
IntroductionOn November 30, 2022, OpenAI released ChatGPT, instantly igniting a global internet frenzy and marking the beginning of a generative artificial intelligence technology revolution. Reflecting on the past year of AI development, no existing vocabulary can adequately describe its monumental scale. AIGC technology has evolved at an unprecedented speed, and the contours of general artificial intelligence are becoming increasingly clear.In the face of this unstoppable wave of technological innovation, public sentiment has shifted from initial observation and shock to a mix of anxiety and a thirst for knowledge—largely stemming from the mysterious veil surrounding AI technology. Delving into the mysteries of AI requires a solid theoretical foundation, which is not an easy task for most people. Therefore, I am launching this series of articles aimed at helping readers lift the veil of AIGC technology and gradually master its practical skills, making technology more accessible. Many people translate AIGC as generative artificial intelligence, which can cause confusion with acronyms like GAI and AGI. Below is my understanding of these acronyms for your reference.
Many people translate AIGC as generative artificial intelligence, which can cause confusion with acronyms like GAI and AGI. Below is my understanding of these acronyms for your reference.
- AGI (Artificial General Intelligence): Translated as General Artificial Intelligence, it refers to AI that possesses human-like cognitive abilities and can perform tasks typically only humans can accomplish.
- GAI (Generative Artificial Intelligence): Translated as Generative Artificial Intelligence, it refers to AI technology capable of generating new data and content.
- AIGC (Artificial Intelligence Generated Content): Initially, AIGC was used to refer to content, translated as Artificial Intelligence Generated Content, corresponding to what people commonly refer to as PGC (Platform Generated Content) and UGC (User Generated Content); however, more and more people also use AIGC to refer to the technology itself. In this case, it is more appropriate to translate AIGC as Intelligent Content Generation Technology to distinguish it from GAI, which more accurately expresses generative artificial intelligence.
In this wave of AIGC technology, large language models (Large Language Models, LLM) have taken center stage, quickly becoming a focal point of public attention and rapidly transforming into practical productivity. Following this, intelligent generation models in the fields of images, videos, and music have also begun to attract significant attention. This series of articles will use large language models as a starting point to guide you step by step into exploring this fascinating field. I hope to use more accessible language to help the public understand AI, and many expressions may not be rigorous, so readers should not use them for precise understanding of AI algorithms.
What is a Large Language Model?
A large language model (Large Language Model, LLM) is a natural language processing model trained on a vast amount of text data using machine learning techniques to understand and generate human language.ChatGPT is a typical representative of large language models.
The “Chat” in ChatGPT is relatively easy to understand: it refers to dialogue. But what does “GPT” actually mean? It is an abbreviation for the following three words:
-
Generative: Generative
-
Pre-trained: Pre-trained
-
Transformer: Transformer
Among these three words, only one is a noun, which is Transformer. G and P are both modifiers, so it is necessary to first understand what a Transformer is.
What is a Transformer?
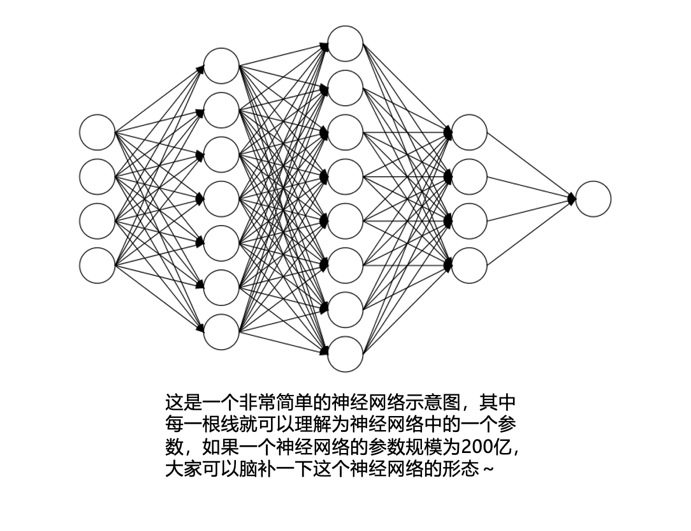
A Transformer is an AI neural network model. Here, the “network” does not refer to the networks used in our daily homes or offices to connect computers and phones, but rather to the neural networks that computer scientists use to simulate the workings of the human brain. It generally consists of many nodes, each designed to simulate the functioning of human brain neurons, receiving input information for simple calculations and then passing it on to the next node. Typically, neurons are divided into many layers, with each layer’s neurons interconnected to transmit information. Each connection can have a numerical value representing the strength of the information being transmitted, which is what we commonly refer to as the “parameters” of a large model. We often see descriptions of parameter scales like 7B (7 billion) or 20B (20 billion) in various articles, which can be imagined as having billions to trillions of densely packed connections between neurons.
