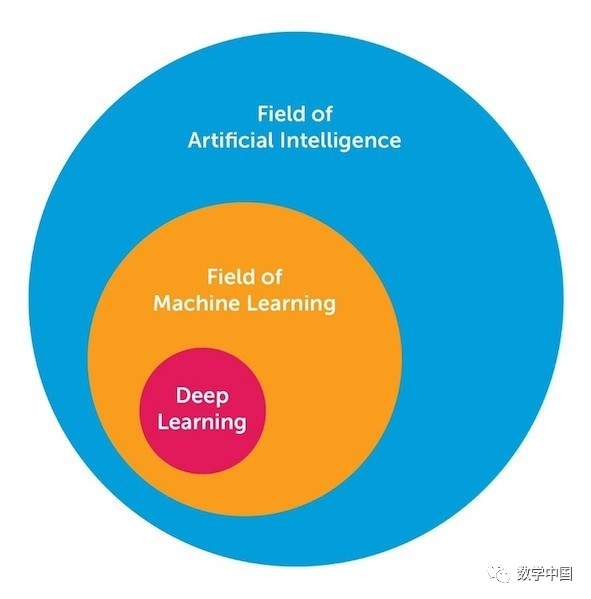
The field of AI is relatively broad, Machine Learning is a subfield of AI, and Deep Learning is a subset within the Machine Learning domain.
Deep learning algorithms have recently become increasingly popular and useful; however, the success of deep learning or deep neural networks is attributed to the continuous emergence of various neural network model architectures. In this article, the author reviews the development of deep neural network architectures over the past 18 years, starting from 1998.

From the coordinates in the figure, we can see that the x-axis represents the complexity of operations, and the y-axis represents accuracy. Initially, as the model’s weights increased, the model became larger and its accuracy higher. However, after the emergence of network architectures like ResNet, GoogleNet, and Inception, the weight parameters have been decreasing while achieving the same or even higher accuracy. It is important to note that moving further right on the x-axis does not necessarily mean longer computation time. Here, no time statistics are provided; rather, a comparison of model parameters and network accuracy is made.
Among these, there are several networks that the author believes are essential and worth learning: AlexNet, LeNet, GoogLeNet, VGG-16, and NiN.
The First Generation of Artificial Neural Networks
In 1943, psychologist Warren McCulloch and mathematician Walter Pitts proposed the concept of artificial neural networks and the mathematical model of artificial neurons in their collaborative paper “A logical calculus of the ideas immanent in nervous activity,” thus beginning the era of research on artificial neural networks. In 1949, psychologist Donald Hebb described the learning rules of neurons in his paper “The Organization of Behavior.”
Further, American neuroscientist Frank Rosenblatt proposed a machine that could simulate human perception abilities, calling it a “Perceptron.” In 1957, he successfully completed the simulation of the perceptron on the IBM 704 machine at Cornell Aeronautical Laboratory, and in 1960, he achieved a perceptron-based neural computer called Mark1 that could recognize some English letters.

The first generation of neural networks could classify simple shapes (such as triangles and quadrilaterals). People gradually recognized that this method was used to implement functions similar to human sensation, learning, memory, and recognition.
However, the structural defects of the first generation of neural networks limited their development. In the perceptron, the parameters of the feature extraction layer were manually adjusted, which contradicted its requirement for “intelligence.” On the other hand, the single-layer structure limited its learning ability, and many functions exceeded its learning scope.
The Second Generation of Neural Networks
In 1985, Geoffrey Hinton replaced the single feature layer in the perceptron with multiple hidden layers and used the BP algorithm (Back-propagation algorithm, proposed in 1969, practicable in 1974) to calculate network parameters.
In 1989, Yann LeCun and others used deep neural networks to recognize handwritten characters in letters. Later, Lecun further applied CNN (Convolutional Neural Networks) to complete the recognition of handwritten characters on bank checks, achieving commercial-level accuracy. Although this algorithm achieved great success, it trained on the dataset for about three days.
