
1. Background Introduction
If you have two machines with 8 A100 cards each (dreaming), and your supervisor asks you to learn how to deploy and train large models of different sizes, and write a documentation. You realize that what you need to learn the most is knowledge about distributed training, because this is your first time dealing with so many cards, but you don’t want to delve deeply into those low-level principles that seem daunting. You just want to understand the basic operation logic and specific implementation methods of distributed systems without seeking too much depth. So, let me help you sort out the knowledge you need to understand about distributed training of large models.
1.1 Definition of Distributed Systems
Distributed means distributing the model or data across different GPUs. Why distribute to different GPUs? Of course, it is because the memory of a single GPU is too small (whether for training acceleration or the model being too large to fit, it fundamentally boils down to insufficient memory on a single GPU). Why is the GPU memory so small? This is because GPUs have high bandwidth requirements, and memory that can achieve such high bandwidth is expensive. In other words, from a cost perspective, this limits the memory of a single GPU.
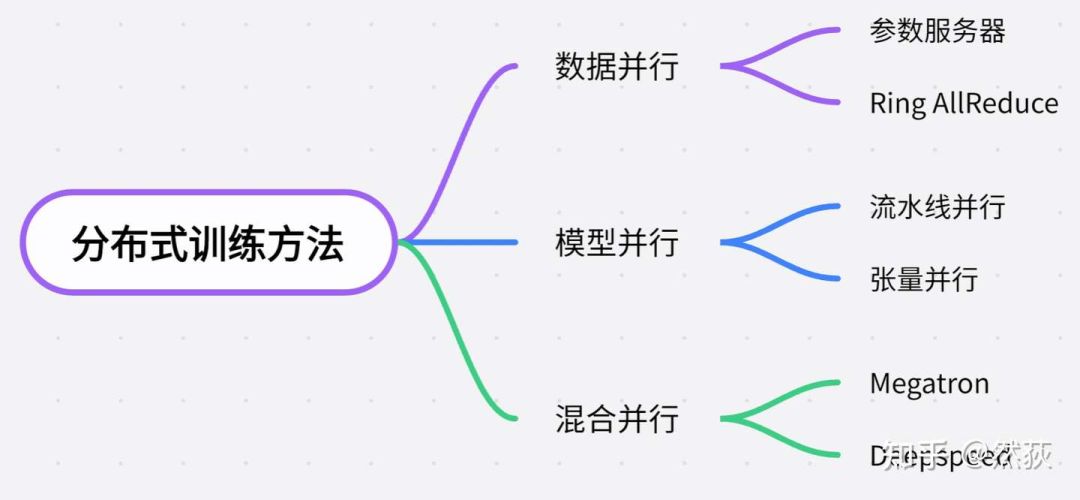
1.2 Classification of Distributed Methods
Based on the size of the model that needs to be loaded, distributed methods can generally be classified as follows:
-
For small models that can be trained on a single card, distribution is mainly for training acceleration, typically using data parallelism, where each GPU has a copy of the model, and different data is fed to different GPUs for training.
-
As models grow larger and cannot be trained on a single card, model parallelism is employed, which can be further divided into pipeline parallelism and tensor parallelism. Pipeline parallelism refers to splitting each layer of the model across different GPUs. When a model becomes so large that a single layer cannot be deployed on a single GPU, tensor parallelism is used to split the model layer for training.
-
Deepspeed uses the Zero Redundancy Optimizer to further reduce memory usage during training, allowing for training larger models.
2. Necessary Knowledge Supplement
2.1 How Models Are Trained
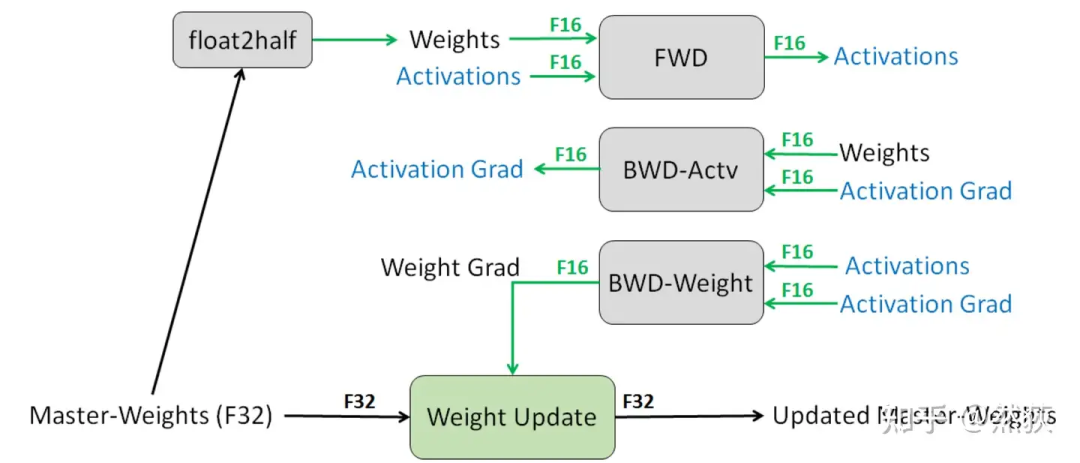
To understand how distributed training optimizes the model training process, it is essential to know how models are trained. Taking mixed precision training, which is currently the most widely used, as an example, the training process can be described as follows:
-
Step 1: The optimizer first backs up a copy of the model weights in FP32 precision and initializes the first and second moment (used for updating weights).
-
Step 2: Allocate a new storage space to convert the FP32 model weights into FP16 precision (used for forward and gradient computation).
-
Step 3: Run forward and backward passes, storing the gradients and activation values in FP16 precision.
-
Step 4: The optimizer uses the FP16 gradients and FP32 first and second moments to update the backed-up FP32 model weights.
-
Step 5: Repeat Steps 2 to 4 until the model converges.
