Author: Sebastian Ruder, Translated by QbitAI
2018 was a significant year for the field of NLP.
The most notable was BERT, which swept various NLP tests and was hailed as the beginning of a new era in NLP.
But in 2018, there was more than just BERT.
Recently, Irish NLP researcher Sebastian Ruder wrote an article summarizing the top ten exciting ideas in NLP based on twelve classic papers.
After the article was published, it received over 1,100 likes and more than 400 retweets on Twitter.
Many well-known institutions in the industry, such as Stanford NLP, also shared and praised it. Some researchers even commented that they hope all NeurIPS papers can be summarized and interpreted using his method.

So, what are these top ten ideas?
Unsupervised Machine Translation (Unsupervised MT)
Two papers on unsupervised machine translation were included in ICLR 2018. Although they showed some results, they were still inferior compared to supervised systems.
At EMNLP 2018, the research teams of these two papers submitted two more papers, significantly improving their research methods, leading to major advancements in unsupervised machine translation.
Representative results:
Phrase-Based & Neural Unsupervised Machine Translation (EMNLP 2018)
https://arxiv.org/abs/1804.07755
This paper effectively distilled three key methods of unsupervised machine translation: good initialization, language modeling, and reverse task modeling (through back-translation).
These three methods are also useful in other unsupervised scenarios. Reverse task modeling can enhance cyclical consistency, which has been applied in various methods, most prominently in CycleGAN.
The paper conducted extensive experiments and evaluations on two low-resource languages, “English-Urdu” and “English-Romanian”.
We hope to see more research on low-resource languages in the future.
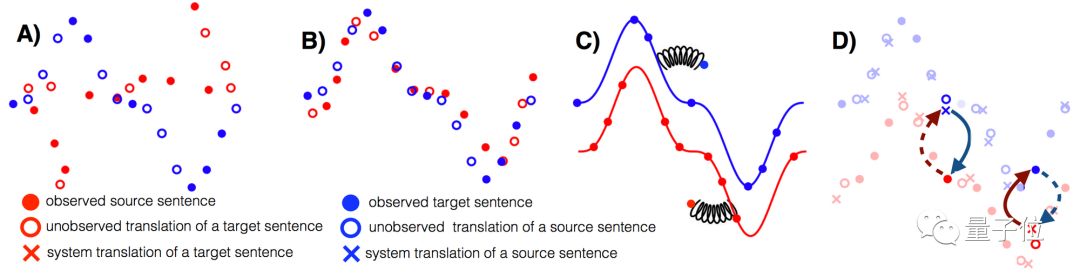
△Explanation of the three key methods of unsupervised machine translation. A: Two monolingual datasets. B: Initialization. C: Language modeling. D: Back-translation.
Pretrained Language Models
This is the most important development trend in the field of NLP this year. There are many memorable methods: ELMo, ULMFiT, OpenAI Transformer, and BERT.
Representative results:
Deep contextualized word representations (NAACL-HLT 2018)
https://arxiv.org/abs/1802.05365
This paper proposed ELMo, which received widespread acclaim.
In addition to impressive empirical results, the most notable part is the analysis section of the paper, which eliminated the influence of various factors and analyzed the information captured in the representations.
Word Sense Disambiguation (WSD) analysis (left image) performed well. Both indicated that the word sense disambiguation and part-of-speech (POS) tagging provided by LM are close to state-of-the-art levels.
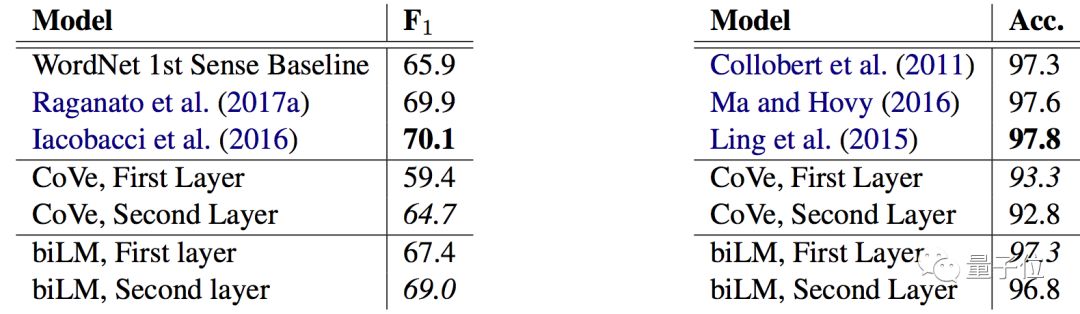
△Results of word sense disambiguation (left) and part-of-speech tagging (right) for the first and second layers of bidirectional language models. Compared to the baseline.
