

This article is approximately 3200 words long and is recommended to be read in 7 minutes.
This article will introduce gradient checkpointing, a technique that allows you to train larger models on the GPU at the cost of increased training time. We will implement it in PyTorch and train a classifier model.
As machine learning practitioners, we often encounter situations where we want to train a relatively large model, but the GPU cannot handle it due to insufficient memory. This problem often arises when we are not allowed to work in cloud computing environments for safety reasons. In such environments, we cannot scale up or switch to powerful hardware quickly enough to train the model. Furthermore, due to the nature of the gradient descent algorithm, larger batches usually yield better results in most models, but in most cases, we must use batch sizes that fit the GPU memory due to memory limitations.

Gradient Checkpointing
In the backpropagation algorithm, gradient computation starts from the loss function, calculating and updating model weights afterward. All derivatives or gradients computed at each step are stored until the final update gradient is calculated. This consumes a large amount of GPU memory. Gradient checkpointing saves memory by recomputing these values when needed and discarding previous values that are no longer needed for further computation.
Let’s explain this with the virtual diagram below.
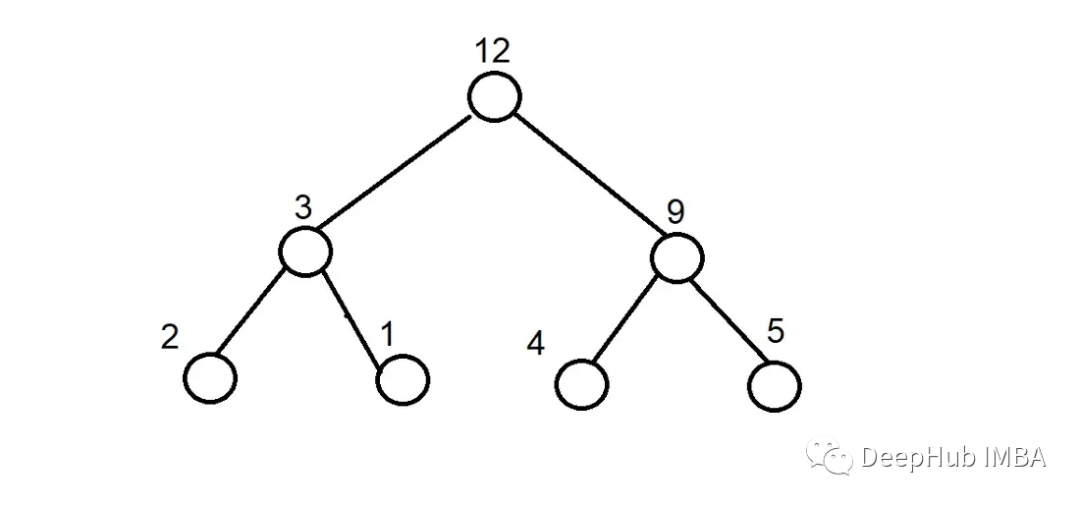
The above is a computation graph, where the numbers at each leaf node add up to the final output. Suppose this graph represents the computations that occur during backpropagation; then the values at each node would be stored, leading to a total memory requirement of 7 for the summation because there are 7 nodes. However, we can use less memory. Suppose we add 1 and 2 and store their value as 3 in the next node, then delete those two values. We can do the same for 4 and 5, storing 9 as the result of the addition. 3 and 9 can also be processed similarly, storing the result and then deleting them. By performing these operations, the memory required during computation is reduced from 7 to 3.
Training a Classification Model with PyTorch Without Gradient Checkpointing
We will build a classification model using PyTorch and train it without using gradient checkpointing. We will record various metrics of the model, such as the time taken for training, memory consumption, accuracy, etc.
Since we are primarily concerned with GPU memory consumption, we need to monitor the memory usage for each batch during training. Here we use the nvidia-ml-py3 library, which uses the nvidia-smi command to get memory information.
pip install nvidia-ml-py3For simplicity, we will use a subset of the simple dog and cat classification dataset.
git clone https://github.com/laxmimerit/dog-cat-full-dataset.gitAfter executing the above command, the complete dataset will be obtained in the dog-cat-full-dataset folder.
