
Click on the “AI Youdao” above to select the “Top” public account
Heavyweight content delivered first-hand
This article is reproduced from Big Data Digest, secondary reproduction is prohibited
Translated by Zhang Qiuyue, Yihang, Gao Yan, Long Xincheng
Embedding is one of the most fascinating ideas in machine learning. If you have ever used Siri, Google Assistant, Alexa, Google Translate, or even a smartphone keyboard for next word prediction, you have likely benefited from this concept that has become central to natural language processing models.
Over the past few decades, embedding technology has seen significant development in neural network models. Especially recently, its evolution includes contextual embeddings that have led to state-of-the-art models like BERT and GPT-2.
BERT:
https://jalammar.github.io/illustrated-bert/
Word2Vec is an effective method for creating word embeddings that has existed since 2013. However, beyond being a method for word embeddings, some of its concepts have proven effective in creating recommendation engines and understanding time series data in business and non-language tasks. Companies like Airbnb, Alibaba, and Spotify have drawn inspiration from the NLP field and applied it in their products, thus supporting new types of recommendation engines.
In this article, we will discuss the concept of embedding and the mechanism of generating embeddings using Word2Vec. Let’s start with an example to familiarize ourselves with using vectors to represent things. Did you know that your personality can be represented by just a list of five numbers (vectors)?
Personality Embedding: What Kind of Person Are You?
How do you represent how introverted/extroverted you are on a scale from 0 to 100 (where 0 is the most introverted and 100 is the most extroverted)? Have you ever taken a personality test like MBTI or the Big Five personality traits test? If you haven’t, these tests ask you a series of questions and then score you on many dimensions, with introversion/extroversion being one of them.

Example results from the Big Five personality traits test. It can really tell you a lot about yourself and has predictive power in academic, personality, and career success. The test results can be found here.
Assuming my introversion/extroversion score is 38/100. We can visualize it this way:
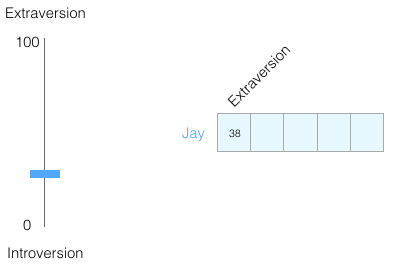
Let’s narrow the range to -1 to 1:

When you only know this one piece of information, how well do you think you understand this person? Not much. People are complex, so let’s add another test score as a new dimension.
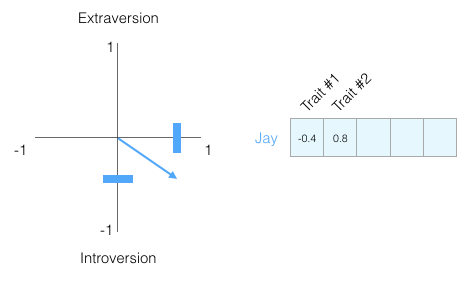
We can represent the two dimensions as a point on a graph or as a vector from the origin to that point. We have great tools to handle the upcoming vectors.
I have hidden the personality traits we are plotting so that you gradually get used to extracting valuable information from a personality vector representation without knowing what each dimension represents.
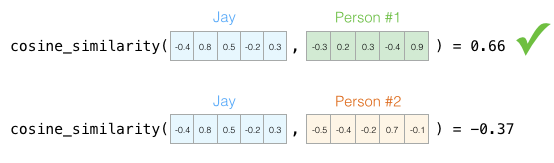
We can now say that this vector partially represents my personality. This representation is useful when you want to compare two other people with me. Suppose I get hit by a bus and need to be replaced with someone with a similar personality; which of the two people in the diagram below is more like me?
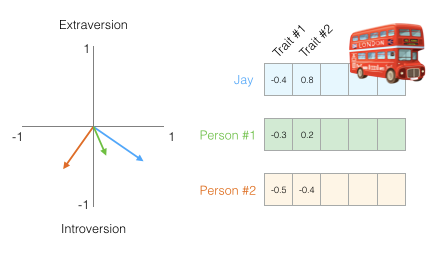
A common method for calculating similarity scores when processing vectors is cosine similarity:

Person 1 is more similar to me in personality. Vectors pointing in the same direction (length also matters) have a higher cosine similarity.
Once again, two dimensions are still not enough to capture sufficient information about different populations. Psychology has identified five major personality traits (along with a large number of subtraits), so let’s compare using all five dimensions:

The issue with using five dimensions is that we can no longer neatly draw little arrows on a two-dimensional plane. This is a common problem in machine learning, where we often need to think in higher-dimensional spaces. But fortunately, cosine similarity still applies, and it works in any number of dimensions:
Cosine similarity applies to any number of dimensions. These scores are better than the previous ones because they are calculated based on higher-dimensional comparisons.
In the final thoughts of this section, I want to propose two central ideas:
1. We can represent people and things as algebraic vectors (which is great for machines!).
2. We can easily calculate the relationships between similar vectors.

Word Embeddings
With the understanding from the above, we continue to look at instances of trained word vectors (also known as word embeddings) and explore some of their interesting properties.
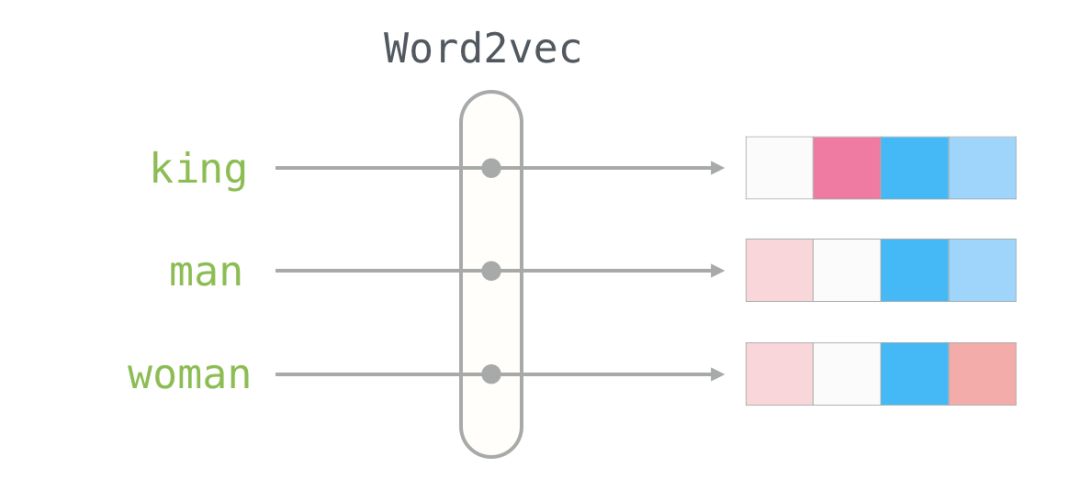
This is a word embedding for the word “king” (trained GloVe vectors from Wikipedia):
[ 0.50451 , 0.68607 , -0.59517 , -0.022801, 0.60046 , -0.13498 , -0.08813 , 0.47377 , -0.61798 , -0.31012 , -0.076666, 1.493 , -0.034189, -0.98173 , 0.68229 , 0.81722 , -0.51874 , -0.31503 , -0.55809 , 0.66421 , 0.1961 , -0.13495 , -0.11476 , -0.30344 , 0.41177 , -2.223 , -1.0756 , -1.0783 , -0.34354 , 0.33505 , 1.9927 , -0.04234 , -0.64319 , 0.71125 , 0.49159 , 0.16754 , 0.34344 , -0.25663 , -0.8523 , 0.1661 , 0.40102 , 1.1685 , -1.0137 , -0.21585 , -0.15155 , 0.78321 , -0.91241 , -1.6106 , -0.64426 , -0.51042 ]
This is a list of 50 numbers. By observing the values, we can’t see much, but let’s visualize it a bit to compare with other word vectors. We place all these numbers in a row:

Let’s color-code the cells based on their values (red for values close to 2, white for values close to 0, blue for values close to -2):

We will ignore the numbers and only look at the colors to indicate the values of the cells. Now let’s compare “king” with other words:
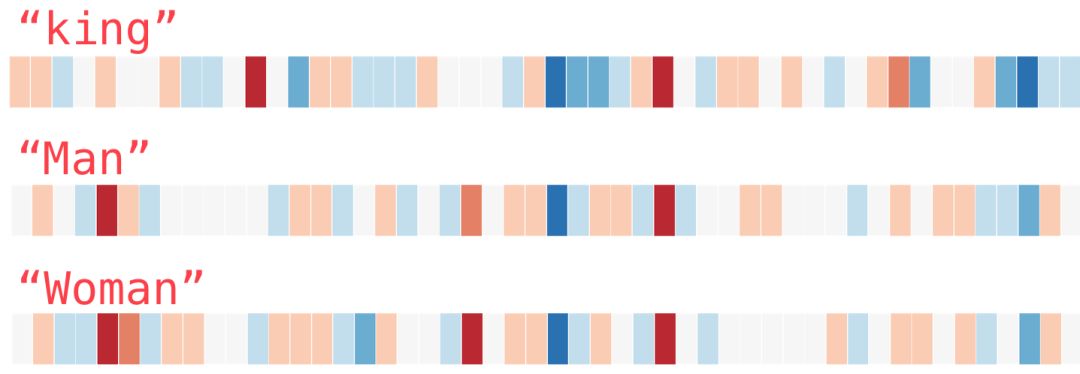
Notice how “Man” and “Woman” are more similar to each other than either of them is to “King”? This suggests something. These vector illustrations nicely showcase the information/meaning/association of these words.
This is another example list (by scanning columns vertically to find columns with similar colors):
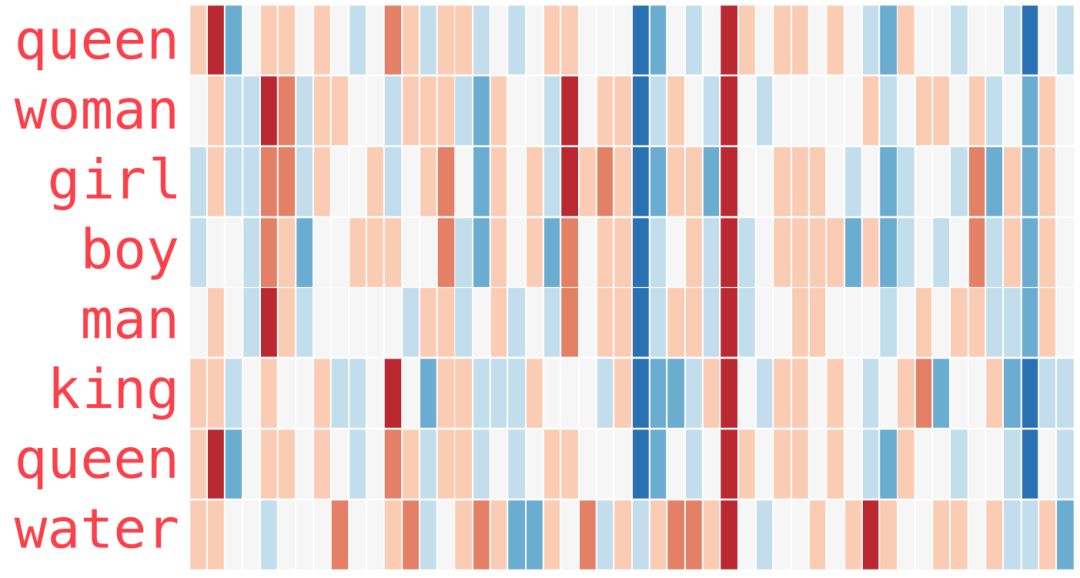
Several points need to be noted:
1. All these different words have a straight red column. They are similar in this dimension (even though we don’t know what each dimension is).
2. You can see that “woman” and “girl” are similar in many ways, and “man” and “boy” are similar too.
3. “boy” and “girl” also have similarities, but these are different from those with “woman” or “man.” Can these be summarized into a vague concept of “youth”? Perhaps.
4. Except for the last word, all words represent people. I added an object “water” to show the differences between categories. You can see that the blue column continues down and stops before the “water” embedding.
5. “king” and “queen” are similar to each other, but they are different from other words. Can these be summarized into a vague concept of “royalty”? Perhaps.
Analogy
A famous example that showcases the wonderful properties of embeddings is analogy. We can add and subtract word embeddings to get interesting results. A well-known example is the formula: “king” – “man” + “woman”:
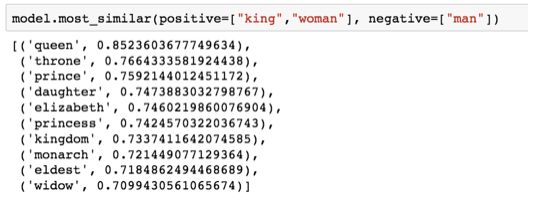
Using the Gensim library in Python, we can add and subtract word vectors, and it will find the most similar words to the resulting vector. This image shows the list of most similar words, each with cosine similarity.
We can visualize this analogy as before:
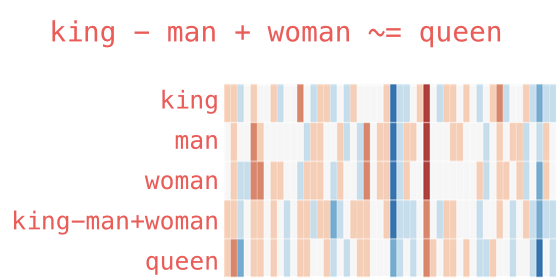
The vector generated by “king” – “man” + “woman” is not exactly equivalent to “queen,” but “queen” is the closest word among the 400,000 word embeddings included in this set.
Now that we have seen trained word embeddings, let’s learn more about the training process. But before we start using Word2Vec, we need to look at the parent concept of word embeddings: neural language models.
Language Models
If we were to cite the most typical example of natural language processing, it would have to be the next word prediction feature in smartphone input methods. This is a feature used hundreds of times daily by billions of people.
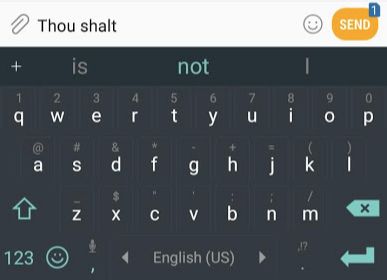
Next word prediction is a task that can be achieved through language models. Language models attempt to predict the next possible word based on a list of words (say, two words).
In the mobile screenshot above, we can consider that the model received two green words (thou shalt) and recommended a set of words (“not” is one of the most likely to be chosen):

