

Table of Contents:
A Brief Review of ELMo and Transformer DAE and Masked Language Model Detailed Explanation of BERT Model Different Training Methods of BERT Model How to Apply BERT Model in Real Projects How to Slim Down BERT Problems with BERT
1. A Brief Review of ELMo and Transformer
1.1 Polysemy

1.2 ELMo
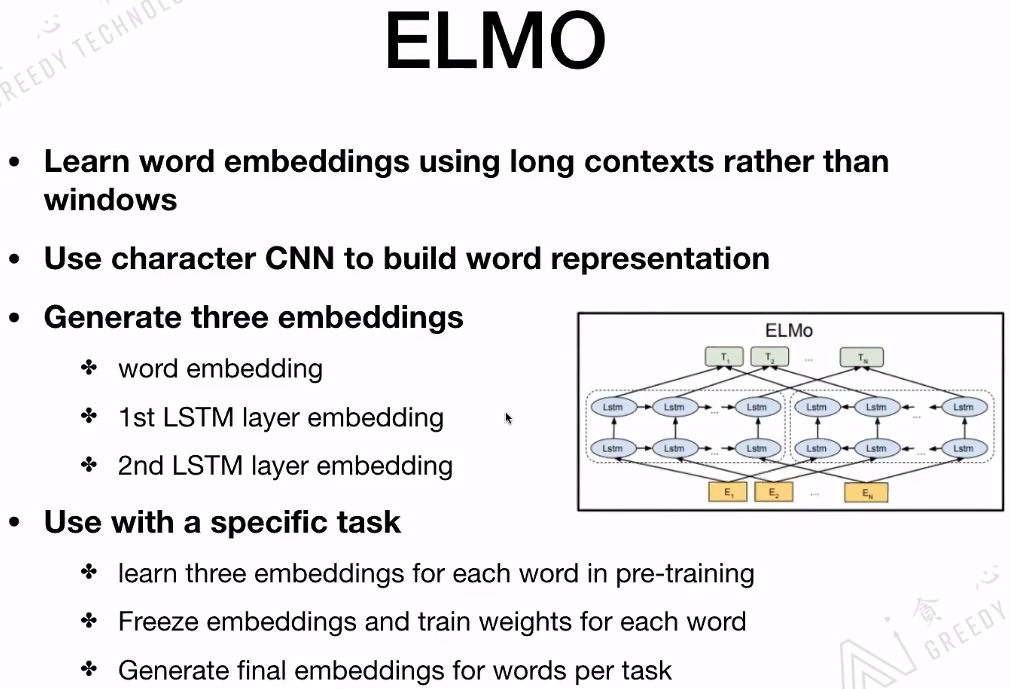
ELMo is a language model primarily designed to predict the next word given a context of text. One of the most important features of ELMo is that it partially solves the issue of polysemy, although it does not completely resolve it! It provides a great solution for handling polysemy. Unlike the static embeddings provided by word2vec and glove, which remain unchanged once trained, ELMo considers more contextual information and provides three embeddings for each word. These three embeddings can be seen as three distinct features of a word, with different weights assigned for different tasks, ultimately combining these embeddings through vector averaging to form the final word embedding.

ELMo utilizes long context information rather than the window size context information used by other models. It employs Bi-LSTM, and if ELMo were replaced with Transformer, it would be structurally similar to BERT.
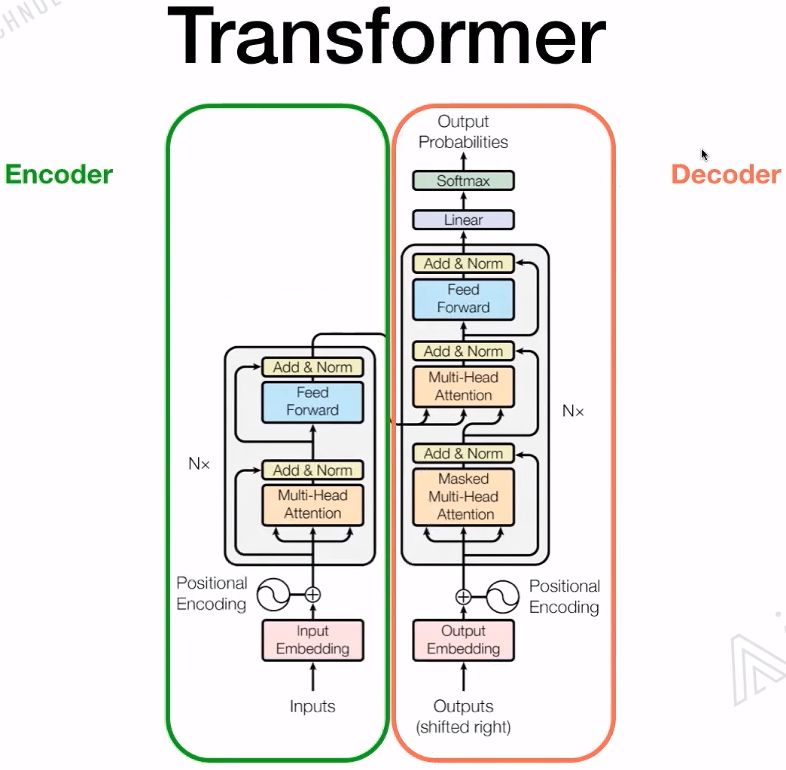
1.3 Transformer
Differences between LSTM and Transformer:
-
The training of RNN-based LSTM is iterative; the current character must enter the LSTM unit before the next character can be inputted, making it a serial process. -
Transformer training is parallel, allowing all characters to be trained simultaneously, greatly enhancing computational efficiency. Additionally, Transformer incorporates positional embeddings to help the model understand the order of language. Using Self-Attention and fully connected layers are fundamental structures of Transformer.
