

More and more people are starting to pay attention to large models, and many colleagues who are doing engineering development ask me how to get started with large model training and inference system software (commonly known as large model Infra).
As a former backend developer, I can empathize with everyone’s feelings. In recent years, the overall internet business in China has been sluggish, while large models have risen against the trend, with daily news being vibrant and contrasting sharply with other subfields. In 2023, while Silicon Valley laid off hundreds of thousands of software engineers, major American companies are frantically buying GPUs and hiring people at high prices to work on large models, and the U.S. stock market has reached new highs due to expectations surrounding AI. The contrast is stark, and as computer professionals, we certainly do not want to miss the opportunity to get on board.
However, it is important to remind everyone that large model Infra is transitioning from the golden era to the silver era. I started writing about large model training systems in 2021, making me a firsthand observer of the complete cycle. Let me talk about several stages that I have observed in the evolution of large model Infra over the years:
2019-2021, Black Iron Era
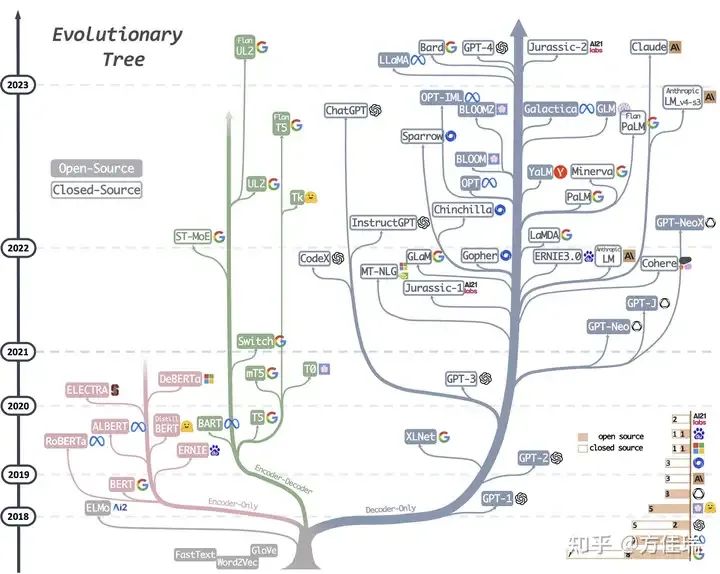
The famous paper “Attention is All You Need” published in 2017 led to the emergence of various model architectures based on Transformers, including the decoder-only GPT-1 (2018), encoder-only Bert (2018), and encoder-decoder T5 (2019), which began to dominate the NLP field. Applications in internet companies such as translation, dialogue, and recommendation were successively occupied by Transformers.
In response to the trend, some began to study how to enlarge Transformers models. Enlarging models was counterintuitive during the CNN era, as everyone was trying to shrink models through methods like NAS and AutoML to fit into cars, cameras, and mobile phones. The main proponents of Scaling Law were OpenAI and Google. In 2018, OpenAI replaced LSTM with Transformers in GPT-1, following the philosophical accumulation from Dota AI, leading to the emergence of GPT-2 and GPT-3. Google, as the origin of Transformers, proposed the MoE architecture for Transformers in 2017 and managed to train a 600B large model called GShard using 2K TPUs in 2020, developing a distributed training framework based on TensorFlow called MeshTensor. However, unlike OpenAI, Google did not bet on the decoder-only structure but instead vigorously developed the encoder-decoder structure (which was also the first structure proposed for Transformers). DeepMind, a relatively independent UK research institution under Google, also had models similar to GPT, such as Gopher and Chinchilla.
Despite the shock brought by GPT-3’s 175B parameters and few-shot learning capabilities in 2020, there was widespread skepticism about the large model technology route in China, with few supporters, and most algorithm colleagues were not interested in large models. I observed that this was due to two main reasons. On one hand, most people lacked a sense of pre-training; at that time, the NLP algorithm development paradigm focused on private data and fine-tuning Bert, based on experiences from the small model era, emphasizing data quality rather than a larger base model. Even doubling the model size required a substantial budget for training, raising doubts about ROI. On the other hand, the Infra was not ready. Training a large model was not something just anyone could afford; at that time, training models required collaboration between algorithm and engineering colleagues, and there was no concept of this kind of team composition. The business teams only had algorithm engineers, and dealing with GPUs was a headache for them, especially when deploying a model that required two GPUs to run, which was a disaster. Moreover, the Infra team belonging to the middle platform department did not understand the trends of large models, and cross-departmental information was siloed.
