
Recently, ChatGPT has gone completely viral.
People all over the world are flirting with ChatGPT.
However, many friends are still confused.
What exactly is this thing? What can it do?
Here is an excellent article
that provides a detailed introduction to the ins and outs of ChatGPT.After reading it, you will also become a semi-expert!
The following is the main text, by Dr. Chen Wei.
On December 1st last year, OpenAI launched the AI chat prototype ChatGPT, once again attracting attention and sparking discussions in the AI community similar to the debates about AIGC making artists unemployed.
ChatGPT is a language model focused on dialogue generation. It can generate intelligent responses based on user text input. These responses can be short phrases or lengthy discussions. The term GPT stands for Generative Pre-trained Transformer. By learning from a large corpus of text and dialogue sets (such as Wiki), ChatGPT can converse in real-time like a human and respond fluently to various questions. (Of course, it is still a bit slower than humans.) Whether in English or other languages (such as Chinese, Korean, etc.), it can “almost” do anything from answering historical questions to writing stories, and even drafting business plans and industry analyses. Some programmers have even shared dialogues where ChatGPT modifies code.
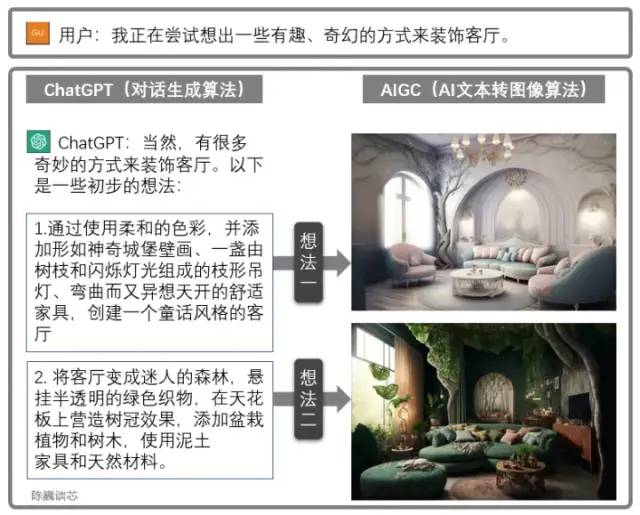
The combined use of ChatGPT and AIGC
ChatGPT can also be used in conjunction with other AIGC models to achieve more impressive and useful functionalities.
For instance, the above demonstrates generating a living room design through dialogue. This greatly enhances the AI application’s ability to interact with customers, giving us a glimpse of the dawn of large-scale AI deployment.
1. Inheritance and Characteristics of ChatGPT

▌1.1 The OpenAI Family
First, let’s understand who OpenAI is. OpenAI is headquartered in San Francisco and was co-founded in 2015 by Elon Musk from Tesla, Sam Altman, and other investors, aiming to develop AI technologies that benefit all humanity. Musk left in 2018 due to differences in the company’s direction. Previously, OpenAI was known for launching the GPT series of natural language processing models. Since 2018, OpenAI has begun releasing generative pre-trained language models GPT (Generative Pre-trained Transformer), which can be used to generate articles, code, machine translation, Q&A, and various other content. Each generation of the GPT model has seen explosive growth in the number of parameters, proving that “bigger is better.” The GPT-2 released in February 2019 had 1.5 billion parameters, while GPT-3 released in May 2020 reached 175 billion parameters.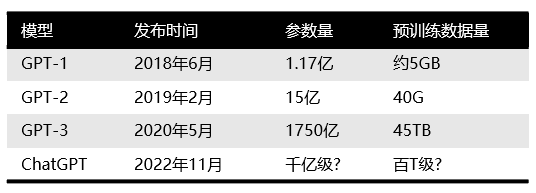
Comparison of Main Models in the GPT Family
▌1.2 Main Features of ChatGPT
ChatGPT is a dialogue AI model developed based on the GPT-3.5 (Generative Pre-trained Transformer 3.5) architecture, and it is a sibling model to InstructGPT. ChatGPT is likely a rehearsal for OpenAI before the official release of GPT-4, or it is used to collect a large amount of dialogue data.
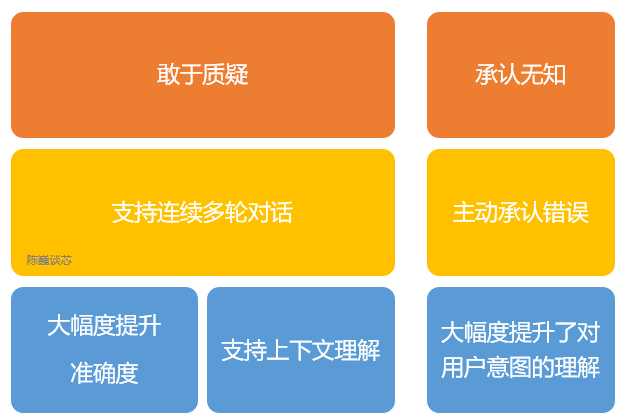
Main Features of ChatGPT
OpenAI trained ChatGPT using RLHF (Reinforcement Learning from Human Feedback) technology and added more human supervision for fine-tuning. Additionally, ChatGPT has the following features: 1) It can actively acknowledge its mistakes. If a user points out its errors, the model will listen to the feedback and optimize its answers. 2) ChatGPT can question incorrect queries. For example, when asked about “Columbus’s arrival in America in 2015,” the bot will clarify that Columbus did not belong to that era and adjust its output. 3) ChatGPT can admit its ignorance, acknowledging its lack of knowledge on specialized topics. 4) It supports continuous multi-turn dialogues. Unlike various smart speakers and “artificially intelligent idiots” we use in daily life, ChatGPT remembers previous users’ dialogue messages during conversations, allowing it to understand context and respond to hypothetical questions. ChatGPT can achieve continuous dialogue, greatly enhancing the user experience in conversational interactions. For accurate translations (especially for Chinese and name transliterations), ChatGPT still has some way to go to achieve perfection, but in terms of fluency and recognizing specific names, it is comparable to other online translation tools. Since ChatGPT is a large language model, it currently does not have web search capabilities, so it can only answer based on the dataset it had up until 2021. For example, it does not know about the 2022 World Cup or answer questions like Siri about today’s weather or help you search for information. If ChatGPT could go online to find learning materials and search for knowledge, it would likely achieve even greater breakthroughs. Even with limited knowledge, ChatGPT can still answer many bizarre questions posed by imaginative humans. To prevent ChatGPT from developing bad habits, it uses algorithms to filter out harmful and deceptive training inputs.