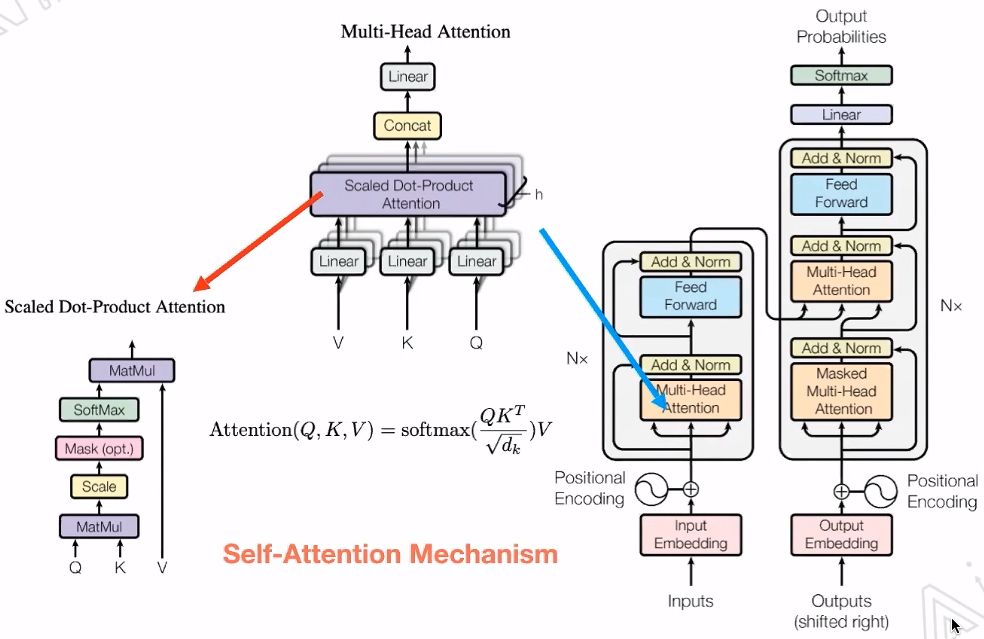
The most important aspect of Transformer is Multi-Head Attention.
The five core components of the Encoder in Transformer are shown in the figure below:
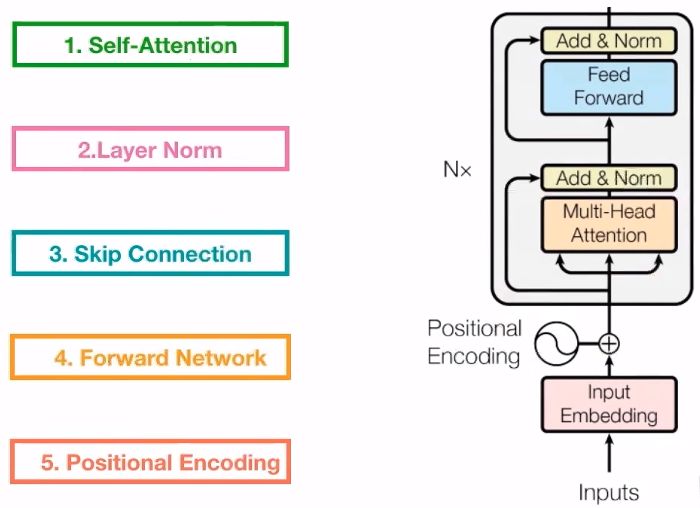
Skip connections: They help prevent the vanishing gradient problem during backpropagation.
