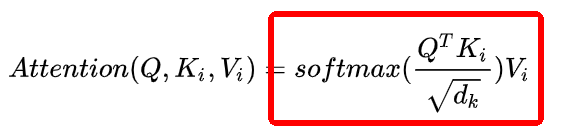Note that here, query, key, and value are just names for operations (linear transformations), and the actual Q/K/V are their respective outputs.
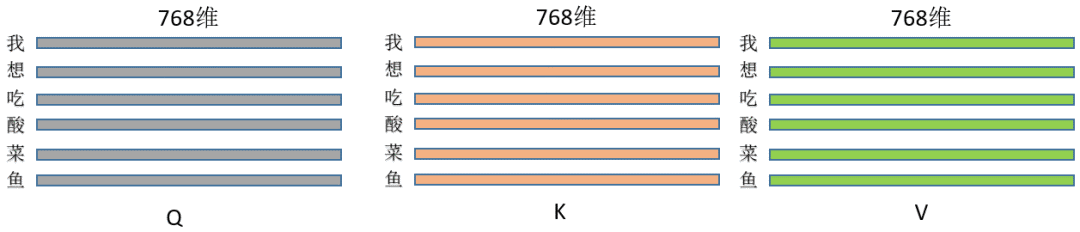
2. Suppose the input to the three operations is the same matrix (let’s not worry about why the input is the same matrix for now), let’s assume it is a sentence of length L, and each token’s feature dimension is 768, then the input is (L, 768), where each row represents a character, like this:
Multiplying by the above three operations gives Q/K/V, (L, 768)*(768,768) = (L,768), so the dimensions actually remain unchanged, and at this moment, Q/K/V are:
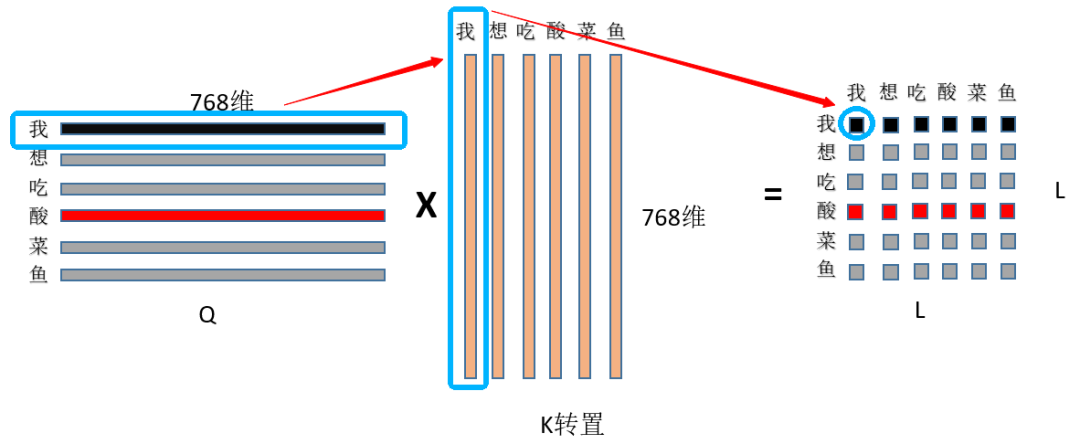
① First, multiply the Q and K matrices, (L, 768)*(L, 768) transposed = (L,L), as shown in the figure:
First, use the first row of Q, which is the 768 features of the character “I”, to perform a dot product with the 768 features of the character “I” in K, obtaining the value at position (0,0). This value represents the attention weight of “I” towards “I” in the phrase “I want to eat sauerkraut fish”. It is evident that the output’s first row represents the attention weights of “I” towards every character in “I want to eat sauerkraut fish”; the entire result naturally represents the attention weights of every character in “I want to eat sauerkraut fish” towards other characters (including itself).~② Then, divide by the square root of dim, where dim is 768. Why do we divide by this value? This is mainly to reduce the range of the dot product and ensure the stability of the softmax gradient. For a detailed derivation, refer to here: Lian Sheng thirty-two: Why the dot-product operation in Self-attention needs to be scaled (https://zhuanlan.zhihu.com/p/149903065). As for why we need softmax, one explanation is to ensure the non-negativity of the attention weights while also increasing non-linearity. Some works have experimented with removing softmax, such as PaperWeekly: Exploring Linear Attention: Does Attention Need a Softmax? (https://zhuanlan.zhihu.com/p/157490738).