Import the necessary packages and initialize nvidia-smi.
import torch import torch.nn as nn import torch.optim as optim import numpy as np from torchvision import datasets, models, transforms import matplotlib.pyplot as plt import time import os import cv2 import nvidia_smi import copy from PIL import Image from torch.utils.data import Dataset,DataLoader import torch.utils.checkpoint as checkpoint from tqdm import tqdm import shutil from torch.utils.checkpoint import checkpoint_sequential device="cuda" if torch.cuda.is_available() else "cpu" %matplotlib inline import random nvidia_smi.nvmlInit()Import all the packages needed for training and testing the model. We also initialize nvidia-smi.
Define the Dataset and DataLoader
#Define the dataset and the dataloader. train_dataset=datasets.ImageFolder(root="/content/dog-cat-full-dataset/data/train", transform=transforms.Compose([ transforms.RandomRotation(30), transforms.RandomHorizontalFlip(), transforms.RandomResizedCrop(224, scale=(0.96, 1.0), ratio=(0.95, 1.05)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ])) val_dataset=datasets.ImageFolder(root="/content/dog-cat-full-dataset/data/test", transform=transforms.Compose([ transforms.Resize([224, 224]), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]), ])) train_dataloader=DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=2) val_dataloader=DataLoader(val_dataset, batch_size=64, shuffle=True, num_workers=2)Here, we define the dataset using the ImageFolder class from torchvision. We also define certain transformations on the dataset, such as RandomRotation, RandomHorizontalFlip, etc. Finally, we normalize the images and set batch_size=64.
Define Training and Testing Functions
def train_model(model,loss_func,optimizer,train_dataloader,val_dataloader,epochs=10): model.train() #Training loop. for epoch in range(epochs): model.train() for images, target in tqdm(train_dataloader): images, target = images.to(device), target.to(device) images.requires_grad=True optimizer.zero_grad() output = model(images) loss = loss_func(output, target) loss.backward() optimizer.step() if os.path.exists('grad_checkpoints/') is False: os.mkdir('grad_checkpoints') torch.save(model.state_dict(), 'grad_checkpoints/epoch_'+str(epoch)+'.pt') #Test the model on validation data. train_acc,train_loss=test_model(model,train_dataloader) val_acc,val_loss=test_model(model,val_dataloader) #Check memory usage. handle = nvidia_smi.nvmlDeviceGetHandleByIndex(0) info = nvidia_smi.nvmlDeviceGetMemoryInfo(handle) memory_used=info.used memory_used=(memory_used/1024)/1024 print(f"Epoch={epoch} Train Accuracy={train_acc} Train loss={train_loss} Validation accuracy={val_acc} Validation loss={val_loss} Memory used={memory_used} MB") def test_model(model,val_dataloader): model.eval() test_loss = 0 correct = 0 with torch.no_grad(): for images, target in val_dataloader: images, target = images.to(device), target.to(device) output = model(images) test_loss += loss_func(output, target).data.item() _, predicted = torch.max(output, 1) correct += (predicted == target).sum().item() test_loss /= len(val_dataloader.dataset) return int(correct / len(val_dataloader.dataset) * 100),test_lossThe above creates a simple training and testing loop to train the model. Finally, it also calculates memory usage by calling nvidia-smi.
Training
torch.manual_seed(0) #Learning rate. lr = 0.003 #Defining the VGG16 sequential model. vgg16=models.vgg16() vgg_layers_list=list(vgg16.children())[:-1] vgg_layers_list.append(nn.Flatten()) vgg_layers_list.append(nn.Linear(25088,4096)) vgg_layers_list.append(nn.ReLU()) vgg_layers_list.append(nn.Dropout(0.5,inplace=False)) vgg_layers_list.append(nn.Linear(4096,4096)) vgg_layers_list.append(nn.ReLU()) vgg_layers_list.append(nn.Dropout(0.5,inplace=False)) vgg_layers_list.append(nn.Linear(4096,2)) model = nn.Sequential(*vgg_layers_list) model=model.to(device) #Num of epochs to train num_epochs=10 #Loss loss_func = nn.CrossEntropyLoss() # Optimizer # optimizer = optim.Adam(model.parameters(), lr=lr, weight_decay=1e-5) optimizer = optim.SGD(params=model.parameters(), lr=0.001, momentum=0.9) #Training the model. model = train_model(model, loss_func, optimizer, train_dataloader,val_dataloader,num_epochs)We use the VGG16 model for classification. Below are the training logs of the model.

From the logs above, we can see that training a model with a batch size of 64 without checkpoints takes about 5 minutes and consumes 14222.125 MB of memory.
