Yunzhong from Aofeisi Quantum Bit Report | WeChat Official Account QbitAI
How do BERT and ERNIE, the two most关注的 models in the NLP field, perform?
Recently, someone conducted a comparison test, and the results were surprising and delightful in a Chinese language environment.
What are the specific details? Let’s take a look at this technical evaluation.
1. Introduction
With the release of models like ELMo and BERT in 2018, the NLP field finally entered the era of “great power brings miracles.” Deep models trained on large-scale corpora through unsupervised pre-training can achieve good results with just a bit of fine-tuning on downstream task data. Tasks that once required repeated parameter tuning and careful design can now be solved simply by using larger pre-training data and deeper models.
In the first half of 2019, Baidu’s open-source deep learning platform PaddlePaddle released the knowledge-enhanced pre-training model ERNIE, which models words, entities, and entity relationships through massive data. Compared to BERT’s learning of raw language signals, ERNIE directly models prior semantic knowledge units, enhancing the model’s semantic representation capabilities.
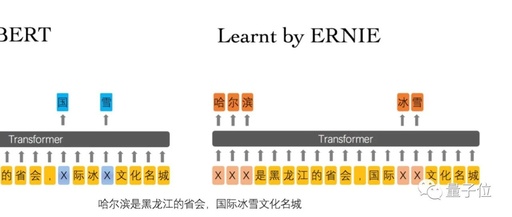
In simple terms, Baidu’s ERNIE uses a Masked Language Model with a prior knowledge Mask mechanism. As shown in the figure below, if BERT uses random masking, the character “黑” can be easily predicted from the suffix “龙江.” By introducing word and entity masks, “黑龙江” is masked as a whole, forcing the model to learn correlations from longer dependencies (“ice and snow cultural city”).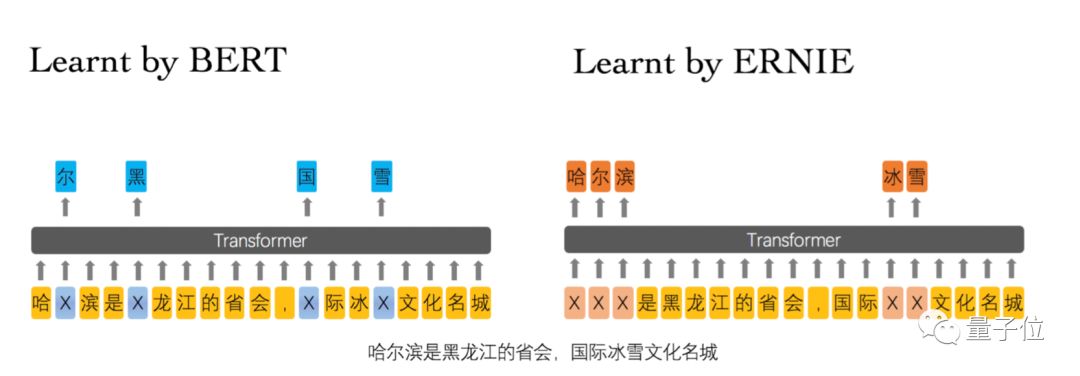 Additionally, Baidu ERNIE introduces the DLM (Dialogue Language Model) task to learn the semantic similarity between queries corresponding to the same response. Experiments have shown that the introduction of DLM significantly helps the LCQMC (text similarity computation) series of tasks. Ultimately, ERNIE utilizes multi-source training data and completes pre-training using the high-performance distributed deep learning platform PaddlePaddle.
Additionally, Baidu ERNIE introduces the DLM (Dialogue Language Model) task to learn the semantic similarity between queries corresponding to the same response. Experiments have shown that the introduction of DLM significantly helps the LCQMC (text similarity computation) series of tasks. Ultimately, ERNIE utilizes multi-source training data and completes pre-training using the high-performance distributed deep learning platform PaddlePaddle.
2. Personal Testing
To determine whether the training mechanisms introduced by Baidu ERNIE have had an effect, I personally ran both BERT and ERNIE models and obtained prediction results in the following scenarios.