We can imagine this model as a black box:

But in fact, the model does not output just one word. Instead, it scores all the words it knows (the model’s vocabulary, which can range from thousands to millions of words) by likelihood, and the input method program selects the one with the highest score to recommend to the user.

The output of a natural language model is the probability scores of the words known to the model, which we usually express as percentages, but in reality, a score like 40% is represented as 0.4 in the output vector group.
Natural language models (see Bengio 2003) complete predictions in three steps as shown below after training:
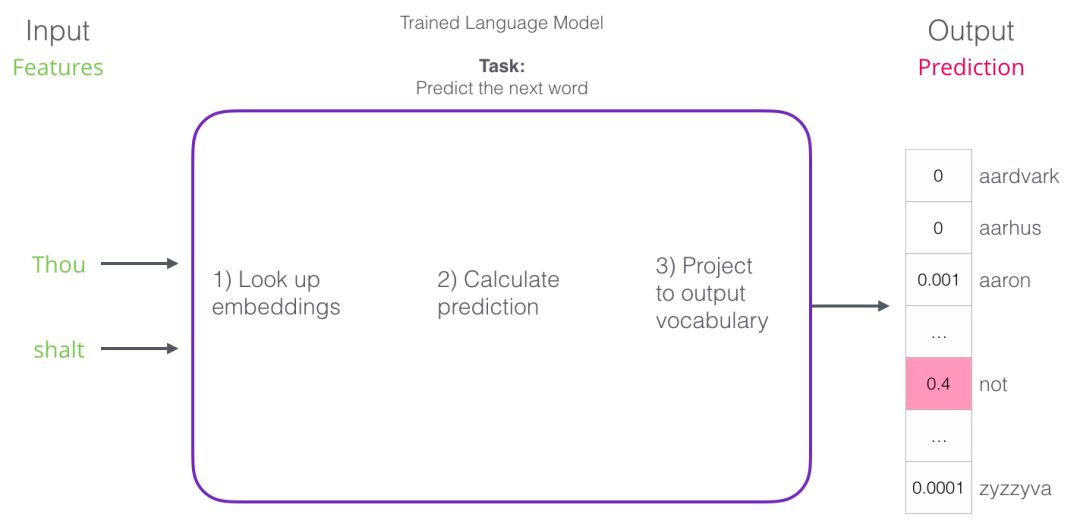
The first step is the most relevant to us because we are discussing Embedding. After training, the model generates a matrix that maps all the words in the vocabulary. When making predictions, our algorithm queries the input words in this mapping matrix and calculates the predicted values:
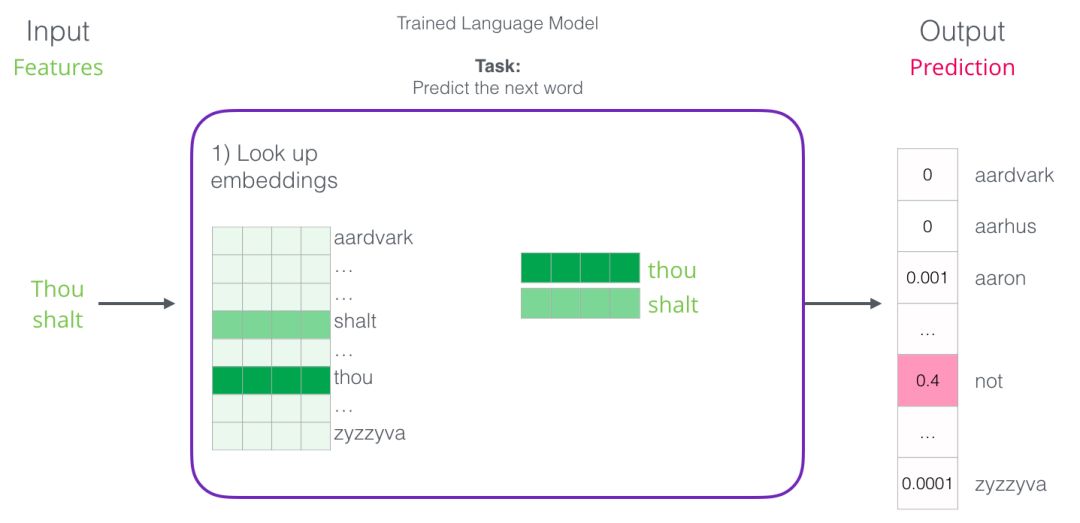
Now let’s focus on the model training to learn how to build this mapping matrix.
Language Model Training
Compared to most other machine learning models, language models have a significant advantage: we have abundant text to train them. All our books, articles, Wikipedia, and various types of text content are available. In contrast, many other machine learning model developments require manually designed data or specially collected data.
We can obtain their mapping relationships by finding the words that frequently appear near each word. The mechanism is as follows:
1. First, acquire a large amount of text data (e.g., all Wikipedia content)
2. Then, establish a sliding window that can move along the text (for example, a window containing three words)
3. Using such a sliding window, we can generate a large sample dataset for training the model.
As this window slides along the text, we can (in reality) generate a set of data for model training. To clarify this process, let’s see how the sliding window handles this phrase:
Initially, the window locks onto the first three words of the sentence:

We treat the first two words as features and the third word as the label:

At this point, we have produced the first sample in our dataset, which will be used in our subsequent language model training.
Next, we slide the window to the next position and produce the second sample:
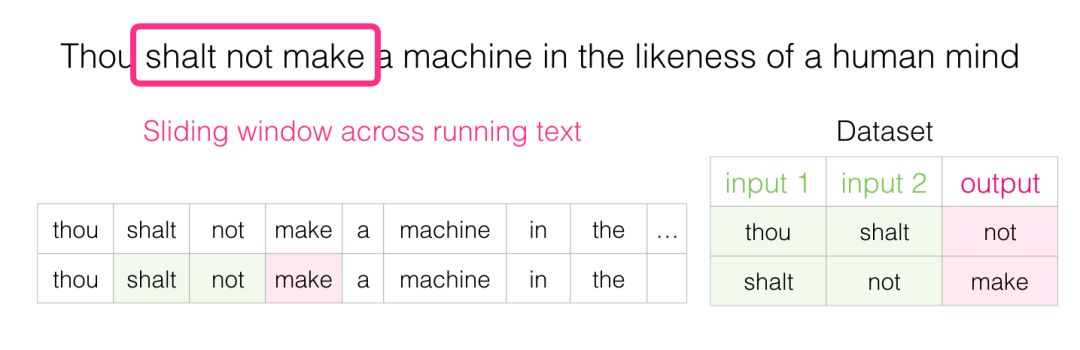
The second sample is also generated.
Before long, we can obtain a large dataset from which we can see the words that appear after different word groups:

In practical applications, the model is often trained as we slide the window. However, I think separating the dataset generation and model training into two stages makes it clearer and easier to understand. Besides using neural networks for modeling, people also commonly use a technique called N-grams for model training.
If you want to understand the transition from using N-grams models to neural models in real products, you can check out a blog published by Swiftkey (my favorite Android input method) in 2015, which describes their natural language model and the comparison with earlier N-grams models. I like this example because it shows how to explain the algorithmic properties of Embedding clearly in marketing presentations.
Considering both ends
Fill in the blanks based on the previous information:

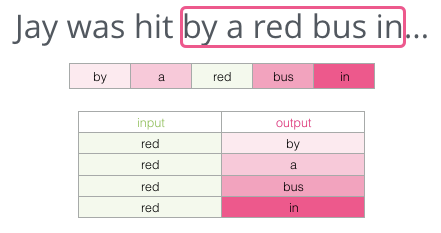
In front of the blank, the background I provided is five words (if ‘bus’ was mentioned beforehand), it is certain that most people would fill in ‘bus’ in the blank. But if I give you one more piece of information – say, a word after the blank, will the answer change?

Now the content filled in the blank has completely changed. At this point, the word ‘red’ is most likely to fit this position. From this example, we learn that the words before and after a word carry informational value. It turns out we need to consider words in both directions (the words to the left and right of the target word). So how should we adjust the training method to meet this requirement? Let’s continue reading.
Skipgram Model
We need to consider not only the two words before the target word but also the two words after it.

If we do this, the model we are actually constructing and training would look like this:
The architecture described above is called Continuous Bag of Words (CBOW), as explained in a paper on Word2Vec.
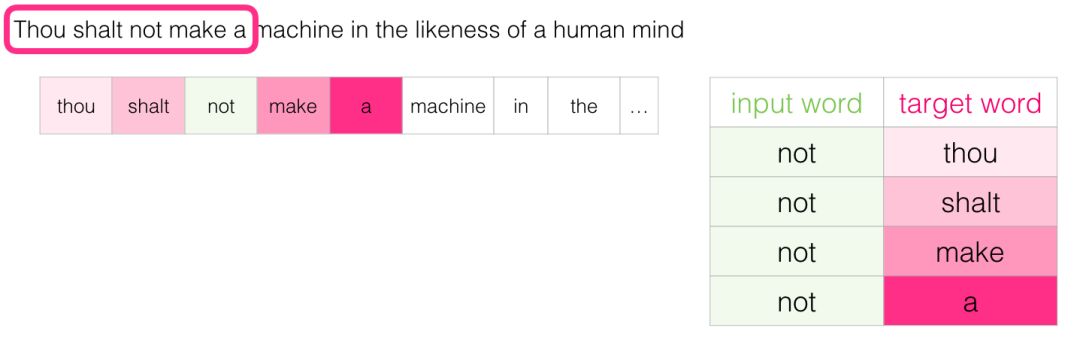
There is another architecture that does not guess the target word based on the context (the words before and after) but instead predicts the likely surrounding words for the current word. Let’s imagine how the sliding window looks during training data:
The words in the green box are the input words, while the pink box contains the possible output results.
The depth of the pink box color indicates that the sliding window produces four independent samples for the training set:
This approach is called the Skipgram architecture. We can visualize the contents of the sliding window as shown below.