We can see that during training, memory is primarily consumed in four modules:
-
Model weights (FP32 + FP16)
-
Gradients (FP16)
-
Optimizer (FP32)
-
Activation values (FP16)
How to calculate the memory consumed during training? How large a model will exceed our maximum memory during training? For an analysis of memory usage during large model training, you can refer to the article “Understanding Memory Usage of Large Models (Single Card Consideration)” which is very detailed (self-promotion) and helpful for understanding how to optimize memory usage.
https://zhuanlan.zhihu.com/p/713256008
2.2 How GPUs Communicate
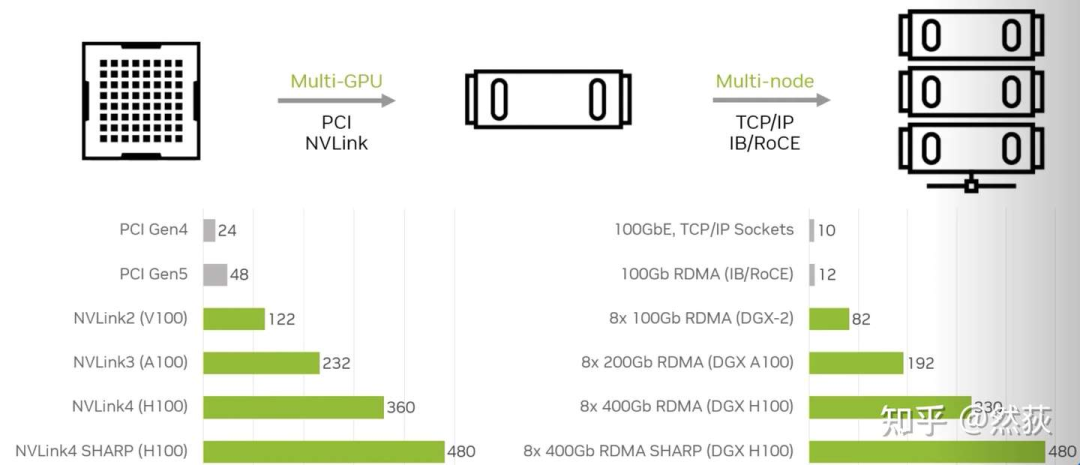
We often hear about single machine with 8 cards, multi-machine multi-card, and multi-node. Here, “single machine” and “node” refer to a single server, and 8 cards naturally refer to 8 GPUs. The 8 GPUs within the same server share the resources of the same host system (such as CPU resources, system memory, etc.). Different GPUs within the same node communicate via PCIe bus or NVLink (limited to NVIDIA cards), while GPUs between different nodes generally communicate via InfiniBand network cards (NVIDIA’s DGX system has one GPU card paired with one InfiniBand card). As shown below, the communication bandwidth between multiple nodes can reach a similar speed as that between multiple GPUs on a single node. You may wonder why NVLink is not used between nodes, because NVLink is designed for very short-distance communication, usually within the same server chassis, which is not convenient for expansion.
In addition to the hardware mentioned above, there is also software, namely the famous NCCL (NVIDIA Collective Communications Library), specifically designed for communication between multiple GPUs and even multiple nodes. AllReduce, Broadcast, Reduce, AllGather, and ReduceScatter are the main communication primitives implemented by NCCL.
In fact, NCCL provides an interface, and we do not need to understand how it is implemented at a low level; we just need to call the interface to achieve communication between GPUs.
2.2.1 Broadcast
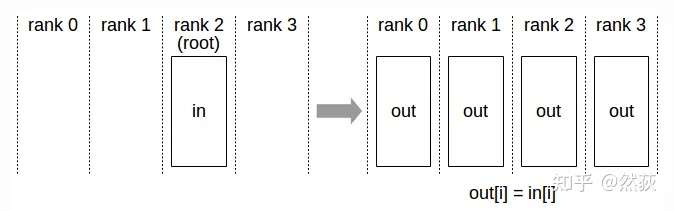
Broadcast refers to sending data from one GPU to all other GPUs simultaneously.
2.2.2 Scatter
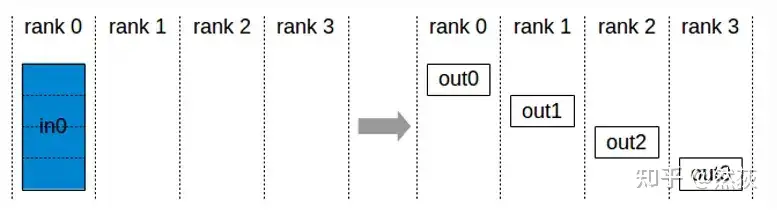
Scatter refers to splitting data from one GPU into multiple chunks and sending them sequentially to other GPUs.
2.2.3 Reduce
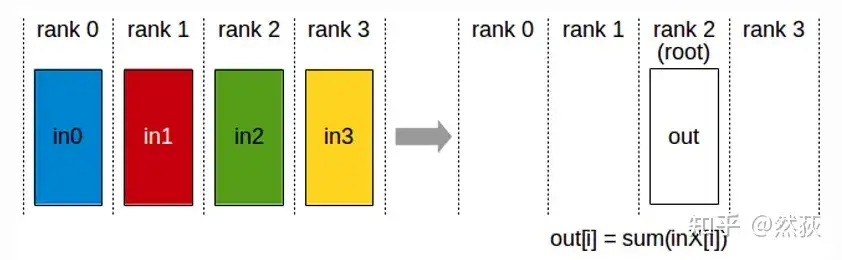
Reduce here serves to sum, i.e., sending data from multiple GPUs to a specified GPU and summing them.
2.2.4 Gather
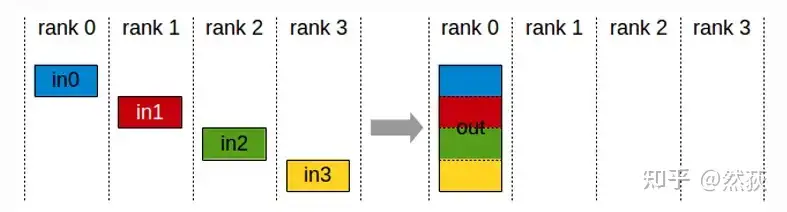
Gather is the reverse operation of Scatter, which merges data chunks scattered across different GPUs.
2.2.5 AllReduce
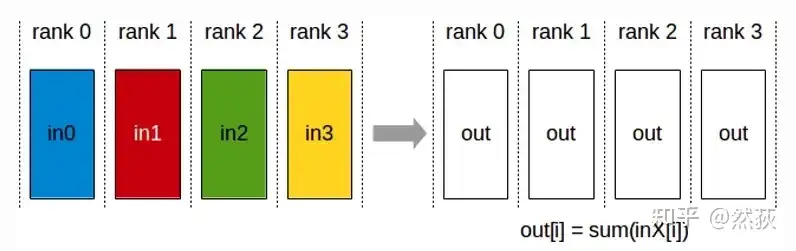
AllReduce means that each GPU sends data to the other GPUs, and each GPU sums the received data.
