In this article, we will learn how to leverage Llama-3 to implement an advanced RAG with a fully local infrastructure.This article provides a firsthand guide for the first day of implementing advanced RAG.
◆Introduction:
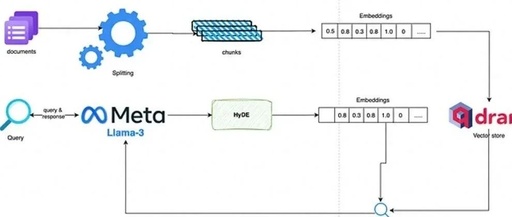
In this article, we will create an advanced RAG that will answer user queries based on research papers provided as input to the pipeline. The technology stack used to build this pipeline is as follows.
-
Ollama embedding model mxbai-embed-large
-
Ollama quantized Llama-3 8b model
-
Locally hosted Qdrant vector database.
With this setup, two obvious things are that the incurred costs are absolutely zero, and the information is highly secure and private.
◆What is HyDE?
HyDE (Hypothetical Document Embedding) originates from the innovative work proposed by Gau et al. in their 2022 paper titled “Zero-Shot Dense Retrieval Without Relevant Labels.” The main goal of this research is to enhance zero-shot dense retrieval that relies on semantic embedding similarity. The proposed solution, HyDE, operates through a two-step approach.
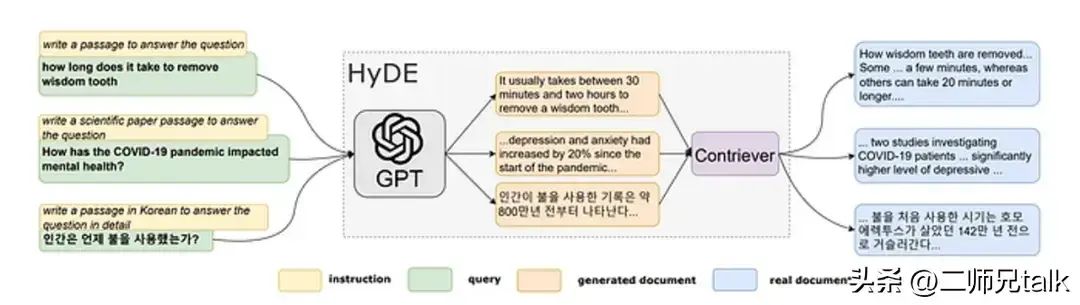
In the initial step (referred to as “Step 1”), the language model (specifically GPT-3 as an example) guides the generation of hypothetical documents based on the original query through instruction prompting. This process is carefully tailored to the questions posed in the paper, ensuring relevance even though the documents are hypothetical.
Moving to Step 2, the generated hypothetical documents are converted into embedding vectors by utilizing Contriever (characterized as an “unsupervised contrastive encoder”). This encoder helps transform the hypothetical documents into vector representations, which are then used for subsequent similarity search and retrieval tasks.
The core functionality of HyDE is to convert documents into vector embeddings through two key components. The first aspect involves using the language model’s generation tasks, aimed at capturing relevance even in hypothetical documents while acknowledging the possibility of factual inaccuracies. Subsequently, the document-document similarity tasks managed by the contrastive encoder refine the embedding process, filtering out irrelevant details and enhancing efficiency.
Notably, HyDE surpasses the performance of existing unsupervised dense retrievers (such as Contriever). Furthermore, it exhibits performance comparable to fine-tuned retrievers across different tasks and languages. This approach compresses dense retrieval into two coherent tasks, marking a significant advancement in retrieval methods based on semantic embeddings.
◆Implementation:
from llama_index.core import (
SimpleDirectoryReader,
VectorStoreIndex,
StorageContext,
Settings,
get_response_synthesizer)
from llama_index.core.query_engine import RetrieverQueryEngine, TransformQueryEngine
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.schema import TextNode, MetadataMode
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.llms.ollama import Ollama
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.indices.query.query_transform import HyDEQueryTransform
import qdrant_client
import loggingInitialization:
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# load the local data directory and chunk the data for further processing
docs = SimpleDirectoryReader(input_dir="data", required_exts=[".pdf"]).load_data(show_progress=True)
text_parser = SentenceSplitter(chunk_size=512, chunk_overlap=100)
text_chunks = []
doc_ids = []
nodes = []Create vector storage to push embeddings.