Queries are filtered through a moderate API, rejecting potential racist or sexist prompts.
2. Principles of ChatGPT/GPT
▌2.1 NLP
The known limitations in the field of NLP/NLU include misunderstandings of repetitive text, highly specialized topics, and contextual phrases. It usually takes years of training for humans or AI to have normal conversations. NLP models not only need to understand the meanings of words but also how to construct sentences and provide contextually meaningful answers, even using appropriate slang and technical vocabulary.
Applications of NLP TechnologyEssentially, the GPT-3 or GPT-3.5 that underlies ChatGPT is an enormous statistical language model or sequential text prediction model.
▌2.2 GPT vs. BERT
Similar to the BERT model, ChatGPT or GPT-3.5 generates each word (or phrase) automatically based on the input statement and the probabilities of the language/corpus. From a mathematical or machine learning perspective, language models model the probability correlations of word sequences, predicting the probability distributions of the next moment’s different statements or even language sets based on previously spoken statements (which can be viewed as vectors in mathematics). ChatGPT is trained using reinforcement learning from human feedback, which enhances machine learning through human intervention for better results. During the training process, human trainers play the roles of users and AI assistants and fine-tune the model using proximal policy optimization algorithms. Due to ChatGPT’s stronger performance and massive parameters, it contains more data on various topics and can handle more niche subjects. ChatGPT can now further tackle tasks such as answering questions, writing articles, summarizing texts, translating languages, and generating computer code.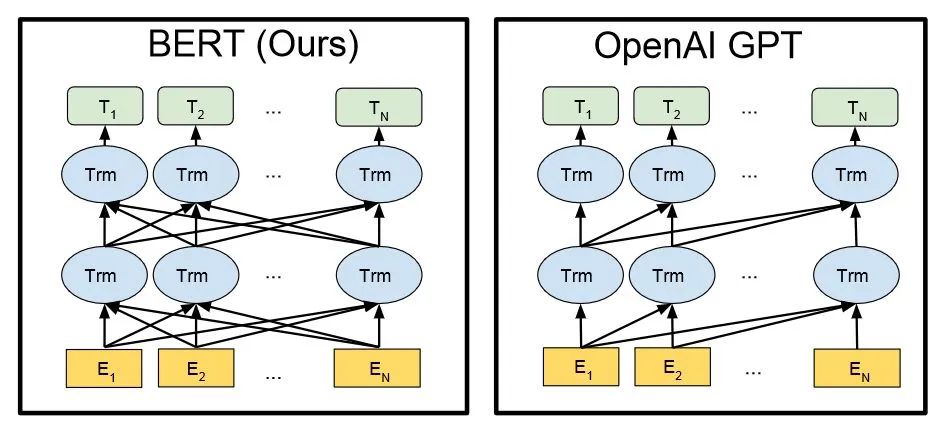 Technical Architecture of BERT and GPT (In the image, En represents each input word, and Tn represents each output word)
Technical Architecture of BERT and GPT (In the image, En represents each input word, and Tn represents each output word)
3. Technical Architecture of ChatGPT
▌3.1 Evolution of the GPT Family
When talking about ChatGPT, one cannot fail to mention the GPT family. Before ChatGPT, there were several well-known siblings, including GPT-1, GPT-2, and GPT-3. Each of these siblings is larger than the last, and ChatGPT is more similar to GPT-3.