2.2.6 AllGather
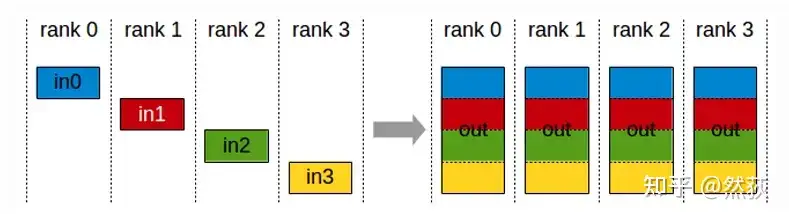
AllGather means that every GPU sends data to all other GPUs, and each GPU concatenates the received data into a complete dataset.
2.2.7 ReduceScatter
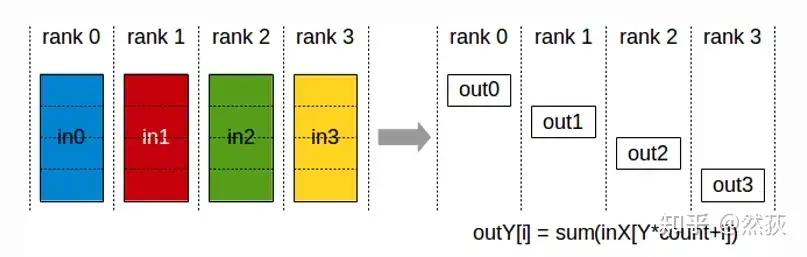
ReduceScatter means first performing Scatter and then Reduce, splitting the GPU data into multiple chunks, and then performing Scatter on each chunk according to the GPU sequence. After scattering all GPUs, the current GPU sums all the received data chunks, which is the Reduce operation.
If it seems confusing after reading, don’t worry; just have a general impression. You only need to know that these basic communication combinations between GPUs can achieve the various data transfers required for distributed systems.
3. Data Parallelism
Data parallelism refers to when the large model is initially small enough to fit comfortably on a single GPU. At this point, if we want to speed up training, besides increasing batch size, what else can we do? If one person is too slow at washing dishes, we can hire more people. Hiring more people means duplicating the model on multiple GPUs to get the job done.

3.1 Parameter Server
A very simple method is to select one of the eight monkeys as a supervisor, whose role is to collect the gradients from all the monkeys, then calculate the average gradient and send it back.
https://zhuanlan.zhihu.com/p/713256008

Here we introduce a concept of communication volume, which is used to measure the communication parameters of a single GPU or the entire system. We denote a complete set of parameters as Φ, which refers to a complete gradient parameter. Assuming there are N GPUs, the communication volume is as follows:

Does this method seem familiar? Yes, this is the previously mentioned ALL_Reduce method. This is also the method proposed by the parameter server in Li Mu’s paper. For more in-depth understanding, you can refer to the paper “Scaling Distributed Machine Learning with the Parameter Server”.
3.2 Ring AllReduce
Although the parameter server method is simple, it has two fatal flaws:
-
(1) Too much redundancy: Each GPU has to copy a model weight, which leads to redundancy.
-
(2) Unbalanced communication load: The server needs to communicate with every worker, while workers only need to send and receive once.
Ring AllReduce is a method used to solve the unbalanced load issue. We can understand the above method as a centralized method, while this method is decentralized, eliminating the distinction between server and worker, achieving balanced communication across all GPUs.
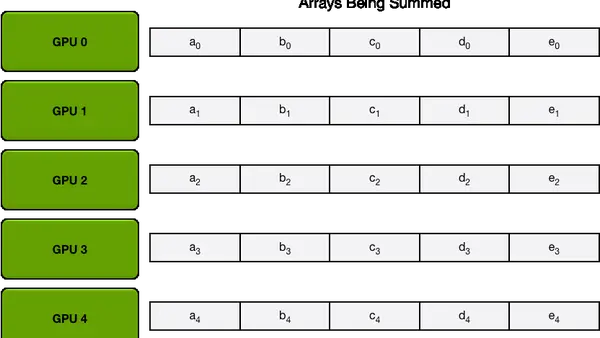
The entire process is actually the previously mentioned communication primitives of ReduceScatter followed by AllGather. For the communication volume calculation of Ring AllReduce, since it is a highly parallelized communication, we only need to consider the communication volume of a single GPU and then multiply by the number of GPUs for the total communication volume.

It is important to note that the total communication volume of the parameter server and Ring AllReduce is almost the same, but their communication times differ because the former has too high a communication load on the server side, causing delays and longer times. Currently, the commonly used DDP (Distributed Data Parallel) multi-machine multi-card training in Torch uses Ring AllReduce for communication.
4. Model Parallelism
The data parallelism mentioned above applies when the model is small enough to fit on a single GPU. However, in the era of large models, where models can have 70B parameters or more, a single card cannot accommodate them. What should we do? We can only disassemble the model. The fundamental difference between this distributed method and data parallelism is that the data in data parallelism is independent, while model parallelism involves splitting the model into parts that must use the same batch of data for processing.
4.1 Pipeline Parallelism
Pipeline parallelism refers to slicing the model layer by layer. Since the model is structured in layers, we can peel it off layer by layer.
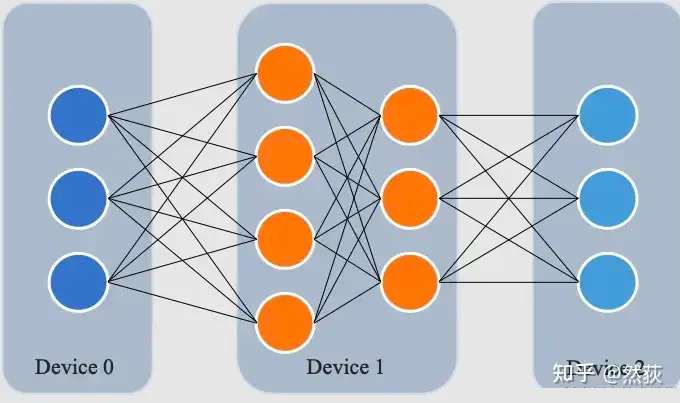
4.1.1 Naive Pipeline
The naive pipeline is the simplest form of pipeline, where we sequentially perform forward passes layer by layer and then backward passes layer by layer. It is easy to understand. It is important to note that we pass the output tensor of the current layer between each layer, not the gradient information, thus the communication volume is relatively small. However, a smaller communication volume does not mean a higher overall utilization efficiency, as the parallelism between communication and computation and memory redundancy are also crucial factors to consider.
