
In this study, the authors propose an improved variant of MobileViT that performs attention-based QKV operations in the early stages of downsampling. Performing QKV operations directly on high-resolution feature maps is computationally intensive due to their large size and numerous tokens.
To address this issue, the authors introduce a filtering attention mechanism that uses convolutional neural networks (CNN) to generate an importance mask (Filter Mask), which is used to select the most informative pixels for attention computation.
Specifically, the CNN scores the pixels of the feature map and ranks them based on these scores to select the top K pixels (the number varies across different network layers). This method effectively reduces the number of tokens participating in attention computation, thereby lowering computational complexity and increasing processing speed.
Moreover, the authors find that the importance mask is interpretable, as the model focuses more on the image regions that are crucial to the results.
Experimental results show that the authors’ model achieves high precision while improving parameter efficiency and computational speed.
Compared with other models, the authors’ method maintains high performance while reducing computational resource consumption.
I Introduction
Vision Transformer (ViT) [1] has revolutionized the field of computer vision by introducing a transformer-based architecture. ViT utilizes the attention mechanism to operate on 16×16 image patches, achieving global context learning of images. However, despite ViT achieving state-of-the-art results across various tasks, its reliance on large tokens incurs high computational costs when applied to high-resolution images. The quadratic complexity of QKV operations [2] means that increasing the number of tokens significantly increases the computational burden.
To address this issue, MobileViT [3] serves as a lightweight version of ViT, performing attention computations after downsampling the image. This reduces the number of tokens involved in attention, thereby improving computational efficiency. However, MobileViT sacrifices fine granularity by operating on downsampled feature maps (e.g., 56×56 or 28×28), which may limit its ability to capture finer details. Additionally, not all pixels contribute equally to the final prediction. Many pixels are noise or irrelevant, while other pixels are critical for decision-making.
In this paper, the authors propose a new variant of MobileViT called FilterVit, which allows for finer-grained attention without early downsampling. The authors’ method leverages a convolutional neural network (CNN) to generate an importance mask that determines which pixels in the feature map are most relevant for attention. By aligning and selecting the top K pixels based on pixel importance scores, the authors perform attention only on the most important parts of the image, thereby reducing the computational complexity of QKV operations.
Unlike the challenging task of implementing sparse matrix operations on GPUs, the authors’ method provides a practical solution by directly selecting important pixels. This ensures a reduction in computational load while maintaining accuracy.
Moreover, the authors’ method is interpretable, as the importance mask highlights the key areas of the image that the model focuses on during attention. For instance, in an image of a sheep, the mask effectively highlights the contours of the sheep while ignoring irrelevant background features.
In summary, the authors’ contributions are threefold:
- The authors propose a lightweight and more efficient attention mechanism that achieves finer-grained attention while reducing computational complexity.
- The authors’ method is inherently interpretable, as it focuses on the most relevant areas of the image, which can be demonstrated through the visualization of the importance mask.
- Through an ablation study, the authors introduce DropoutVIT, a variant of the authors’ model that simulates dropout by randomly selecting pixels, further validating the scalability and robustness of the authors’ method.
II Related Work
Vision Transformers
Vision Transformers (ViT) [1] have achieved significant success in computer vision tasks by applying attention mechanisms to image patches (typically 16×16 patches).
Although ViT performs well in capturing global dependencies in images, the quadratic complexity of its QKV operations [2] poses computational challenges, especially for high-resolution images. As image resolution increases, the number of tokens rapidly rises, leading to a significant increase in computational costs.
MobileViT
MobileViT [3] addresses this issue by downsampling the image before applying transformer-based attention.
By performing attention at smaller resolutions (e.g., 56×56 or 28×28), the number of tokens can be reduced, thus lowering computational complexity. However, this downsampling sacrifices the granularity of attention, potentially missing some subtle details when attention is applied to lower-resolution feature maps.
Efficient Attention Mechanisms
Several attention-based models have been proposed to optimize computational complexity. Longformer [4] employs a sparse attention mechanism, limiting attention to a local window around each token, thus reducing computational load, though it may struggle to capture global dependencies in images.
Performer [5] uses kernel-based methods to approximate softmax attention, achieving linear complexity proportional to sequence length, which is a promising approach to reduce attention costs in visual tasks. Linformer [6] further reduces complexity by mapping keys and values to lower dimensions, saving memory while maintaining linear complexity. Reformer [7] introduces locality-sensitive hashing (LSH) to approximate nearest neighbors in attention space, making computations more efficient, though this approach may face challenges when high-detail structures are required.