The teams most motivated to scale models domestically were those focused on algorithmic competitions, but most of the models used for competitions often ended up collecting dust after PR (public relations) efforts. However, this process trained many teams, and they later became the main force in training domestic large models after the explosive popularity of ChatGPT.
Courtesy to: Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
The poison of one is the honey of another. The enlargement of models provided new opportunities for AI Infra personnel. During that period, the main application of AI Infra was still recommendation systems, and NVIDIA was betting on the metaverse as a new growth point. Large models were also a novelty for Infra personnel. With OpenAI and Google paving the way, some institutions in the U.S. began exploratory work on enlarging models, mainly along the lines of enlarging the encoder structure of Bert. However, for training, there is not much difference between encoders and decoders. It was during this opportunity that the large model training frameworks Megatron-LM and DeepSpeed began to take shape. In 2020, Microsoft developed a 17B large Bert called Turing-NLG, and its training code became the prototype for DeepSpeed. In 2019, NVIDIA developed an 8.3B Megatron-LM, which, yes, is the name of a large Bert; the Megatron-LM repository also contained training model code scripts that implemented tensor parallelism and gradually evolved into the most popular training framework.
During this period, the main purpose of training models in major American companies was to test the waters and show off their strength, which is why DeepSpeed and Megatron-LM were open-sourced at the beginning. This was a good thing. Imagine if large models had been introduced as nuclear weapons, and everyone had hidden them like OpenAI did after 2022; the dissemination of Infra technology would not have been so rapid.
Using large-scale GPUs to train models made the data parallelism of the small model era inadequate. Some basic concepts for training optimization began to take shape, such as ZeRO, tensor parallelism, pipeline parallelism, offloading, and mixed parallelism. These technologies had earlier predecessors, such as FlexFlow for mixed parallelism in 2018, pipeline parallelism from GPipe trained by NAS, and ZeRO, a special form of Parameter Server, etc. However, these technologies were optimized and adapted more specifically for the Transformers architecture and high-bandwidth interconnects.
At that time, the understanding of large models was limited in China. Teacher Yuan’s Oneflow was an early attempt at distributed training for large models, and the SBP method for automated model parallelism was very advanced, but unfortunately, there was no business demand to support them in achieving PMF. Huawei’s MindSpore also made early attempts at automatic parallelism. Other teams that acted early included Alibaba’s M6, Zhiyuan’s GLM, and Huawei’s Pangu-alpha.
Aside from a few large model believers, major domestic companies were not interested in large models. The cloud/middle platform teams of various companies had just completed a round of arms race training ImageNet in X minutes and were still pondering what commercial value there was in training a model using such a large scale of GPUs. Some NLP technology startups were still focusing on customizing fine-tuned Bert for different businesses. Some investors from institutions would call to consult technical personnel about whether large models were a scam. Overall, before 2022, large models were still too advanced for China, resulting in a very weak consensus, which is why I referred to this period as the black iron era of large model Infra.
I began researching large model training systems at the end of the black iron era in early 2021. At Tencent’s WeChat AI, the research atmosphere was relatively relaxed and free, and I was fortunate that my +1 and +2 leaders had very good technical foresight and supported me in doing this without a clear prospect for landing. The biggest obstacle to training large models was computational resources. At that time, the GPU hardware I could access was mainly a single machine with 8 V100 cards, so I looked for a way to design a better CPU-offloading strategy to allow low-end machines to run large models, which is PatrickStar. At that time, several teams in the company tried to apply for hundreds of cards to train models, but due to unclear ROI, the applications were not approved.
2022-2023, Golden Era
After the preparatory period of the black iron era, marked by Meta’s open-source OPT-175B model, the large model Infra began to enter the golden era in 2022.