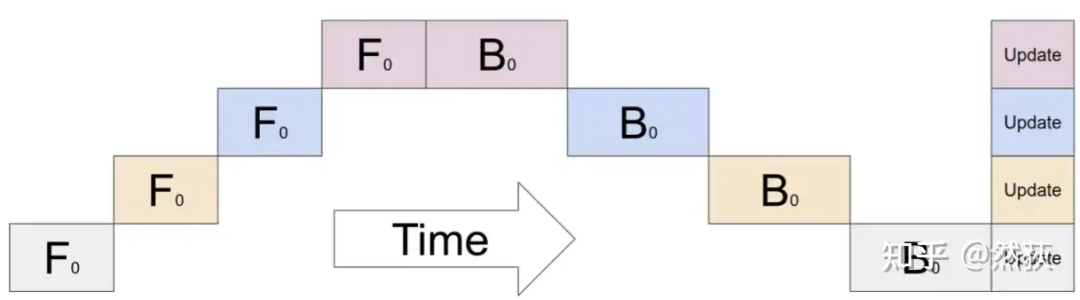
The image below shows a more concrete implementation of naive pipeline with two GPUs. We find that aside from the additional forward and backward information transfer in between, there is no difference in operation compared to running on a single GPU.
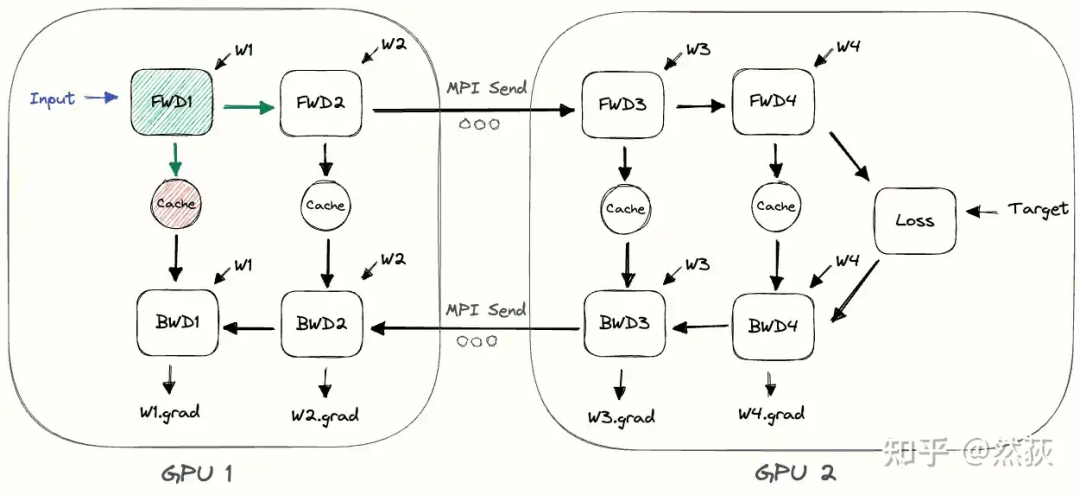
The naive pipeline is very simple, which leads to very obvious problems. We identify the two main issues:
-
Low GPU Utilization: As can be seen from our figure 4-2, all the blank spaces in the figure are wasted GPU space, referred to as bubbles. The bubble rate of the naive pipeline can be calculated as (Bubble Rate = (G – 1)/G), where G refers to the number of GPUs. It can be seen that the more GPUs there are, the closer the bubble rate approaches 1, which results in very low GPU utilization.
-
No Interleaving of Communication and Computation: When GPUs communicate between layers, all GPUs remain idle, and the communication and computation do not achieve a parallel mode, which significantly reduces training efficiency.
4.1.2 Micro-Batch Pipeline Parallelism
This method’s core idea is to use data parallelism to address the low GPU parallel efficiency of naive pipelines by splitting a large batch into multiple smaller batches for the pipeline. Let’s illustrate with a simple example: Zhang San and Li Si are processing a basket of fish using a naive pipeline, where Zhang San washes the fish, and Li Si cooks them. Li Si must wait for Zhang San to finish washing the entire basket before he can cook. Now they improve the process to micro-batch pipeline by dividing a large basket of fish into N smaller baskets. At this point, Zhang San can wash a small basket of fish and hand it to Li Si to cook, while Zhang San continues washing the next small basket, creating a parallel processing segment between them.
