Reprinted from | Xinzhiyuan
Author | JinHui
Source | https://zhuanlan.zhihu.com/p/220403674
1
『Visualization of Network Structure』
When training a neural network, in addition to observing the trend of the loss function with each step or epoch to establish a basic understanding of the network optimization, we can also use some additional visualization libraries to visualize our neural network structure. This will more efficiently present the current network structure to the reader.
To visualize the neural network, we first create a simple Convolutional Neural Network:
import torch
import torch.nn as nn
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(1, 16, 3, 1, 1),
nn.ReLU(),
nn.AvgPool2d(2, 2)
)
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.fc = nn.Sequential(
nn.Linear(32 * 7 * 7, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU()
)
self.out = nn.Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
output = self.out(x)
return output
Output the network structure:
MyConvNet = ConvNet()
print(MyConvNet)
Output result:
ConvNet(
(conv1): Sequential(
(0): Conv2d(1, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(conv2): Sequential(
(0): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): Linear(in_features=1568, out_features=128, bias=True)
(1): ReLU()
(2): Linear(in_features=128, out_features=64, bias=True)
(3): ReLU()
)
(out): Linear(in_features=64, out_features=10, bias=True)
)
With the basic neural network established, we can visualize the above convolutional neural network using the <span>HiddenLayer</span> and <span>PyTorchViz</span> libraries.
It should be noted that both of these libraries are developed based on Graphviz, so if you do not have Graphviz installed and added to your environment variables, please install the Graphviz tool yourself. Installation tutorial
1.1 Visualizing the Network with HiddenLayer
First, of course, you need to install the library. Open cmd and enter:
pip install hiddenlayer
The basic drawing program is as follows:
import hiddenlayer as h
vis_graph = h.build_graph(MyConvNet, torch.zeros([1 ,1, 28, 28])) # Get the object to draw the image
vis_graph.theme = h.graph.THEMES["blue"].copy() # Specify theme color
vis_graph.save("./demo1.png") # Save the image path
The effect is as follows:

1.2 Visualizing the Network with PyTorchViz
First, install the library:
pip install torchviz
Here we only use the visualization function <span>make_dot()</span> to obtain the drawing object, which is similar to <span>HiddenLayer</span>, but the difference is that <span>PyTorch</span> allows you to specify the input value and prediction value of the network before drawing.
from torchviz import make_dot
x = torch.randn(1, 1, 28, 28).requires_grad_(True) # Define an input value for the network
y = MyConvNet(x) # Get the network's prediction value
MyConvNetVis = make_dot(y, params=dict(list(MyConvNet.named_parameters()) + [('x', x)]))
MyConvNetVis.format = "png"
# Specify the folder for the generated file
MyConvNetVis.directory = "data"
# Generate the file
MyConvNetVis.view()
Open the data folder in the same root directory as the above code, where there will be a <span>.gv</span> file and a <span>.png</span> file. The <span>.gv</span> file is the script code generated by the Graphviz tool to create the image, and the <span>.png</span> file is the image compiled from the <span>.gv</span> file. Just open the <span>.png</span> file.
By default, the above program will automatically open the .png file after running
Generate image:

2
『Training Process Visualization』
Observing the changes in loss function or accuracy at each step of our network can effectively help us assess the quality of the current training process. If we can visualize these processes, both the accuracy and comfort of our judgments will improve.
This section mainly discusses how to visualize the training process using the visualization tools <span>tensorboardX</span> and the <span>HiddenLayer</span> we just used.