# Create a local Qdrant vector store
logger.info("initializing the vector store related objects")
client = qdrant_client.QdrantClient(host="localhost", port=6333)
vector_store = QdrantVectorStore(client=client, collection_name="research_papers")Local embeddings and LLM model
# local vector embeddings model
logger.info("initializing the OllamaEmbedding")
embed_model = OllamaEmbedding(model_name='mxbai-embed-large', base_url='<http://localhost:11434>')
logger.info("initializing the global settings")
Settings.embed_model = embed_model
Settings.llm = Ollama(model="llama3", base_url='<http://localhost:11434>')
Settings.transformations = [text_parser]Create nodes, vector storage, HyDE converter, and finally perform queries
logger.info("enumerating docs")
for doc_idx, doc in enumerate(docs):
curr_text_chunks = text_parser.split_text(doc.text)
text_chunks.extend(curr_text_chunks)
doc_ids.extend([doc_idx] * len(curr_text_chunks))
logger.info("enumerating text_chunks")
for idx, text_chunk in enumerate(text_chunks):
node = TextNode(text=text_chunk)
src_doc = docs[doc_ids[idx]]
node.metadata = src_doc.metadata
nodes.append(node)
logger.info("enumerating nodes")
for node in nodes:
node_embedding = embed_model.get_text_embedding(
node.get_content(metadata_mode=MetadataMode.ALL)
)
node.embedding = node_embedding
logger.info("initializing the storage context")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
logger.info("indexing the nodes in VectorStoreIndex")
index = VectorStoreIndex(
nodes=nodes,
storage_context=storage_context,
transformations=Settings.transformations,
)
logger.info("initializing the VectorIndexRetriever with top_k as 5")
vector_retriever = VectorIndexRetriever(index=index, similarity_top_k=5)
response_synthesizer = get_response_synthesizer()
logger.info("creating the RetrieverQueryEngine instance")
vector_query_engine = RetrieverQueryEngine(
retriever=vector_retriever,
response_synthesizer=response_synthesizer,
)
logger.info("creating the HyDEQueryTransform instance")
hyde = HyDEQueryTransform(include_original=True)
hyde_query_engine = TransformQueryEngine(vector_query_engine, hyde)
logger.info("retrieving the response to the query")
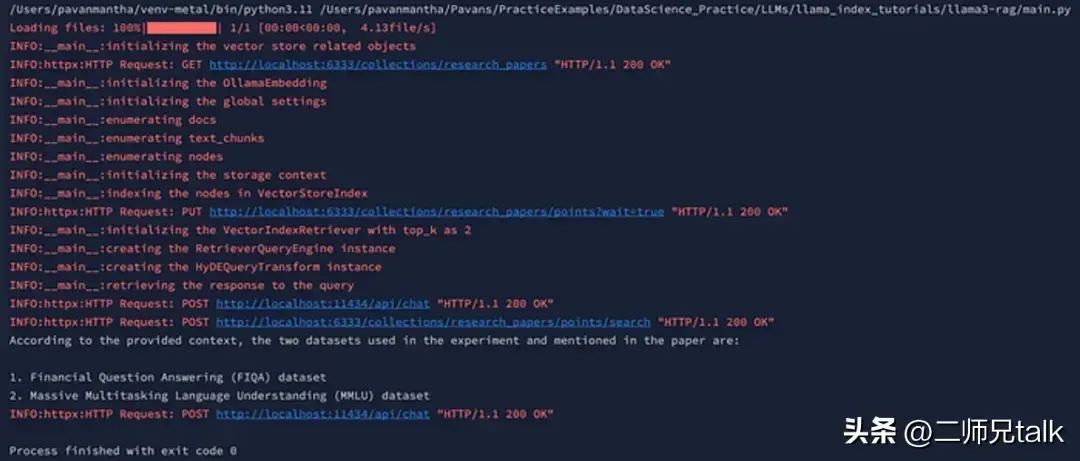
response = hyde_query_engine.query(
str_or_query_bundle="what are all the data sets used in the experiment and told in the paper")
print(response)
client.close()The above code first configures the logging for INFO level messages so that each log can be seen in the output, then continues to load PDF data from the local directory and splits it into text chunks. It establishes a Qdrant vector store to store research paper embeddings and initializes the Ollama text embedding model to generate embeddings from the text. It configures global settings, processes text chunks, and associates them with document IDs. Text nodes are created from the chunks, retaining metadata, and embeddings are generated for these nodes using the Ollama model. The script then sets up a storage context for indexing the text embeddings in the Qdrant vector store and continues to index them. The vector retriever is configured to retrieve similar embeddings, and the query engine is initialized to handle queries. The HyDE query transform is set up to enhance query processing. Finally, a query is executed to retrieve information about the datasets mentioned in the paper’s experiments and prints the response.
Output:
◆Conclusion:
In conclusion, by leveraging the power of cutting-edge technologies such as Meta’s large language model Llama-3, and complex methods like HyDE, along with the capabilities of Ollama, we are prepared to build an unparalleled RAG pipeline. By meticulously tuning critical hyperparameters such as top_k, chunk_size, and chunk_overlap, we can elevate accuracy and efficiency to new heights. The fusion of advanced tools and meticulous optimization is expected to unleash the full potential of our system, paving the way for breakthrough advancements and ensuring our solutions stand at the forefront of innovation and excellence, with maximum privacy and security.
Resources:HyDE Paper:https://arxiv.org/pdf/2212.10496.pdf
Source: https://www.toutiao.com/article/7359733486611218959/?log_from=adb4c5d3cf43a_1713747619961
“IT Experts Say” welcomes contributions from technical personnel, submission email: [email protected]
IT Experts Say | About Copyright
Articles originally published by “IT Experts Say (ID: itdakashuo)” must indicate the author, source, and WeChat public account when reprinted.For submissions, commissions, and reprints, please add WeChat: ITDKS10 (Note: Submission), and Miss Jasmine will contact you promptly!
Thank you for your enthusiastic support for IT Experts Say!
Related Recommendations
Recommended Articles
Redis Official Visualization Tool, Even the Official One is This Good!
Abandon Nginx; Try the Rust-based Pingora Framework
Another Option for Distributed Delayed Messaging: Redisson
Backend Tool for Taking Jobs: Based on Vue, Drag and Drop to Generate UI Interfaces, Simple and Beautiful, Now Open Source
Using Nginx Forward Proxy to Access the External Network from LAN Computers
During the Git Interview with Byte, the Teacher Asked: What is the Difference Between Rebase and Merge in Merging Branches?
Strongly Recommend You Not to Use the Date Class Anymore!!!
10.9K Star Super Useful Domestic Lightweight Text Editor
SpringBoot+Docker: Best Practices for Efficient Containerization