
On April 18, 2024, Meta open-sourced the Llama 3 large models[1]. Although there are only 8B[2] and 70B[3] versions, the powerful capabilities demonstrated by Llama 3 have shocked the AI large model community. I personally tested the inference capabilities of the Llama3-70B version, which are very close to OpenAI’s GPT-4[4]. Moreover, a 400B super large model is reportedly on its way and is expected to be released in a few months.
The popular local model deployment and running tool project Ollama[5] has also announced support for Llama3 immediately[6]:

Recently, besides learning Rust[7], I have been researching how to apply LLMs in products. The previous path of fine-tuning was not feasible, but recent approaches like RAG (Retrieval-Augmented Generation) and Agents have given me a glimmer of hope. However, the prerequisite for implementing these two paths is a powerful LLM, and the open-source Meta Llama series LLM is the best choice.
In this article, I will first experience how to install and run the Meta Llama3-8B large model based on Ollama, and establish a web graphical access method for the large model using OpenWebUI[8], which is compatible with the Ollama API.
1. Installing Ollama
Ollama is a tool implemented in Go that can smoothly install and run various open-source large models locally. It supports many mainstream open-source models both domestically and internationally, such as Llama, Mistral[9], Gemma[10], DBRX[11], Qwen[12], phi[13], vicuna[14], yi[15], falcon[16], etc. The complete list of supported models can be found in the Ollama library[17].
The installation of Ollama uses “curl | sh”, allowing us to download and install it locally with one command:
$ curl -fsSL https://ollama.com/install.sh | sh
>>> Downloading ollama...
######################################################################## 100.0%
>>> Installing ollama to /usr/local/bin...
>>> Creating ollama user...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink from /etc/systemd/system/default.target.wants/ollama.service to /etc/systemd/system/ollama.service.
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run "ollama" from the command line.
WARNING: No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode.We see that after downloading, Ollama started an ollama systemd service, which is the core API service of Ollama and stays in memory. We can check the running status of this service using systemctl:
$ systemctl status ollama
● ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; vendor preset: disabled)
Active: active (running) since Sun 2024-04-22 17:51:18 CST; 11h ago
Main PID: 9576 (ollama)
Tasks: 22
Memory: 463.5M
CGroup: /system.slice/ollama.service
└─9576 /usr/local/bin/ollama serve
Additionally, I made some changes to Ollama’s systemd unit file. I modified the Environment value to add “OLLAMA_HOST=0.0.0.0”, which allows the OpenWebUI running in a container to access the Ollama API service:
# cat /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/root/.cargo/bin:/usr/local/cmake/bin:/usr/local/bin:.:/root/.bin/go1.21.4/bin:/root/go/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin" "OLLAMA_HOST=0.0.0.0"
[Install]
WantedBy=default.targetAfter making the changes, execute the following commands to make it take effect:
$ systemctl daemon-reload
$ systemctl restart ollama2. Downloading and Running the Large Model
Ollama supports one-click downloading and running of models. I have a cloud virtual machine with 16/32G, but no GPU, so here I am using the Llama3-8B instruction-tuned model for chat/dialogue[18]. We can quickly download and run this model (4-bit quantization) with the following command:
$ ollama run llama3
pulling manifest
pulling 00e1317cbf74... 0% ▕ ▏ 0 B/4.7 GB
pulling 00e1317cbf74... 7% ▕█ ▏ 331 MB/4.7 GB 34 MB/s 2m3s^C
pulling manifest
pulling manifest
pulling manifest
pulling 00e1317cbf74... 61% ▕█████████ ▏ 2.8 GB/4.7 GB 21 MB/s 1m23s^C
... ...After successfully downloading and executing, the command line will wait for your input. Let’s type a question about Go, and here is the output:
$ ollama run llama3
>>> could you tell me something about golang language?
Go!
Here are some interesting facts and features about the Go programming language:
**What is Go?**
Go, also known as Golang, is a statically typed, compiled, and designed to be concurrent and garbage-collected language. It
was developed by Google in 2009.
**Key Features:**
1. **Concurrency**: Go has built-in concurrency support through goroutines (lightweight threads) and channels (communication
mechanisms). This makes it easy to write concurrent programs.
2. **Garbage Collection**: Go has a automatic garbage collector, which frees developers from worrying about memory
management.
3. **Static Typing**: Go is statically typed, meaning that the type system checks the types of variables at compile time,
preventing type-related errors at runtime.
4. **Simple Syntax**: Go's syntax is designed to be simple and easy to read. It has a minimalistic approach to programming
language design.