To train the network, we first import the data needed for training. Here we import the MNIST dataset and perform some basic data processing before training.
import torchvision
import torch.utils.data as Data
# Prepare the MNIST dataset for training
train_data = torchvision.datasets.MNIST(
root = "./data/MNIST", # Path to extract data
train=True, # Use the training data in MNIST
transform=torchvision.transforms.ToTensor(), # Convert to torch.tensor
download=False # If running for the first time, set to True to download the dataset to the root directory
)
# Define loader
train_loader = Data.DataLoader(
dataset=train_data,
batch_size=128,
shuffle=True,
num_workers=0
)
test_data = torchvision.datasets.MNIST(
root="./data/MNIST",
train=False, # Use test data
download=False
)
# Normalize test data to 0-1
test_data_x = test_data.data.type(torch.FloatTensor) / 255.0
test_data_x = torch.unsqueeze(test_data_x, dim=1)
test_data_y = test_data.targets
# Print the shape of test data and training data
print("test_data_x.shape:", test_data_x.shape)
print("test_data_y.shape:", test_data_y.shape)
for x, y in train_loader:
print(x.shape)
print(y.shape)
break
Result:
test_data_x.shape: torch.Size([10000, 1, 28, 28])
test_data_y.shape: torch.Size([10000])
torch.Size([128, 1, 28, 28])
torch.Size([128])
2.1 Visualizing the Training Process with TensorboardX
<span>tensorboard</span> is a deep learning visualization tool developed by Google for the deep learning framework TensorFlow. With the efforts of the PyTorch team, they developed tensorboardX to allow PyTorch users to enjoy the benefits of TensorBoard.
First, install the relevant libraries:
pip install tensorboardX
pip install tensorboard
Add the folder path where tensorboard.exe is located to the environment variable path (for example, if my tensorboard.exe path is <span>D:\Python376\Scripts\tensorboard.exe</span>, then add <span>D:\Python376\Scripts</span> to the path).
The following is the usage process of <span>tensorboardX</span>. The basic usage is to first obtain a log writer object through the <span>SummaryWriter</span> class under <span>tensorboardX</span>. Then, by using a set of methods of this object, events are added to the log, generating corresponding images. Finally, start the frontend server, and you can see the final result in localhost.
