
Foreword
If your hard drive is running low on space, check this out first for a thrill. Running models has become as easy as changing packages. This article introduces the Ollama framework developed in Go language, which allows users to run large models locally. Through Ollama, users can download and run different models, and generate conversations via the terminal or API. Today’s front-end morning reading article is shared by @Yang Peng, authorized by the public account: Qiwu Selected.
The main content starts here~~
Introduction to Ollama
Ollama is an open-source framework developed in Go language that can run large models locally.
Official website: https://ollama.com/
GitHub address: https://github.com/ollama/ollama
Installing Ollama
Download and Install Ollama
Choose the corresponding installation package based on your operating system type on the Ollama official website. Here, we choose to download and install for macOS.
After installation, enter ollama in the terminal to see the commands supported by ollama.
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.Check the ollama version
ollama -v
ollama version is 0.1.31Check downloaded models
ollama list
NAME ID SIZE MODIFIED
gemma:2b b50d6c999e59 1.7 GB 3 hours agoI already have a large model locally, next we will see how to download a large model.
Downloading a Large Model
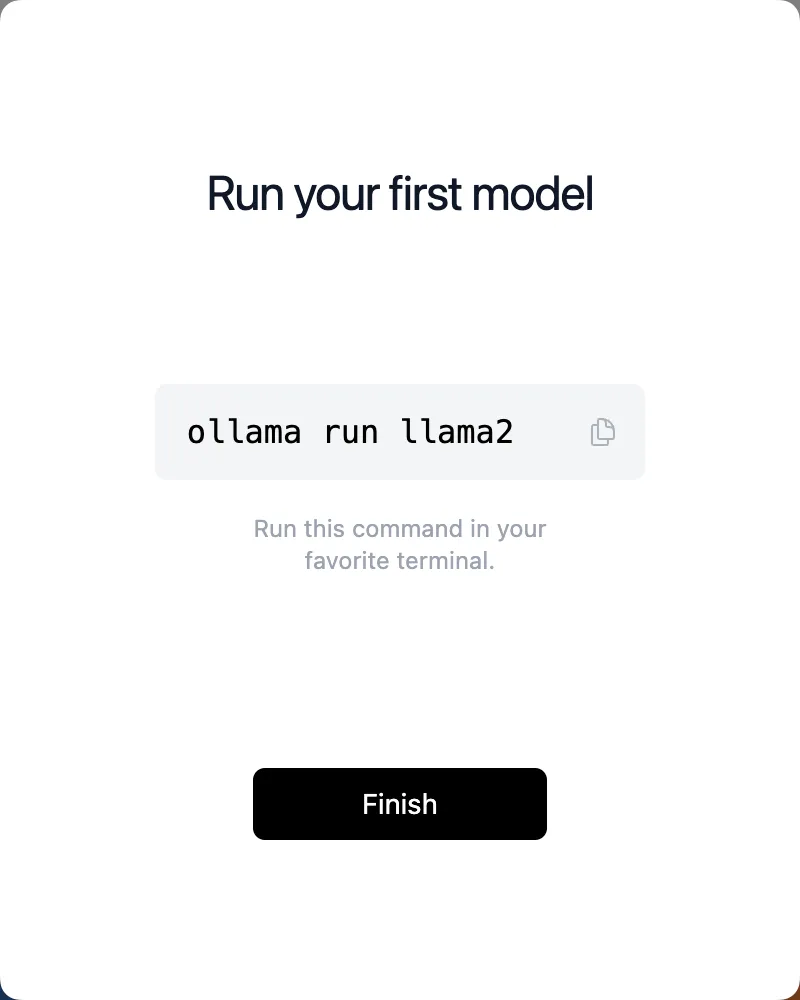 Download the model
Download the model
After installation, it will by default prompt to install the llama2 large model, below are some models supported by Ollama
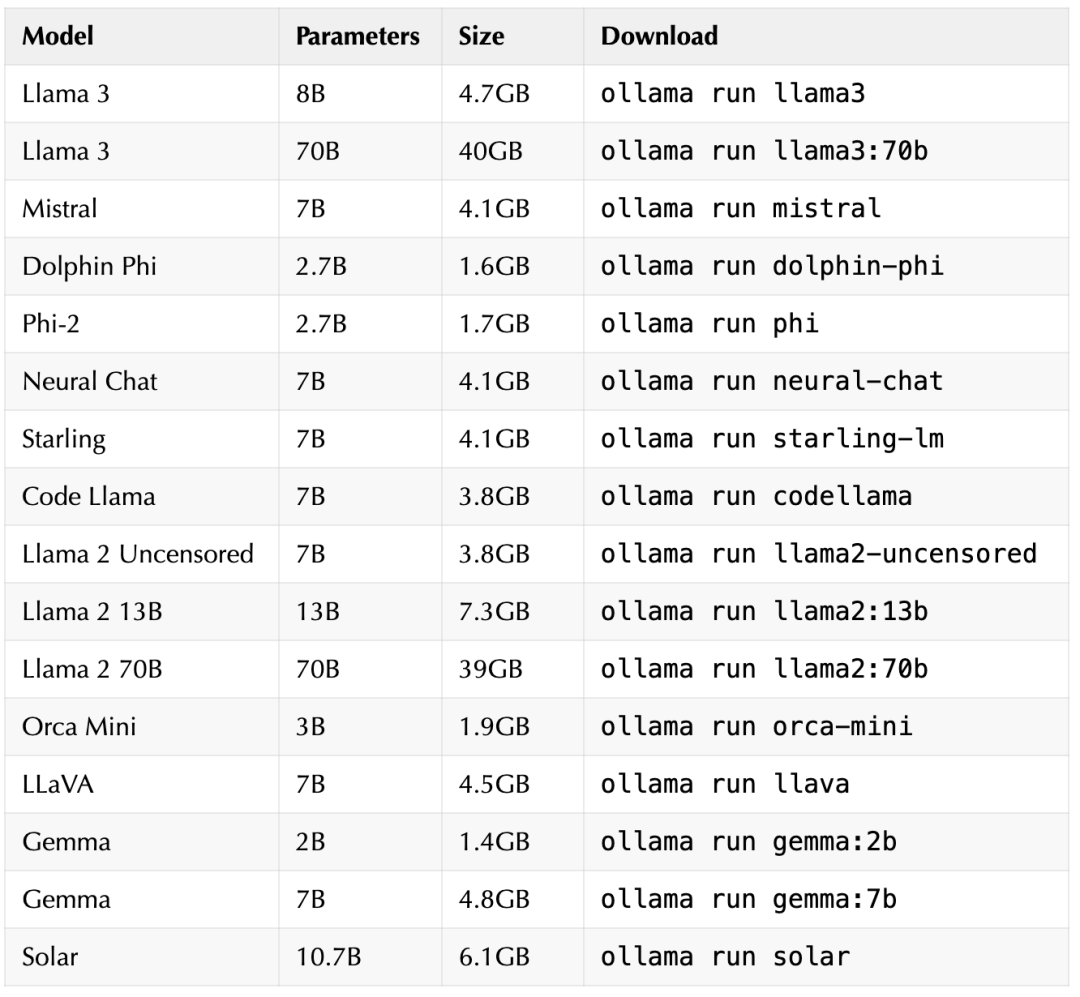
Llama 3 is a large language model open-sourced by Meta on April 19, 2024, with versions of 8 billion and 70 billion parameters, both supported by Ollama.
Here we choose to install gemma 2b, open the terminal, and execute the following command:
ollama run gemma:2b pulling manifest
pulling c1864a5eb193... 100% ▕██████████████████████████████████████████████████████████▏ 1.7 GB
pulling 097a36493f71... 100% ▕██████████████████████████████████████████████████████████▏ 8.4 KB
pulling 109037bec39c... 100% ▕██████████████████████████████████████████████████████████▏ 136 B
pulling 22a838ceb7fb... 100% ▕██████████████████████████████████████████████████████████▏ 84 B
pulling 887433b89a90... 100% ▕██████████████████████████████████████████████████████████▏ 483 B
verifying sha256 digest
writing manifest
removing any unused layers
successAfter a while, it shows that the model download is complete.
The above table only shows some models supported by Ollama, more models can be viewed at https://ollama.com/library, including Chinese models like Alibaba’s Tongyi Qianwen.