... ...The inference speed is about 5-6 tokens, which is acceptable, but this process is quite CPU-intensive:
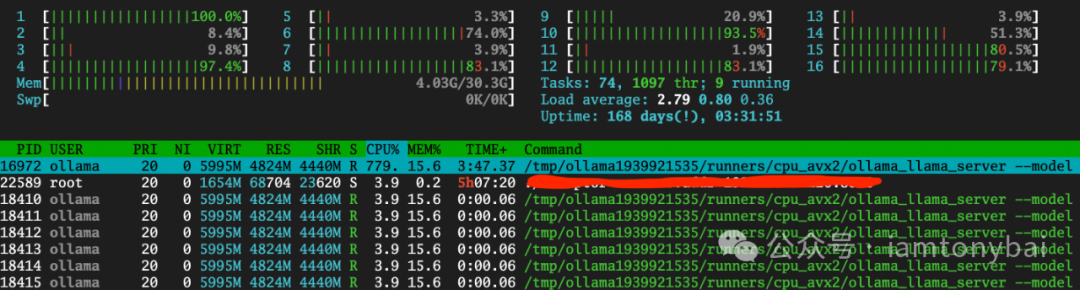
In addition to interacting with the Ollama API service via the command line, we can also use Ollama’s RESTful API:
$ curl http://localhost:11434/api/generate -d '{
> "model": "llama3",
> "prompt":"Why is the sky blue?"
> }'
{"model":"llama3","created_at":"2024-04-22T07:02:36.394785618Z","response":"The","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:36.564938841Z","response":" color","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:36.745215652Z","response":" of","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:36.926111842Z","response":" the","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:37.107460031Z","response":" sky","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:37.287201658Z","response":" can","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:37.468517901Z","response":" vary","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:37.649011829Z","response":" depending","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:37.789353456Z","response":" on","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:37.969236546Z","response":" the","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:38.15172159Z","response":" time","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:38.333323271Z","response":" of","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:38.514564929Z","response":" day","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:38.693824676Z","response":",","done":false}