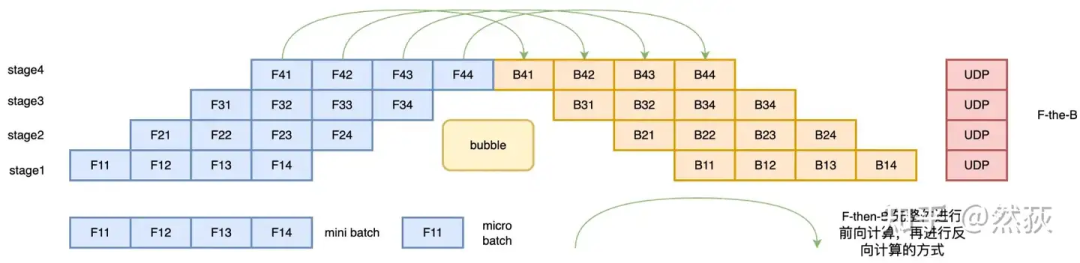
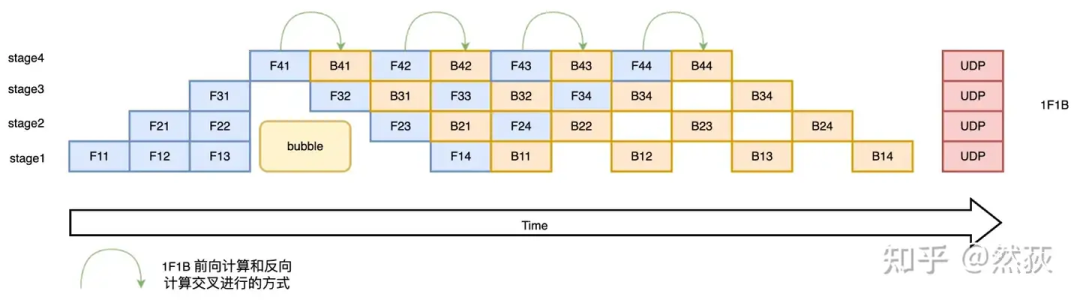
4.2 Tensor Parallelism
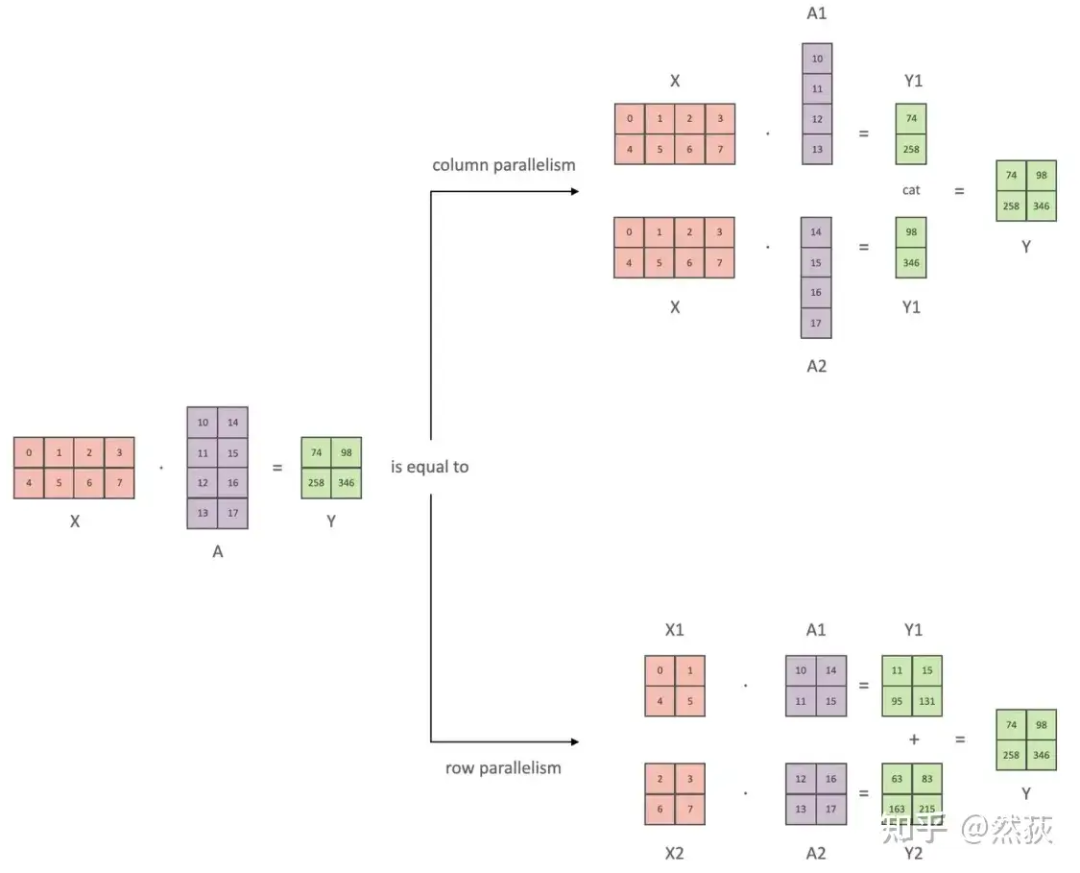
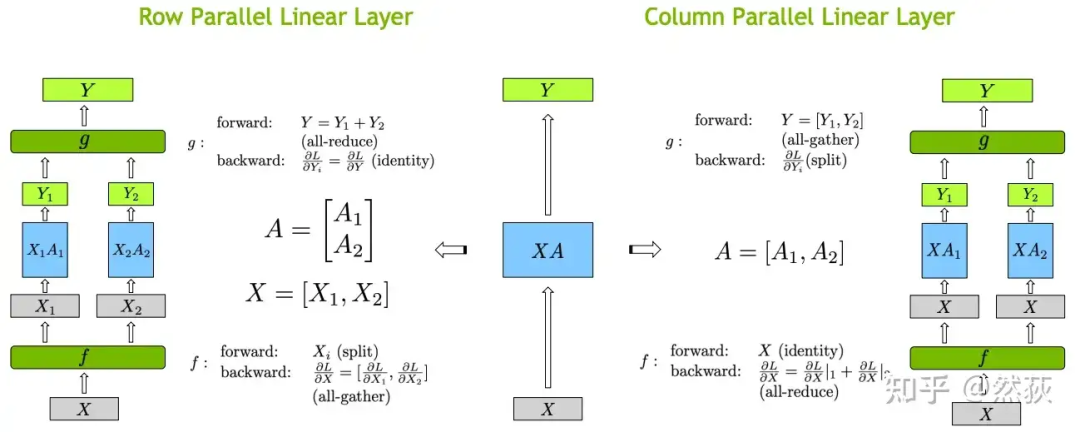
5. Mixed Parallelism
5.1 Megatron
5.1.1 Review of Transformer Model Structure
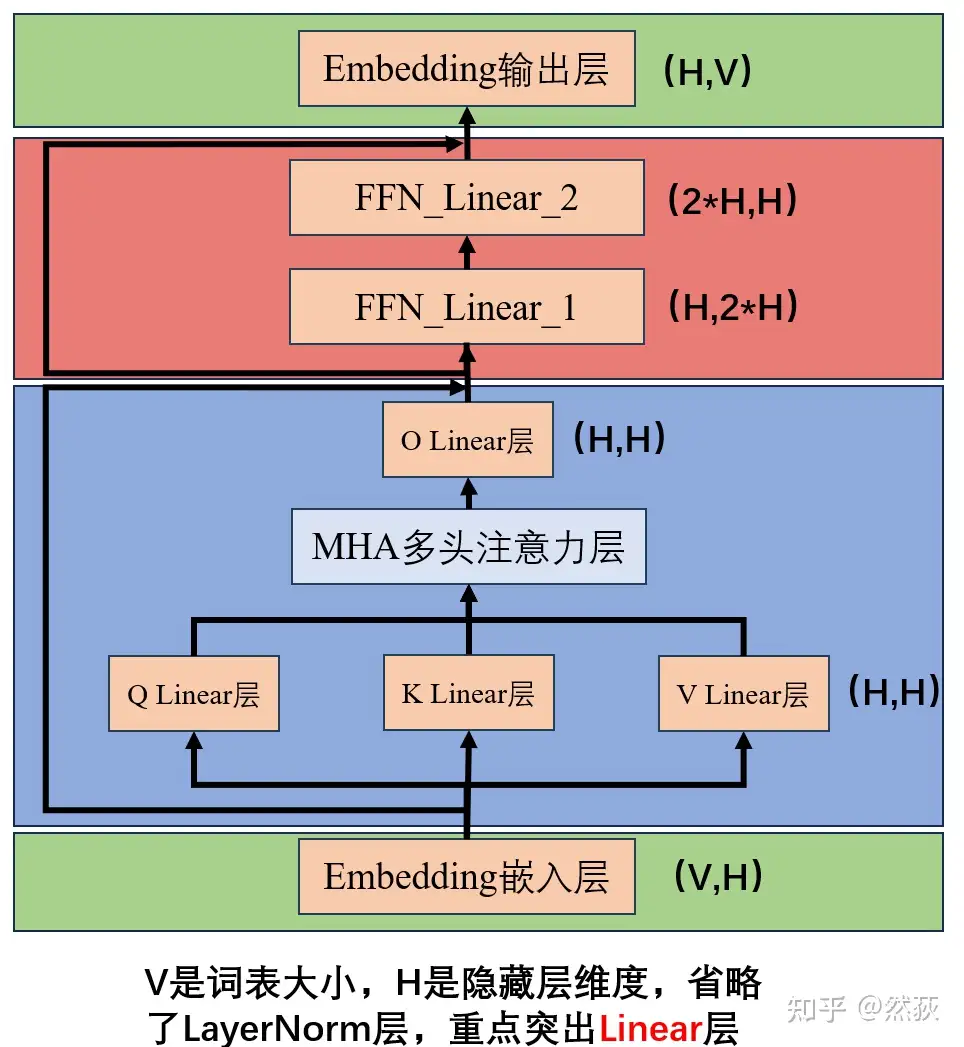
5.1.2 Tensor Parallelism in Feedforward Layers
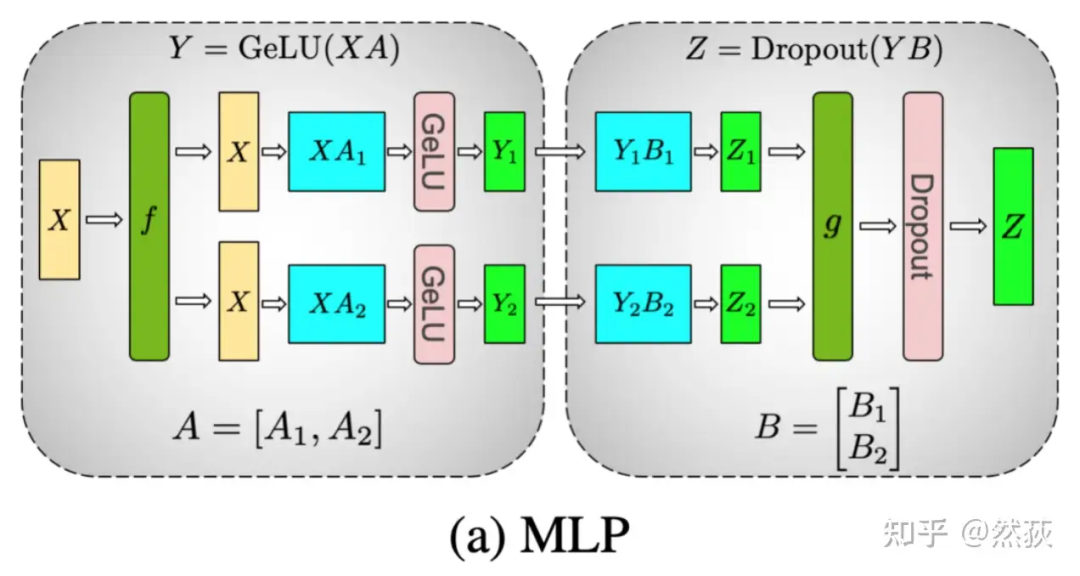
Let’s look at two equations: If
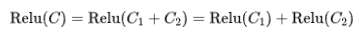
Where the colon represents concat
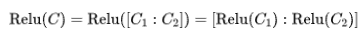
Which equation do you think is correct? I won’t keep you in suspense; the first addition equation is incorrect, while the second merging equation is correct.
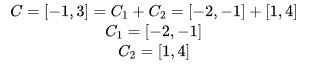
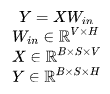
-
Forward computation of f: Copy input X to two GPUs, allowing each GPU to perform forward computation independently. -
Forward computation of g: After completing the forward computation on each GPU, obtaining Z_1 and Z_2, the GPUs perform an AllReduce to sum the results to produce Z. -
Backward computation of g: We only need to copy the weights to two GPUs, allowing them to independently compute gradients. -
Backward computation of f: When the gradient for the current layer is computed and needs to be passed to the next layer, we need to obtain . At this point, the two GPUs perform an AllReduce to sum their respective gradients.