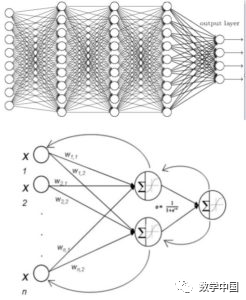
The network structure is divided into an input layer, multiple hidden layers, and an output layer. Before training the network, weights are randomly initialized, and network parameters are adjusted using the BP algorithm.
The BP algorithm does not always run well. Even with stochastic gradient descent, the BP algorithm can easily get trapped in local optima. Moreover, as the number of layers in the network increases, the difficulty of training increases.
The second generation of neural networks has the following main drawbacks:
1. It must be trained on labeled data, unable to train on unlabeled data.
2. As the number of layers increases, the signal backpropagated by BP becomes weaker, limiting the number of layers in the network.
3. The backpropagation between multiple hidden layers slows down training.
4. It may cause the network to get trapped in local optima.
5. Many parameters need to be manually set by human experience and skills, such as the number of layers and the number of node units, which cannot be intelligently selected and thus restrict the development of neural networks.
Subsequently, people attempted to increase the dataset and estimate initialization weights to overcome the shortcomings of artificial neural networks. However, the emergence of SVM (Support Vector Machines) led to a winter in the research of artificial neural networks.
The simple structure of SVM allows for fast training speed and relatively easy implementation. However, due to SVM’s simple structure, it is good at handling simple features but not complex ones. Learning with SVM requires prior knowledge of specific problems, but it is difficult to find some universal prior knowledge. Furthermore, the features of SVM are not self-selected but manually extracted.
Although SVM performs well in certain fields, due to its shallow structure’s fatal flaws, it is not a good trend for the development of artificial intelligence.
The Visual Principles of the Human Brain
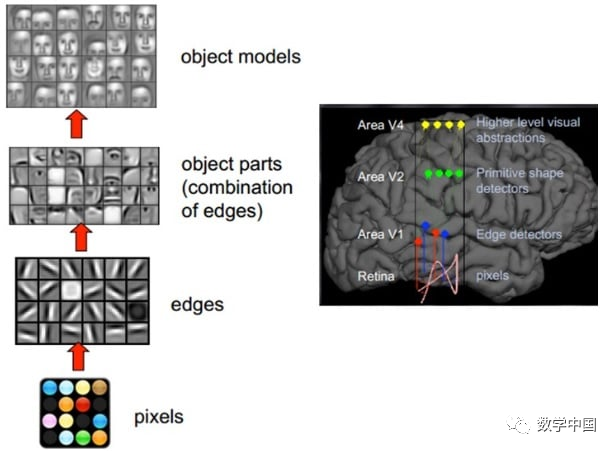
In 1958, David Hubel and Torsten Wiesel conducted research on the correspondence between the pupil region and cortical neurons, discovering direction-selective cells in the visual cortex, showing that the cortex performs low-level abstractions of raw signals, gradually iterating to higher-level abstractions.
Further scientific research indicates that the cortical areas related to many human cognitive abilities do not explicitly preprocess perceptual signals but allow them to pass through a complex modular hierarchical structure, which over time can express them based on the patterns presented by observations.
In summary, the information processing of the human visual system is hierarchical, extracting edge features from the low-level V1 area, then moving to the V2 area for shapes or parts of targets, and finally to higher levels for the entire target and its behavior. In other words, high-level features are combinations of low-level features, and the representation of features becomes increasingly abstract from low to high. This physiological discovery has contributed to breakthroughs in computer artificial intelligence forty years later.
Around 1995, Bruno Olshausen and David Field simultaneously studied visual problems using physiological and computational methods. They proposed a sparse coding algorithm, iterating with 400 image fragments to select the best fragment weight coefficients. Surprisingly, the selected weights were primarily the edges of different objects in photographs, with similar shapes but differing in direction.
The research results of Bruno Olshausen and David Field align with the physiological findings of David and Torsten Wiesel forty years ago. Further research indicates that the information processing of deep neural networks is hierarchical, similar to humans, moving from low-level edge features to high-level abstract representations in a complex hierarchical structure.