2. DAE and Masked Language Model
2.1 What are DAE and Masked Language Model
With the emergence of some peculiar high-dimensional data, such as images and speech, traditional statistical and machine learning methods have faced unprecedented challenges. The high dimensionality, monotonicity of data, and widespread noise distribution make traditional feature engineering ineffective.
To address high-dimensional issues, linear learning methods like PCA were developed, which indeed have impeccable mathematical theories but only perform well on linear data. Therefore, seeking simple, automatic, and intelligent feature extraction methods remains a key focus of machine learning research.
As a result, CNNs have taken a different approach by effectively extracting features from signal data through convolution and down-sampling. But what about general non-signal data?
Researchers proposed AutoEncoders based on the fact that the original input (denoted as ) is weighted ( ), mapped (Sigmoid) to obtain , and then the is reverse weighted and mapped back to become . The network structure is illustrated below:
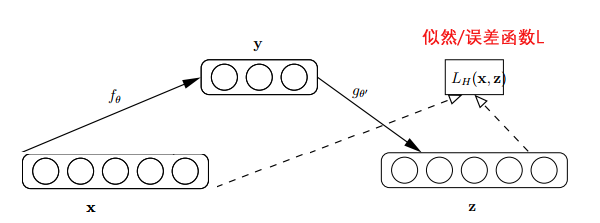
The process of AutoEncoder is quite interesting; first, it does not use data labels to compute errors for parameter updates, making it unsupervised learning. Secondly, it employs a double hidden layer similar to a neural network to crudely extract sample features.
To alleviate the classic AutoEncoder’s tendency to overfit, one approach is to introduce random noise into the input, leading Vincent to propose a modified version of AutoEncoder called Denoising AutoEncoder (DAE) in his 2008 paper “Extracting and Composing Robust Features with Denoising Autoencoders”.
How can we make features robust? By erasing the original input matrix with a certain probability distribution (usually a binomial distribution), meaning each value is randomly set to 0, which results in some features of the original data being lost. Using this corrupted data to compute , calculating , and iterating the error with the original allows the network to learn from this corrupted data. The network structure is illustrated below:
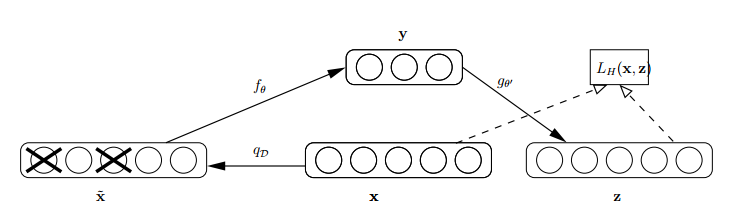
This corrupted data is very useful for two reasons:
-
The weights trained on corrupted data show less noise compared to those trained on non-corrupted data. This is why it is called denoising. The reasoning is straightforward: because some input noise is inadvertently erased during the erasing process. -
The corrupted data somewhat alleviates the gap between training and testing data. Since part of the data is erased, this corrupted data is somewhat closer to the testing data (there are similarities and differences between training and testing data, and we require similarities). Thus, the robustness of the weights trained will be improved.
2.2 The Relationship between BERT, DAE, and Masked Language Model
BERT is a model built on the Transformer Encoder, and its entire architecture is based on DAE (Denoising Autoencoder), referred to as Masked Language Model (MLM) in the BERT paper. MLM is not strictly a language model because the entire training process does not utilize the language model approach. BERT randomly replaces some words with MASK tokens and then predicts the masked word; the process is, in fact, the DAE process. BERT has two main trained models: BERT-Small and BERT-Large, with BERT-Large using a 12-layer Encoder structure. The entire model has a substantial number of parameters.
Although BERT performs well, it also has some issues. For instance, BERT cannot be used to generate data. Since BERT relies on the DAE structure for training, it lacks the generating capability that models trained using language models possess. Previous methods like NNLM and ELMo were generated based on language models, allowing trained models to generate sentences and texts. However, the methodology behind these generative models also has issues, as understanding a word’s meaning in context considers only its preceding context and not the following context!
BERT was proposed in 2018, causing an explosive reaction as it set numerous records in terms of performance, effectively igniting rapid development in this field.
3. Detailed Explanation of BERT Model
3.1 Introduction to BERT
Bidirection: The entire model structure of BERT is similar to ELMo, being bidirectional.
Encoder: It is a type of encoder, and BERT only utilizes the Encoder part of Transformer.
Representation: It represents words.
Transformer: Transformer is the core internal element of BERT.
The basic idea of BERT is similar to Word2Vec and CBOW, both predicting the next word given the context. The structure of BERT is similar to ELMo, both being bidirectional. The first to utilize Transformer was not BERT but GPT.