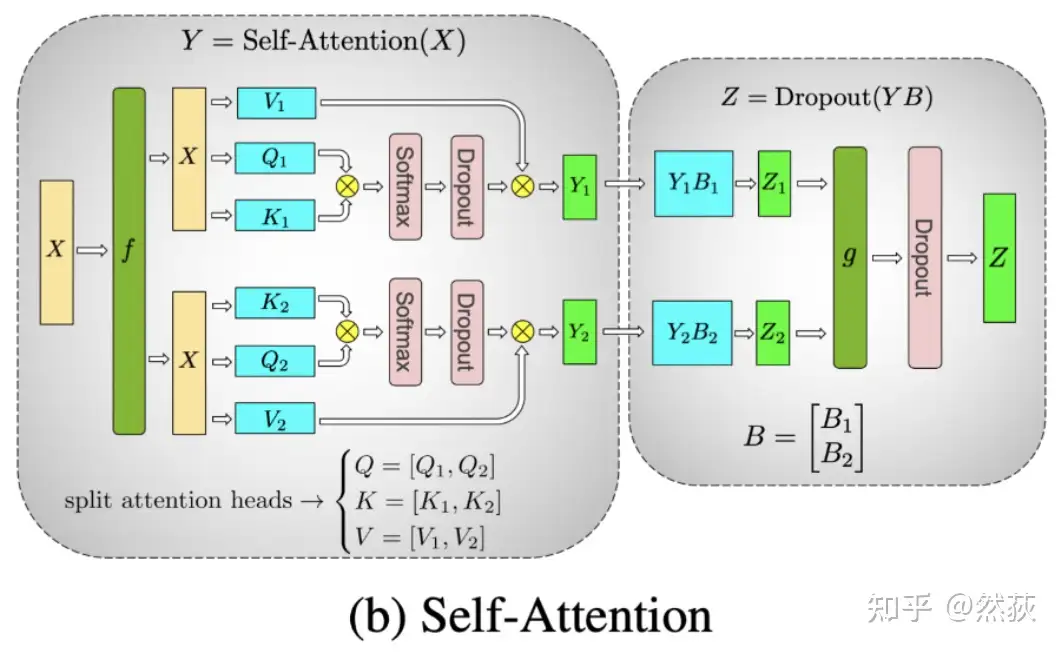
5.1.3 Tensor Parallelism in Multi-Head Attention Layers
5.1.4 Tensor Parallelism in Embedding Layers
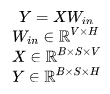
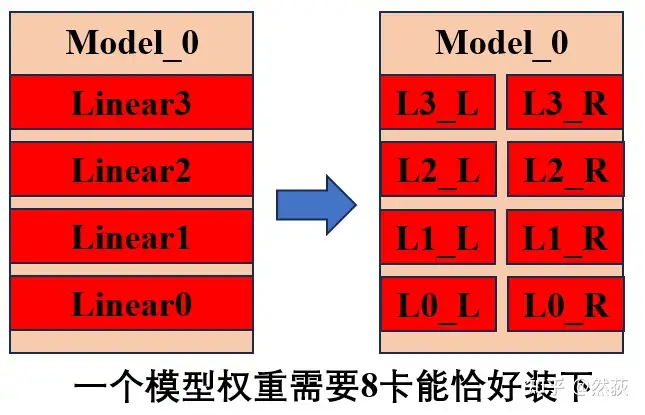
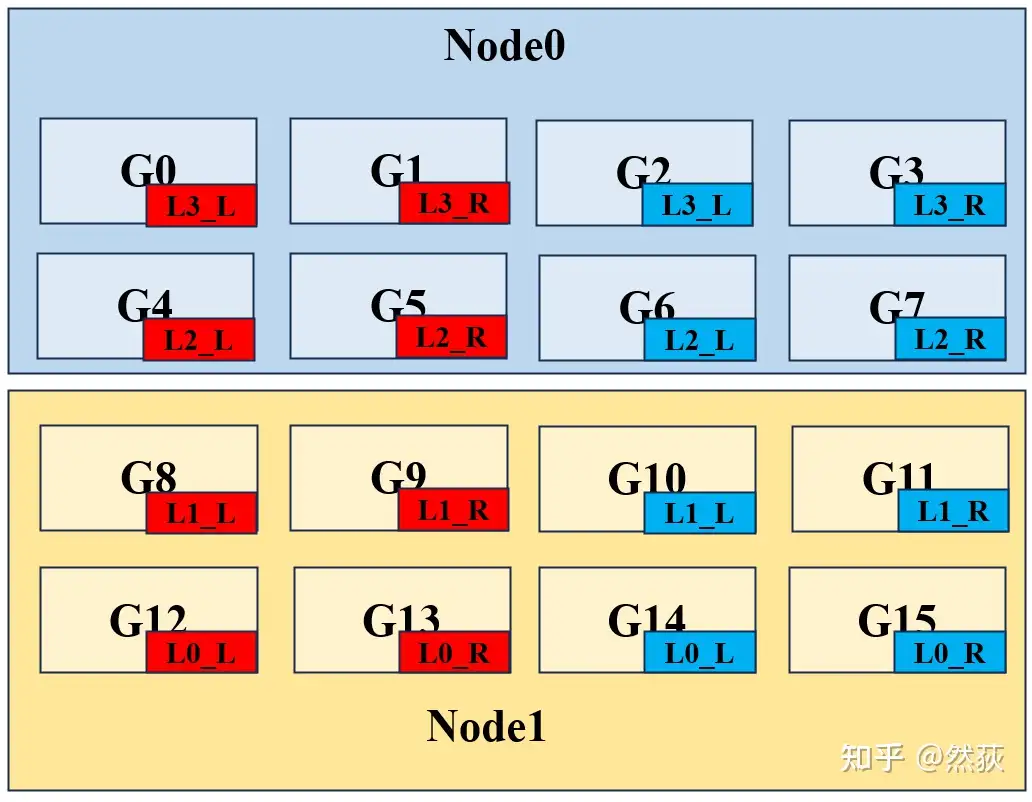
5.1.5 Example Analysis of 3D Parallelism
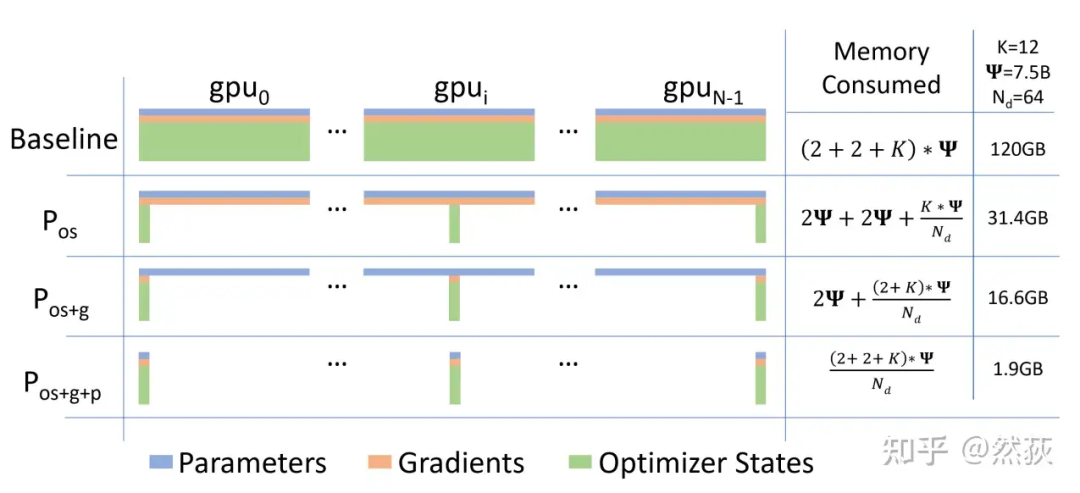
5.2 DeepSpeed
-
Model weights perform forward and backward passes to obtain gradients. -
Use gradients to update the first and second moments of the optimizer (Adam). -
Update model weights using the optimizer.