This provides four samples for the dataset:
Then we move the sliding window to the next position:
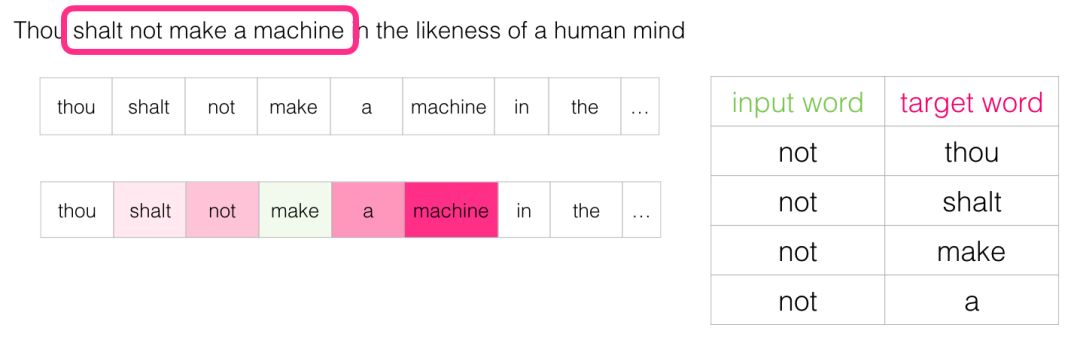
This generates the next four samples:
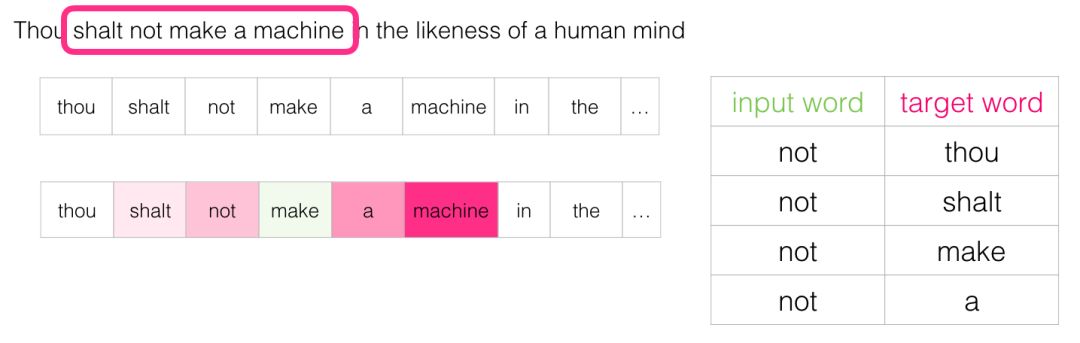
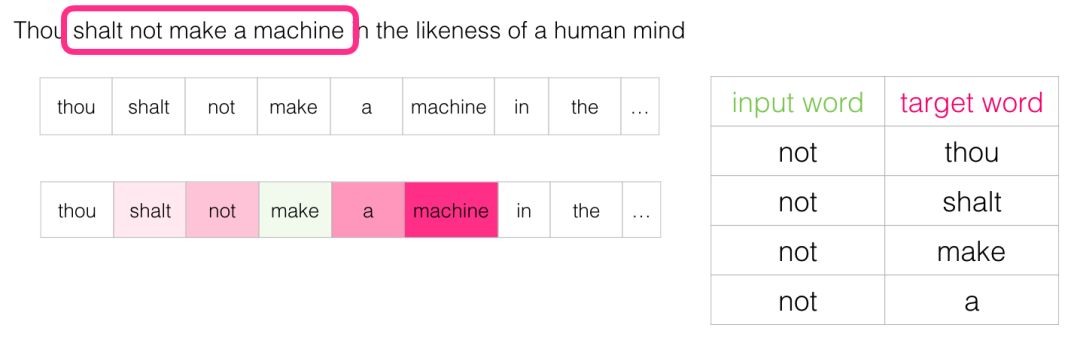
After moving through several positions, we can obtain a batch of samples:
Revisiting the Training Process
Now that we have obtained the training dataset for the Skipgram model from existing text, let’s see how to use it to train a natural language model that predicts adjacent words.
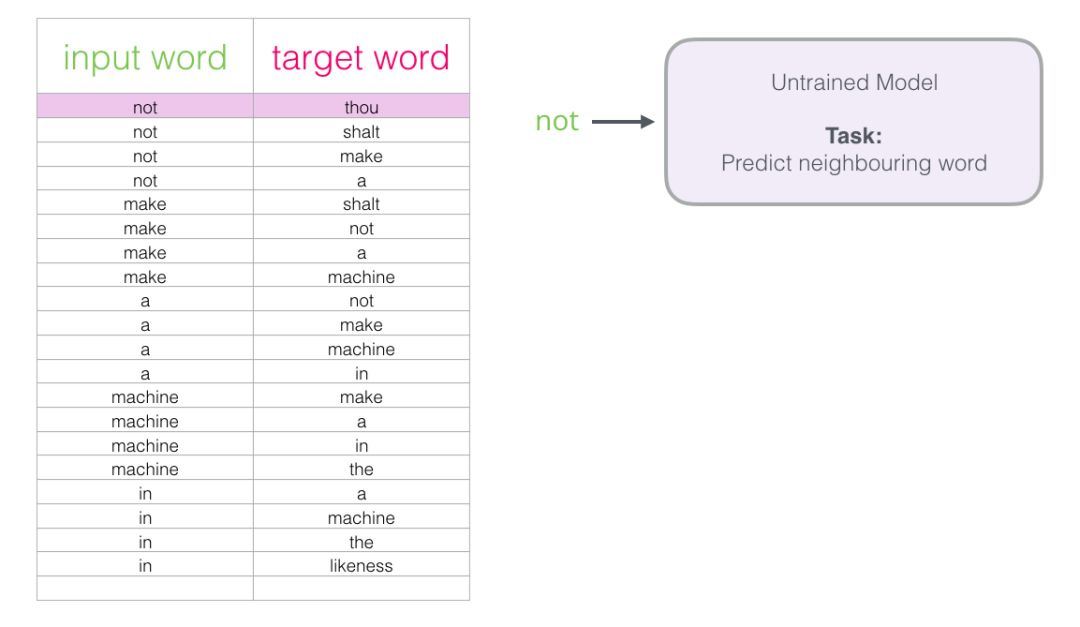
Starting with the first sample from the dataset. We input the features into the untrained model and let it predict a possible adjacent word.
The model will perform three steps and output a prediction vector (corresponding to the probability of each word in the vocabulary). Since the model is untrained, the predictions at this stage are certainly incorrect. But that’s okay; we know which word should be guessed – that word is the output label in my training dataset:
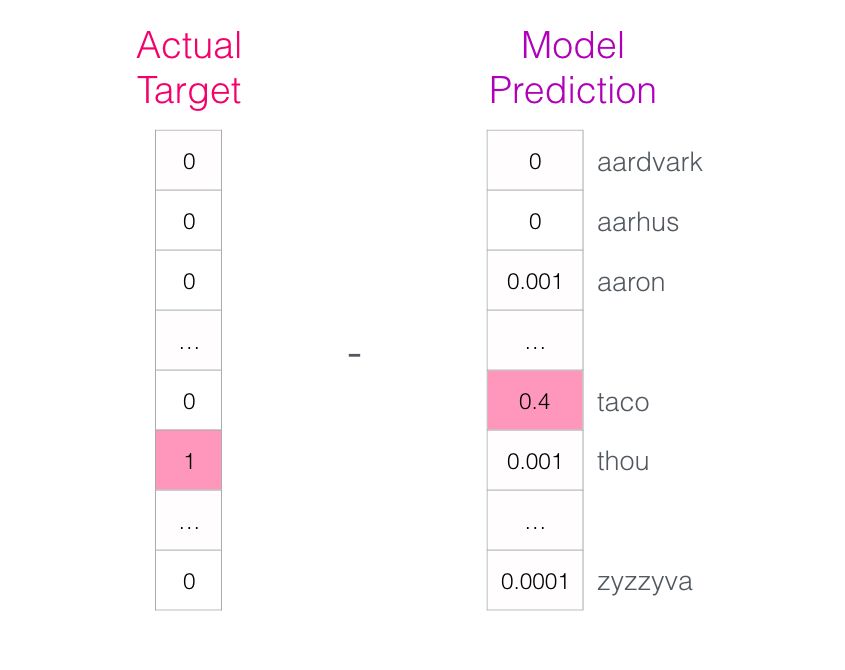
The target word has a probability of 1, while all other words have a probability of 0, thus forming the “target vector”.
How much bias does the model have? By subtracting the two vectors, we can obtain the bias vector:
This error vector can now be used to update the model, so in the next round of predictions, if we use “not” as input, we are more likely to get “thou” as output.
This is actually the first step of training. Next, we continue with the same operation for the next sample in the dataset until we have traversed all samples. This constitutes one epoch. We repeat this for several epochs, resulting in a trained model from which we can extract the embedding matrix for other applications.
This indeed helps us understand the entire process, but this still does not represent the true training method of Word2Vec. We have missed some key ideas.
Negative Sampling
Recall the three steps that the neural language model computes the prediction value:
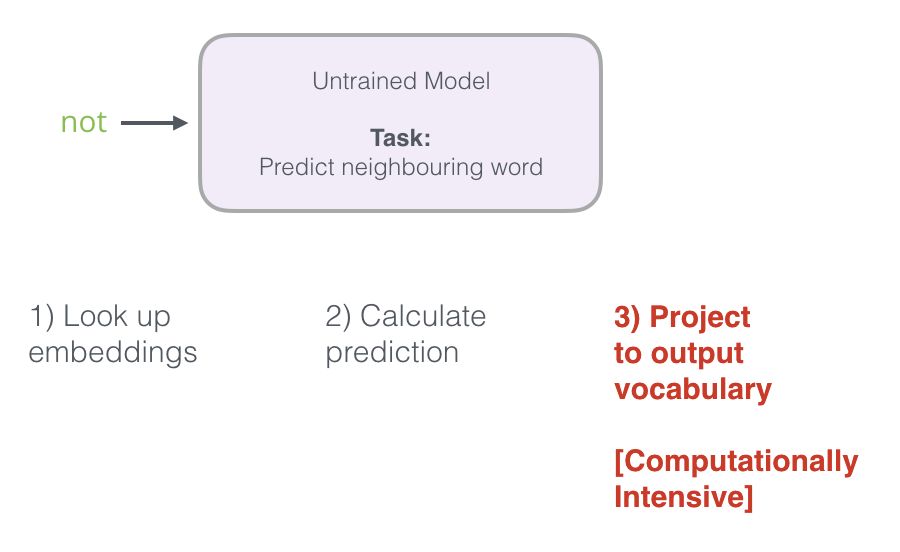
From a computational perspective, the third step is very expensive – especially when we need to do it for each training sample in the dataset (which can easily amount to tens of millions of times). We need to find ways to improve performance.
One method is to divide the target into two steps:
1. Generate high-quality word embeddings (don’t worry about predicting the next word).
2. Use these high-quality embeddings to train the language model (for next word prediction).
In this article, we will focus on the first step (as this article focuses on embeddings). To generate high-quality embeddings using high-performance models, we can switch the task of predicting adjacent words:
Switching it to a model that extracts input and output words and outputs a score indicating whether they are neighbors (0 means “not neighbors,” 1 means “neighbors”).