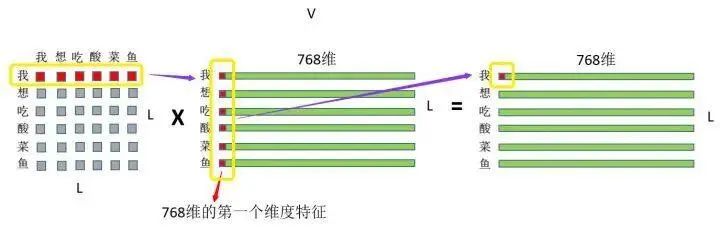
③ Then, multiply the earlier attention weight with the V matrix, as shown in the figure:
Attention weight x VALUE matrix = final resultFirst, the attention weight of the character “I” towards each character in the phrase “I want to eat sauerkraut fish” is multiplied by the first-dimensional feature of each character in V, followed by summing them up. This process is essentially equivalent to performing a weighted sum of each character’s features based on their weights. Then, the attention weight of “I” towards each character in “I want to eat sauerkraut fish” is multiplied by the second-dimensional features of each character in V, and so forth. In the end, we also obtain a result matrix of (L,768), which maintains consistency with the input.~
The entire process can be easily visualized on draft paper with simple matrix multiplication, making it clear at a glance. Finally, here is the code:
4. Why is it called self attention network? Because we can see that Q/K/V are all computed from the input of the same sentence, which means each character in the sentence allocates weights to other characters (including itself). If it were not self-attention, simply put, Q would come from sentence A, while K and V would come from sentence B.~5. Note that in K/V, if you simultaneously swap any two characters, it will not affect the final result. Why? You can sketch the matrix multiplication on paper to see; this means that the attention mechanism does not have positional information, unlike CNN/RNN/LSTM. This is also why positional embedding needs to be introduced.02
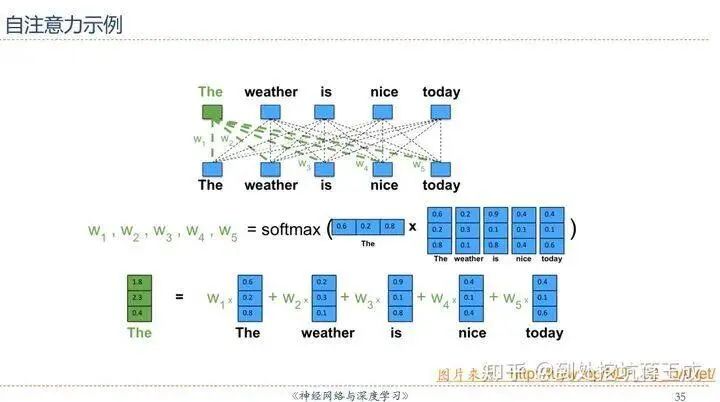
Actually, you can intuitively understand this by directly using a diagram from Professor Qiu Xipeng’s PPT – assuming D is the content of the input sequence, completely ignoring the linear transformation, we can approximate Q=K=V=D (hence the name Self-Attention, as it is the input sequence’s attention to itself), so the representation of each element in the sequence after Self-Attention can be shown as follows:In other words, the representation of the word ‘The’ is actually the result of a weighted sum of the entire sequence – where do the weights come from? They are obtained through the dot product followed by Softmax – here Softmax(QK) reflects the process of obtaining the weights. We know that the value of the vector dot product can represent the similarity between words, and here, the ‘entire sequence’ includes the word ‘The’ itself (again emphasizing that this is Self-Attention), so the final output representation of the word mainly contains its own representation and the representations of similar words, while the representations of irrelevant words will have comparatively low weights.03
Answer 3: Author – Qu Liang
First, here is a link: Zhang Junlin: Attention Models in Deep Learning (2017 Edition) (https://zhuanlan.zhihu.com/p/37601161). This is one of the most thorough explanations of Attention I have read.Q (Query) represents the query value, corresponding to the H(t-1) state of the Decoder. Here, it is important to correctly understand H(t-1). To decode the output at time t, you must input the previous hidden state computed at time t-1 into the Decoder. So, the so-called query is to take the H(t-1) in the Decoder and compare it with the hidden states at each time in the Encoder [H(1), H(2), …, H(T)] (which are the various Keys) to calculate similarity (corresponding to various energy functions in the literature). The result obtained is normalized using Softmax, and this calculated weight is the attention mechanism weight. In translation tasks, Key and Value are equal. In the implementation source code of Transformer, the initial values of Key and Value are also equal. With this weight, you can perform a weighted sum on Value, and the resulting new vector is the semantic vector with attention mechanism, which weighs the relationship between Target and Source tokens, thereby achieving the association with the tokens in Source that are truly significant during decoding output.Let me add a few more words: First, the Attention mechanism originated from the Encoder-Decoder architecture and was initially used to complete translation tasks in the NLP field. Thus, the input-output relationship is very clear: Source-Target correspondence. The classic Seq2Seq structure generates a semantic vector (Context vector) from the Encoder that does not change after that, and this semantic vector is sent to the Decoder for decoding output. The biggest problem with this method is whether we want this semantic vector to remain unchanged or whether it would be better for it to adjust dynamically with the Decoder to associate certain tokens in the Target with the truly ‘decisive’ tokens in the Source.This is the reason for the Attention mechanism. Ultimately, the Attention mechanism aims to generate a dynamically changing semantic vector to aid in decoding output. The new Self-Attention is designed to address the relationships between tokens within Target and Source. In the Transformer, these two attention mechanisms are organically unified, releasing extraordinary potential.