
If you’re starting to explore how to test open source large language models (LLM) with Generative AI for the first time, the overwhelming amount of information can be daunting. There is a lot of fragmented information from various sources on the internet, making it difficult to quickly start a project.
The goal of this article is to provide an easy-to-follow guide to help you set up and run open source AI models locally using a launcher called Ollama. Of course, these steps can also be used to run it on your server.
What is Ollama
Ollama is a tool that helps us run large language models on local machines, making it easier to test LLMs locally. Ollama provides multiple ways to interact through local command line and API calls. If you want to quickly test, the CLI is a great option; if you’re looking to start a product, you can also choose to use /api/chat for application development.
Ollama consists of two parts: one is the server that runs the LLM, and the other is an optional component: the CLI for interacting with the server and LLM.
Installing Ollama
Ollama[1] provides installation packages[2] for MacOS/Linux/Windows downloads. As of now (2024/02/27), Windows support is still in preview, which may have issues. Therefore, we will demonstrate installing this application on MacOS.
Graphical Installation
Once downloaded, unzip the zip file to get the Ollama application. You can drag it to your system’s Applications folder and double-click to open:

If it’s your first time opening it, you may encounter a security prompt; just select open.

Next, you need to install the command line tool for Ollama so that you can access the LLM from the command line.
Command Line Installation
Of course, if you have the homebrew package manager installed, you can quickly install Ollama using the following command:
brew install ollama
When installing via the command line, note that you cannot start the background service like you can with the graphical interface. You need to execute the following command to start the Ollama server:
ollama serve
Testing Ollama
Now that you have installed Ollama, let’s run a basic model to try it out. Ollama supports many open source models[3], including Google’s latest open source Gemma[4]. However, I recommend using the Mistral[5] 7B model. We can quickly install the corresponding model using the following command:
ollama pull mistral
This will install the Mistral 7B model[6], which is highly efficient and performs well. This command typically downloads several GBs to tens of GBs of models locally, so please ensure your internet speed and local disk space are sufficient for the installation.
Assuming you have successfully installed the model, we can use the following command to start testing:
ollama run mistral
If you encounter the following error when executing this command, it means your server has not started yet:
ollama run mistral
Error: could not connect to ollama app, is it running?
You can double-click to open the application, or use the following command to quickly start the server:
ollama serve
After executing the command, it may take some time to load the model. This may take a while, depending on your computer’s configuration.
Once the model loads successfully, you will see an interface like this:

Let’s ask a question and see how it responds:

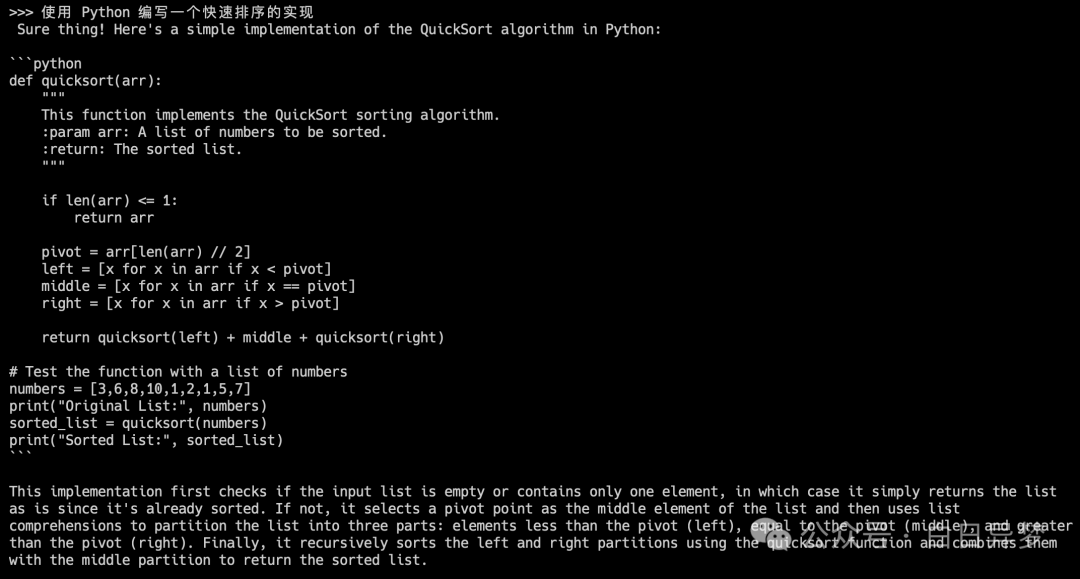
This question may be too simple; let’s ask the AI to implement a quicksort in Python:
Some Insights About Mistral
There are many open source models; why do I recommend Mistral? Mistral has several advantages: although it is a 7B model, benchmarks show it can rival the LLaMA 13B model; at the same time, because it is a 7B model, its performance during CPU inference is acceptable, and if using GPU inference, it is very fast.
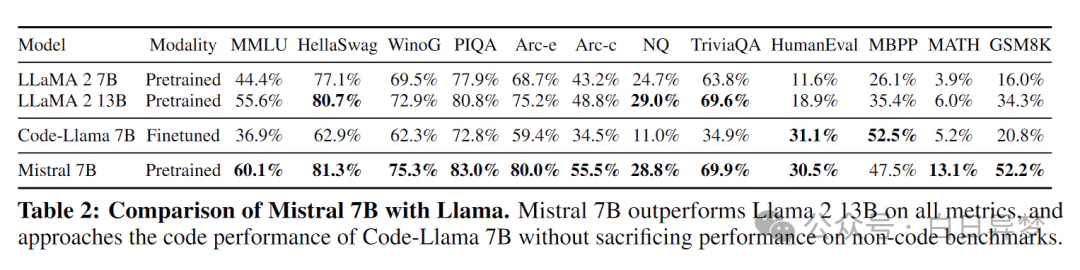
Of course, it also has many drawbacks. For instance, due to the parameter size, Mistral’s information capacity is quite limited. This means that if you are using it in an actual project or as an AI assistant, you may need to provide a lot of additional information for the model to understand. This makes Mistral a very suitable model for extension development work.
Developing with Ollama
To quickly develop applications, we choose to use Python.
Let’s start with the initial Q&A:
# llm_chat.py
import requests
res = requests.post(
"http://127.0.0.1:11434/api/chat", # server address
json={
"model": "mistral", # use mistral model
"stream": False, # disable streaming output
"messages": [
{"role": "user", "content": "Who are you?"}, # user input
],
},
)
print(res.json())
Next, let’s run this Python script:

# llm_chat.py
import requests
res = requests.post(
"http://localhost:11434/api/chat",
json={
"model": "mistral", # use mistral model
"stream": False, # disable streaming output
"messages": [
{
"role": "user",
"content": "Who are you? Please respond in YAML format, as follows:
name: string
language: string
", # user input
},
],
},
)
print(res.json())
Note that here we ask the LLM to output in YAML format[7]. This is a format friendly to both humans and machines. We provide specific format definitions and field names and types to prevent the LLM from improvising:
name: string
language: string
Let’s execute this file again:

We can see that the LLM outputs the corresponding content according to our format requirements. Let’s display the output content in YAML format:
name: "AI Assistant"
language: "English"
This way, we can leverage the LLM to convert unformatted content into formatted content for further processing in our applications.
Conclusion
As you can see, using Ollama to quickly deploy local open source large language models is that simple. With the capabilities provided by Ollama, we can easily test open source AI models locally. This is the first step in creating applications that utilize real artificial intelligence. Regarding the subsequent development of actual AI applications, I will update a series of articles to explain further.
Ollama: https://ollama.com/
[2]Installation Package: https://ollama.com/download
[3]Many Open Source Models: https://ollama.com/library
[4]Gemma: https://ollama.com/library/gemma
[5]Mistral: https://ollama.com/library/mistral
[6]Mistral 7B Model: https://mistral.ai/news/announcing-mistral-7b/
[7]YAML Format: https://yaml.org/