Lightweight Convolutional Architectures
In addition to attention mechanisms, lightweight convolutional architectures have also been developed to balance efficiency and performance. MobileNetV2 [8] introduces inverted residual modules to optimize information flow, requiring fewer parameters. MobileNetV3 [9] improves upon this by designing efficient structures through neural architecture search (NAS), optimizing latency and accuracy.
EfficientNet [10] scales networks by balancing depth, width, and resolution, achieving optimal performance across configurations. GhostNet [11] improves speed and reduces parameter count by generating fewer feature maps, ultimately focusing on achieving low-complexity convolutional operations for faster inference times while maintaining reasonable accuracy, making it well-suited for edge computing tasks.
Filter Attention Mechanism
The authors’ work builds upon these advancements by introducing the Filter Attention mechanism. Unlike models that downsample or linearize attention computations, the authors’ method selectively applies attention to the most important pixels using a filter mask generated by a convolutional neural network. By ranking pixels based on their importance and selecting the top K pixels, the number of tokens involved in QKV computations is reduced.
This maintains global context while significantly lowering computational complexity without sacrificing attention granularity. The authors’ method is also interpretable, as visualizing the filter mask can show the model’s effective focus on the most relevant parts of the image.
III Method
Structure
In the network architecture proposed by the authors, convolutional layers are combined with transformer layers to achieve a balance between local feature extraction and global attention. The key innovation of the authors’ method is the introduction of a Filter Attention mechanism that selectively focuses on important areas of the feature map, significantly reducing the computational complexity of attention-based computations.
The network processes the input image through a convolutional neural network (CNN) to produce a feature map. This feature map is treated as a set of reshaped tokens, which are passed through a Transformer Encoder [2]. Unlike traditional attention mechanisms, the authors’ Filter Attention selectively identifies important tokens based on the filtering mask generated by the CNN, thereby reducing the number of tokens used in attention computations.
This mechanism allows the model to ignore irrelevant regions of the image, as not every pixel contributes equally to the final prediction. Theoretically, certain pixels may represent noise or useless details, and even among useful pixels, their contributions to predictions are not uniform [13].
Filter Attention Block
The core of the authors’ method is the Filter Attention block, which integrates convolutional blocks with the transformer encoder. The key idea is to treat the pixels in the feature map as tokens for the transformer encoder, but instead of processing all tokens, a filter mask is applied to select the most important few.
First, the image is processed through a convolutional neural network (CNN) module to generate a feature map. The CNN also produces a convolutional mask that assigns importance scores to each pixel. Then, the feature map is element-wise multiplied with the mask to filter out less important tokens, as expressed in the following formula:
Here, denotes element-wise multiplication, ensuring that only the most relevant pixels are retained for further attention-based computations.
Next, the filtered tokens will be reshaped into a shape suitable for the transformer structure, where denotes the number of filtered selected tokens. The filtered tokens are passed through a Transformer Encoder [2], producing output .
The filtering attention mechanism (Filter Attention mechanism) is described in detail as follows. By calculating the importance map and applying the Transformer Encoder, this mechanism can selectively focus on the most informative pixels in the feature map. This approach reduces computational complexity while retaining critical spatial information.
Inverted Residual Block
In the authors’ network, the inverted residual module [8] is used to enhance feature extraction while maintaining model efficiency. This module first expands the input channels, applies pointwise convolution, and then projects the output back to its original size, creating a residual connection. This structure ensures the retention of important spatial information while reducing the number of parameters in the model, making it computationally efficient for both small and large visual tasks.
Global Self-Attention with Pooling
To further reduce the computational complexity of the attention mechanism, the authors perform average pooling on the feature map before inputting it into the self-attention layer. Pooling reduces the spatial dimensions of the input feature map, thereby lowering the number of tokens entering the attention module, thus reducing the quadratic cost of QKV operations. Despite this reduction, global context is still preserved, ensuring that the model can still capture long-range dependencies between the most relevant regions in the image.
Transformer Encoder
The selected tokens from the filtered feature map are passed to the Transformer Encoder [2] for processing. The transformer layer applies self-attention mechanisms to capture global dependencies between tokens. After passing through the transformer, the tokens are reshaped back to their original spatial dimensions and further optimized through subsequent CNN layers.
Finally, the output feature map is used for classification or other downstream tasks, leveraging the local and global information extracted from the image.