Common Sense Inference Datasets
Integrating common sense into models is one of the most important directions for NLP’s progress. However, creating a good dataset is not easy; even popular datasets have significant biases.
This year, some excellent datasets have attempted to teach models some common sense, such as Event2Mind and SWAG, both from the University of Washington. Surprisingly, SWAG was quickly surpassed by BERT.
Representative results:
Visual Commonsense Reasoning (arXiv 2018)
http://visualcommonsense.com/
This is the first visual QA dataset, where each answer includes an explanation of why the answer is correct. Moreover, each question requires complex reasoning.
The creators made efforts to address potential biases, ensuring that the accuracy of each answer is 25% (each answer appears four times in the dataset, with wrong answers appearing three times and the correct answer appearing once).
This requires using models to calculate relevance and similarity to solve constrained optimization problems. We hope that preventing potential biases when creating datasets will become common sense.
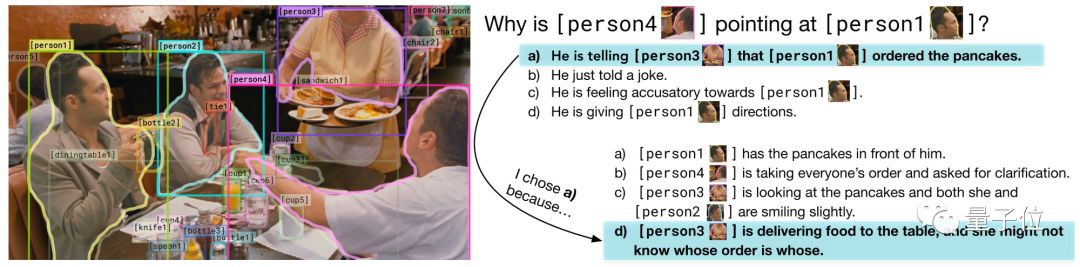
△VCR: Given an image, a list of regions, and a question, the model must answer the question and provide a reason for why its answer is correct.
Meta-Learning
Meta-learning has been widely applied in few-shot learning, reinforcement learning, and robotic learning, with the most prominent example being model-agnostic meta-learning (MAML).
However, there have been few successful applications of meta-learning in the field of NLP. It is very useful in addressing issues with limited sample sizes.
Representative paper:
Meta-Learning for Low-Resource Neural Machine Translation (EMNLP 2018)
http://aclweb.org/anthology/D18-1398
In this paper, the authors used MAML, treating each “language pair” as a separate meta-task.
In the field of NLP, adapting to low-resource languages might be the best application for meta-learning.
Especially when combining multilingual transfer learning (such as multilingual BERT), unsupervised learning, and meta-learning, this is a very promising direction for progress.
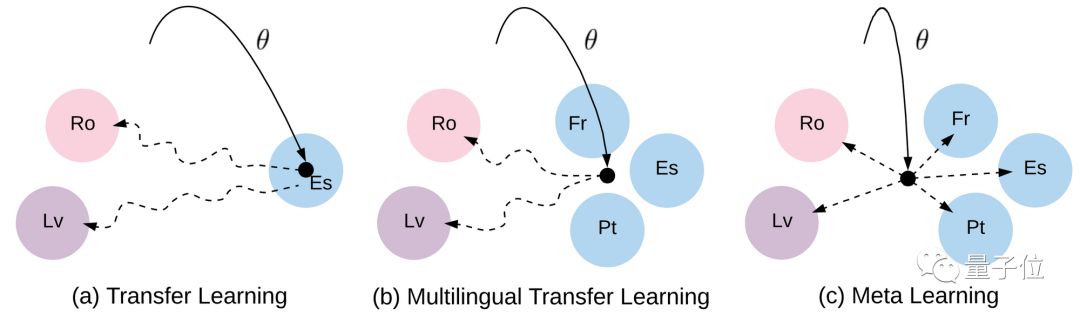
△Differences between transfer learning, multilingual transfer learning, and meta-learning. Solid line: learning initialization. Dashed line: fine-tuning path.
