
Follow the WeChat public account “ML_NLP“

Recently, I need to start using Transformers for some tasks, so I specifically recorded related knowledge points to build a relevant and complete knowledge structure system,
The following are the articles to be written, this article is the fourth in this series:
-
Transformer: The Pinnacle of Attention -
GPT-1 & 2: Miracles Brought by Pre-training + Fine-tuning -
Bert: Bidirectional Pre-training + Fine-tuning -
Bert and Model Compression (To Be Continued) -
ALBert -
MobileBert -
More -
Bert and AutoML (To Be Continued) -
Linear Transformer (To Be Continued) -
Bert Variants -
Roberta: Fine-Tuning Bert (This Article) -
Reformer (To Be Continued) -
Longformer (To Be Continued) -
T5 (To Be Continued) -
More To Be Continued -
GPT-3 -
More To Be Continued
Overall
After Bert was released, it quickly ignited the NLP field, leading to many improvements targeting the model. However, Roberta demonstrates that fine-tuning the original Bert model can lead to significant enhancements.
Roberta stands for Robustly Optimized BERT Approach.
The term “Robustly” is great, it conveys both “robust” and “physical strength”. Roberta is an experiment-based paper, implying some physical labor, yet the results are very robust and reliable.
Let’s review some details in Bert:
-
In terms of input, Bert’s input consists of two segments, where each segment can contain multiple sentences, and the two segments are concatenated with [SEP]. -
In terms of model structure, it uses Transformers, which is consistent with Roberta. -
In terms of learning objectives, it uses two objectives: -
Masked Language Model (MLM): 15% of tokens are masked, of those 15%, 80% are replaced with the [Mask] token, 10% are randomly replaced with other tokens, and 10% remain unchanged. -
Next Sentence Prediction: Determines whether the second segment is a continuation of the first. 50% are sampled as yes and 50% as no. -
Optimizations: -
Adam, beta1=0.9, beta2=0.999, epsilon=1e-6, L2 weight decay=0.01 -
Learning rate increases to 1e-4 in the first 10,000 steps, then linearly decreases. -
Dropout=0.1 -
GELU activation function -
Training steps: 1M -