IV Experiment
The authors conducted experiments using five different img-100 subsets, each randomly sampled from the ImageNet-1K dataset [14]. The results presented in this paper are based on the first img-100 subset. To ensure fair comparisons, all models were trained under unified settings and hyperparameters.
The specific category selections for the five img-100 subsets used in this study have been provided on GitHub https://github.com/BobSun98/FilterVIT for reference and reproducibility.
Dataset
The img-100 subset is constructed from 100 randomly selected categories from the ImageNet-1K dataset [14]. Training and validation are performed on these subsets. Each model is trained on these five different subsets to enhance robustness and reduce overfitting, ensuring that the reported results are not biased by the choice of specific subsets. The smaller img-100 dataset allows for faster prototyping and algorithm validation while still posing challenges in reducing overfitting. If lightweight models perform well on smaller datasets, they are likely to have better generalization capabilities.
Iv-A1 Data Augmentation
To improve the generalization ability of all models, the authors applied uniform data augmentation techniques during training. These techniques include: random scaling (224) to randomly scale and resize images to 224×224 pixels, random horizontal flipping (RandomHorizontalFlip) to randomly flip images horizontally, introducing a wide variety of simple augmentations (TrivialAugmentWide [15]), and normalization using a mean of [0.5, 0.5, 0.5] and a standard deviation of [0.5, 0.5, 0.5]. During the validation phase, images are scaled to 256×256 pixels and then center-cropped to 224×224 pixels, using the same mean and standard deviation values as before.
Training and Hyperparameters
All models are trained using the same hyperparameters. The batch size is set to 64, and the learning rate is set to 0.0005, which decays to a minimum learning rate of 1e-5 using a cosine annealing schedule [16].
The models are trained for 120 epochs using the AdamW optimizer [17], with β1 set to 0.9, β2 set to 0.999, and weight decay set to 0.01. The learning rate scheduler CosineAnnealingLR has a maximum period of 120 epochs and a minimum learning rate of 1e-5.
Hardware Configuration
The training is conducted on a Tesla P40 GPU. Performance on CUDA is measured in frames per second (FPS) on an RTX 4090 GPU, while CPU performance is evaluated on an Apple M1 Pro chip. These hardware configurations allow for a comparison of the efficiency of each model in high-performance and resource-constrained environments.
V Experiment
The authors conducted experiments using five different img-100 subsets from the ImageNet-1K dataset [14]. The results presented in this paper are based on the first img-100 subset. To ensure fair comparisons, all models were trained under unified settings and hyperparameters.
The specific category selections for the five img-100 subsets used in this study have been provided on GitHub for reference and reproducibility: https://github.com/BobSun98/FilterVIT.
Dataset
The img-100 subset is constructed from 100 randomly selected categories from the ImageNet-1K dataset [14]. Training and validation are performed on these subsets. Each model is trained on these five different subsets to enhance robustness and reduce overfitting, ensuring that the reported results are not biased by the choice of specific subsets. The smaller img-100 dataset allows for faster prototyping and algorithm validation while still posing challenges in reducing overfitting. If lightweight models perform well on smaller datasets, they are likely to have better generalization potential.
V-B1 Data Augmentation
To improve the generalization ability of all models, the authors applied uniform data augmentation techniques during training. These techniques include: random scaling (224) to randomly scale and crop images to 224×224 pixels, random flipping (horizontal) to randomly flip images, introducing a wide range of augmentation variations [15] (TrivialAugmentWide), and normalization using a mean of [0.5,0.5,0.5] and a standard deviation of [0.5,0.5,0.5]. During the validation phase, images are resized to 256×256 pixels and then center-cropped to 224×224 pixels, using the same mean and standard deviation values as before.
Models and Baselines
To evaluate the effectiveness of the proposed FilterMobileViT, the authors compared it with several baseline models that represent various architectures in the field of efficient neural networks. These include MobileNetV2 [8], known for its inverted residual blocks and linear bottleneck, as well as MobileNetV3 [9], which improves upon its predecessor through neural architecture search and hard Swish activation functions. The authors also included EfficientNet-Lite0 [10], which achieves optimal efficiency balance among network depth, width, and resolution, and GhostNet [11], which improves computational performance by reducing redundancy in feature maps.
In addition to convolutional architectures, the authors compared with lightweight transformer models such as TinyViT [18], a small vision transformer designed for high performance with fewer parameters, and LeViT [19], a hybrid model that combines convolutional and transformer layers for efficient inference. The authors also included TinyNet [20], a family of models optimized for small parameter sizes and computational costs, as well as LCNet [12], which prioritizes speed in lightweight convolutional network designs. Finally, MobileViT was included as it integrates transformer layers into a mobile-friendly architecture, similar to the authors’ approach.