The code to train the network and visualize the training process is as follows:
from tensorboardX import SummaryWriter
logger = SummaryWriter(log_dir="data/log")
# Get optimizer and loss function
optimizer = torch.optim.Adam(MyConvNet.parameters(), lr=3e-4)
loss_func = nn.CrossEntropyLoss()
log_step_interval = 100 # Step interval for logging
for epoch in range(5):
print("epoch:", epoch)
# Iterate through the data loader for each round
for step, (x, y) in enumerate(train_loader):
# Forward computation -> calculate loss function -> (from loss function) backpropagation -> update network
predict = MyConvNet(x)
loss = loss_func(predict, y)
optimizer.zero_grad() # Clear gradients (optional)
loss.backward() # Backpropagation to calculate gradients
optimizer.step() # Update network
global_iter_num = epoch * len(train_loader) + step + 1 # Calculate the current step from the start of training (global iteration count)
if global_iter_num % log_step_interval == 0:
# Output to console
print("global_step:{}, loss:{:.2}".format(global_iter_num, loss.item()))
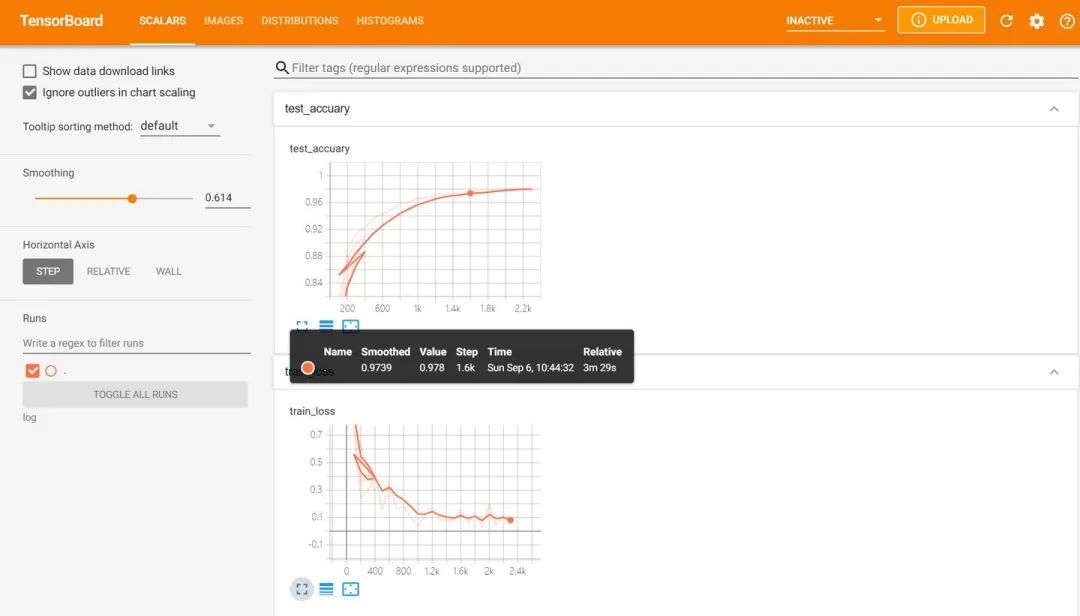
# First log entry: loss function - global iteration count
logger.add_scalar("train loss", loss.item() ,global_step=global_iter_num)
# Predict on the test set and calculate accuracy
test_predict = MyConvNet(test_data_x)
_, predict_idx = torch.max(test_predict, 1) # Calculate the index of the maximum value after softmax, i.e., the prediction result
acc = accuracy_score(test_data_y, predict_idx)
# Second log entry: accuracy - global iteration count
logger.add_scalar("test accuary", acc.item(), global_step=global_iter_num)
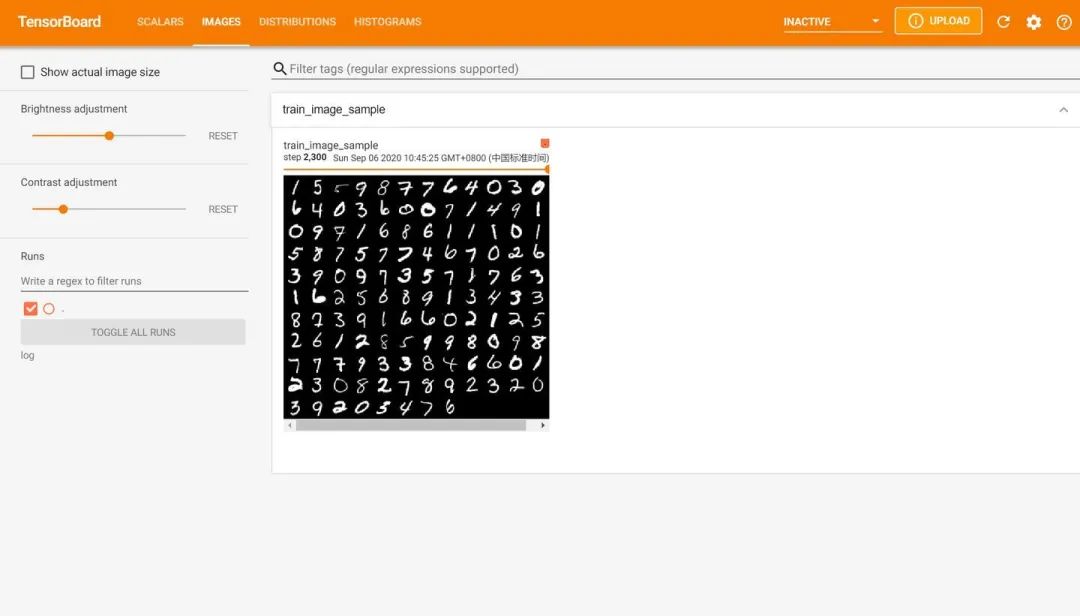
# Third log entry: 128 images in this batch
img = vutils.make_grid(x, nrow=12)
logger.add_image("train image sample", img, global_step=global_iter_num)
# Fourth log entry: histogram of parameter distribution in the network
for name, param in MyConvNet.named_parameters():
logger.add_histogram(name, param.data.numpy(), global_step=global_iter_num)
After running, we enter the same directory as the code in cmd (if you are using PyCharm, you can use the terminal in PyCharm) and enter the command <span>tensorboard --logdir="./data/log"</span> to start the server.