Mini-batch: 256 -
Input length: 512 -
Data -
BookCorpus + English Wiki = 16GB
Roberta fine-tunes Bert in the following aspects:
-
Masking Strategy – Static vs Dynamic -
Model Input Format and Next Sentence Prediction -
Large Batch -
Input Encoding -
Larger Corpora and Longer Training Steps
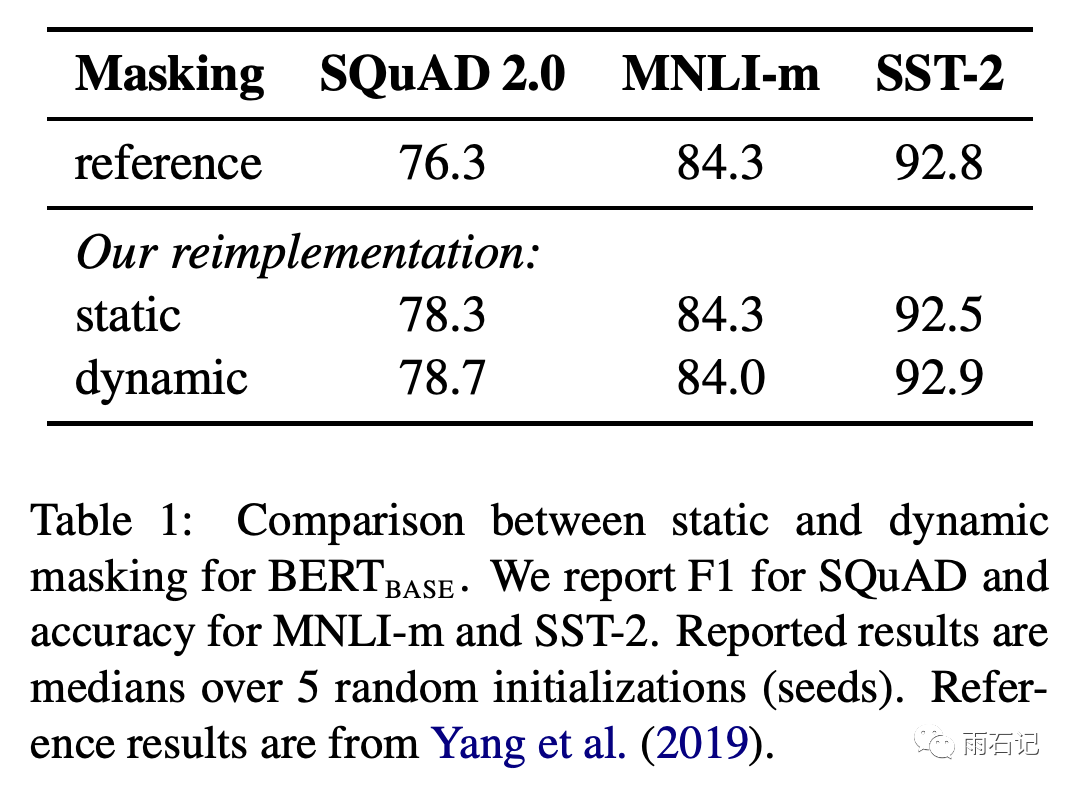
Masking Strategy – Static vs Dynamic
In the original Bert, the Mask tokens are statically marked in the training data and remain unchanged during training, which is a static approach.
Roberta attempts a dynamic approach; although it is implemented statically, the data is duplicated 10 times, with each copy using a different mask. This results in 10 different masked datasets.
From the results, it can be seen that dynamic masking brings a slight improvement.
Model Input Format and Next Sentence Prediction
Bert’s model input consists of two segments, which raises two questions:
-
Are two segments necessary? -
Why segments instead of single sentences?
Thus, four experiments were set up:
-
Segment-Pair + NSP -
Sentence-Pair + NSP: Using only sentences reduces the input length, so to keep the number of tokens seen in each training step similar, the batch size is increased. -
Full-Sentence: Each sample is continuously sampled from a document; if it crosses document boundaries, a [SEP] token is added, with no NSP loss. -
Doc-Sentence: Similar to Full-Sentence, but does not cross document boundaries.
From the experimental results, it can be seen that switching to Sentence-Pair incurs a significant loss. It is speculated that this is because it cannot capture long-term dependencies.
Additionally, Full-Sentence and Doc-Sentence provide slight improvements, indicating that NSP is not essential.
This is contrary to the conclusions of the ablation experiments in Bert, but please note that their inputs are different; the original Bert uses Segment-Pair with a 50%/50% sampling, while Full/Doc-Sentence samples sentences continuously from the article.
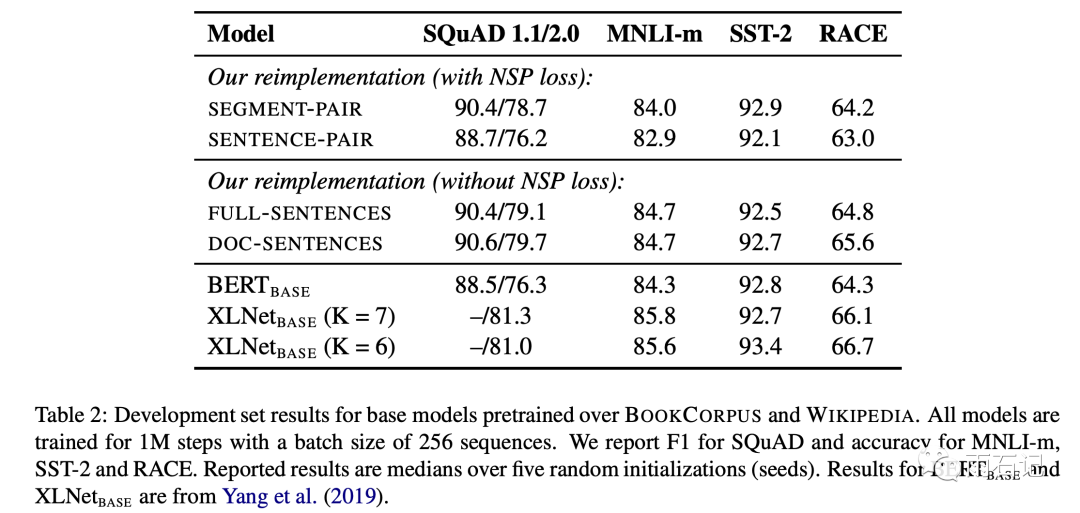
Since Doc-Sentence leads to different batch sizes (because the number of tokens seen in each batch must be similar), Roberta uses the Full-Sentence mode.