2.1 Cloze Test
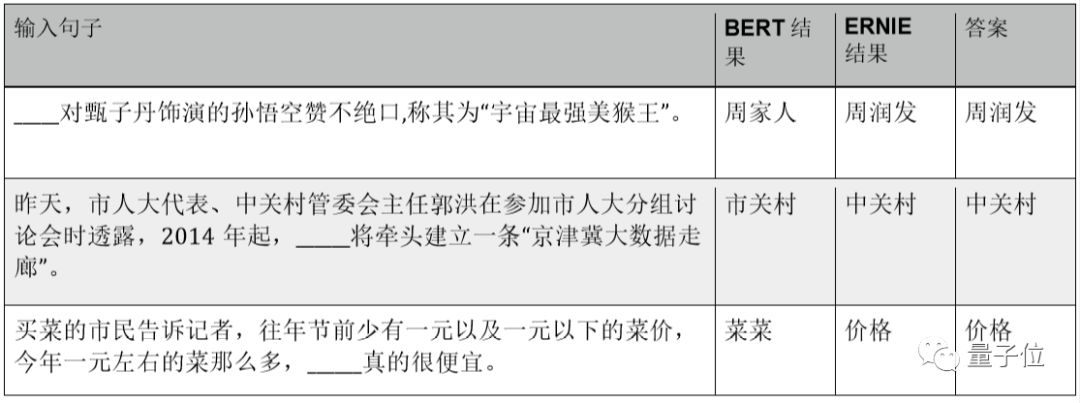
The cloze test task is very similar to the knowledge prior Mask LM task introduced during ERNIE’s pre-training. From the comparison below, we can see that ERNIE models entity words more clearly and predicts entity nouns more accurately than BERT. For example, BERT’s answer “周家人” merges similar words “周润发” and “家人,” resulting in a lack of clarity; “市关村” is not a known entity; the word boundary of “菜菜” is incomplete. ERNIE’s answer can accurately pinpoint the missing entity.
2.2 NER (Named Entity Recognition)
In the token-level NER task, the knowledge prior Mask LM also yielded significant results. Comparing the F1 score performance on the MSRA-NER dataset, ERNIE achieved 93.8% while BERT achieved 92.6%. On PaddleNLP’s LAC dataset, ERNIE also performed better, with a test set F1 of 92.0%, improving 1.7% over BERT’s result of 90.3%. Analyzing the prediction results of both on the MSRA-NER test data reveals:
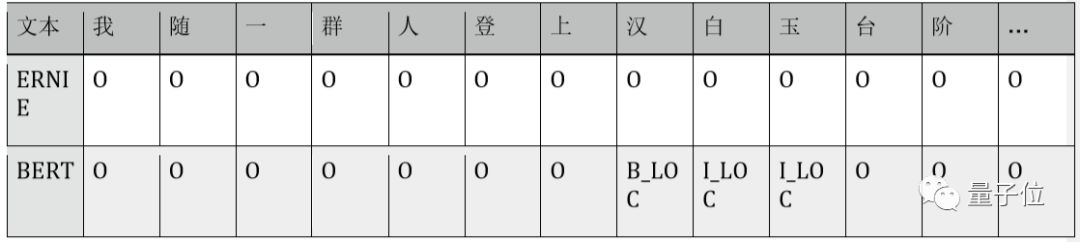
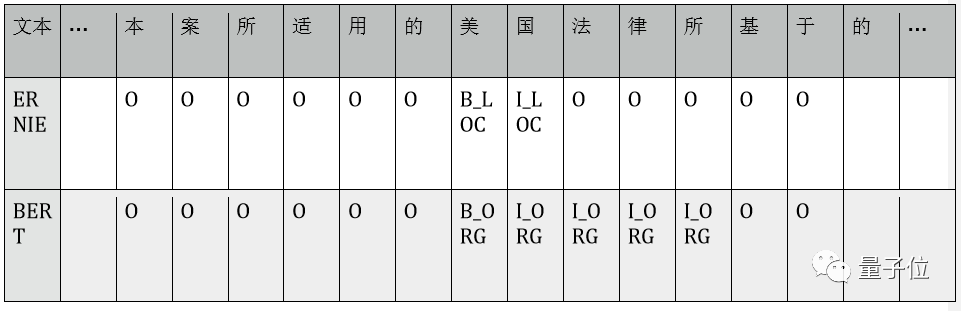
1.) ERNIE understands entities more accurately: “汉白玉” is not misclassified as an entity type;
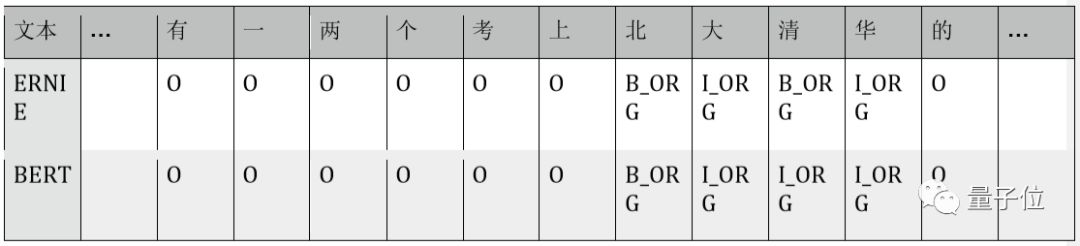
2.) ERNIE’s modeling of entity boundaries is clearer: “美国法律所” has an incomplete word boundary, while “北大” and “清华” are two separate institutions.