On one hand, with the iterative planning of NVIDIA chips, a DGX SuperPOD (2021) can easily handle the training of large models with hundreds of billions of parameters. NVIDIA promoted this supercomputer as a killer application. Aside from large models, there was really no known application that could fill it up. In November 2021, Tencent acquired a SuperPod prototype and tested it with various Infra teams in the company for two months. Initially, a dense testing schedule was set up, but it was discovered that only our tuning of PatrickStar was using the machine, and we ended up monopolizing it.
On the other hand, people began to see the power of large models. In May 2022, Meta open-sourced the weights of OPT-175B, which was trained to replicate GPT-3 using PyTorch FairScale. Although the model’s performance was not commendable, it truly benefited a wide range of large model researchers, and those in AI Infra finally had a real model to experiment with. In June 2022, HuggingFace organized over thirty national institutions and multinational teams to open-source the Bloom-176B model, which used the DeepSpeed framework.
Among the startups in Silicon Valley, Character.ai and Anthropic.ai had already been established for some time. At the beginning of 2022, while the nation was united in fighting against the pandemic, several groups abroad were intensively training models at the GPT-3 level. A memorable moment was in April 2022 when two authors of a Transformers paper left Google to establish a large model company called Adept.ai (which has recently been sold to Amazon), using large models to help people complete complex tasks. Their Twitter demo showcased how a large model could generate a bar chart from input text, which left me in disbelief; that was my ChatGPT moment. Now, seeing similar things is no longer surprising.
It wasn’t until November 2022 that ChatGPT exploded onto the scene, igniting interest in large models. This event significantly accelerated the consensus on the value of enlarging models. Large model teams quickly gathered a wealth of human, material, and financial resources, leading to a leap in the development of large model Infra.
The development of large models is driven by training. In the field of training systems, Megatron-LM and DeepSpeed rapidly iterated during the golden era. However, to be honest, the quality of these two pieces of software before the ChatGPT era was concerning; it felt like they were in a state of no architecture, frantically stitching together various research ideas, with many system bugs and unfriendly user interfaces. However, having an early-mover advantage in large model training frameworks is crucial. When choosing, people did not consider how user-friendly it was but rather what models this framework had previously trained. After all, training once could cost hundreds of thousands to millions of dollars, so stability was paramount. After the ChatGPT era, the advantages of Megatron-LM, backed by NVIDIA’s brand and technology, began to snowball, and now it is basically dominated by its commercial version Nemo.
In terms of technological innovation, there are abundant opportunities in parallel strategies and operator optimization, with many impactful works such as Sequence Parallelism and Flash Attention being simple but effective. After pre-training, there was also demand for SFT, RLHF, leading to the emergence of mixed scheduling and works like S-LoRA.
The large model Infra has also profoundly influenced the trajectory of upper-level algorithm development. For example, for a long time, people were hesitant to increase context length because the memory cost of the QK^T matrix in attention calculations is quadratic in terms of sequence length, leading to a trend of researching linear attention and approximate attention that sacrificed precision for length. After the engineering optimization of memory-efficient attention, the most notable being Flash Attention, which eliminated the quadratic memory cost, everyone returned to using standard attention.
In the field of inference systems, major developments occurred much later than training, primarily happening after 2023. On one hand, there was no inference demand if the model had not been trained. On the other hand, before the decoder structure was standardized, inference acceleration had not been researched in depth. Previously, everyone was focused on optimizing the inference of encoder Transformers, looking at operator fusion and how to eliminate padding for variable-length inputs, with ByteDance’s Effective Transformers being a notable example. During the Bert era, the most commonly used framework was FasterTransformers (FT), and my project TurboTransformers from 2019 was directly aimed at FT. FT was developed by NVIDIA’s China team (made in China), and I witnessed it grow from a small corner of NVIDIA DeepLearning Example to becoming a separate product line.