This simple transformation shifts our required model from a neural network to a logistic regression model – thus making it simpler and faster to compute.
This switch requires us to change the structure of the dataset – the label values are now a new column with values of 0 or 1. They will all be 1 because all the words we add are neighbors.
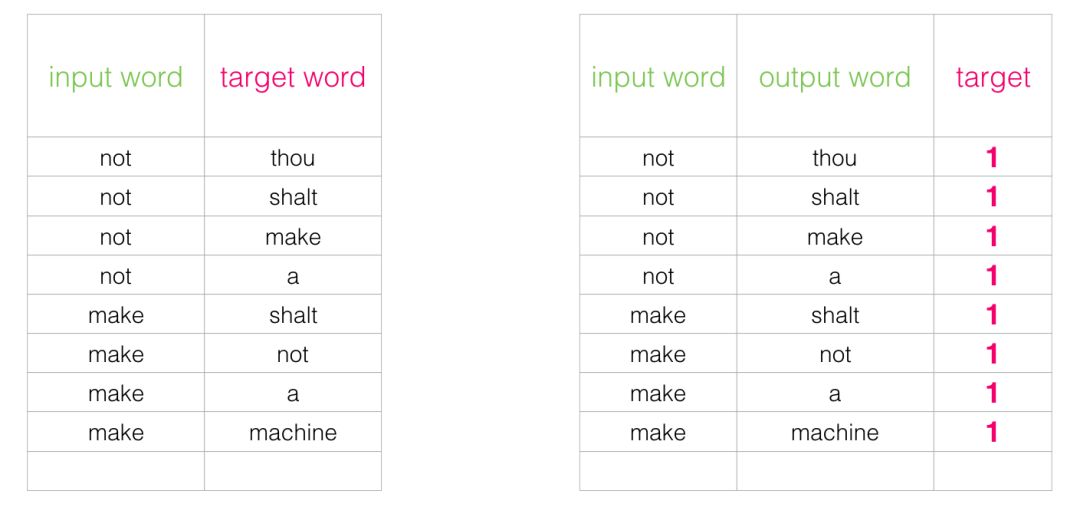
Now the computation speed is incredibly fast – processing millions of examples in just a few minutes. However, we still need to address a loophole. If all examples are neighbors (target: 1), our “genius model” may be trained to always return 1 – accuracy is 100%, but it learns nothing and only produces garbage embedding results.
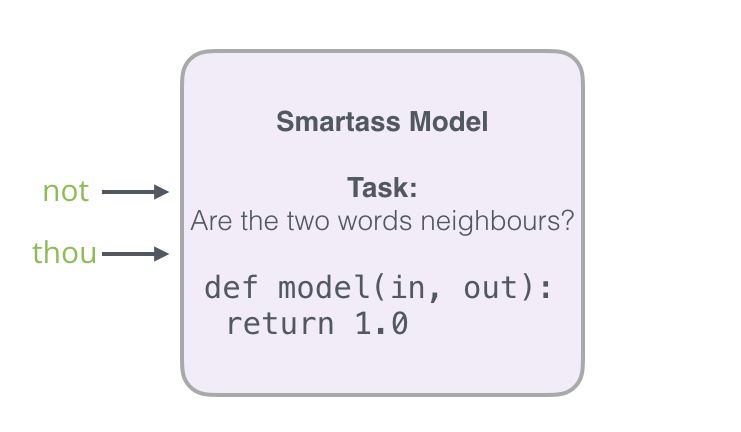
To solve this problem, we need to introduce negative samples into the dataset – samples of words that are not neighbors. Our model needs to return 0 for these samples. The model must work hard to meet this challenge – and still maintain high speed.
For each sample in our dataset, we add negative examples. They have the same input words, but the label is 0.
But what do we fill in as output words? We randomly select words from the vocabulary.