Case comparison: Extracted from three sentences in the MSRA-NER data test set. B_LOC/I_LOC indicates location entity labels, B_ORG/L_ORG indicates organization entity labels, and O indicates no entity category label. The table below shows the annotation results for each character from the ERNIE and BERT models.
2.3 Similarity
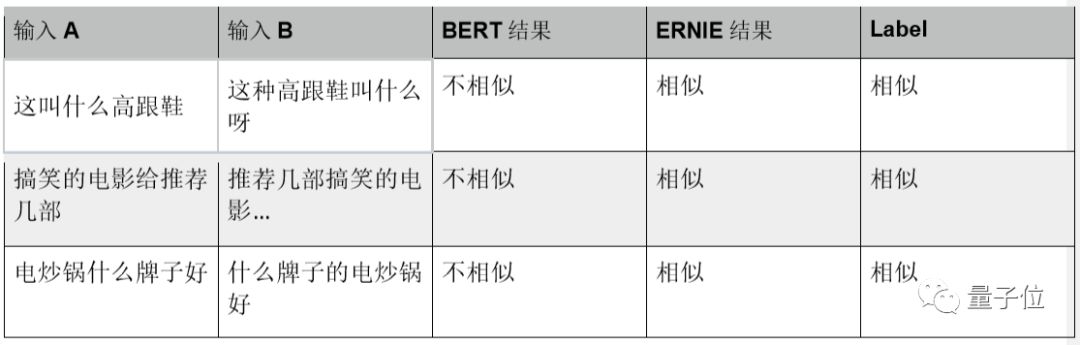
The DLM introduced during ERNIE’s training effectively enhances the model’s ability to model text similarity. Therefore, we compared the performance of both on the text similarity task using the LCQMC dataset. The prediction results in the table below indicate that ERNIE has learned the complex word order changes in Chinese. Ultimately, ERNIE and BERT achieved prediction accuracies of 87.4% and 87.0%, respectively.
2.4 Classification
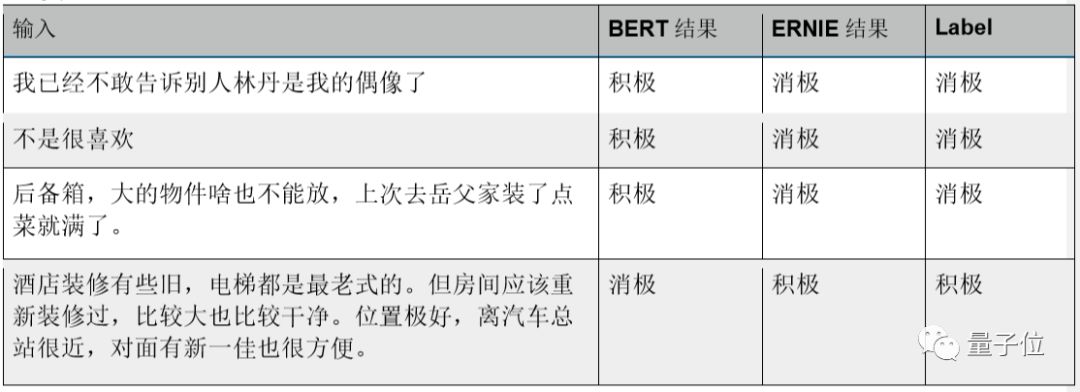
Finally, comparing the widely used sentiment classification task. The pre-trained ERNIE can capture more subtle semantic differences, which often contain more euphemistic expressions. Below are the scoring performances of ERNIE and BERT on the PaddleNLP sentiment classification test set: In the sentence “不是很…” which contains a turning point relationship, ERNIE can understand this relationship well and predicts the result as “negative.” After fine-tuning on the ChnSentiCorp sentiment classification test set, ERNIE’s prediction accuracy reached 95.4%, higher than BERT’s accuracy of 94.3%.
From the above data, we can see that ERNIE performs well in most tasks. Especially in tasks like sequence labeling and cloze tests, ERNIE’s performance is particularly outstanding, matching Google’s BERT. Interested developers can give it a try:
https://github.com/PaddlePaddle/LARK/tree/develop/ERNIE
— End —
Mini Program | Comprehensive AI Learning Tutorials

AI Community | Communicate with Excellent People


Quantum Bit QbitAI · Author of Headline Number Contract
Tracking AI technology and product dynamics
If you like it, please click “Looking”!