... ...However, the most common way I interact with large models is still through a Web UI. Currently, there are many Web & Desktop projects that support the Ollama API. Here, we choose Open WebUI[19], which is the predecessor of the Ollama WebUI.
3. Installing and Using Open WebUI to Interact with the Large Model
The fastest way to experience Open WebUI is to use container installation. However, the official image site ghcr.io/open-webui/open-webui:main downloads too slowly, so I found a personal mirror image located on Docker Hub. Below is the command to install Open WebUI locally:
$ docker run -d -p 13000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://host.docker.internal:11434 --name open-webui --restart always dyrnq/open-webui:mainAfter the container starts, we can access the Open WebUI page by visiting port 13000 on the host:
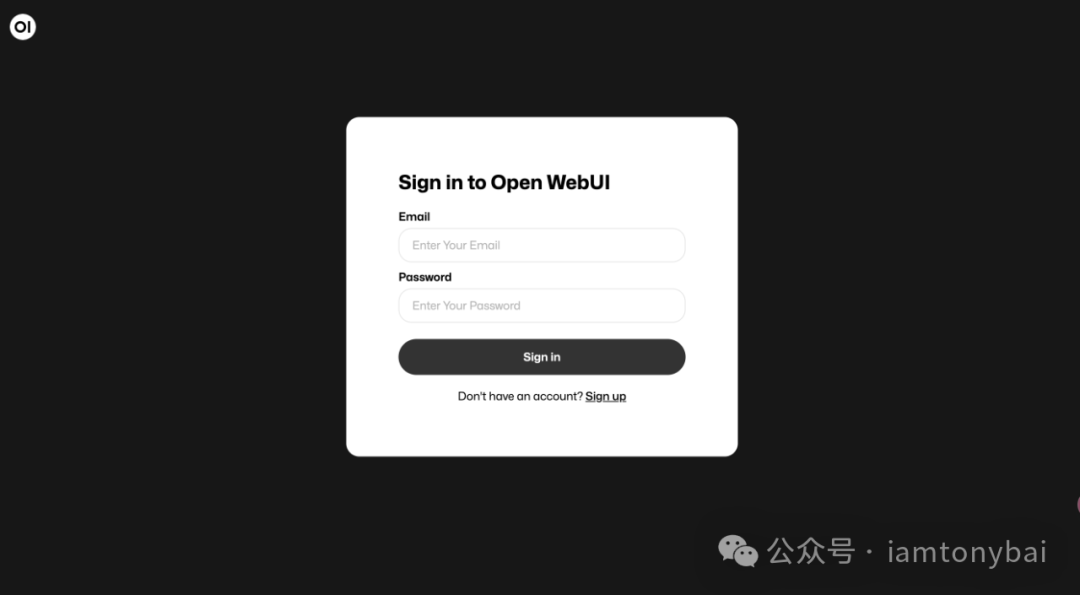
The first registered user will be recognized as the admin user by Open WebUI! After registering and logging in, we can enter the homepage:
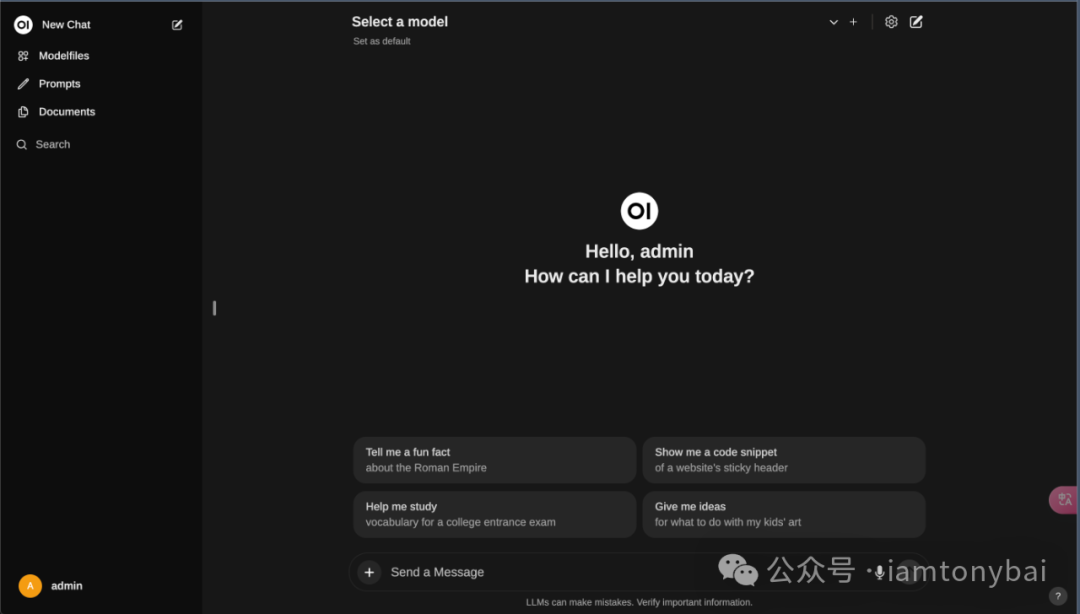
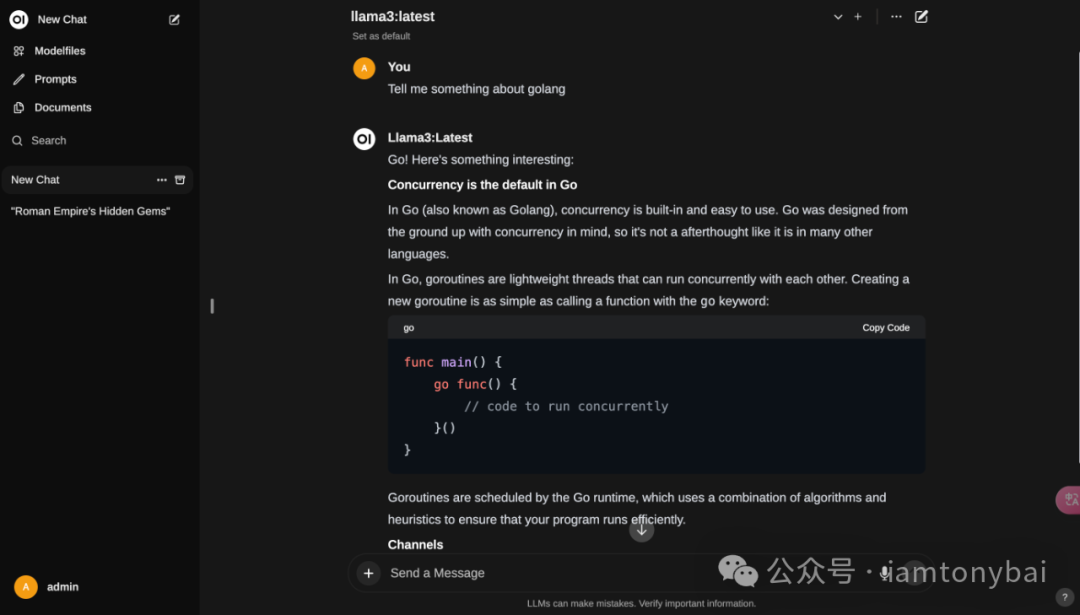
After selecting the model, we can input questions and chat with the Llama3 model deployed by Ollama:
Note: If Open WebUI does not run properly, you can check the logs of the openwebui container to assist in diagnosing the problem.