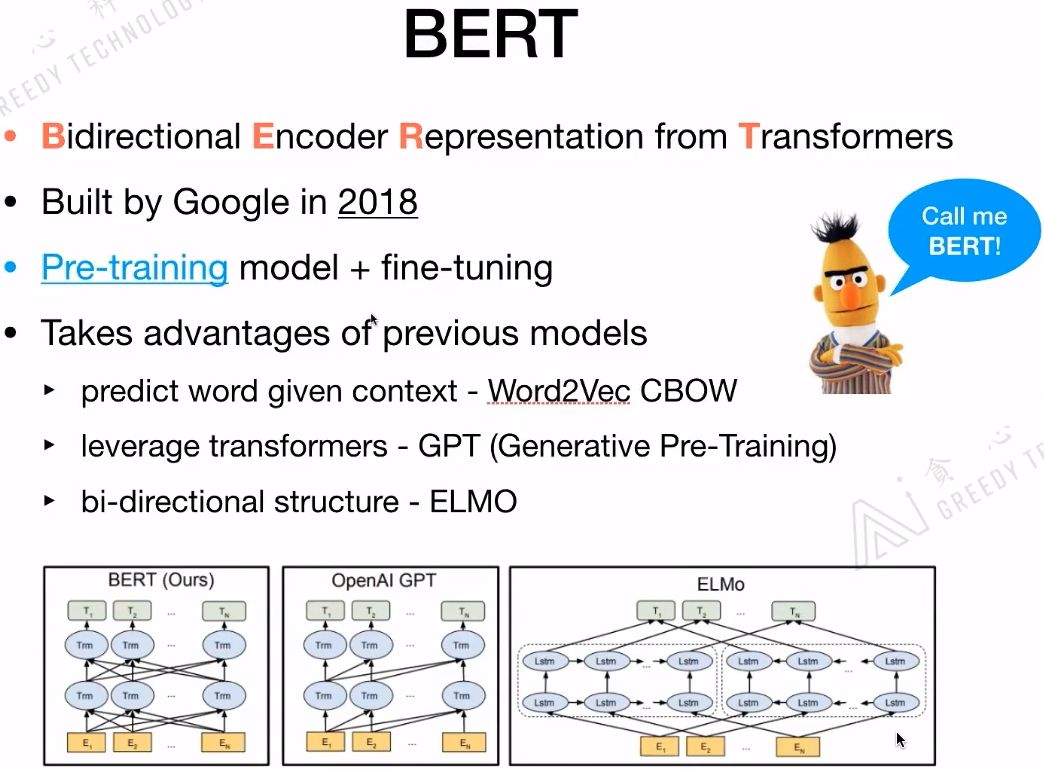
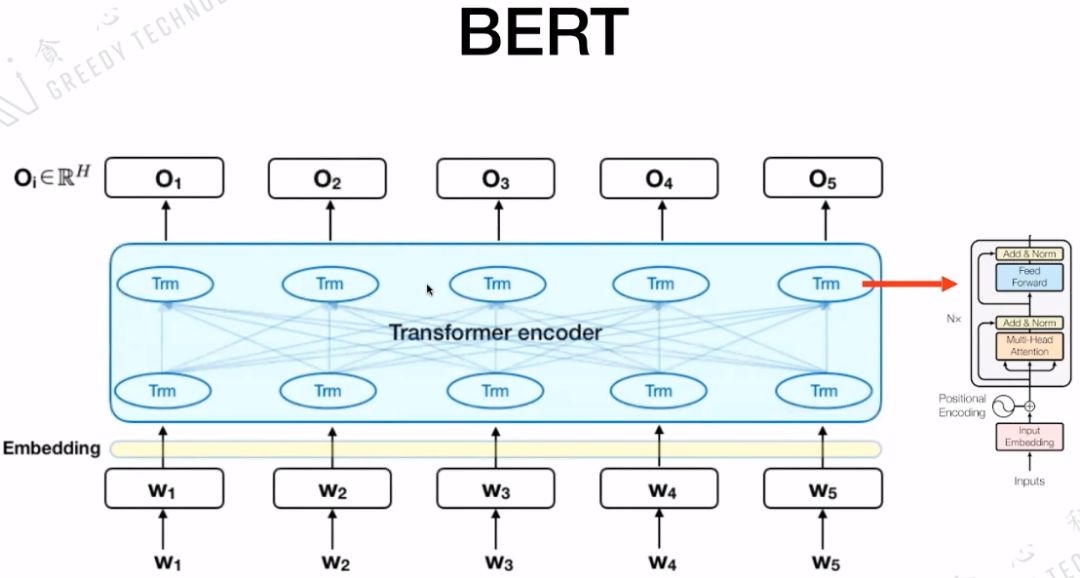
3.2 BERT’s Model Structure
The model structure of BERT is Seq2Seq, with the core being the Transformer encoder, which also contains the five important parts mentioned earlier.