Terminal Conversation
After downloading, you can directly have a conversation in the terminal, such as asking “Introduce React”
>>> Introduce ReactThe output is as follows:

Show Help Command -/?
>>> /?
Available Commands:
/set Set session variables
/show Show model information
/load <model> Load a session or model
/save <model> Save your current session
/bye Exit
/?, /help Help for a command
/? shortcuts Help for keyboard shortcuts
Use """ to begin a multi-line message.Show Model Information Command -/show
>>> /show
Available Commands:
/show info Show details for this model
/show license Show model license
/show modelfile Show Modelfile for this model
/show parameters Show parameters for this model
/show system Show system message
/show template Show prompt templateShow Model Details Command -/show info
>>> /show info
Model details:
Family gemma
Parameter Size 3B
Quantization Level Q4_0API Calls
In addition to having conversations directly in the terminal, ollama can also be called via API. For example, executing ollama show –help will show the local access address as: http://localhost:11434
ollama show --help
Show information for a model
Usage:
ollama show MODEL [flags]
Flags:
-h, --help help for show
--license Show license of a model
--modelfile Show Modelfile of a model
--parameters Show parameters of a model
--system Show system message of a model
--template Show template of a model
Environment Variables:
OLLAMA_HOST The host:port or base URL of the Ollama server (e.g. http://localhost:11434)Next, we will mainly introduce two APIs: generate and chat.
Generate
Streaming return
curl http://localhost:11434/api/generate -d '{
"model": "gemma:2b",
"prompt":"Introduce React, within 20 words"
}' {"model":"gemma:2b","created_at":"2024-04-19T10:12:32.337192Z","response":"React","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:32.421481Z","response":" 是","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:32.503852Z","response":"一个","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:32.584813Z","response":"用于","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:32.672575Z","response":"构建","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:32.754663Z","response":"用户","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:32.837639Z","response":"界面","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:32.918767Z","response":"(","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:32.998863Z","response":"UI","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:33.080361Z","response":")","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:33.160418Z","response":"的","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:33.239247Z","response":" JavaScript","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:33.318396Z","response":" 库","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:33.484203Z","response":"。","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:33.671075Z","response":"它","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:33.751622Z","response":"允许","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:33.833298Z","response":"开发者","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:33.919385Z","response":"轻松","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:34.007706Z","response":"构建","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:34.09201Z","response":"可","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:34.174897Z","response":"重","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:34.414743Z","response":"用的","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:34.497013Z","response":" UI","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:34.584026Z","response":",","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:34.669825Z","response":"并","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:34.749524Z","response":"与","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:34.837544Z","response":"各种","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:34.927049Z","response":" JavaScript","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:35.008527Z","response":" ","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:35.088936Z","response":"框架","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:35.176094Z","response":"一起","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:35.255251Z","response":"使用","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:35.34085Z","response":"。","done":false}
{"model":"gemma:2b","created_at":"2024-04-19T10:12:35.428575Z","response":"","done":true,"context":[106,1645,108,25661,18071,22469,235365,235284,235276,235960,179621,107,108,106,2516,108,22469,23437,5121,40163,81964,16464,57881,235538,5639,235536,235370,22978,185852,235362,236380,64032,227725,64727,81964,235553,235846,37694,13566,235365,236203,235971,34384,22978,235248,90141,19600,7060,235362,107,108]} Non-streaming return
By setting the “stream”: false parameter, you can set it to return all at once.