Research has found that this pattern exists not only in images but also in sounds. Scientists have discovered 20 basic sound structures from unlabeled sounds, with other sounds composed of these 20 basic structures. In 1997, LSTM (a special type of RNN) was proposed and showed good results in natural language understanding.
4. The Rise and Development of Deep Neural Networks
In 2006, Hinton proposed the Deep Belief Network (DBN), a deep network model. It used a greedy unsupervised training method to solve problems and achieved good results. The training method of DBN (Deep Belief Networks) reduced the difficulty of learning hidden layer parameters. Moreover, the training time of this algorithm is nearly linearly related to the size and depth of the network.
Unlike traditional shallow learning, deep learning emphasizes the depth of the model structure, clarifying the importance of feature learning. By transforming features layer by layer, it changes the representation of sample meta-space features into a new feature space, making classification or prediction easier. Compared to the manual feature construction methods, using big data to learn features can better characterize the rich intrinsic information of the data.
Compared to shallow models, deep models have great potential. With massive data, it is easy to achieve higher accuracy by increasing the model size. Deep models can perform unsupervised feature extraction, directly handle unlabeled data, and learn structured features; thus, deep learning is also known as Unsupervised Feature Learning. With the advent of high-performance computing devices like GPUs and FPGAs, as well as the emergence of neural network hardware and distributed deep learning systems, the training time of deep learning has been significantly reduced, allowing people to increase learning speed simply by increasing the number of devices used. The emergence of deep network models has solved countless difficult problems, and deep learning has become the hottest research direction in the field of artificial intelligence.
In 2010, the U.S. Department of Defense’s DARPA program first funded deep learning projects.
In 2011, researchers from Microsoft Research and Google used DNN technology to reduce the speech recognition error rate by 20%-30%, the largest breakthrough in the field in 10 years.
In 2012, Hinton reduced the Top-5 error rate of the ImageNet image classification problem from 26% to 15%. That same year, Andrew Ng and Jeff Dean built the Google Brain project, training a deep network with over a billion neurons on a parallel computing platform containing 16,000 CPU cores, achieving breakthroughs in speech recognition and image recognition.
In 2013, Hinton’s DNN Research company was acquired by Google, and Yann LeCun joined Facebook’s artificial intelligence lab.
In 2014, Google improved language recognition accuracy from 84% in 2012 to 98% today, with a 25% increase in language recognition accuracy on the Android mobile system. In facial recognition, Google’s FaceNet system achieved 99.63% accuracy on LFW.
In 2015, Microsoft used deep neural network residual learning methods to reduce the ImageNet classification error rate to 3.57%, lower than the 5.1% error rate of human eye recognition in similar experiments, with a neural network that reached 152 layers.
In 2016, DeepMind used a deep learning Go software called AlphaGo, with 1920 CPU clusters and 280 GPUs, to defeat human Go champion Lee Sedol.
Research on deep learning in China is also accelerating:
In 2012, Huawei established the “Noah’s Ark Lab” in Hong Kong to conduct research in natural language processing, data mining and machine learning, media social interaction, and human interaction.
In 2013, Baidu established the “Deep Learning Research Institute” (IDL), applying deep learning to language recognition and image recognition and retrieval. In 2014, Andrew Ng joined Baidu.
In 2013, Tencent began building the deep learning platform Mariana, which provides parallel implementations of default algorithms for various application areas such as recognition and advertising recommendations.
In 2015, Alibaba released the DTPAI artificial intelligence platform, which includes deep learning open modules.
Research on deep learning has permeated various fields of life and has become the main development direction of artificial intelligence technology. The ultimate goal of artificial intelligence is to enable machines to possess inductive abilities, learning abilities, analytical abilities, and logical thinking abilities comparable to humans. Although current technology is still far from this goal, deep learning undoubtedly provides a possible path for machines to exceed human capabilities in specific domains.