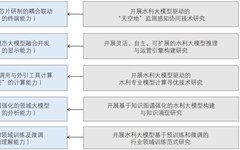
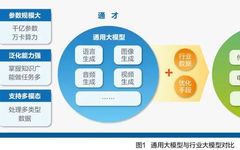
Eight Observations on Large Model Technology Development

Following the emergence of ChatGPT, the introduction of the Sora model has once again ignited enthusiasm for AI across various industries. In the face of rapidly evolving terminology, the plethora of personal and enterprise applications, and the continuous restructuring of business models, large models can exhibit astonishing capabilities and quickly impact society, which has deeper … Read more