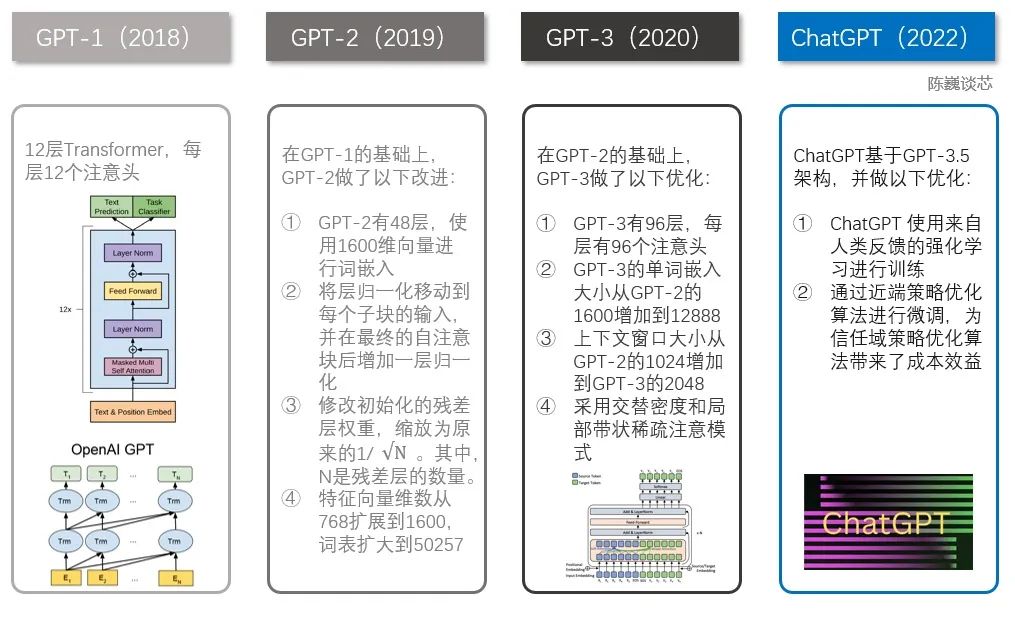
Technical Comparison of ChatGPT and GPT 1-3
Both the GPT family and the BERT model are well-known NLP models, both based on transformer technology. GPT-1 has only 12 transformer layers, while GPT-3 has increased to 96 layers.
▌3.2 Reinforcement Learning from Human Feedback
InstructGPT/GPT-3.5 (the predecessor of ChatGPT) differs from GPT-3 mainly because it introduces a new training paradigm called RLHF (Reinforcement Learning from Human Feedback). This training paradigm enhances human regulation of the model’s output and provides a more interpretable ranking of the results. In InstructGPT, the following are the evaluation criteria for the “goodness of sentences.”
- Truthfulness: Is it false or misleading information?
- Harmlessness: Does it cause physical or mental harm to people or the environment?
- Usefulness: Does it solve the user’s task?
▌3.3 TAMER Framework
Here, we must mention the TAMER (Training an Agent Manually via Evaluative Reinforcement) framework. This framework incorporates human annotators into the learning loop of agents, allowing humans to provide reward feedback to agents (i.e., guide agents in training), thus quickly achieving training task objectives. The main purpose of introducing human annotators is to accelerate training speed. Although reinforcement learning techniques have outstanding performance in many fields, they still have many shortcomings, such as slow convergence speed and high training costs. Particularly in the real world, the exploration cost or data acquisition cost for many tasks is high. How to accelerate training efficiency is one of the important issues to be solved in reinforcement learning tasks today. The TAMER framework allows the knowledge of human annotators to be used to train agents in the form of reward feedback, accelerating their rapid convergence.
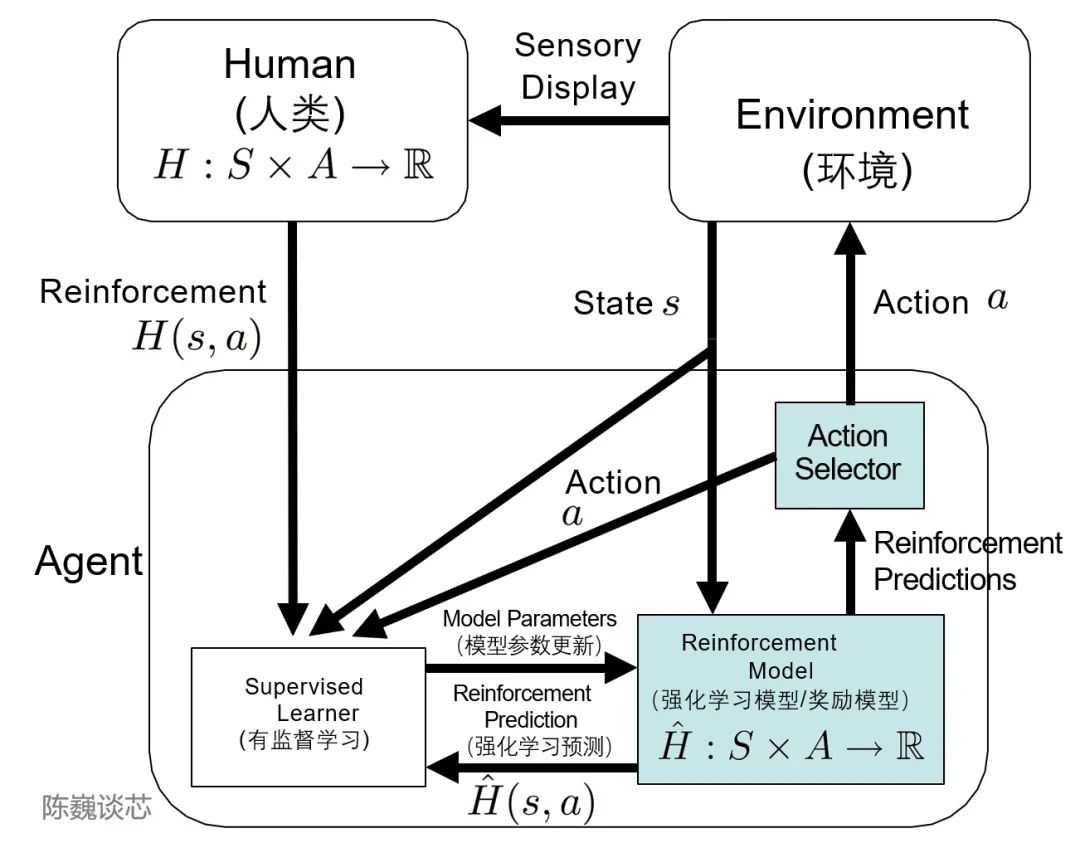
Application of the TAMER Architecture in Reinforcement LearningIn practice, human annotators play the roles of users and AI assistants, providing dialogue samples that allow the model to generate responses. The annotators then score and rank the response options, feeding the better results back into the model. Agents learn from both feedback modes—human reinforcement and Markov decision process rewards—as an integrated system, fine-tuning the model through reward strategies and continuously iterating. On this basis, ChatGPT can better understand and fulfill human language or instructions than GPT-3, mimicking humans and providing coherent, logical textual information.