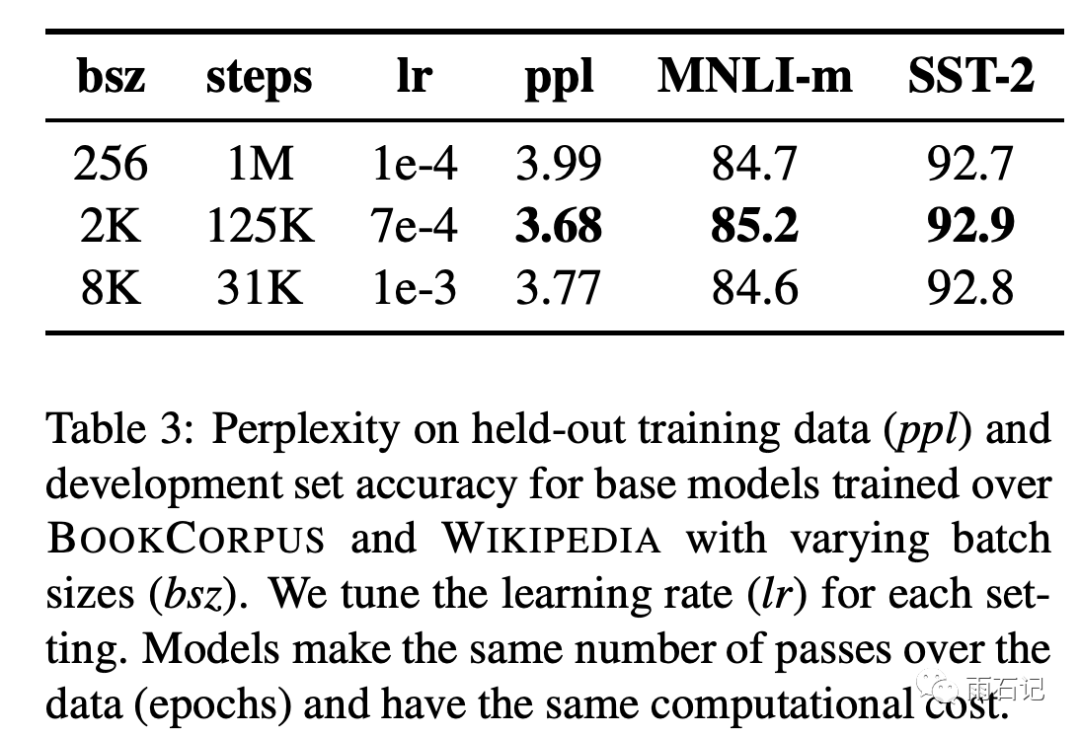
Large-Batch
Increasing batch size is increasingly shown to accelerate convergence and improve final results. In the original Bert, batch_size=256, trained for 1M steps.
In Roberta, two settings were experimented:
-
batch_size=2k, trained for 125k steps. -
batch_size=8k, trained for 31k steps.
The results show that batch_size=2k yields the best results.
Input Encoding
Both GPT and Bert use BPE encoding, which stands for Byte-Pair Encoding, a representation between characters and words. For example, “hello” might be broken down into “he”, “ll”, “o”, where the BPE dictionary is learned from the corpus.
The original Bert uses a BPE dictionary of 30k, while Roberta increases it to 50k, resulting in an additional 15M/20M parameters compared to Bertbase and Bertlarge.
Increasing Corpora and Training Steps
Increasing the corpus and training steps can lead to significant improvements.
