A crucial step in training a chatbot is word vector training. Whether it’s a generative chatbot or a retrieval-based chatbot, it is necessary to convert text into word vectors. The most popular word vector training model nowadays is Word2Vec. Today, I will guide you through training word vectors using Chinese Wikipedia.
Training Data Download
We will use Chinese Wikipedia to train word vectors. The download link for Wikipedia data is: https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2. After downloading, there’s no need to extract it; the compressed file of the Chinese Wikipedia data is relatively small, only about 1GB.
Installing Dependencies
After downloading the data, there are existing programs online to extract the XML. I found a Python file for parsing XML, named process_wiki.py. However, it needs to be modified; change output = open(outp, ‘w’) to output = open(outp, ‘w’, encoding=’utf-8′).
Otherwise, you will encounter the error shown in the image below:

Before providing the complete code, we need to install some dependencies: numpy, scipy, and gensim. Installing gensim depends on scipy, and installing scipy depends on numpy. We will directly install numpy using the command in the Windows command line: pip install numpy.
After successfully installing numpy, install scipy using the command pip install scipy. However, you might encounter an error; generally, this happens. The correct way is to download the .whl file from the website and install it. You can download the scipy package from: http://www.lfd.uci.edu/~gohlke/pythonlibs/
Find the appropriate version:

After downloading, you can install it using the pip command: pip install scipy-0.19.0-cp35-cp35m-win_amd64.whl. Then use the command pip install gensim.
Converting XML Wiki Data to Text Format
Use the code below to process the data, naming it process_wiki.py. This code is compatible with both Python 2 and Python 3:
from __future__ import print_function
import logging
import os.path
import six
import sys
from gensim.corpora import WikiCorpus
if __name__ == '__main__':
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
# check and process input arguments
if len(sys.argv) != 3:
print("Using: python process_wiki.py enwiki.xxx.xml.bz2 wiki.en.text")
sys.exit(1)
inp, outp = sys.argv[1:3]
space = " "
i = 0
output = open(outp, 'w', encoding='utf-8')
wiki = WikiCorpus(inp, lemmatize=False, dictionary={})
for text in wiki.get_texts():
if six.PY3:
output.write(b' '.join(text).decode('utf-8') + '\n')
# ###another method###
# output.write(
# space.join(map(lambda x:x.decode("utf-8"), text)) + '\n')
else:
output.write(space.join(text) + "\n")
i = i + 1
if (i % 10000 == 0):
logger.info("Saved " + str(i) + " articles")
output.close()
logger.info("Finished Saved " + str(i) + " articles")
Execute the code with the following command:
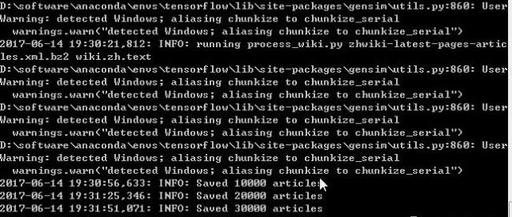
python process_wiki.py zhwiki-latest-pages-articles.xml.bz2 wiki.zh.text
However, an error occurred:

This is because our numpy version is incorrect, so we first need to uninstall the current numpy using pip, then go to the website: http://www.lfd.uci.edu/~gohlke/pythonlibs/
Download the corresponding version of numpy and install it:

Then execute the command again, and it should run successfully:
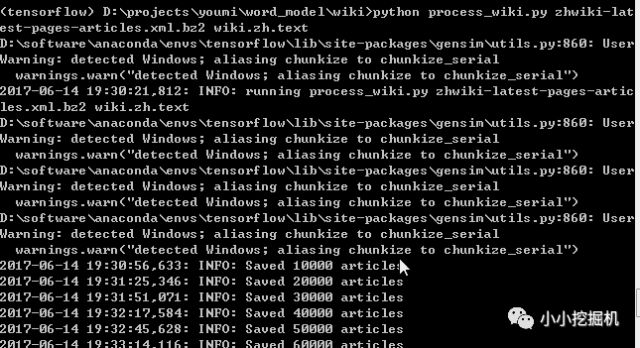
Alright, we will stop here for today’s experiment, and continue tomorrow!
To learn more, please scan the QR code below and follow the Machine Learning Research Association.

Source: Artificial Intelligence LeadAI