The Transformer was proposed by Google in June 2017 in the paper “Attention Is All You Need.” This paper was completed by an eight-person team, which included both interns still in college and early employees of Google. However, they have all since left Google and started their own ventures in the AI field. There is an article that specifically discusses the story of these eight people writing this paper: “The Great Milestone of AI: The Origin Story of Transformer Technology – The Eight Traitors of Google”, which interested readers might find quite interesting. As for why it is called Transformer, there is no way to verify this, but it is said that the initiator of this team liked to play with Transformers toys as a child, and this model was initially used to solve translation tasks, making the name quite fitting.
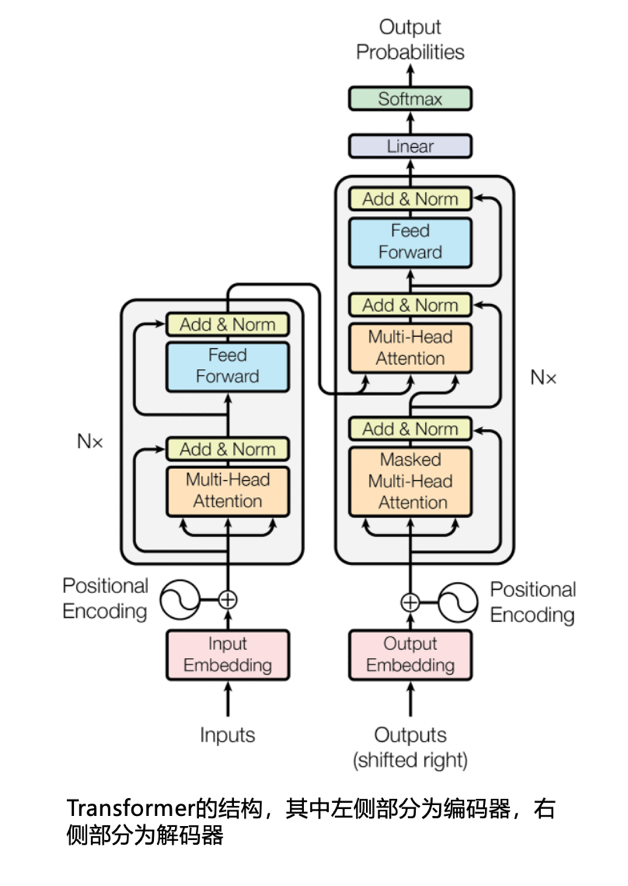
The Transformer was initially proposed to address translation and other tasks, with its structure being an Encoder-Decoder architecture. As the title of its paper, “Attention Is All You Need,” reveals, its essence lies in Attention. We generally translate this as “attention mechanism.” Attention is a revolutionary parallel computation strategy that allows the model to efficiently capture the subtle relationships between each word in the input text, enabling quick understanding of the overall context.