System optimizations from the Bert era can be reused in the prefill stage of GPT, but there is still a lack of solutions for the key issues in the decoding phase. The paradigm shift from encoder to decoder has a minimal impact on training but a significant one on inference. It transforms the computationally intensive problem into a super-complex issue of memory-intensive computation in the decoding phase. Various optimizations from the Bert era cannot be applied to the decoding phase. Since the output length in decoding is uncertain, it leads to two key issues that are difficult to resolve: first, how to dynamically batch when the output token length is uncertain to reduce ineffective padding calculations; and second, how to dynamically allocate GPU memory to KVCache without wasting memory fragments.
Although inference started late, its development speed is much faster than training. This is because inference requires fewer resources and has a lower threshold, allowing everyone to participate, pooling the wisdom of the masses, which quickly exposes many problems that can be resolved immediately. In 2022, the OSDI paper ORCA proposed Continuous Batching, which solved the first problem. Just one year ago, in June 2023, the vast majority of professionals in large models in China were still unaware of Continuous Batching. In 2023, the SOSP paper Paged Attention solved the second problem.
The open-source community is developing rapidly. Excluding libraries like Accelerate and DeepSpeed-Inference, which only handle computation but not scheduling, the earliest inference framework in the open-source field was HuggingFace’s TGI (text-generation-inference), initially designed for inference on models hosted on HuggingFace’s website. However, the early-mover advantage in inference frameworks has diminished, partly because this framework was written in Rust, making it inaccessible for most people to participate. At this time, some excellent open-source inference frameworks had already emerged in China, such as Shanghai AI Lab’s LMDelopyer.
The real game changer was Berkeley’s vLLM, which was open-sourced in June 2023 and became famous for its unique Paged Attention technology. At this point, various large models had also released their first versions, and vLLM immediately met the demand for concentrated online deployment. In September 2023, NVIDIA launched TensorRT-LLM, initially open-sourcing it for enterprise internal testing and later to the public, capturing a significant portion of the inference market. In early 2023, NVIDIA officially organized efforts to develop a decoder model inference framework, and TensorRT-LLM integrated the three major products: TensorRT, Triton-server, and FT, indicating that the convergence of inference demand has only formed in the past year. In the second half of 2023, a small but beautiful domestic inference framework called LightLLM emerged, which is pure Python and implements CUDA kernels using Triton; some of Silicon Valley’s latest papers are also developed based on it.
With inference frameworks in place, many experimental works can unfold, such as quantization methods like GPTQ and AWQ, speculative sampling, Medusa, and strategies for increasing the computational memory ratio in the decoding phase, as well as batching scheduling strategies like FastGen and ChunkPrefill, and separating scheduling strategies like DistServe and Splitewise, along with more NPU support.
The demand for training and inference has surged, attracting many talents to the large model Infra field, leading to a wave of prosperity. As long as ordinary people have strong learning abilities, they have a chance to get on board, which is why I refer to this as the golden era.
2024-, Silver Era
In 2024, although large models are flourishing, production resources are concentrating towards the top, and the stratification of practitioners is intensifying, leading large model Infra into the silver era.
After the madness brought about by FOMO in 2023, people are beginning to calm down; some are exiting the field while others are expanding.
In the pre-training field, GPU resources are starting to concentrate at the top. There are only about six or seven remaining startups, some of which are banding together with cloud vendors. Within major companies, only one designated team is collecting all GPUs for pre-training. This is significantly different from the small model era, where each business team could train their own models and manage some GPU computing power. It’s like every province used to have its own army, but now the country only has a central army. Therefore, the demand for talent is lower than in traditional AI businesses, but the number of people wanting to enter the field has greatly increased, raising the entry barriers. If one does not join one of the dozen or so pre-training teams in China, they may have little chance to be involved in pre-training.
In the fine-tuning and inference fields, opportunities are also shrinking. Looking at the reasons for the contraction in both open-source and closed-source models, for closed-source models, fine-tuning and inference are still monopolized by pre-training teams, as the weights of models costing hundreds of millions cannot be leaked; only clients can bring data in for privatized deployment. For open-source models, although the number of open-source large models is increasing and their capabilities are improving, the demand for fine-tuning and training is decreasing. First, the difficulty of fine-tuning is actually very high; without training model experience, one cannot achieve the expected results, which is why RAG methods are flourishing, as they only require calling large model MaaS APIs. Second, inference is also highly competitive, with the best practices for integrating quantization, scheduling, and speculative sampling being quite challenging. Now, some trendy separation and mixed techniques require increasingly high engineering standards, making it difficult for a small team to compete with some free open-source MaaS APIs, which are optimized by professionals.