The parameter after logdir is the path of the log file folder
Then visit the URL in the red box with a web browser to obtain the visualization interface. Click on the page controls above to view the images generated by <span>add_scalar</span>, <span>add_image</span>, and <span>add_histogram</span>, and everything is very smooth.
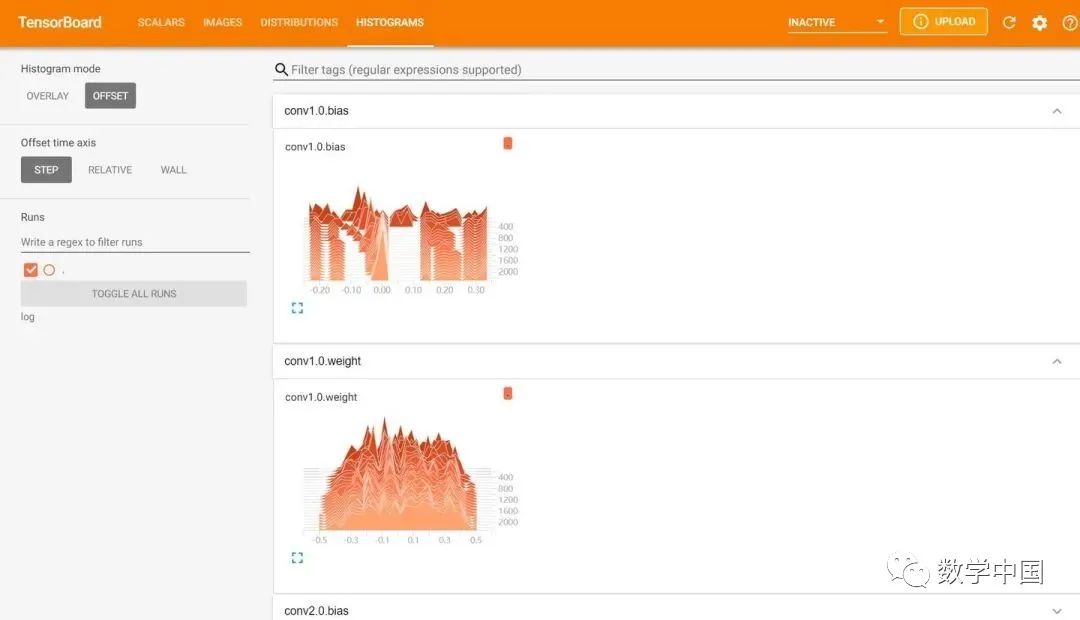
Below are some errors encountered by the author when installing and using tensorboard.
As a user who has never installed TensorFlow, the author will now start stepping into pitfalls. After stepping through, I will present several possible errors.
The first error occurs when runningtensorboard --logdir="./data/log", encountering an error indicating duplicate tensorboard packages.