Robust Unsupervised Methods
This year, we and others have observed that unsupervised cross-lingual word embedding methods collapse when languages are dissimilar.
This is a common phenomenon in transfer learning, where differences between source and target settings (e.g., domain adaptation, continual learning, and multi-task learning) can lead to degraded or collapsed model performance.
Therefore, it is important to make models more robust in the face of such variations.
Representative results:
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings (ACL 2018)
http://www.aclweb.org/anthology/P18-1073
This paper does not apply meta-learning to initialization but uses their understanding of the problem to design better initialization.
Notably, they paired words with similar distributions across two languages. This is a good example of how domain expertise and analytical insights can make models more robust.
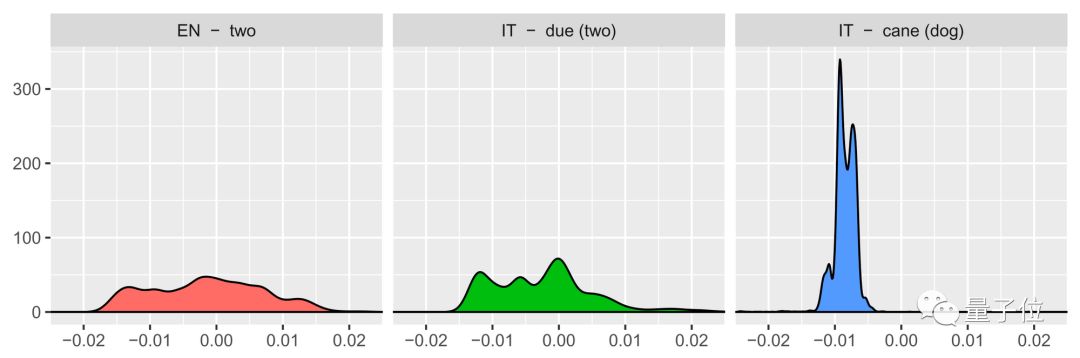
△Distribution of similarity for three words. The distribution of equivalent translations (“two” and “due”) is more similar than the distribution of unrelated words (“two” and “cane”—meaning “dog”).
Understanding Representations
To better understand representations, researchers have made significant efforts. In particular, “diagnostic classifiers” (aimed at measuring whether learned representations can predict certain attributes) have become very common.
Representative results:
Dissecting Contextual Word Embeddings: Architecture and Representation (EMNLP 2018)
http://aclweb.org/anthology/D18-1179
This paper made significant contributions to better understanding the representations of pretrained language models.
The authors conducted extensive studies on word and span representations in carefully designed unsupervised and supervised tasks.
The results found that pretrained representation learning tasks relate to lower-level morphological and syntactic tasks over longer semantic ranges in both lower and higher layers.
This actually indicates that pretrained language models capture characteristics similar to those of computer vision models pretrained on ImageNet.

△Performance of BiLSTM and Transformer pretrained representations in part-of-speech tagging, span analysis, and unsupervised coreference resolution (from left to right) for each layer.
Clever Auxiliary Tasks
In many scenarios, we have seen an increasing number of scholars using multi-task learning and carefully selected auxiliary tasks.
For a good auxiliary task, the data must be easily accessible.
A prominent example is BERT, which achieved significant results using next sentence prediction (used in Skip-thoughts and recently in Quick-thoughts).