▌3.4 Training of ChatGPT
The training process of ChatGPT is divided into three stages: First Stage: Training the Supervised Policy Model GPT-3.5 itself finds it challenging to understand the different intentions inherent in various types of human instructions and to determine whether the generated content is of high quality. To help GPT-3.5 initially understand the intent of instructions, questions are randomly drawn from the dataset, and human annotators provide high-quality answers, which are then used to fine-tune the GPT-3.5 model (resulting in the SFT model, Supervised Fine-Tuning). At this point, the SFT model is already superior to GPT-3 in following instructions/dialogues but may not necessarily align with human preferences.
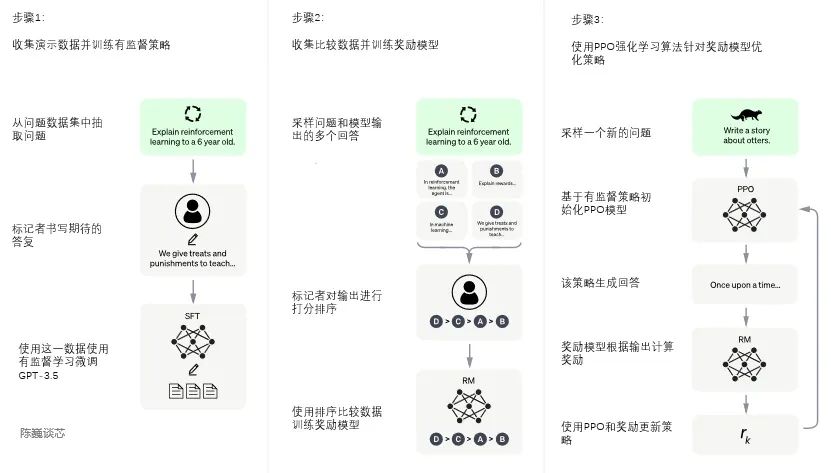
Training Process of the ChatGPT ModelSecond Stage: Training the Reward Model (Reward Model, RM)This stage mainly involves using human-annotated training data (about 33K data points) to train the reward model. Questions are randomly drawn from the dataset, and the model generated in the first stage produces multiple different answers for each question. Human annotators rank these results based on comprehensive considerations. This process is similar to coaching or teaching. Next, the ranking results are used to train the reward model. For multiple ranking results, pairs are combined to form multiple training data pairs. The RM model receives an input and outputs a score evaluating the quality of the answer. Thus, for each training data pair, parameters are adjusted so that high-quality answers receive higher scores than low-quality ones. Third Stage: Using PPO (Proximal Policy Optimization) Reinforcement Learning to Optimize the Policy. The core idea of PPO is to transform the on-policy training process in Policy Gradient into off-policy, meaning the transition from online learning to offline learning, a process called Importance Sampling. This stage utilizes the reward model trained in the second stage to update the pre-trained model parameters based on reward scores. Questions are randomly drawn from the dataset, and the PPO model generates answers, which are scored for quality using the previously trained RM model. The reward scores are passed down sequentially, generating policy gradients to update the PPO model parameters.
If we continuously repeat the second and third stages through iteration, we will train a higher-quality ChatGPT model.
4. Limitations of ChatGPT
As long as users input questions, does it mean we no longer need to feed Google or Baidu with keywords to get immediate answers?
Although ChatGPT demonstrates excellent contextual dialogue capabilities and even programming skills, changing the public’s perception of human-computer dialogue robots (ChatBots) from “artificially intelligent idiots” to “interesting,” we must also recognize that ChatGPT technology still has some limitations and is continuously improving. 1) ChatGPT lacks “common sense” and inference abilities in areas where it has not been trained on a large corpus, and it may even spout nonsense seriously. ChatGPT can “create answers” in many fields, but when users seek correct answers, ChatGPT may also provide misleading responses. For example, when asked to solve an elementary school math problem, although it can write a long calculation process, the final answer may be incorrect. So should we trust ChatGPT’s results or not?