Training a Classification Model with Gradient Checkpointing in PyTorch
To train the model with gradient checkpointing, we only need to edit the train_model function.
def train_with_grad_checkpointing(model,loss_func,optimizer,train_dataloader,val_dataloader,epochs=10): #Training loop. for epoch in range(epochs): model.train() for images, target in tqdm(train_dataloader): images, target = images.to(device), target.to(device) images.requires_grad=True optimizer.zero_grad() #Applying gradient checkpointing segments = 2 # get the modules in the model. These modules should be in the order # the model should be executed modules = [module for k, module in model._modules.items()] # now call the checkpoint API and get the output output = checkpoint_sequential(modules, segments, images) loss = loss_func(output, target) loss.backward() optimizer.step() if os.path.exists('checkpoints/') is False: os.mkdir('checkpoints') torch.save(model.state_dict(), 'checkpoints/epoch_'+str(epoch)+'.pt') #Test the model on validation data. train_acc,train_loss=test_model(model,train_dataloader) val_acc,val_loss=test_model(model,val_dataloader) #Check memory. handle = nvidia_smi.nvmlDeviceGetHandleByIndex(0) info = nvidia_smi.nvmlDeviceGetMemoryInfo(handle) memory_used=info.used memory_used=(memory_used/1024)/1024 print(f"Epoch={epoch} Train Accuracy={train_acc} Train loss={train_loss} Validation accuracy={val_acc} Validation loss={val_loss} Memory used={memory_used} MB") def test_model(model,val_dataloader): model.eval() test_loss = 0 correct = 0 with torch.no_grad(): for images, target in val_dataloader: images, target = images.to(device), target.to(device) output = model(images) test_loss += loss_func(output, target).data.item() _, predicted = torch.max(output, 1) correct += (predicted == target).sum().item() test_loss /= len(val_dataloader.dataset) return int(correct / len(val_dataloader.dataset) * 100),test_lossdef test_model(model,val_dataloader)We renamed the function to train_with_grad_checkpointing. Instead of running the training through the model (graph), we use the checkpoint_sequential function for training, which takes three inputs: modules, segments, and input. Modules are a list of the neural network layers arranged in the order they should be executed.
Segments are the number of segments created in the sequence, using gradient checkpointing to train in segments will use the output for recalculating the gradients during backpropagation. In this article, we set segments=2. The input is the input to the model, which in our case is the images. Here, checkpoint_sequential is only used for sequential models, and will generate errors for some other models.
When training with gradient checkpointing, if you execute all the code in a notebook, it is recommended to restart because nvidia-smi may still reflect memory consumption from previous code.
torch.manual_seed(0) lr = 0.003 # model = models.resnet50() # model=model.to(device) vgg16=models.vgg16() vgg_layers_list=list(vgg16.children())[:-1] vgg_layers_list.append(nn.Flatten()) vgg_layers_list.append(nn.Linear(25088,4096)) vgg_layers_list.append(nn.ReLU()) vgg_layers_list.append(nn.Dropout(0.5,inplace=False)) vgg_layers_list.append(nn.Linear(4096,4096)) vgg_layers_list.append(nn.ReLU()) vgg_layers_list.append(nn.Dropout(0.5,inplace=False)) vgg_layers_list.append(nn.Linear(4096,2)) model = nn.Sequential(*vgg_layers_list) model=model.to(device) num_epochs=10 #Loss loss_func = nn.CrossEntropyLoss() # Optimizer # optimizer = optim.Adam(model.parameters(), lr=lr, weight_decay=1e-5) optimizer = optim.SGD(params=model.parameters(), lr=0.001, momentum=0.9) #Fitting the model. model = train_with_grad_checkpointing(model, loss_func, optimizer, train_dataloader,val_dataloader,num_epochs)The output is as follows:

From the output above, it can be seen that training each epoch takes about 6 minutes and 45 seconds, but only requires 10550.125 MB of memory, meaning we exchanged time for space, and the accuracy in both cases is 79, as there was no loss in model accuracy with gradient checkpointing.
Conclusion
Gradient checkpointing is a very good technique that can help complete the training of models in cases of low GPU memory. Based on our tests, gradient checkpointing generally extends training time by about 20%, but a longer time is still better than not being able to use it, right?
Editor: Wang Jing
Proofreader: Lin Yilin