Language is the treasure of human civilization, allowing us to express rich meanings using natural language. From birth, we live in an environment where language carries various information, enabling us to understand the meaning of written words from a young age and discern which textual content is similar and which is unrelated.
However, enabling computers to possess this ability proves challenging. This is because, at the core of computers, all information is represented numerically. We can use numbers to store and present text, images, and videos, but in the age of intelligence, computer scientists aim to take a significant leap forward: attempting to express the semantics of a piece of information using numbers and subsequently perform complex reasoning tasks.
Why can numbers express meaning? Let’s explain this in a more intuitive way.
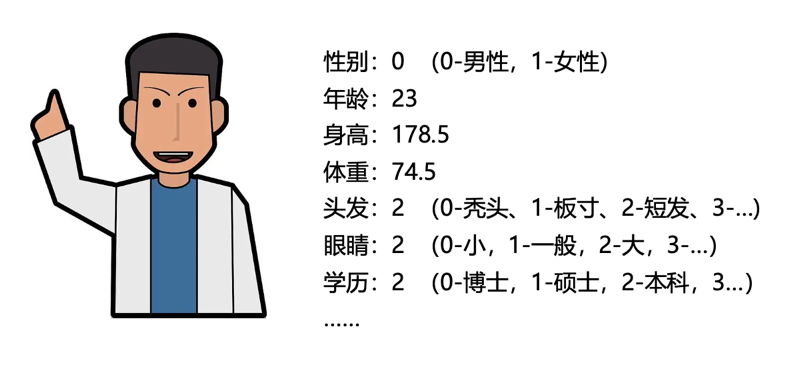
For example, if we want to describe a “person,” we can use attributes like gender, weight, height, and age. We can represent a person with a set of numbers (0, 74.5, 178.5, 23): male (0 = male, 1 = female), 74.5 kg, 178.5 cm tall, and 23 years old. If we want to describe this person more precisely, we can also express skin color, eye size, hair length, education level, occupation, personality traits, and voice tone in numbers. The more attributes we describe, the more accurate our mental image of this person becomes. Moreover, if two people’s values are closer, their similarity increases; conversely, the greater their differences, the higher their dissimilarity.
In addition to intuitively describing a “person” with a set of numbers, other information (such as images, text, videos) can also be represented by extracting their features into a series of numbers. The number of dimensions is the dimension; as the dimensions gradually expand, the amount of information that can be expressed and accommodated increases, allowing everything in life to be converted into a high-dimensional numerical vector, which can also be understood as a point in high-dimensional space. Through this mapping, an interesting phenomenon emerges: content that feels similar in meaning in our lives is also close in this space, while unrelated information is relatively distant in this space. Many neural network models have been proposed in hopes of finding various ways to achieve this information mapping more quickly and accurately, and then use reasoning to solve various real-life tasks.
The core of the Transformer paper is the use of the Attention mechanism to achieve this goal. The characteristic of Attention is its ability to quickly focus on the relationships between each word in the text through parallel computation, thereby achieving an understanding and reasoning of the semantics of the entire input content. Prior algorithms mostly required serial computation to sequentially perceive each piece of information, resulting in low computational efficiency. The introduction of Attention significantly improved this efficiency. This efficiency boost brought about a tremendous effect: large-scale training became possible, and with large-scale training, AI models emerged with astonishing capabilities.
The Transformer consists of two main parts: the encoder and the decoder. The encoder acts as the “understanding” role before translation, using Attention to quickly analyze the input text content and understand its semantics, while the decoder is a “reasoner”, which derives the target language text based on the semantics understood by the encoder. This derivation is done word by word: it first outputs the first word, then feeds the first word back into the decoder to derive the second word, and so on until the decoder determines that “translation is complete” is the next output. During the decoder’s derivation process, Attention also plays an important role, as it is used to understand the information that has already been derived and integrate it with the semantic information captured by the encoder to ensure the accuracy of the translation work.
How Do GPT-like Large Language Models Work?