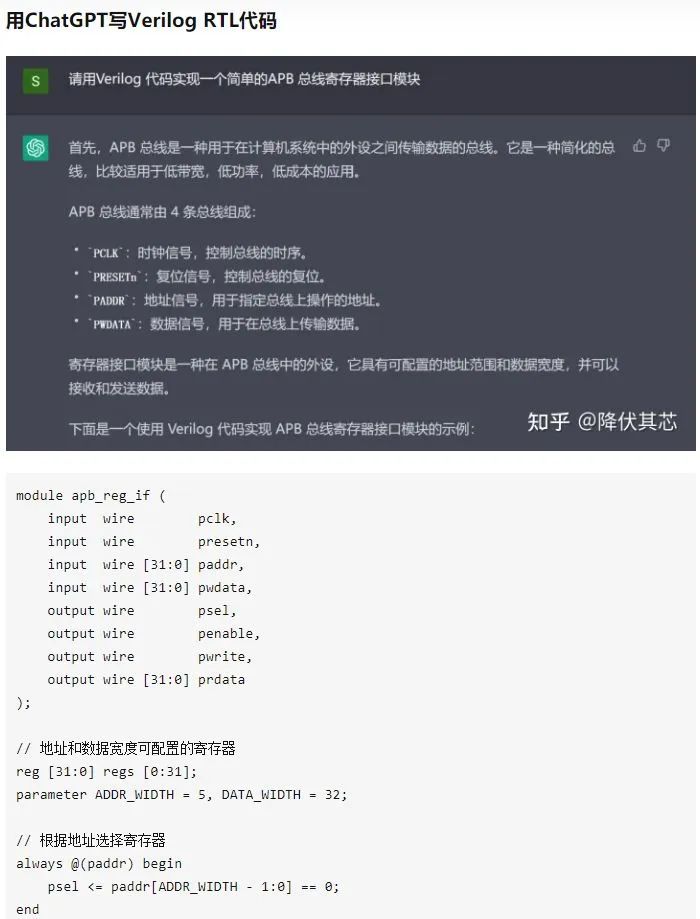
ChatGPT provides an incorrect answer to a math problem2) ChatGPT cannot handle complex, lengthy, or particularly specialized language structures. For questions from highly specialized fields such as finance, natural sciences, or medicine, if it has not been sufficiently “fed” with relevant corpus, ChatGPT may not generate appropriate responses. 3) ChatGPT requires a significant amount of computing power (chips) to support its training and deployment. Aside from the need for a vast corpus of data to train the model, currently, ChatGPT still requires high-power servers for application, and the costs of these servers are unaffordable for ordinary users. Even models with billions of parameters require an astonishing amount of computational resources to run and train. Faced with the billions of user requests from real search engines, adopting the current free strategy would be difficult for any company to bear this cost. Therefore, for the general public, we still need to wait for a more lightweight model or a cost-effective computing platform. 4) ChatGPT cannot incorporate new knowledge online, and retraining the GPT model whenever new knowledge emerges is unrealistic due to training time and costs, which are difficult for ordinary trainers to accept. If an online training model for new knowledge seems feasible and relatively low in corpus costs, it can easily lead to catastrophic forgetting of existing knowledge due to the introduction of new data. 5) ChatGPT remains a black box model. Currently, we cannot decompose the internal algorithmic logic of ChatGPT, so we cannot guarantee that ChatGPT will not produce harmful or attacking statements against users. Of course, despite its flaws, engineers have shared dialogues requesting ChatGPT to write Verilog code (chip design code). It is evident that ChatGPT’s level has surpassed that of some Verilog beginners.
5. Future Improvement Directions for ChatGPT
▌5.1 Reducing Human Feedback with RLAIF
At the end of 2020, Dario Amodei, former VP of research at OpenAI, founded an AI company called Anthropic with 10 employees. Most of the founding team members of Anthropic were early and core employees of OpenAI, having participated in OpenAI’s GPT-3, multimodal neurons, and reinforcement learning of human preferences. In December 2022, Anthropic published a paper titled “Constitutional AI: Harmlessness from AI Feedback,” introducing the AI model Claude.
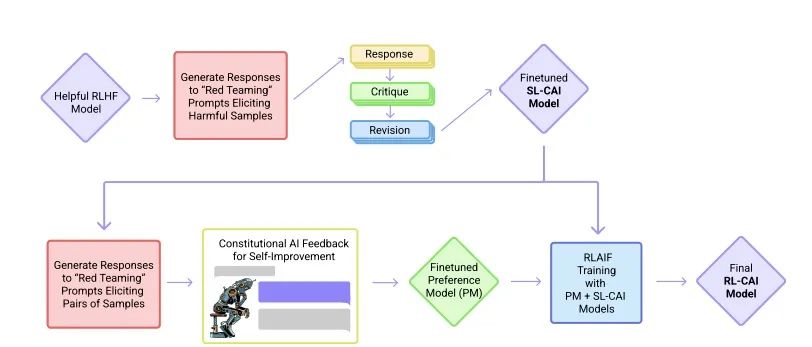
Training Process of the CAI ModelClaude and ChatGPT both rely on reinforcement learning (RL) to train preference models. CAI (Constitutional AI) is also based on RLHF, with the difference being that CAI’s ranking process uses models (rather than humans) to provide an initial ranking of all generated outputs. CAI uses AI feedback to replace human preferences for expressing harmlessness, i.e., RLAIF, where AI evaluates response content based on a set of constitutional principles.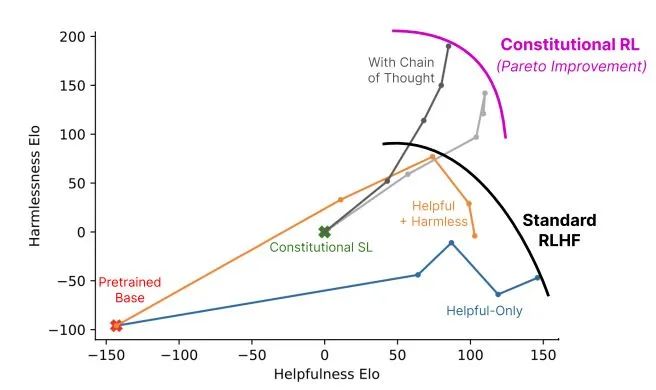
▌5.2 Addressing Mathematical Shortcomings
Although ChatGPT has strong dialogue capabilities, it tends to spout nonsense in mathematical conversations. Computer scientist Stephen Wolfram has proposed a solution to this problem. Stephen Wolfram created the Wolfram Language and the computational knowledge search engine Wolfram | Alpha, which is implemented through Mathematica.