Representative results:
Syntactic Scaffolds for Semantic Structures (EMNLP 2018)
http://aclweb.org/anthology/D18-1412
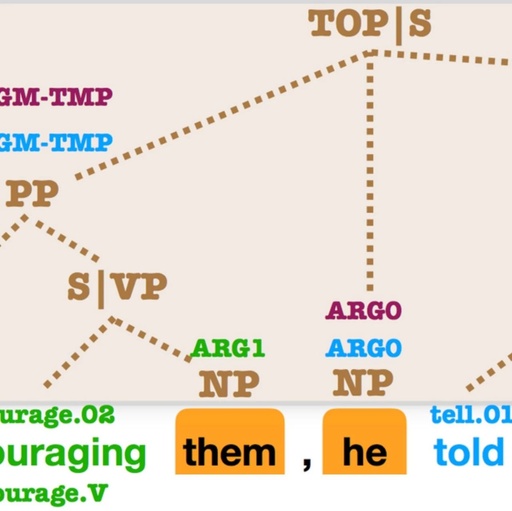
This paper proposed an auxiliary task to preprocess span representations by predicting the syntactic component types corresponding to each span.
Although conceptually simple, auxiliary tasks are crucial in driving significant improvements in span prediction tasks, such as semantic role labeling and coreference resolution.
This paper demonstrates that learning specialized representations at the level required by the target task is very useful.
pair2vec: Compositional Word-Pair Embeddings for Cross-Sentence Inference (arXiv 2018)
https://arxiv.org/abs/1810.08854
Based on similar contexts, this paper pretrains “word pair” representations by maximizing the pointwise mutual information between the “word pair” and its context. This encourages the model to learn more meaningful “word pair” representations rather than more general objectives, such as language modeling.
Pretrained representations are effective for tasks requiring cross-sentence inference, such as SQuAD and MultiNLI.
In the future, we may see more pretraining tasks that capture attributes particularly suited for certain downstream tasks and complement more general tasks (such as language modeling).
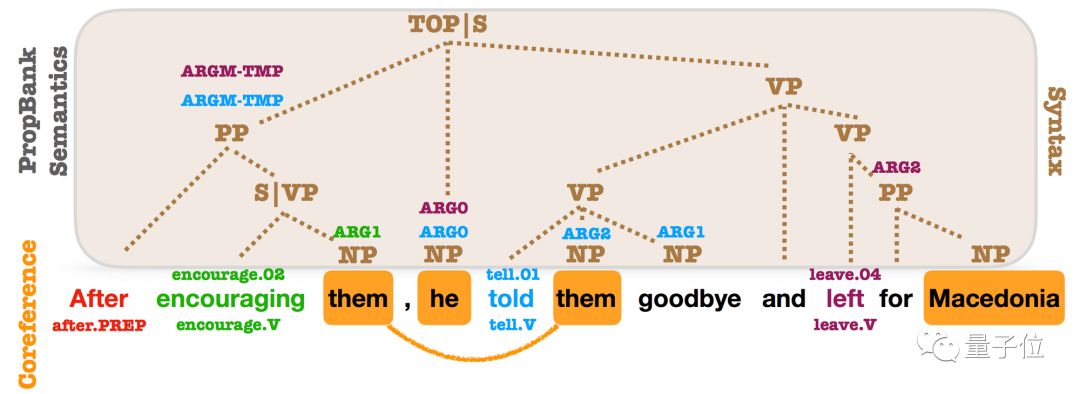
△OntoNotes’ syntactic, PropBank, and coreference annotations. PropBank SRL parameters and coreference mention annotations are overlaid on syntactic components. Almost every parameter relates to a syntactic component.
Combining Semi-Supervised Learning with Transfer Learning
In fact, pretrained representations are complementary to many semi-supervised learning representation methods.
Some scholars have explored self-labeling methods, a special type of semi-supervised learning.