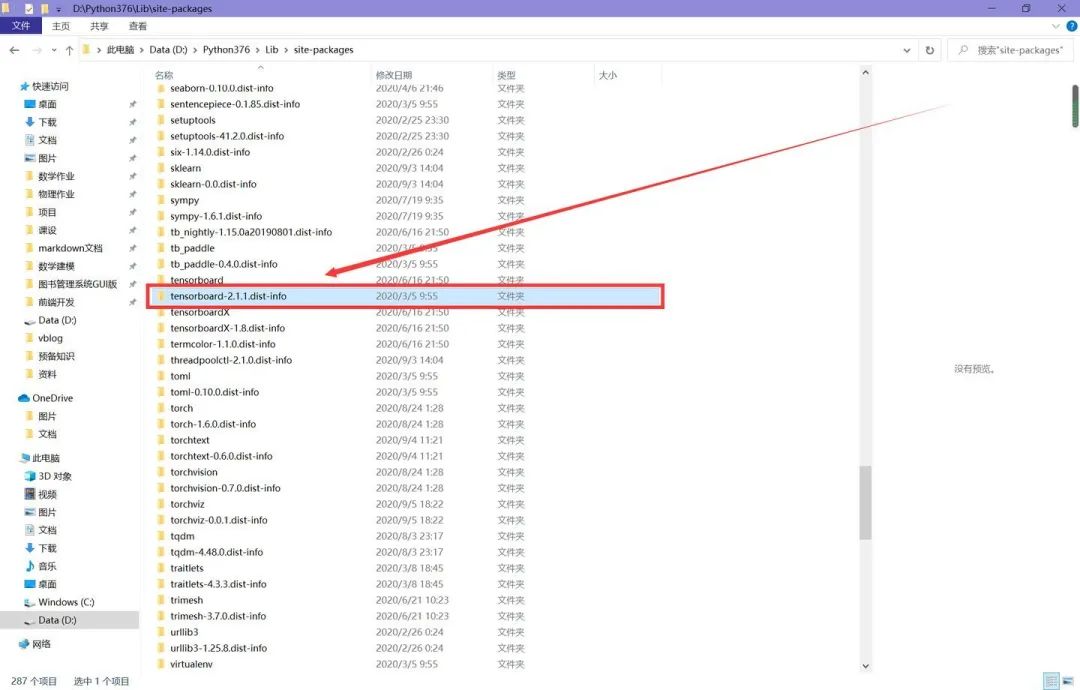
Solution: Find site-packages (if you installed globally like I did, find the site-packages at the interpreter level; if installed in the project’s virtual environment, find site-packages in the project), and delete the folder marked in red in the image below.
The second error occurs after resolving the first error, but the error still occurs, indicating an encoding error. Since the author has done some front-end work, I was told that project paths cannot contain Chinese characters, otherwise there will be encoding errors. Since the previous error involved starting the front-end server, I thought of starting from the file name.
Solution: Ensure that the file paths involved in the command and all programs do not contain Chinese characters. My computer name contains Chinese, and the tensorboard log file is suffixed with the local computer name, so I changed my computer name to English, restarted, and then entered the command, and it worked.
2.2 Visualizing the Training Process with HiddenLayer
The images from tensorboard are very beautiful, but the process is relatively cumbersome compared to other toolkits, so it is generally unnecessary to use tensorboard for small networks.