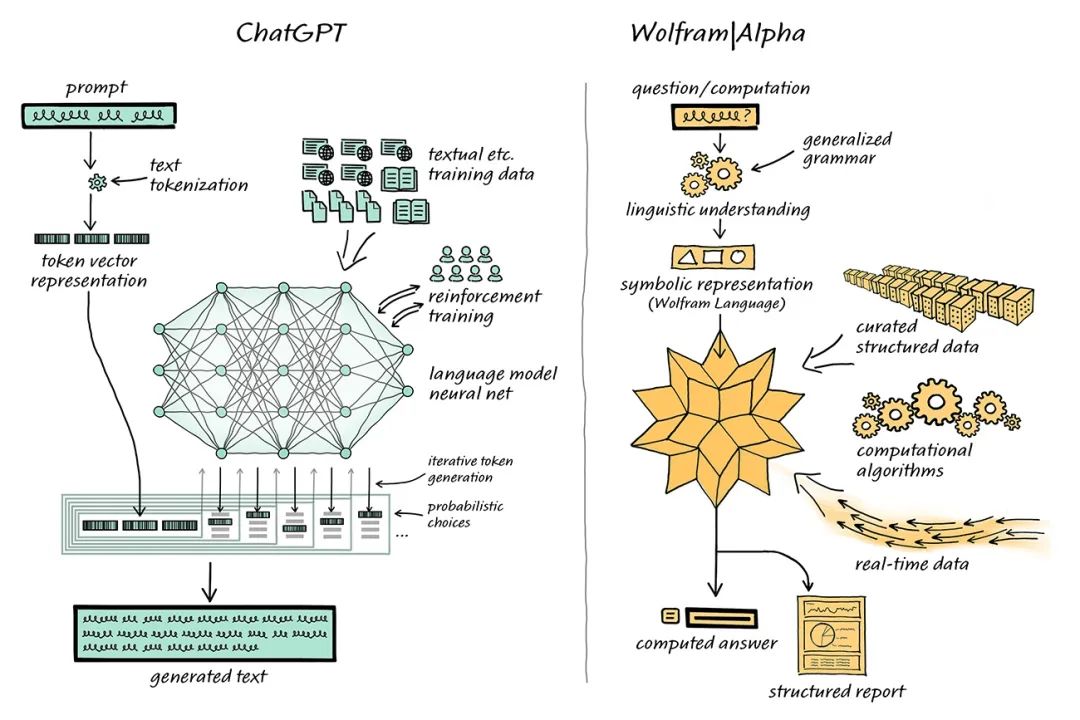
Combining ChatGPT with Wolfram | Alpha to Solve ProblemsIn this combined system, ChatGPT can “converse” with Wolfram | Alpha just like humans do, and Wolfram | Alpha will use its symbolic translation capability to translate the natural language expressions obtained from ChatGPT into corresponding symbolic computation language. In the past, there has been a divergence in the academic community regarding the “statistical methods” used by ChatGPT and the “symbolic methods” employed by Wolfram | Alpha. However, the complementarity of ChatGPT and Wolfram | Alpha now provides the possibility of advancing the NLP field. ChatGPT does not need to generate such code; it only needs to generate conventional natural language, which is then translated into precise Wolfram Language by Wolfram | Alpha, and computed by the underlying Mathematica.
▌5.3 Miniaturization of ChatGPT
Although ChatGPT is powerful, its model size and usage costs deter many users. There are three types of model compression that can reduce model size and costs. The first method is quantization, which reduces the precision of individual weight values. For example, reducing the Transformer from FP32 to INT8 has minimal impact on its precision. The second method of model compression is pruning, which involves removing network elements, ranging from individual weights (unstructured pruning) to higher-granularity components such as weight matrix channels. This method is effective in visual and smaller-scale language models. The third method of model compression is sparsification. For instance, the SparseGPT proposed by the Austrian Institute of Science and Technology (ISTA) can prune the GPT series models to 50% sparsity in a single pass without any retraining. For the GPT-175B model, this can be achieved using a single GPU in a few hours.
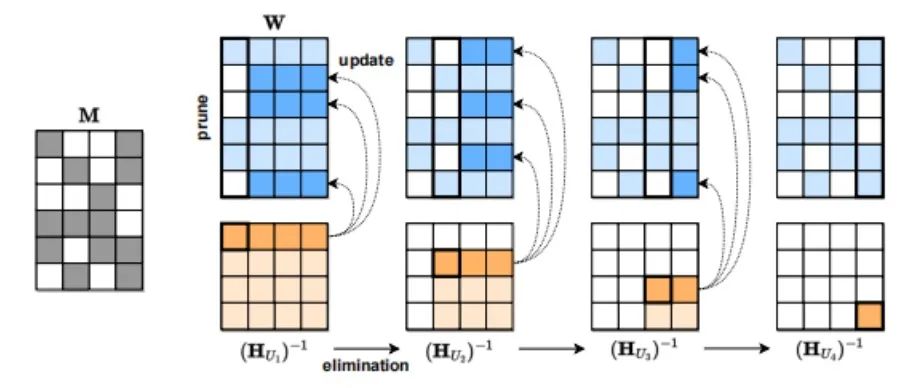
SparseGPT Compression Process
6. Future of ChatGPT in Industry and Investment Opportunities
▌6.1 AIGC
Speaking of ChatGPT, one cannot ignore AIGC. AIGC refers to using artificial intelligence technology to generate content. Compared to the UGC (user-generated content) and PGC (professionally generated content) of the previous Web 1.0 and Web 2.0 eras, AIGC, which represents AI-generated content, marks a new round of transformation in content production methods, and AIGC content is expected to experience exponential growth in the Web 3.0 era. The emergence of the ChatGPT model is of significant importance for text/voice modality AIGC applications and will have a substantial impact on the upstream and downstream of the AI industry.