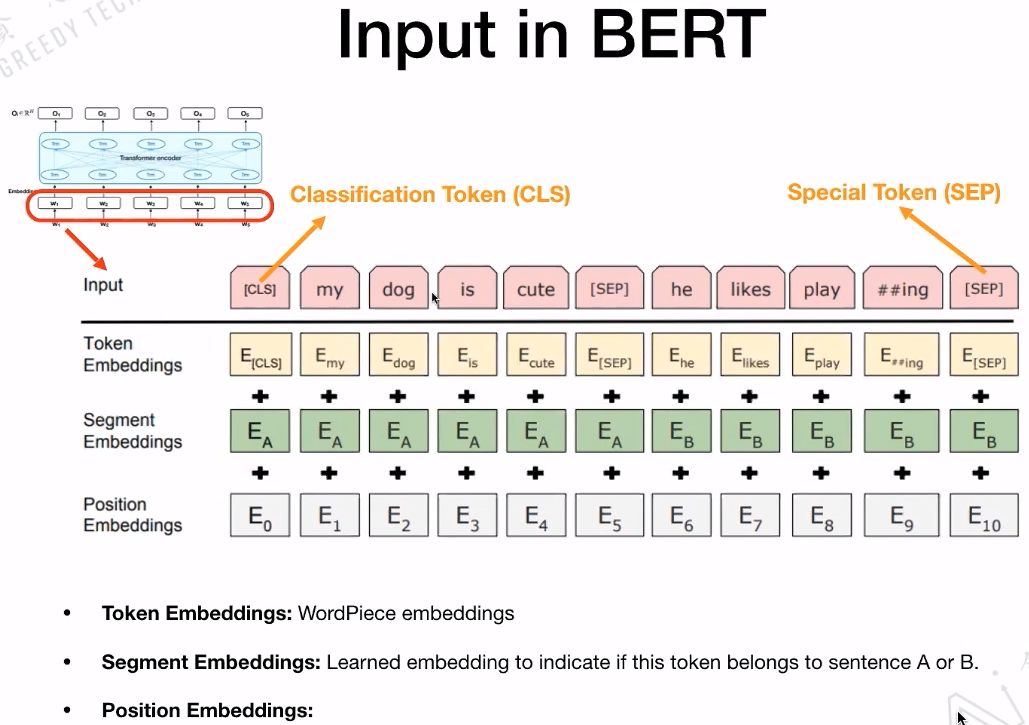
3.3 BERT’s Input
Next, let’s look at BERT’s input, which consists of three parts: Token Embeddings, Segment Embeddings, and Position Embeddings. These three parts can be learned throughout the process.
Introduction to Special Characters:
-
CLS, which stands for Classification Token (CLS), is used for classification tasks. Why is the “CLS” token placed first? Because BERT is a parallel structure, the “CLS” can also be placed at the end or in the middle, but placing it first is more convenient.
-
SEP, which stands for Special Token (SEP), is used to distinguish between two sentences, as BERT typically inputs two sentences during training. As shown in the image below, SEP is the token that distinguishes between two sentences.
-
Token Embedding: This is the embedding for each input word.
-
Segment Embedding: Marks whether the input token belongs to sentence A or sentence B.
-
Position Embedding: Specifically marks the position of each token.
Finally, the corresponding positions of these three embeddings are summed up to form the final input embedding for BERT.
4. Different Training Methods of BERT Model
4.1 BERT’s Pre-training
How does BERT perform pre-training? There are two tasks: one is the Masked Language Model (MLM); the other is Next Sentence Prediction (NSP). During BERT’s training, these two tasks are trained simultaneously. Therefore, BERT’s loss function combines the loss functions of these two tasks, resulting in a multi-task training.
BERT officially provides two versions of the BERT model: one is the BERT BASE version, and the other is the BERT LARGE version. The BASE version has 12 layers of Transformer, with a hidden layer embedding dimension of 768, 12 heads, and a total parameter count of about 110 million. The LARGE version has 24 layers of Transformer, with a hidden layer embedding dimension of 1024, 16 heads, and a total parameter count of about 340 million.