This idea is inspired by noise-contrastive estimation. We contrast the actual signal (positive examples of adjacent words) with noise (randomly chosen non-neighboring words). This leads to a huge compromise in computational and statistical efficiency.
Noise-Contrastive Estimation
http://proceedings.mlr.press/v9/gutmann10a/gutmann10a.pdf
Skipgram with Negative Sampling (SGNS)
We have now introduced two (pairs of) core ideas in Word2Vec: negative sampling and skipgram.
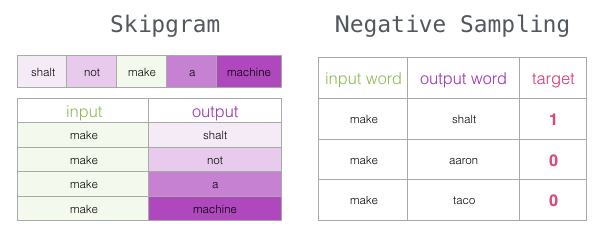
Word2Vec Training Process
Now that we understand the two central ideas of skipgram and negative sampling, we can continue to closely examine the actual training process of Word2Vec.
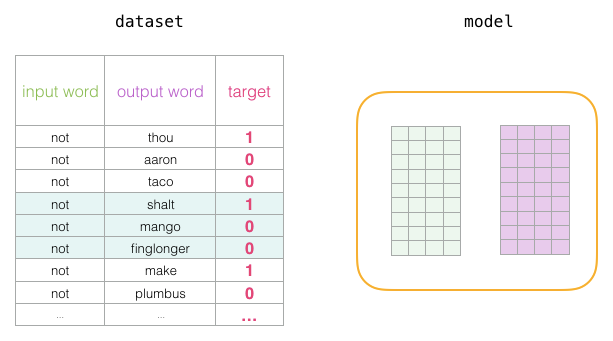
Before the training process begins, we preprocess the text that we are training the model on. At this step, we determine the size of the vocabulary (we call it vocab_size, say 10,000) and which words are included in it.
At the start of the training phase, we create two matrices – the Embedding matrix and the Context matrix. These two matrices embed each word in our vocabulary (so vocab_size is one of their dimensions). The second dimension is the length we wish each embedding to be (embedding_size – 300 is a common value, but we have also seen examples of 50 before).
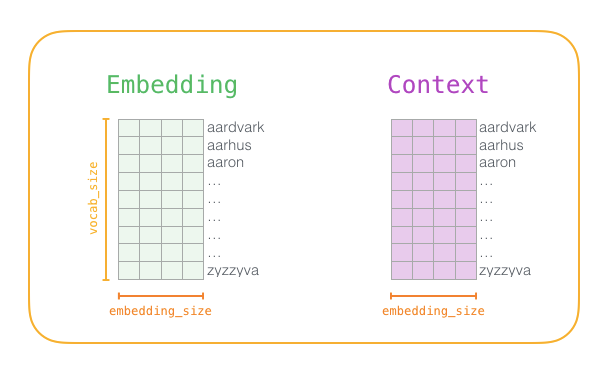
At the start of the training process, we initialize these matrices with random values. Then we begin the training process. In each training step, we take a neighboring example and its related non-neighboring examples. Let’s take a look at our first set:
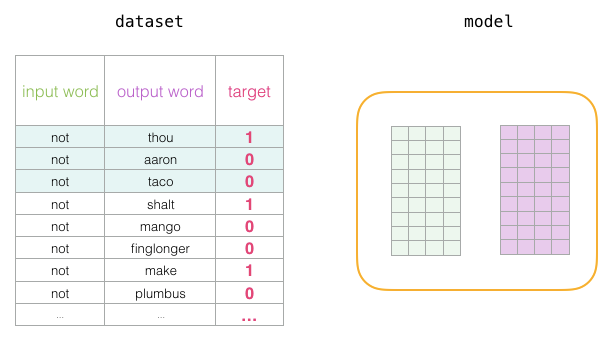
Now we have four words: the input word “not” and the output/context words: “thou” (the actual neighboring word), “aaron” and “taco” (the negative examples). We continue to look for their embeddings – for the input word, we check the Embedding matrix. For the context words, we check the Context matrix (even though both matrices embed each word in our vocabulary).
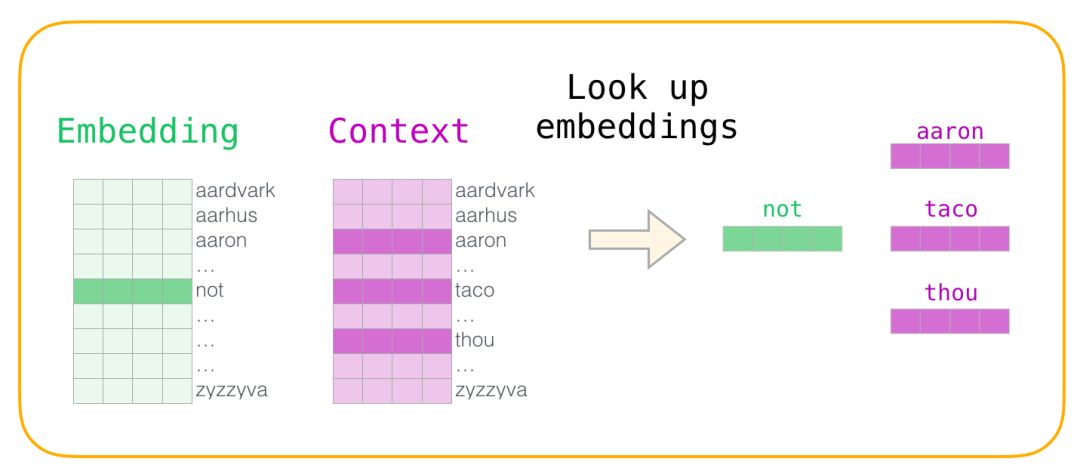
Next, we calculate the dot product of the input embedding with each context embedding. In each case, the result will be a number representing the similarity between the input and context embeddings.
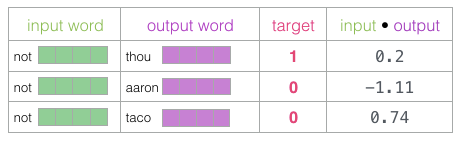
Now we need a way to turn these scores into something that looks like probabilities – we need them to all be positive and within the range of 0 to 1. The sigmoid function is perfect for this.
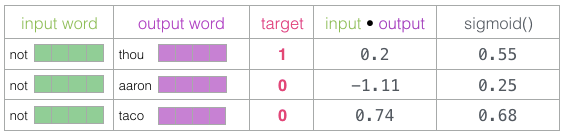
Now we can view the output of the sigmoid operation as the model’s output for these examples. You can see that “taco” scores the highest, while “aaron” scores the lowest, both before and after the sigmoid operation.
Since the untrained model has made predictions and we indeed have the real target labels for comparison, let’s calculate the error in the model’s predictions. To do this, we simply subtract the sigmoid scores from the target labels.