import hiddenlayer as hl
import time
# Record metrics during training
history = hl.History()
# Use canvas for visualization
canvas = hl.Canvas()
# Get optimizer and loss function
optimizer = torch.optim.Adam(MyConvNet.parameters(), lr=3e-4)
loss_func = nn.CrossEntropyLoss()
log_step_interval = 100 # Step interval for logging
for epoch in range(5):
print("epoch:", epoch)
# Iterate through the data loader for each round
for step, (x, y) in enumerate(train_loader):
# Forward computation -> calculate loss function -> (from loss function) backpropagation -> update network
predict = MyConvNet(x)
loss = loss_func(predict, y)
optimizer.zero_grad() # Clear gradients (optional)
loss.backward() # Backpropagation to calculate gradients
optimizer.step() # Update network
global_iter_num = epoch * len(train_loader) + step + 1 # Calculate the current step from the start of training (global iteration count)
if global_iter_num % log_step_interval == 0:
# Output to console
print("global_step:{}, loss:{:.2}".format(global_iter_num, loss.item()))
# Predict on the test set and calculate accuracy
test_predict = MyConvNet(test_data_x)
_, predict_idx = torch.max(test_predict, 1) # Calculate the index of the maximum value after softmax, i.e., the prediction result
acc = accuracy_score(test_data_y, predict_idx)
# Create a log dictionary indexed by epoch and step
history.log((epoch, step),
train_loss=loss,
test_acc=acc,
hidden_weight=MyConvNet.fc[2].weight)
# Visualization
with canvas:
canvas.draw_plot(history["train_loss"])
canvas.draw_plot(history["test_acc"])
canvas.draw_image(history["hidden_weight"])
Unlike tensorboard, hiddenlayer dynamically generates images during program execution, rather than after model training is complete
Below is a screenshot at a certain moment during model training:
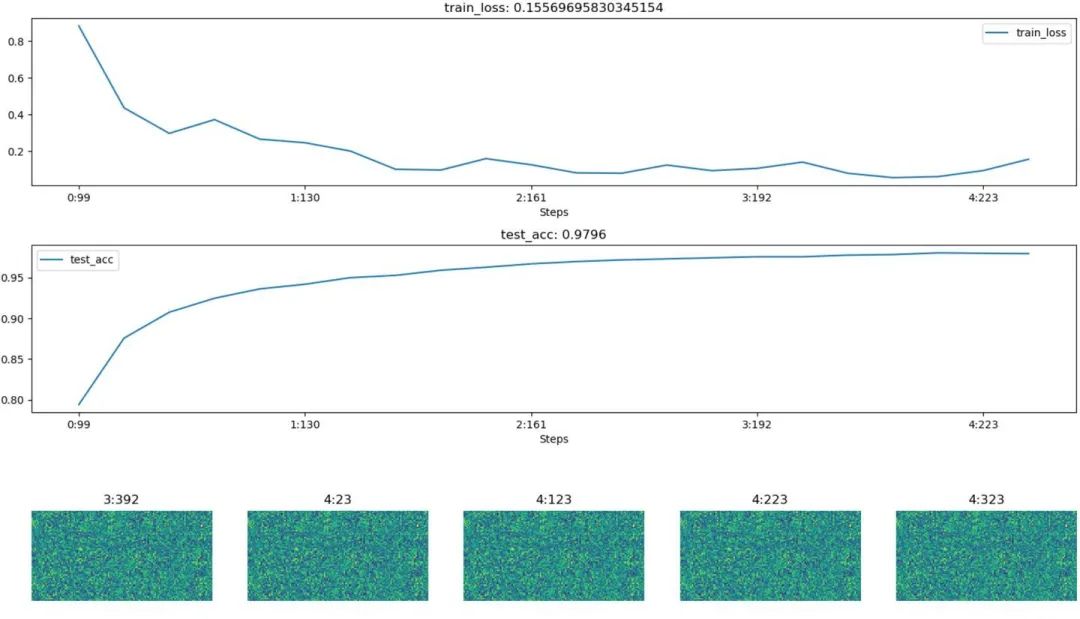
3
『Using Visdom for Visualization』
Visdom is a visualization tool developed by Facebook for PyTorch. Similar to TensorBoard, Visdom also achieves visualization by starting a frontend server locally, but in terms of specific operations, Visdom is more similar to matplotlib.pyplot. So it is very flexible to use.
First, install the visdom library, and then fill in the gaps. Since starting the frontend server requires a lot of dependencies, it may be slow the first time you start it (you need to download the dependencies for the frontend), please see here for solutions.
First, import the required third-party libraries:
from visdom import Visdom
from sklearn.datasets import load_iris
import torch
import numpy as np
from PIL import Image
In matplotlib, users can draw through the plt object, and in Visdom, a drawing object is similarly required, which we obtain through <span>vis = Visdom()</span>. When drawing, since we will draw several images at once, Visdom requires users to specify the window name for the current image (i.e., the <span>win</span> parameter); in addition, to display the blocks later, users also need to specify the drawing environment <span>env</span>, which will display images with the same parameter on the same page.