▌6.2 Beneficial Scenarios
From the perspective of downstream related beneficial applications, this includes but is not limited to no-code programming, novel generation, conversational search engines, voice companions, voice work assistants, conversational virtual humans, AI customer service, machine translation, chip design, etc. From the perspective of increasing demand upstream, this includes computing power chips, data labeling, natural language processing (NLP), etc.
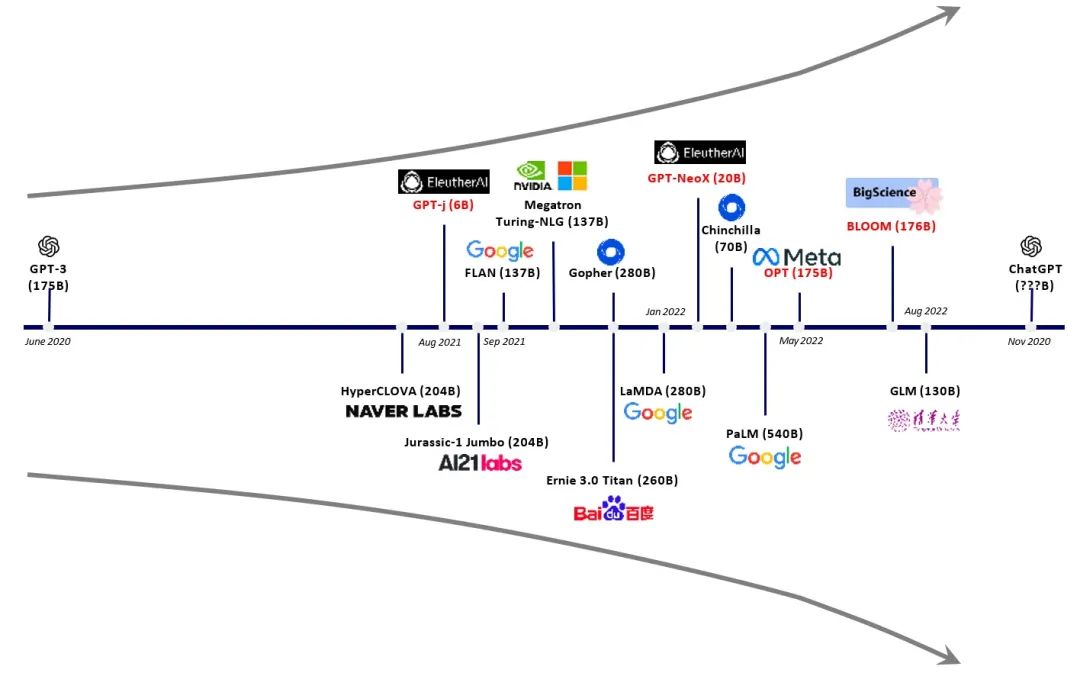
The Large Model is in an Explosive State (more parameters / greater demand for computing power chips)
With continuous advancements in algorithmic and computing technologies, ChatGPT will further evolve into more advanced and powerful versions, applying in more fields to generate more and better dialogues and content for humanity. Finally, the author asked about the position of storage-computing integration technology in the field of ChatGPT (the author is currently focusing on promoting the product landing of storage-computing integration chips), and ChatGPT boldly predicted that storage-computing integration technology will dominate the ChatGPT chip market. (This resonates with me )
)

References:
-
ChatGPT: Optimizing Language Models for Dialogue ChatGPT: Optimizing Language Models for Dialogue
-
GPT Paper: Language Models are Few-Shot Learners Language Models are Few-Shot Learners
-
InstructGPT Paper: Training Language Models to Follow Instructions with Human Feedback Training Language Models to Follow Instructions with Human Feedback
-
Huggingface Interpretation of RHLF Algorithm: Illustrating Reinforcement Learning from Human Feedback (RLHF) Illustrating Reinforcement Learning from Human Feedback (RLHF)
-
RHLF Algorithm Paper: Augmenting Reinforcement Learning with Human Feedback cs.utexas.edu/~ai-lab/p
-
TAMER Framework Paper: Interactively Shaping Agents via Human Reinforcement cs.utexas.edu/~bradknox
-
PPO Algorithm: Proximal Policy Optimization Algorithms Proximal Policy Optimization Algorithms
Article Author:Dr. Chen Wei, former Chief Scientist of Huawei’s Natural Language Processing (NLP) division, originally published in “In-Depth Analysis of Advanced AI Technologies.”Original link: https://zhuanlan.zhihu.com/p/590655677Source: Special Edition
END
Hot articles (Swipe up to read)
Article Recommendation | Jiao Xiaofeng:Overview of CO2 Detection Technology Based on TDLAS
Article Recommendation | Chen Haiming: Online Calibration Method for Magnetic Sensors in Backup Navigation Systems
Article Recommendation | Ren Dantong: Dual-Light Fusion Workshop Personnel Behavior Recognition Method for Smart Factories
Article Recommendation | Li Shuhao: Research on Integrated Monitoring Technology in Bearing Fault Diagnosis
Article Recommendation | Zhuo Li: Multi-Attribute Collaborative Recognition Method for Pedestrians Based on ResNet50 and Channel Attention Mechanism
Article Recommendation | Liang Minjian: Research on Mechanical Fault Classification of Escalators Based on One-Dimensional Convolutional Neural Networks
Article Recommendation | Hou Qilin: Remaining Useful Life Prediction of Aviation Lithium Batteries Based on Indirect Health Indicators and Echo State Networks
Article Recommendation | Chen Peng: An End-to-End Natural Scene Text Detection and Recognition Model
Article Recommendation | Hou Feng: Remote Sensing Image Retrieval Based on Deep Feature Dictionary Learning and Largevis
Article Recommendation | Wang Xinyao: Global Inertial Navigation and Integrated Navigation Methods Based on Earth Coordinate System
Article Recommendation | Chen Lijing: Fault Diagnosis of Aviation Inverters Based on Multi-Class SVM
Article Recommendation | Li Mingfei: Discussion on Image Enhancement and Flow Field Density Processing of Leaf Shadow Pattern Experiments
Article Recommendation | Liu Qiuyu: Flexible Pressure Sensor Research Based on Capacitive-Resistive Conversion Principle
Article Recommendation | Li Lei: Research on Data-Driven Fault Prediction Methods