4.2 BERT-Masked Language Model
What is the Masked Language Model? Its inspiration comes from Cloze tests. Specifically in BERT, 15% of the tokens are masked. This masking of 15% of the tokens is divided into three situations: first, 80% of the characters are replaced with the character “MASK”; second, 10% of the characters are replaced with other characters; third, 10% of the characters remain unchanged. Finally, when calculating the loss, only the masked tokens are considered, which means that 15% of the tokens are masked.

4.3 BERT-Next Sentence Prediction
Next Sentence Prediction focuses more on the relationship between two sentences. Compared to the Masked Language Model task, Next Sentence Prediction is somewhat simpler.

4.4 BERT-Training Tips

4.5 BERT-What it Looks Like?
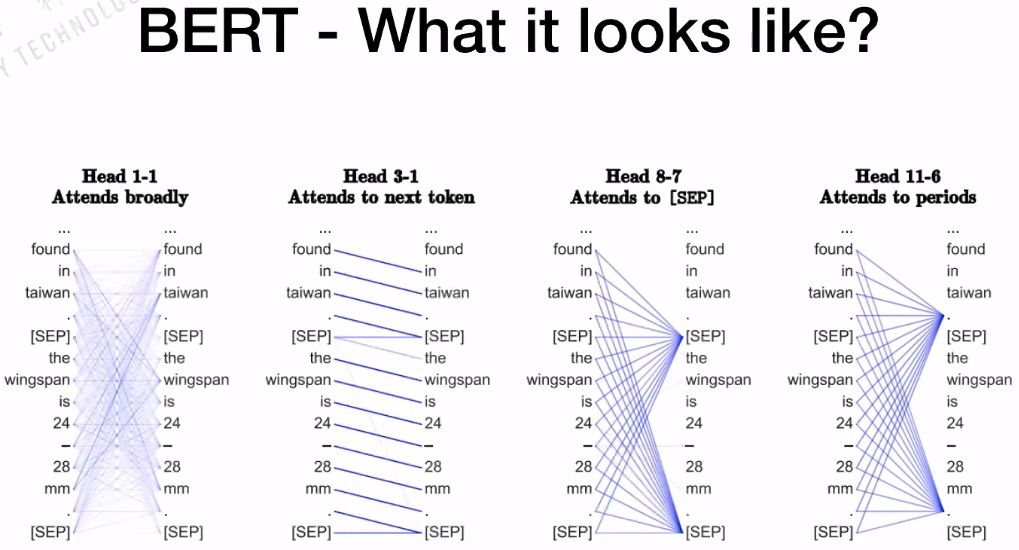
After training BERT, let’s examine the internal mechanisms of BERT. The BASE version of BERT has 12 heads; does each head have the same function? As shown in the figure, the first head has very dense connections, attending broadly; the third head focuses more on the next word; the eighth head focuses on the sentence separator (SEP); and the eleventh head focuses on the sentence period.
Thus, each head represents different meanings, which is also the reason for BERT’s power. The Multi-Headed structure of BERT can capture different features, including global and local features.
The BASE version of BERT has 12 layers of Transformer; in the figure below, each color represents a layer of Transformer, and similar colors tend to cluster closely. Heads from the same layer are very close to each other!

To summarize the two figures above, for a BERT model with 12 layers and 12 heads, the heads’ functions are similar for each layer; however, the attention demonstrated within each head is entirely different.
4.6 BERT-What it Learns?
In the paper “Tenney I, Das D, Pavlick E. Bert Rediscovers the Classical NLP Pipeline[J]. arXiv preprint arXiv:1905.05950, 2019,” the contributions of each layer of the Transformer in the BERT LARGE version to different NLP tasks were studied.

As seen in the figure, the longer the blue part, the greater the contribution of that layer of Transformer to the NLP task. In the Coref. task, layers 18, 19, and 20 play a more significant role.
4.7 BERT-Multilingual Version

Related GitHub address: https://github.com/google-research/bert/blob/master/multilingual.md
5. How to Apply BERT Model in Real Projects
With the BERT model trained, what NLP tasks can we perform using the BERT model?
-
Classification -
Questions & Answering -
Named Entity Recognition (NER) -
Chat Bot (Intent Classification & Slot Filling) -
Reading Comprehension -
Sentiment Analysis -
Reference Resolution -
Fact Checking -
etc.
5.1 Classification
BERT paper mentions:【1】Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.