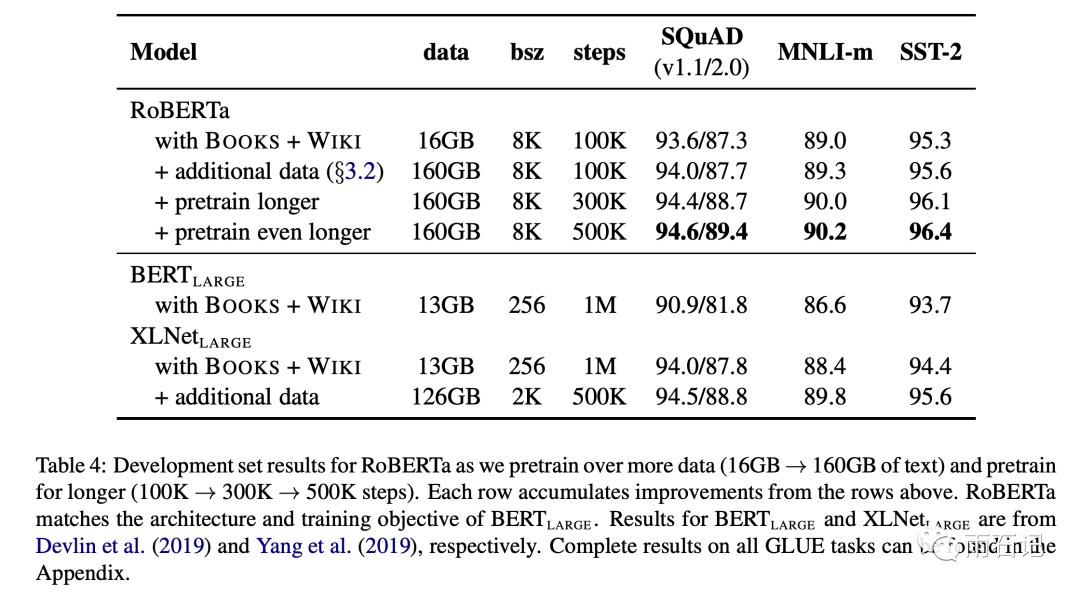
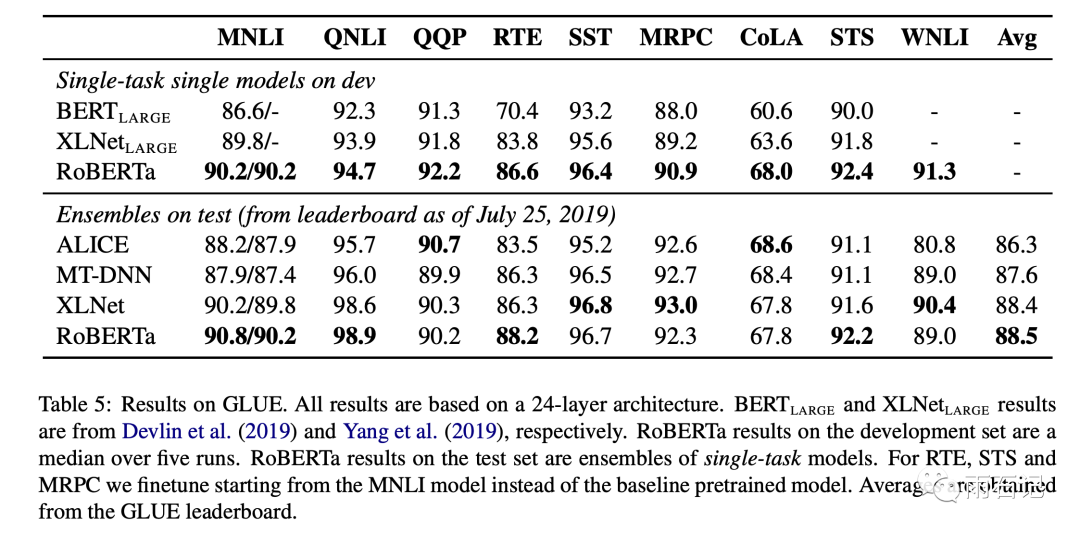
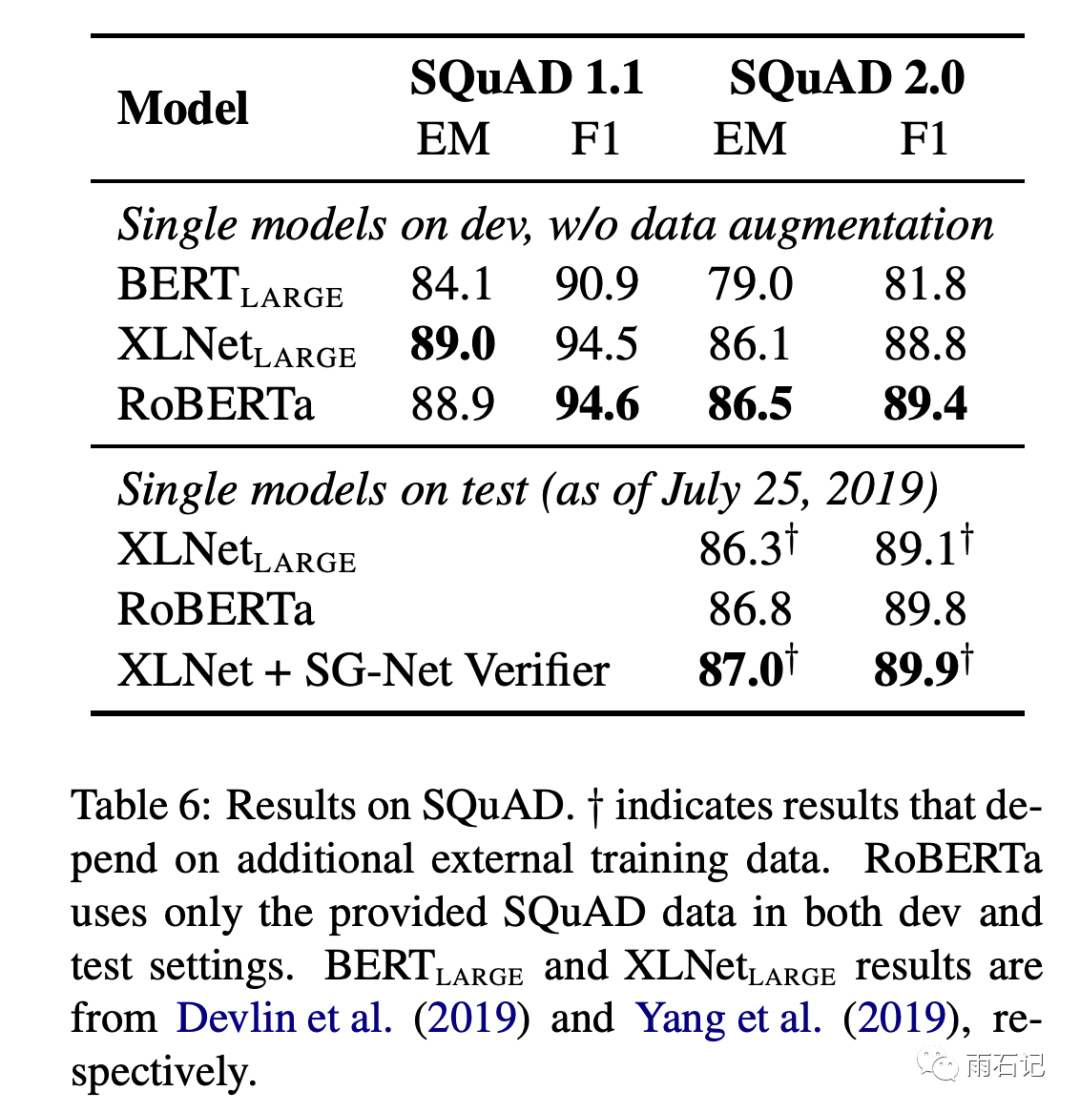
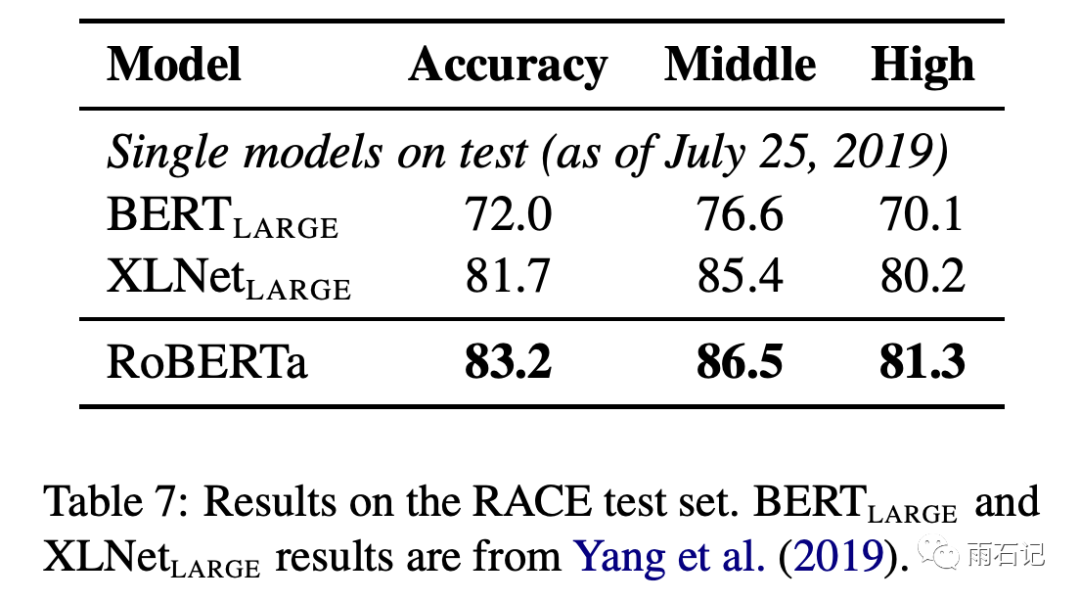
Roberta
is the sum of all the improvements above. It can be seen that there are significant enhancements across various tasks. Roberta’s training takes about one day on 1024 V100 GPUs.
Thoughts and Summary
From the various experimental results above, the following conclusions can be drawn:
-
NSP is not a necessary loss -
The masking method, though not optimal, is close to it. -
Increasing batch size and training data can lead to significant improvements.
Due to Roberta’s outstanding performance, many applications are now fine-tuned based on Roberta rather than the original Bert.
Thinking critically and asking questions is a good virtue of engineers.
Questions are as follows:
-
Is there any possibility of further improvement by continuing to increase the dataset? What is the distribution of dataset size versus the resulting improvement? -
Regardless of whether it is Bert or Roberta, the training time is long; how can it be optimized?
References
-
[1]. Liu, Yinhan, et al. “Roberta: A robustly optimized bert pretraining approach.” arXiv preprint arXiv:1907.11692 (2019).
Repository address sharing:
Reply "code" in the background of the Machine Learning Algorithms and Natural Language Processing public account to obtain 195 NAACL + 295 ACL2019 papers with open-source code. The open-source address is as follows: https://github.com/yizhen20133868/NLP-Conferences-Code
Heavyweight! The Machine Learning Algorithms and Natural Language Processing WeChat group has been officially established! There are a lot of resources in the group, welcome everyone to join and learn!
Extra bonus resources! Qiu Xipeng's deep learning and neural networks, official PyTorch Chinese tutorial, data analysis using Python, machine learning notes, official pandas documentation in Chinese, effective java (Chinese version), and 20 other welfare resources.
How to obtain: After joining the group, click on the group announcement to get the download link. Please modify the remarks when adding, e.g. [School/Company + Name + Direction]. For example - Harbin Institute of Technology + Zhang San + Dialogue System. The host, please consciously avoid. Thank you!
Recommended reading:
Review of Open-Domain Knowledge Base Question Answering Research
Automatically Train Your Deep Neural Network Using PyTorch Lightning
Collection of Common Code Snippets in PyTorch