Article Recommendation | Yan Junjie: Automatic Precision Assembly Technology of Satellite Antenna Modules Based on Machine Vision
Article Recommendation | Yao Yanling: Research on the Diagnosis Model of Surge in Aviation Engines Based on CNN-Seq2Seq
Article Recommendation | Guan Li: Overview of Electric Static Liquid Actuation Technology Research in Aircraft Flight Control Systems
Article Recommendation | He Yunze: Analysis of Acoustic Emission Signals of Power Devices in Inverter Circuits
Article Recommendation | Xie Li: Detection of Circuit Board Component Defects Based on Improved YOLOv4 Network
Article Recommendation | Wang Yizhou: Fingerprint Extraction from Short Videos Based on R(2+1)D Twin Networks
Article Recommendation | Han Han: Overview of No-Reference Image Quality Assessment Based on Deep Learning
Article Recommendation | Wang Jiulong: Research on Fatigue Test Technology of Helicopter Tail Rotor Blades
Article Recommendation | Sun Weihong: Research on Portable ECG Monitoring Systems Based on Flexible Electrodes
Article Recommendation | Zhang Meiju: Research Status and Development Trends of Ceramic Substrate Thin Film Thermocouples
Article Recommendation | Ouyang Lin: Fatigue Driving Detection Algorithm Based on Driver Facial Temporal Data
Article Recommendation | Zhang Wenli: Multi-Target Tracking Algorithm Based on Improved Transformer and Anchor-free Network
Article Recommendation | Liu Guanjun: Research Progress of Silicon-based and Graphene-based Resonant Pressure Sensors
Article Recommendation | Jiang Chao: Overview of Image-Based UAV Battlefield Situation Awareness Technology
Article Recommendation | Zhang Feiyang: Overview of Alertness Detection Research Based on Physiological Signals
Article Recommendation | Qiu Fang: Research on Autonomous Management Software Architecture for Spacecraft Control Systems
Article Recommendation | Wang Yanshan: Research Progress of Flexible Pressure/Strain Sensors Based on Graphene
Article Recommendation | Wang Hong: Research on the Testing Technology System Architecture of Civil Aircraft
Article Recommendation | Liu Yawei: Overview of Digital Twin and Application Research for Aircraft Structural Health Management
Article Recommendation | Sun Zhiyan: Overview of Development of Aviation Engine Control Systems
Forum | Academician Gao Jinjie: Intelligent Monitoring of Vibration Faults in Aviation Engines
Forum | Wang Haifeng: Understanding and Discussion on the Intelligent Development of Aviation Equipment Guarantee
Forum | Wang Huamao: Overview of Comprehensive Testing Technology and Development Trends for Spacecraft
Forum | Li Kaisheng: Discussion on Testing and Control Technology Needs for Large Aircraft Power Systems
2021 Collection of Excellent Papers in Computer and Automation Technology
2021 Collection of Excellent Papers in Aerospace
2020 Collection of Excellent Papers in Aerospace
2020 Collection of Excellent Papers in Computer and Automation Technology
Journal Dynamics (Swipe up to read)
Notice on the Call for Papers for the “Gas Turbine Engine Measurement and Control Technology” Column of “Measurement and Control Technology”
“Measurement and Control Technology” continues to be selected as a “Core Journal of Chinese Science and Technology”
Journal Directory (Swipe up to read)
2023 Issue 1
2022 Issue 12
2022 Issue 11
2022 Issue 10 Special Issue on Intelligent Testing Technology for On-Board Systems
2022 Issue 9 Special Issue on Advanced Sensors and Atmospheric/Meteorological Measurement Technology
2022 Issue 8
2022 Issue 7
2022 Issue 6
2022 Issue 5
2022 Issue 4
2022 Issue 3
2022 Issue 2
2022 Issue 1
2021 Issue 12
2021 Issue 11 Special Issue on Condition Monitoring Sensor Technology
2021 Issue 10
2021 Issue 9
2021 Issue 8
2021 Issue 7
2021 Issue 6
2021 Issue 5
2021 Issue 4
2021 Issue 3
2021 Issue 2
2021 Issue 1
2020 Issue 8 Special Issue on Machine Vision Technology
2020 Issue 12 Special Issue on Artificial Intelligence and Testing Support