5.2 Questions & Answering
BERT paper mentions:【1】Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
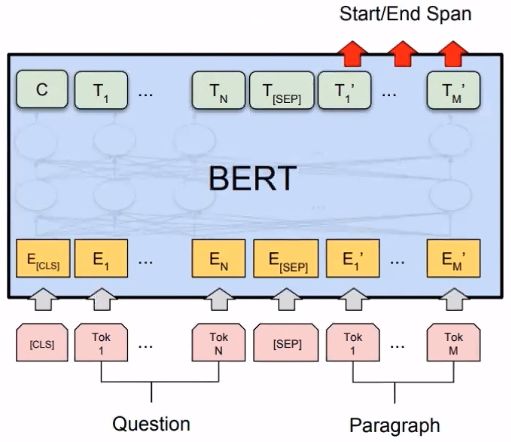
Let’s take a look at how BERT should be used in a QA system:
For specific information, please refer to: Innovations in the Era of BERT (Application Edition): Progress of BERT in Various Fields of NLP – Zhang Junlin’s article – Zhihu https://zhuanlan.zhihu.com/p/68446772
5.3 Named Entity Recognition (NER)
BERT paper mentions:【1】Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
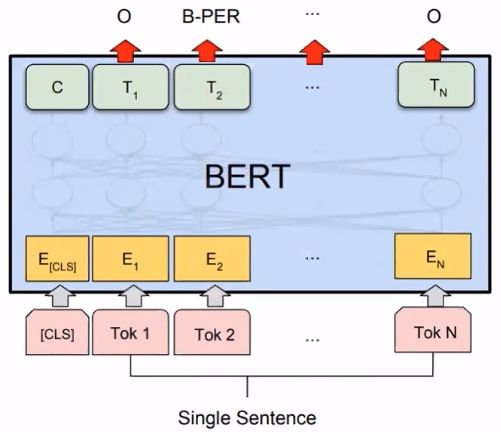
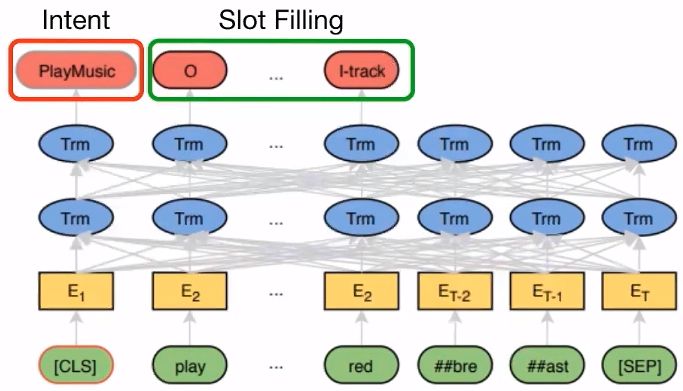
5.4 Chat Bot (Intent Classification & Slot Filling)
Related paper:【1】Chen Q, Zhuo Z, Wang W. Bert for joint intent classification and slot filling[J]. arXiv preprint arXiv:1902.10909, 2019.
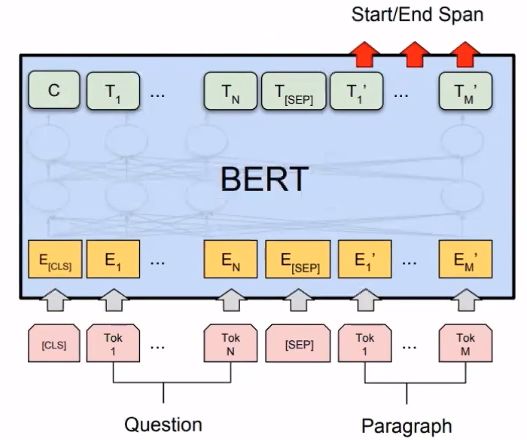
5.5 Reading Comprehension
6. How to Slim Down BERT
BERT performs exceptionally well, but it has too many parameters. Can we compress the BERT model for easier use? Common methods for model compression include:
-
Pruning – remove parts from the model -
Quantization – convert Double to Int32 -
Distillation – teach a small model
6.1 Knowledge Distillation
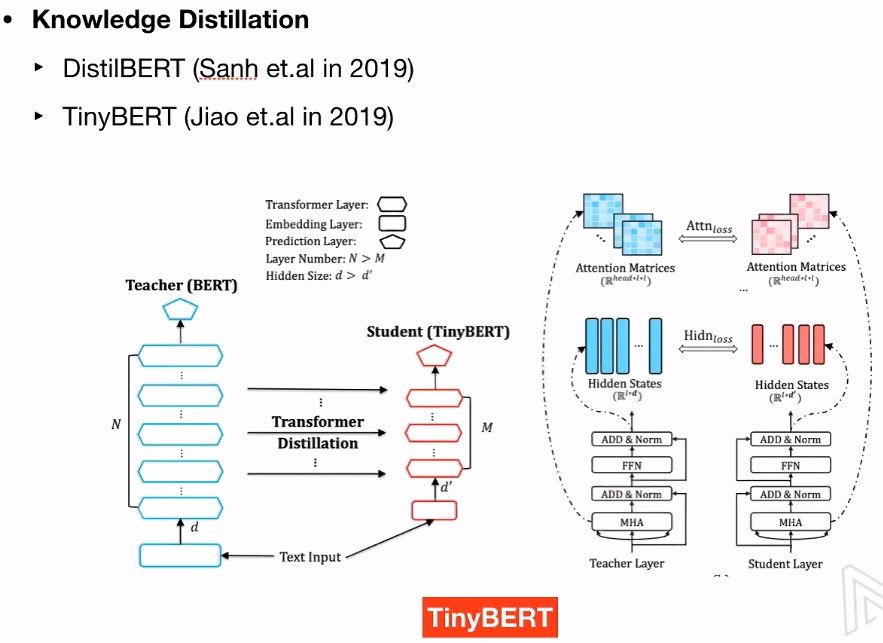
7. Problems with BERT
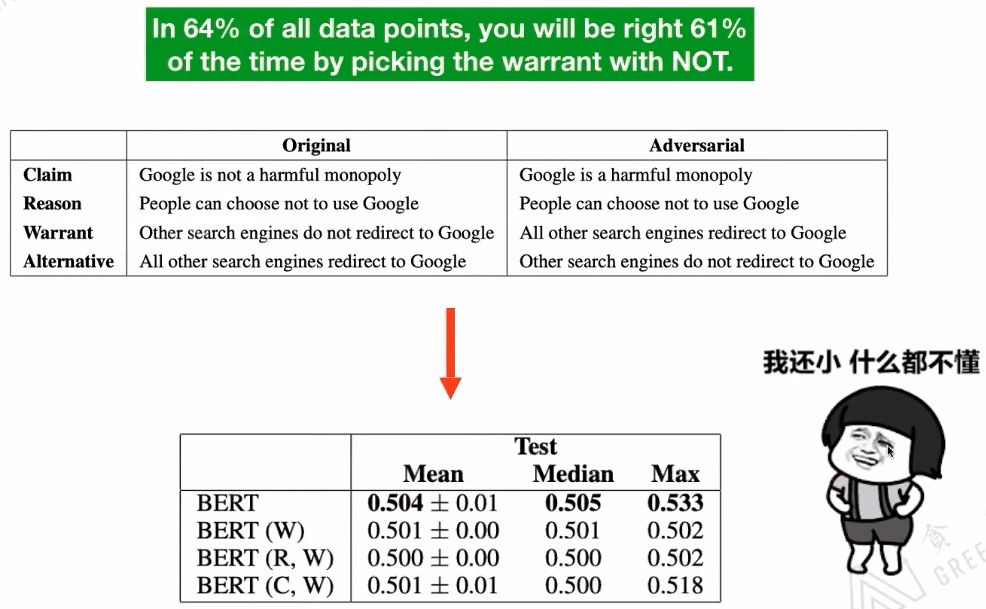