curl http://localhost:11434/api/generate -d '{
"model": "gemma:2b",
"prompt":"Introduce React, within 20 words",
"stream": false
}' {
"model": "gemma:2b",
"created_at": "2024-04-19T08:53:14.534085Z",
"response": "React is a large JavaScript library for building user interfaces, allowing you to easily create dynamic websites and applications.",
"done": true,
"context": [106, 1645, 108, 25661, 18071, 22469, 235365, 235284, 235276, 235960, 179621, 107, 108, 106, 2516, 108, 22469, 23437, 5121, 40163, 81964, 16464, 236074, 26546, 66240, 22978, 185852, 235365, 64032, 236552, 64727, 22957, 80376, 235370, 37188, 235581, 79826, 235362, 107, 108]
}Chat
Streaming return
curl http://localhost:11434/api/chat -d '{
"model": "gemma:2b",
"messages": [
{ "role": "user", "content": "Introduce React, within 20 words" }
]
}'You can see the terminal output result:
{"model":"gemma:2b","created_at":"2024-04-19T08:45:54.86791Z","message":{"role":"assistant","content":"React"},"done":false}
{"model":"gemma:2b","created_at":"2024-04-19T08:45:54.949168Z","message":{"role":"assistant","content":"是"},"done":false}
{"model":"gemma:2b","created_at":"2024-04-19T08:45:55.034272Z","message":{"role":"assistant","content":"用于"},"done":false}
{"model":"gemma:2b","created_at":"2024-04-19T08:45:55.119119Z","message":{"role":"assistant","content":"构建"},"done":false}
{"model":"gemma:2b","created_at":"2024-04-19T08:45:55.201837Z","message":{"role":"assistant","content":"用户"},"done":false}
{"model":"gemma:2b","created_at":"2024-04-19T08:45:55.286611Z","message":{"role":"assistant","content":"界面"},"done":false}
{"model":"gemma:2b","created_at":"2024-04-19T08:45:55.37054Z","message":{"role":"assistant","content":" React"},"done":false}
{"model":"gemma:2b","created_at":"2024-04-19T08:45:55.45099Z","message":{"role":"assistant","content":"."},"done":false}
{"model":"gemma:2b","created_at":"2024-04-19T08:45:55.534105Z","message":{"role":"assistant","content":"js"},"done":false}
{"model":"gemma:2b","created_at":"2024-04-19T08:45:55.612744Z","message":{"role":"assistant","content":"框架"},"done":false}
{"model":"gemma:2b","created_at":"2024-04-19T08:45:55.695129Z","message":{"role":"assistant","content":","},"done":false}
{"model":"gemma:2b","created_at":"2024-04-19T08:45:55.775357Z","message":{"role":"assistant","content":"允许"},"done":false}
{"model":"gemma:2b","created_at":"2024-04-19T08:45:55.855803Z","message":{"role":"assistant","content":"开发者"},"done":false}
{"model":"gemma:2b","created_at":"2024-04-19T08:45:55.936518Z","message":{"role":"assistant","content":"轻松"},"done":false}
{"model":"gemma:2b","created_at":"2024-04-19T08:45:56.012203Z","message":{"role":"assistant","content":"地"},"done":false}
{"model":"gemma:2b","created_at":"2024-04-19T08:45:56.098045Z","message":{"role":"assistant","content":"创建"},"done":false}
{"model":"gemma:2b","created_at":"2024-04-19T08:45:56.178332Z","message":{"role":"assistant","content":"动态"},"done":false}
{"model":"gemma:2b","created_at":"2024-04-19T08:45:56.255488Z","message":{"role":"assistant","content":"网页"},"done":false}
{"model":"gemma:2b","created_at":"2024-04-19T08:45:56.336361Z","message":{"role":"assistant","content":"。"},"done":false}
{"model":"gemma:2b","created_at":"2024-04-19T08:45:56.415904Z","message":{"role":"assistant","content":""},"done":true,"total_duration":2057551864,"load_duration":568391,"prompt_eval_count":11,"prompt_eval_duration":506238000,"eval_count":20,"eval_duration":1547724000}The default is streaming return, and it can also be set to return all at once by using the “stream”: false parameter.
The difference between generate and chat is that generate is for one-time data generation. Chat can include historical records for multi-turn conversations.
Web UI
In addition to the above terminal and API calling methods, there are currently many open-source Web UIs available to set up a visual page for conversation locally, such as:
open-webui: https://github.com/open-webui/open-webui
lollms-webui: https://github.com/ParisNeo/lollms-webui
The cost of learning to run large models locally through Ollama has become very low. If you’re interested, try deploying a large model locally 🎉🎉🎉
References
About the author of this article: @Yang Peng Original text: https://mp.weixin.qq.com/s/7Wl9vJ_DICsfqk1MeOAhxA

If this issue of front-end morning reading is helpful to you, please help “like” it, and look forward to the next issue, help “look” at it.