In summary, large models are a technology that is very decoupled from business, more like cloud vendors or chips. Traditional online and offline backend systems are closely related to business, and since many things are not standard parts, not achieving best practices still holds value. For large model Infra, having open-source frameworks as a baseline means that it’s either the best or nothing; if one cannot achieve the best, there is no value in existing. Thus, it can also be referenced against the chip industry, where resources will concentrate in the hands of a few giants, while most can only participate in downstream support, such as RAG, Agent, and so on.
Overall, in the silver era, the overall demand for large model Infra is increasing, but there is a Matthew effect: “To those who have, more will be given; but from those who do not have, even what they have will be taken away.” The good times do not last long, and the grand feast is hard to repeat. Those who have already boarded can feel the thrilling push, while those who have not can only watch helplessly.
However, the silver era, after all, is still a precious metal, and there are still many opportunities. The market for large model Infra is still expanding, with more chips and new algorithm innovations on the way. Those entering the field now, if they are robust enough, can still find a way aboard.
Some Suggestions for the Silver Era
It is often said that there is a seven-year cycle; in 2016, Alpha-Go opened a cycle with deep learning, and in 2022, ChatGPT opened a new cycle with large models.
Many people now enter the large model Infra field with expectations of excess returns, but such expectations need to be lowered in the silver era. Only a few will hit the cycle just right, as there are risks where there are differences, and only with risks can there be excess returns. The consensus on large models has long been solidified, and this field is bound to reach a supply-demand balance, becoming governed by market rules. It’s like when a vegetable vendor starts buying a certain stock; that stock is no longer profitable.
Large models are destined to profoundly change our world, but the trend of concentrating resources and information at the top is very frightening. On one hand, the core technology of large models is mastered by a small group of people, such as OpenAI. On the other hand, facing huge information and computational disparities, ordinary people are unable to participate in the development system of large models. Just as AI will eventually replace ride-hailing drivers, it will also one day replace programmers. How to find one’s place in a world where productivity has advanced, and not become a second-class citizen in the AGI world, is the source of anxiety for each of us.
To alleviate societal fears of AI and to rationally plan a future where AI coexists harmoniously with society, there must be regulatory oversight of the giants, as well as opportunities for more people to understand large model technology equally. There are still many people striving for the latter, spreading large model technology through open-source code and published papers. For those looking to enter the field, leveraging open-source resources can help keep oneself aligned with the industry. There are also many unresolved technical challenges waiting for you to tackle. Additionally, directions such as Agents, multimodality, and embodied intelligence are burgeoning, providing an opportunity to lay the groundwork for the next wave of trends.
As a practitioner in large model Infra, the silver era requires honing fundamental skills. In 2023, many people showcased their value through information asymmetry, with knowledge that others did not possess, which required time to explore. Many were willing to pay for knowledge due to intense competition. This year, such opportunities will greatly diminish, and the competition will be based on true skills: the ability to quickly follow new technologies, independently handle complex large systems, and possess a broader technical vision and the ability to communicate with other collaborators. This requires knowledge of Infra as well as understanding algorithms and cloud computing, making traditional engineering qualities especially important.
I have always hoped to contribute to the democratization of AI; my GitHub signature is “Democratizing LLM”. Over the past year, my shares on Zhihu have focused on interpreting cutting-edge papers in large model Infra. As we enter the silver era, I deeply feel that the low-hanging fruit has almost been picked clean, and the papers are not as exciting as in the previous two years. Previous papers often defined key issues in LLM, such as ZeRO, ORCA, and Paged Attention, whereas current papers rarely present such enlightening content. I plan to systematically share foundational knowledge in the large model Infra field in the future, aiming to reveal the universal principles behind it, so that students with no AI background or undergraduate students with backend development experience can easily understand. This idea is still immature, and I welcome any suggestions.

Scan the QR code to add the assistant on WeChat
About Us