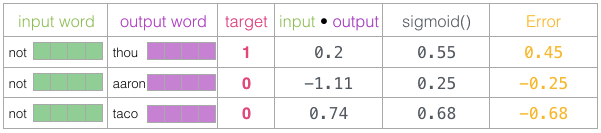
error = target – sigmoid_scores
This is the “learning” part of “machine learning.” Now, we can use this error score to adjust the embeddings of “not”, “thou”, “aaron”, and “taco” so that the next time we perform this calculation, the results will be closer to the target score.
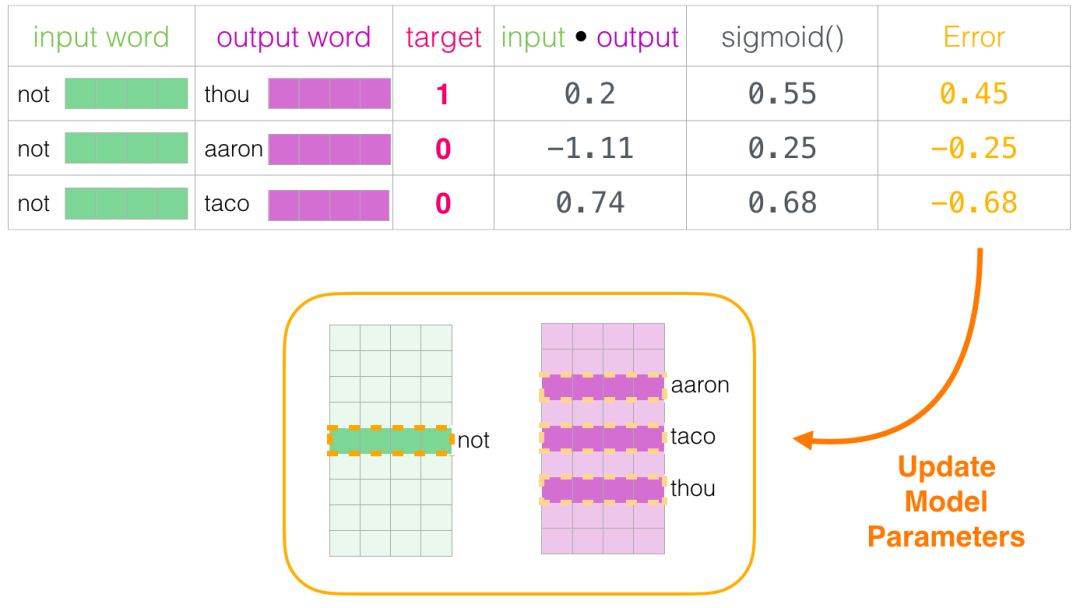
The training step ends here. We have obtained better embeddings for the words used in this step (not, thou, aaron, and taco). We now proceed to the next step (the next neighboring sample and its related non-neighboring samples) and execute the same process again.
As we loop through the entire dataset multiple times, the embeddings will continue to improve. Then we can stop the training process, discard the Context matrix, and use the Embeddings matrix as the trained embeddings for the next task.
Window Size and Number of Negative Samples
Two key hyperparameters in the Word2Vec training process are the window size and the number of negative samples.
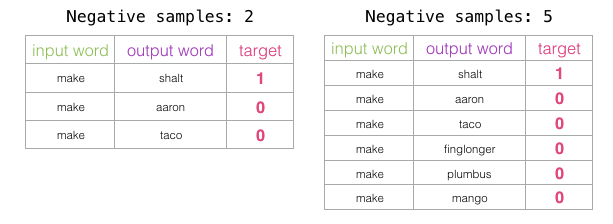
Different tasks are suited to different window sizes. A heuristic approach is that using a smaller window size (2-15) will yield embeddings where a high similarity score between two embeddings indicates that these words are interchangeable (note that if we only look at nearby words, antonyms can often be interchangeable – for example, good and bad often appear in similar contexts). Using a larger window size (15-50, or even more) will yield embeddings where similarity better indicates the correlation of words. In practice, you often need to guide the embedding process to help readers achieve a similar “sense of language.” Gensim defaults to a window size of 5 (including two words before and after the input word, excluding the input word itself).
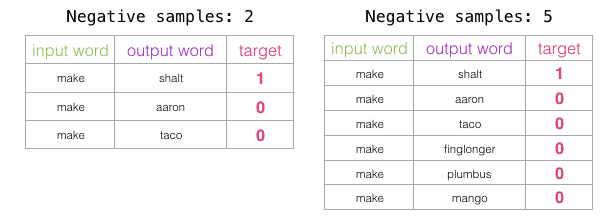 The number of negative samples is another factor that influences the training process. The original paper suggests that 5-20 negative samples is an ideal number. It also notes that when you have a sufficiently large dataset, 2-5 seems to be enough. Gensim defaults to 5 negative samples.
The number of negative samples is another factor that influences the training process. The original paper suggests that 5-20 negative samples is an ideal number. It also notes that when you have a sufficiently large dataset, 2-5 seems to be enough. Gensim defaults to 5 negative samples.
Conclusion
I hope you now have a better understanding of word embeddings and the Word2Vec algorithm. I also hope that now when you read a paper mentioning “Skipgram with Negative Sampling” (SGNS) (like the recommended systems paper at the top), you have a better grasp of these concepts.
Related reports:
https://jalammar.github.io/illustrated-word2vec/

【Recommended Reading】
Heavy Content | Selected Historical Articles from the Public Account (with Resources)
My Deep Learning Entry Route
My Machine Learning Entry Roadmap

Are you watching? 👇