Representative results:
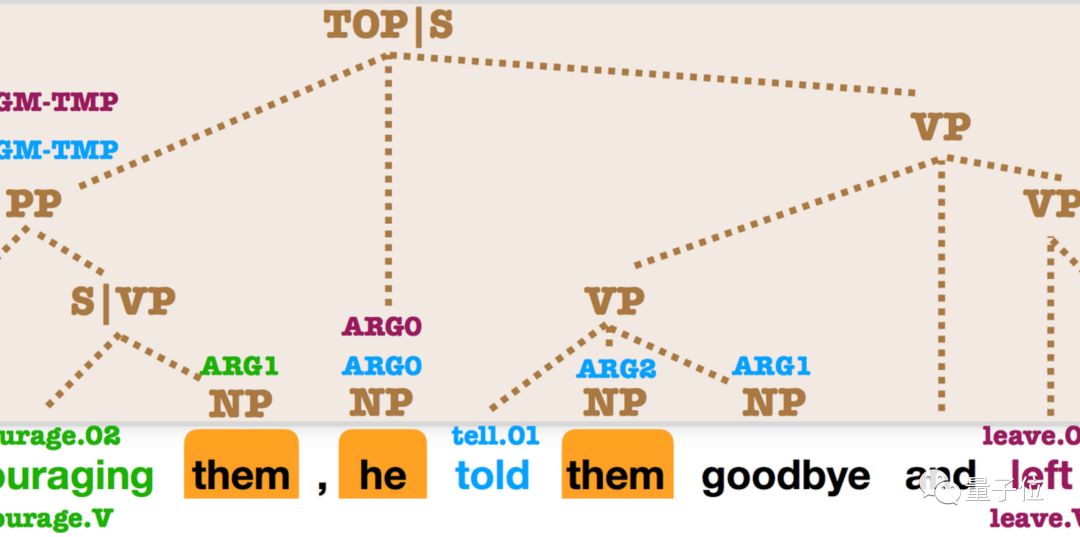
Semi-Supervised Sequence Modeling with Cross-View Training (EMNLP 2018)
http://aclweb.org/anthology/D18-1217
This paper demonstrates a conceptually simple idea: ensuring that predictions from different input views are consistent with predictions from the main model can yield benefits across different task sets.
This idea is similar to word dropout but can utilize unlabeled data to make models more robust.
Compared to other self-ensemble models, it is specifically designed for certain NLP tasks.
As research on semi-supervised learning grows, we can expect to see more studies explicitly attempt to model future target predictions.
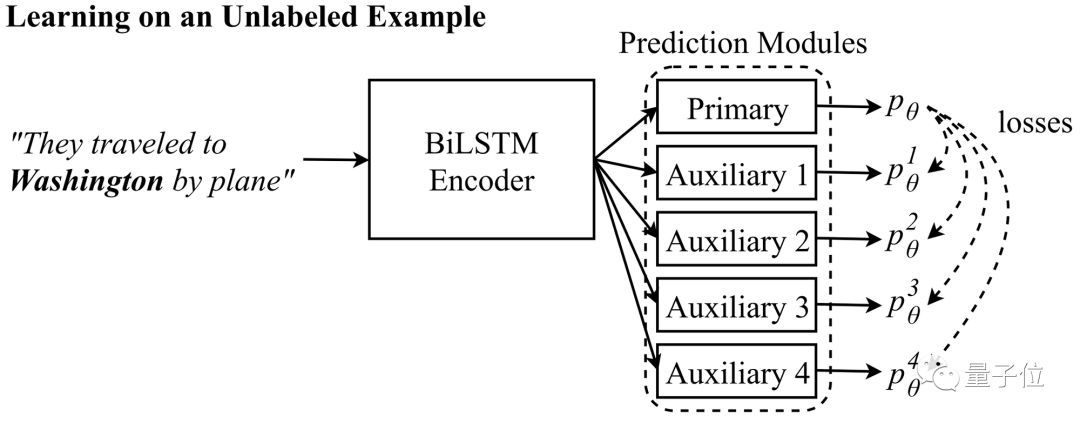
△Input seen by the auxiliary prediction module: Auxiliary 1: They traveled to __. Auxiliary 2: They traveled to Washington__. Auxiliary 3: _ Washington by plane. Auxiliary 4: __ by plane.
QA and Reasoning with Large Documents
With the emergence of a series of new question-answering datasets, question-answering systems have made significant advancements.
Beyond conversational question answering and multi-step reasoning, the most challenging aspect of question answering is synthesizing narratives and processing large amounts of information.
Representative results:
The NarrativeQA Reading Comprehension Challenge (TACL 2018)
http://aclweb.org/anthology/Q18-1023
This paper proposed a challenging new QA dataset based on answering questions from entire movie scripts and books.