After the proposal of the Transformer, two main branches emerged: one explores the encoder part more deeply, where the structure of the encoder is designed to quickly understand a complete piece of text, making this research direction suitable for understanding the sentiment expressed in a piece of text, filling in missing words (cloze tests), etc.; the other direction delves into the decoder part, where the structure is designed to derive subsequent content word by word based on the perceived information, making it suitable for tasks like content continuation and answering questions. A representative team of this branch is OpenAI.

Since the publication of the Transformer paper, computer scientists at OpenAI have keenly sensed its potential and quickly organized teams to conduct in-depth research, especially on the decoder part. Starting in 2018, OpenAI successively released GPT1.0, GPT2.0, GPT3.0, WebGPT, InstructGPT, and finally ChatGPT on November 30, 2022. Since then, almost all teams have focused on the decoder part, and in the past year, models such as Claude, Llama, Gemini, Tongyi Qianwen, Wenxin Yiyan, ChatGLM, Baichuan, etc., have been trained primarily on the decoder structure. Therefore, if you see the term “Decoder-Only” in some articles in the future, it refers to models based on the decoder structure of the Transformer.
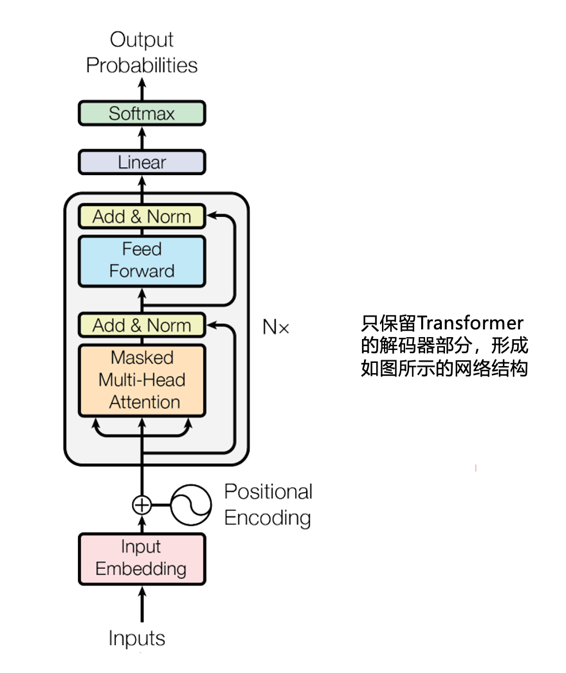
So, how does the GPT-like large language model (hereinafter referred to as GPT for simplicity) developed on the decoder structure actually work? Since the design of this part’s structure is to use the Attention mechanism to quickly perceive the acquired information and derive subsequent content word by word, the working principle of GPT can be summarized in one sentence: predicting the next word based on known content.
GPT can be intuitively compared to the input method we use daily. When we input a Chinese character, the input method suggests the next most likely character to continue inputting, helping us complete our input quickly. The power of GPT lies in its ability to not only perceive the previous input character but also all previously known information, continuously predicting the next character based on this information.
We can think of GPT as a function where the input is the known information and the output is the next character. For example, if the input content we ask GPT (commonly referred to as the prompt) is “Please explain the concept of large language models,” the following image illustrates its working mechanism.

GPT will continue to predict the next character until it determines that “current answer is complete”. This is also why the results are output gradually when using GPT. Although this mechanism seems uncomplicated, the strength of GPT lies in its ability to provide high-quality responses even to very complex questions posed by users. This requires a large model, high-quality data, and powerful computing power to construct this model. In the following articles, we will further explore the training process of GPT and the key capabilities it presents.
Prompt: Refers to the segment of text input provided to the large language model to guide it in generating the corresponding output. This prompt can be a question, instruction, an introduction to a paragraph, or any other form of text, serving to set the context and help the model understand the user’s intent and generate responses or complete tasks relevant to that context.

END