These models were selected to provide a comprehensive comparison across different architectural strategies, highlighting the advantages of the authors’ FilterMobileViT in terms of accuracy and efficiency.
Training Details
All models were trained using consistent hyperparameters: a batch size of 64, using the AdamW optimizer [17] (with weight decay of 0.01). The initial learning rate is set to 0.0005 and decays to a minimum after following a cosine annealing schedule [16] over 120 epochs. The training is conducted on a Tesla P40 GPU, while inference performance is measured on both the CUDA RTX 4090 GPU and the Apple M1 Pro chip CPU. These configurations allow for a comprehensive comparison of model efficiency across different hardware environments, from high-performance GPUs to resource-constrained CPUs.
Experimental Results
Table 1 shows that FilterMobileViT achieves a good balance between accuracy and computational efficiency. With only 1.89 million parameters, it achieves an accuracy of 0.861, surpassing most models except for Tiny-ViT [18], which has slightly higher accuracy at 0.876 but with a larger parameter count (10.59M). This indicates that while Tiny-ViT performs slightly better, FilterMobileViT offers a more efficient solution in terms of model size, making it more suitable for deployment in resource-constrained environments.
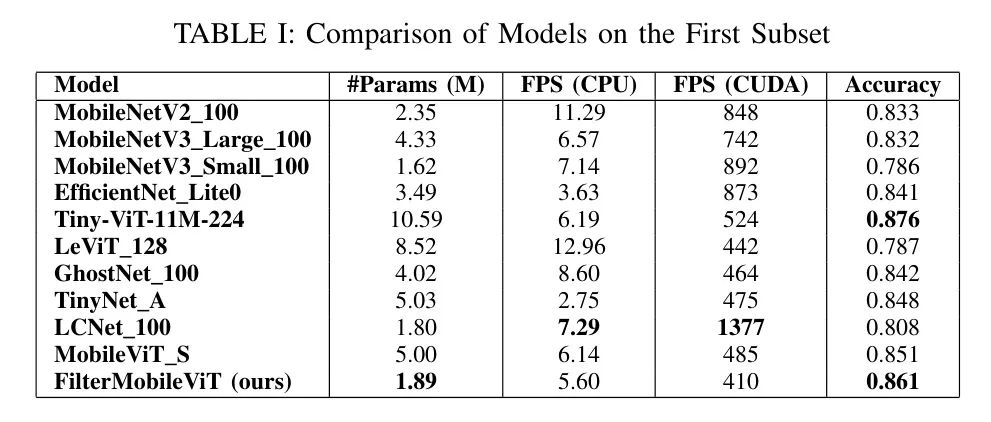
FilterMobileViT also demonstrates competitive performance in terms of frames per second (FPS). Although it is slightly outperformed by models like LCNet_100 in terms of FPS on CPU and CUDA platforms, LCNet focuses more on speed than accuracy, resulting in an accuracy of 0.808, while FilterMobileViT achieves a better trade-off between speed and accuracy, maintaining high accuracy with reasonable computational efficiency.
Additionally, compared to lightweight models like MobileNetV2 [8] and GhostNet [11], FilterMobileViT not only reduces the number of parameters but also improves accuracy. For example, MobileNetV2 has 2.35 million parameters with an accuracy of 0.833, while GhostNet has 4.02 million parameters achieving an accuracy of 0.842. This improvement highlights the effectiveness of the Filter Attention mechanism in selectively focusing on the most informative areas of the image, achieving better performance without increasing computational costs.
In terms of inference speed, although EfficientNet_Lite0 and MobileNetV3_Small have higher FPS on CUDA, their accuracy is lower compared to FilterMobileViT. This further highlights the advantage of the authors’ method in achieving balanced performance, suitable for applications where both accuracy and efficiency are core requirements.
Overall, FilterMobileViT demonstrates that integrating the Filter Attention mechanism can significantly enhance accuracy and efficiency, surpassing several existing models in the field. Its smaller parameter count and competitive speed make it an attractive option for deployment on devices with limited computational resources.
For example, [21] proposed an attention expansion method for visualizing attention maps, providing insights into where the model focuses during predictions. Similarly, [22] developed techniques to analyze the internal representations of ViTs by clustering their learned features. Additionally, Vit-CX [13] utilizes the last-layer representations of ViTs and employs clustering to represent the model’s areas of focus. In the authors’ experiments, they found that FilterVIT is inherently interpretable without the need for additional visualization techniques.