Open WebUI has many features, and everyone can explore them slowly 🙂
4. Conclusion
In this article, I introduced the Meta open-sourced Llama 3 large model and the use of Ollama and OpenWebUI. Llama 3 is a powerful AI large model, with practical tests showing it is close to OpenAI’s GPT-4, and a more powerful 400B model is about to be released. Ollama is a tool for local deployment and operation of large models, supporting multiple domestic and foreign open-source models, including Llama. I detailed how to install and run Ollama, and how to download and run the Llama3-8B model using Ollama. I demonstrated how to interact with Ollama through the command line and REST API, as well as the model’s inference speed and CPU consumption. Additionally, I mentioned OpenWebUI, a graphical web access method compatible with the Ollama API. Through Ollama and OpenWebUI, everyone can easily use the Meta Llama3-8B large model for inference tasks on CPU and achieve satisfactory results.
In the future, I will further explore how to apply Llama3 in products and delve into the potential of RAG (Retrieval-Augmented Generation) and Agent technologies. These two paths can bring new possibilities for application development based on Llama3.
The Gopher Tribe Knowledge Planet[20] will continue to strive to create a high-quality learning and communication platform for the Go language in 2024. We will continue to provide high-quality first-release technical articles on Go and reading experiences. Meanwhile, we will strengthen the sharing of code quality and best practices, including how to write concise, readable, and testable Go code. Additionally, we will enhance communication and interaction among community members. Everyone is welcome to ask questions, share insights, and discuss technology. I will respond and communicate promptly. I sincerely hope that the Gopher Tribe can become a haven for everyone to learn, progress, and communicate. Let us gather in the Gopher Tribe and enjoy the joy of coding! Everyone is welcome to join!




The famous cloud hosting service provider DigitalOcean has released the latest hosting plan, upgrading the entry-level Droplet configuration to: 1 core CPU, 1G memory, 25G high-speed SSD, priced at $5/month. If you have a need for DigitalOcean, you can open this link[21]: https://m.do.co/c/bff6eed92687 to start your DO hosting journey.
Gopher Daily (Gopher Daily News) – https://gopherdaily.tonybai.com
My contact information:
-
Weibo (currently unavailable): https://weibo.com/bigwhite20xx -
Weibo 2: https://weibo.com/u/6484441286 -
Blog: tonybai.com -
GitHub: https://github.com/bigwhite -
Gopher Daily Archive – https://github.com/bigwhite/gopherdaily

Business cooperation methods: writing, publishing books, training, online courses, entrepreneurial partnerships, consulting, advertising cooperation.
Meta open-sourced the Llama 3 large model: https://ai.meta.com/blog/meta-llama-3/
[2]8B: https://huggingface.co/meta-llama/Meta-Llama-3-8B
[3]70B: https://huggingface.co/meta-llama/Meta-Llama-3-70B
[4]OpenAI’s GPT-4: https://openai.com/research/gpt-4
[5]Ollama: https://github.com/ollama/ollama
[6]Announced support for Llama3 immediately: https://ollama.com/blog/llama3
[7]Learning Rust: https://tonybai.com/2024/04/22/gopher-rust-first-lesson-all-about-rust/
[8]OpenWebUI: https://github.com/open-webui/open-webui
[9]Mistral: https://mistral.ai/
[10]Gemma: https://ai.google.dev/gemma
[11]DBRX: https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm
[12]Qwen: https://github.com/QwenLM/Qwen
[13]Phi: https://huggingface.co/microsoft/phi-2
[14]Vicuna: https://lmsys.org/blog/2023-03-30-vicuna/
[15]Yi: https://github.com/01-ai/Yi
[16]Falcon: https://huggingface.co/blog/falcon
[17]Ollama library: https://ollama.com/library
[18]Llama3-8B instruction-tuned model for chat/dialogue: https://ollama.com/library/llama3
[19]Open WebUI: https://github.com/open-webui/open-webui
[20]The Gopher Tribe Knowledge Planet: https://public.zsxq.com/groups/51284458844544
[21]Link: https://m.do.co/c/bff6eed92687