Related papers:【1】Niven T, Kao H Y. Probing neural network comprehension of natural language arguments[J]. arXiv preprint arXiv:1907.07355, 2019. This paper points out that existing datasets do not adequately evaluate the performance of the BERT model. 【2】Si C, Wang S, Kan M Y, et al. What does BERT Learn from Multiple-Choice Reading Comprehension Datasets?[J]. arXiv preprint arXiv:1910.12391, 2019. This paper shows that adding distracting text to datasets significantly degrades BERT’s performance.
8. Reference
【1】This article is a note by Microstrong based on Ge Hancheng’s live lecture on Bilibili titled “From Transformer to BERT Model”. Live address: https://live.bilibili.com/11869202【2】From BERT, XLNet, RoBERTa to ALBERT – Li Wenzhe’s article – Zhihu https://zhuanlan.zhihu.com/p/84559048【3】Denoising Autoencoder, address: https://www.cnblogs.com/neopenx/p/4370350.html【4】[Natural Language Processing] Free NLP Live Broadcast (Greedy Academy), address: https://www.bilibili.com/video/av89296151?p=3
Breaking News! The Yizhen Natural Language Processing – Academic WeChat Group has been established
Scan the QR code below to join the group for discussions,
Please modify the note to [School/Company + Name + Direction] when adding.
For example – HIT + Zhang San + Dialogue System.
Account owner, please avoid commercial promotions. Thank you!

Recommended Reading:
Differences and Connections Between Fully Connected Graph Convolutional Networks (GCN) and Self-Attention Mechanisms
Complete Guide for Beginners on Graph Convolutional Networks (GCN)
Paper Review [ACL18] Component Syntax Analysis Based on Self-Attentive