Although current methods still cannot complete this task, models can choose to use summaries (instead of the entire book) as context to select answers (rather than generate answers).
These variants make it more feasible to complete the task and allow models to gradually scale to full context.
We need more datasets like this that pose challenging questions but can be solved incrementally.
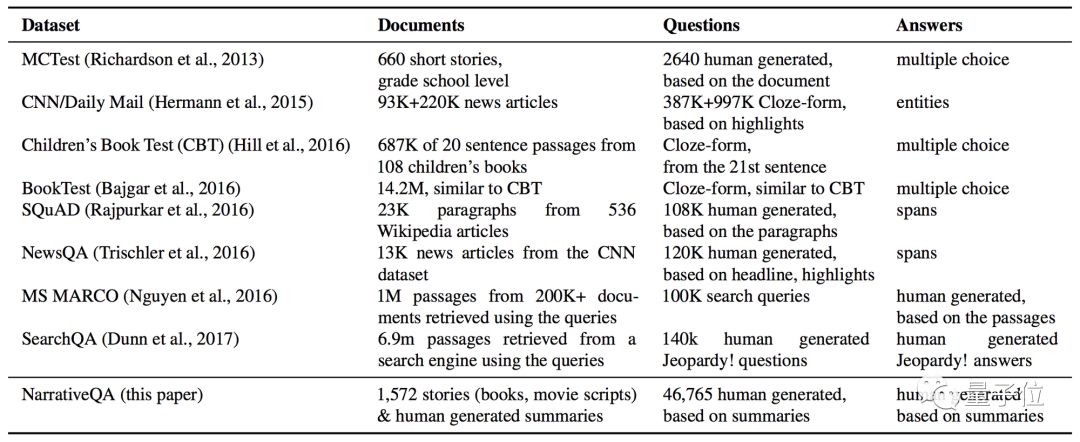
△Comparison of QA datasets.
Inductive Bias
Inductive biases, such as convolutions in CNNs, regularization, dropout, and other mechanisms, are core components of neural network models that act as regulators, making models more sample-efficient.
However, proposing a more broadly applicable inductive bias method and integrating it into models is a challenge.
Representative results:
Sequence Classification with Human Attention (CoNLL 2018)
http://aclweb.org/anthology/K18-1030
This paper proposes using human attention from visual tracking corpora to regulate attention in visual neural networks.
Considering that many current models (such as Transformers) also use attention, finding more effective training methods for it is an important direction.
Additionally, the paper demonstrates that human language learning can help improve computational models.
Linguistically-Informed Self-Attention for Semantic Role Labeling (EMNLP 2018)
http://aclweb.org/anthology/D18-1548
This paper has many highlights: a transformer jointly training syntactic and semantic tasks; the ability to inject high-quality parses during testing; and out-of-scope evaluations.
The paper also trains an attention head to focus on the syntactic parent of each token, making the multi-head attention of the Transformer more sensitive to syntax.
In the future, we hope to see more Transformer attention heads used for auxiliary predictions focused on specific aspects of input.

△Comparison of PropBank semantic role labeling over ten years. Self-attention with linguistic information (LISA) compared to other out-of-scope data methods.
Portal
http://ruder.io/10-exciting-ideas-of-2018-in-nlp/
Author is a contracted author for NetEase News · NetEase account “Each has its own attitude”
— End —
Join the community
The QbitAI AI community is now recruiting. Welcome students interested in AI to reply with the keyword “community” in the QbitAI WeChat public account to get the entry method;
In addition, QbitAI’s specialized sub-groups (autonomous driving, CV, NLP, machine learning, etc.) are recruiting engineers and researchers working in related fields.
To join the specialized group, please reply with the keyword “specialized group” in the QbitAI WeChat public account to get the entry method. (The specialized group has a stricter review process, please understand.)
Sincere recruitment
QbitAI is recruiting editors/reporters, with the work location in Zhongguancun, Beijing. We look forward to talented and passionate students joining us! For details, please reply with the word “recruitment” in the QbitAI WeChat public account.

QbitAIQbitAI · Contracted Author for Toutiao
Tracking new dynamics in AI technology and products

△ Is it good looking?↘↘↘