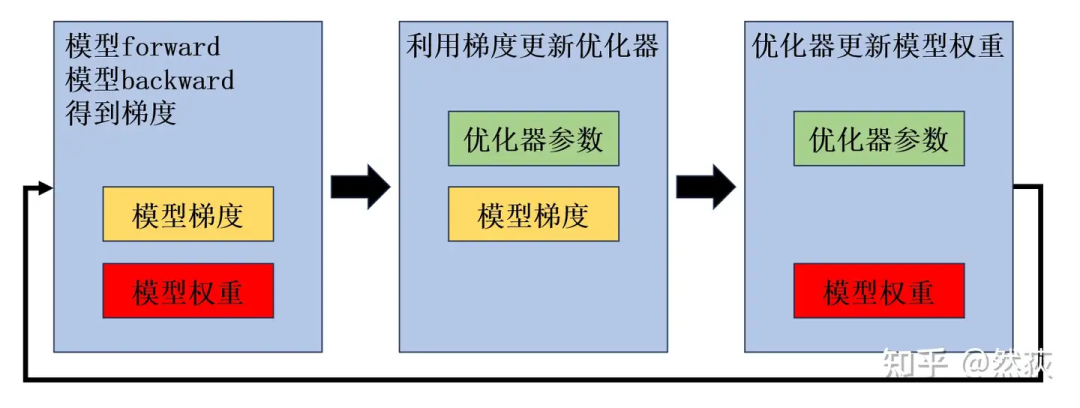
-
In the first image: During the backward pass, memory will certainly contain model weights and gradients, but optimizer parameters are not needed. -
In the second image: When updating the first and second moments of the optimizer, model weights are not required. -
In the third image: When using the optimizer’s first and second moments to update model weights, gradients should not be needed anymore and can be released.

-
The significance of the first and second moment parameters of the optimizer is to store historical gradient information and changes, so they cannot be released and must occupy memory waiting to be updated. -
Model weights are the parameters we need to update, so they must always be stored in memory waiting for updates. -
Gradients are different each time; can they be released? Actually, no, because the second and third steps are combined, which means that the optimizer.step() function requires the gradients to be retained until the weights are updated, but then it enters the next forward and backward passes, and the gradients remain stored (I actually find this strange; I wonder if anyone can clarify this, as I feel the gradients could theoretically be released).
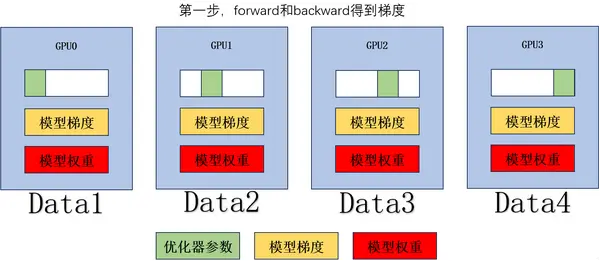
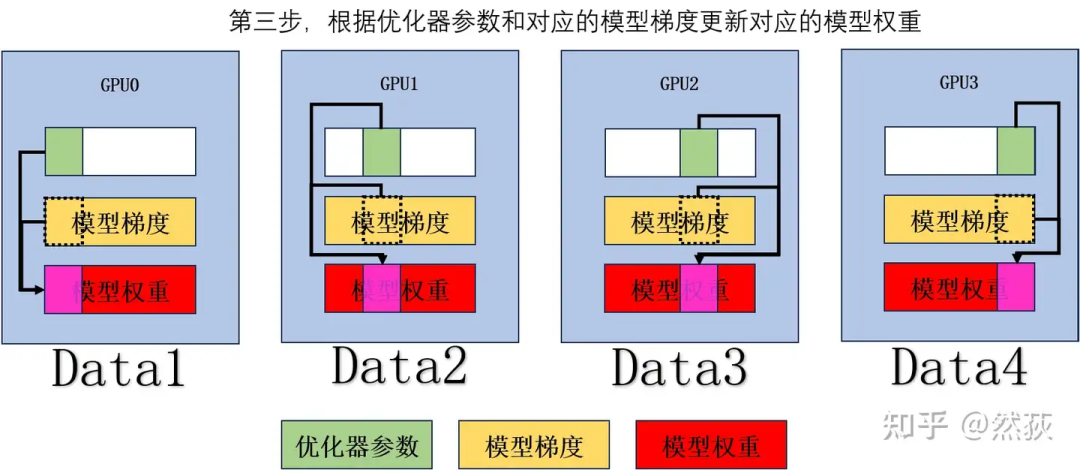
5.2.1 Zero1: Slicing Optimizer States

-
Perform forward and backward passes to obtain gradients. -
Perform Ring AllReduce on the gradients to obtain the average gradient, with a single GPU communication volume of . -
Update the corresponding model weights based on the optimizer parameters and corresponding model gradients. -
Perform AllGather on the updated model weights, with a single GPU communication volume of .

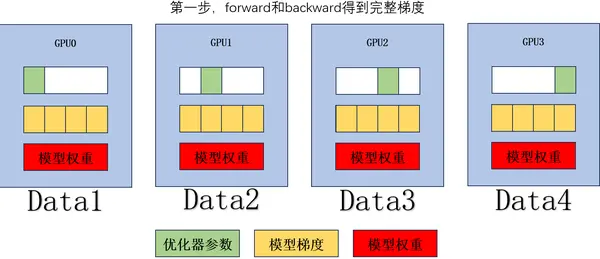
5.2.2 Zero2: Slicing Gradients
-
Perform forward and backward passes to obtain complete gradients. -
Perform ReduceScatter on the gradients, with a single GPU communication volume of . -
Update the corresponding model weights based on partial gradients and corresponding optimizer parameters. -
Perform AllGather on the model weights, with a single GPU communication volume of .

5.2.3 Zero3: Slicing Model Weights

6. Summary

Scan the QR code to add the assistant on WeChat