To better understand the behavior of FilterMobileVit, the authors visualized the filter masks generated by each Filter Attention layer. This was accomplished by running inference on a test image set from the pretrained model and extracting the filter masks at different layers. These masks were then resized to match the original image size and overlaid on the input images to provide a clear visual representation of the areas the model focuses on [23].
In the first Filter Attention layer, the model tends to focus on both foreground and background, sometimes highlighting the edges of objects. This indicates that the first layer is responsible for identifying broad and general features of the image. As the authors move deeper into the second layer, the focus shifts more towards the main object or foreground of the image, indicating that the model has begun to optimize its attention and concentrate on the most prominent features. In the third and final layers, attention shifts back to the background, possibly to optimize overall context and ensure that irrelevant areas are appropriately weighted.
This cooperative behavior suggests that the filtering attention mechanism not only selects computationally important areas but also helps the model understand the image at different granularities. By progressively optimizing its attention from edges to main objects and then to the background, FilterMobileVit exhibits interpretability in its decision-making process, as illustrated in Figure 5.

These observations indicate that the model’s filter masks are not arbitrary settings but reflect a structured approach to understanding the image. Each layer contributes unique aspects of the image, allowing the model to effectively balance attention between foreground objects and the broader environment. This hierarchical attention structure not only enhances performance but also provides a more interpretable understanding of how the model processes visual information, while validating the correctness of the design.
Ablation Study: DropOutVIT
In this study, the authors introduce a variant of the FilterVIT model called DropOutVIT. The key difference between DropOutVIT and FilterVIT lies in how the model selects pixels for attention computation. FilterVIT deterministically selects the most important pixels using the filter mask generated by the CNN, while DropOutVIT replaces this mechanism with a random sampling approach, randomly selecting a portion of pixels during each training step to pass through the Transformer Encoder. This can be viewed as applying dropout in the attention computation, introducing a degree of randomness to the selection process [24].
The rationale behind DropOutVIT is to explore whether random sampling of pixels can lead to similar or improved performance, thereby preventing overfitting to specific features. By introducing randomness, the authors hypothesize that the model may perform better before the filter mask of FilterVIT is fully optimized during large-scale training, particularly in terms of generalization capabilities.
V-1 DropOutVIT vs. FilterVIT
The authors compared the performance of DropOutVIT and FilterVIT across several training runs (see Figure 6). Initially, both models exhibited similar performance, with DropOutVIT performing slightly better in the first few epochs. This could be attributed to the increased diversity of features selected during the random sampling process, potentially preventing overfitting.
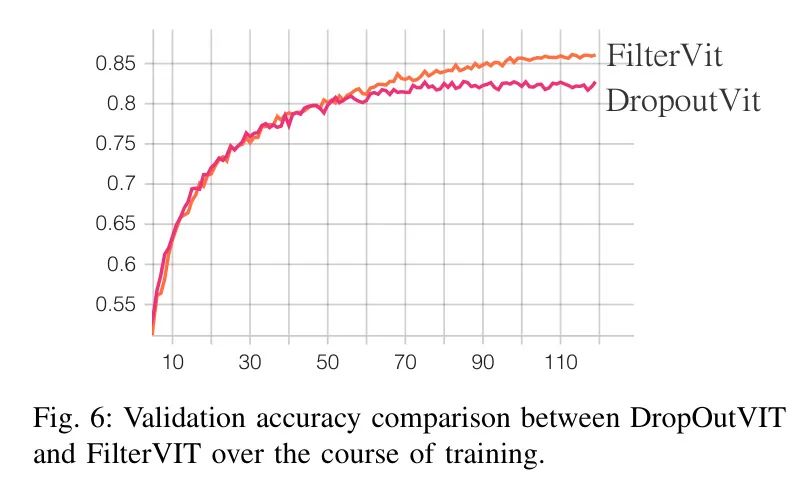
However, as training progressed, DropOutVIT appeared to reach a performance plateau around the 50th epoch, while FilterVIT continued to improve.
A possible explanation for this phenomenon is that the CNN in FilterVIT gradually learns to generate more meaningful filter masks, enabling the model to focus on the most important pixels for attention computation. This refined selection process may allow FilterVIT to achieve better overall performance as the model increasingly benefits from targeted attention.
References
[0]. FilterVIT and DropoutVIT.