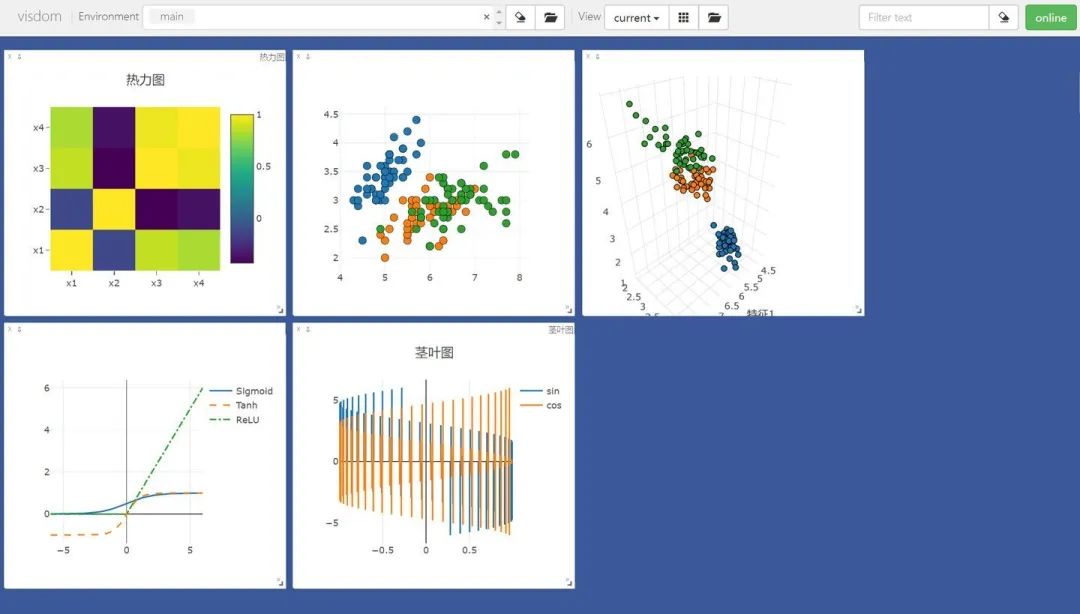
Drawing a line chart (equivalent to <span>plt.plot</span> in matplotlib)
# Data needed to draw the image
iris_x, iris_y = load_iris(return_X_y=True)
# Get drawing object, equivalent to plt
vis = Visdom()
# Add line chart
x = torch.linspace(-6, 6, 100).view([-1, 1])
sigmoid = torch.nn.Sigmoid()
sigmoid_y = sigmoid(x)
tanh = torch.nn.Tanh()
tanh_y = tanh(x)
relu = torch.nn.ReLU()
relu_y = relu(x)
# Concatenate three tensors
plot_x = torch.cat([x, x, x], dim=1)
plot_y = torch.cat([sigmoid_y, tanh_y, relu_y], dim=1)
# Draw line chart
vis.line(X=plot_x, Y=plot_y, win="line plot", env="main",
opts={
"dash" : np.array(["solid", "dash", "dashdot"]),
"legend" : ["Sigmoid", "Tanh", "ReLU"]
})
Drawing a scatter plot:
# Draw 2D and 3D scatter plots
# Parameter Y specifies the point distribution, win specifies the image window name, env specifies the image environment, opts specifies some styles through a dictionary
vis.scatter(iris_x[ : , 0 : 2], Y=iris_y+1, win="windows1", env="main")
vis.scatter(iris_x[ : , 0 : 3], Y=iris_y+1, win="3D scatter", env="main",
opts={
"markersize" : 4, # Point size
"xlabel" : "Feature 1",
"ylabel" : "Feature 2"
})
Drawing a stem plot:
# Add stem plot
x = torch.linspace(-6, 6, 100).view([-1, 1])
y1 = torch.sin(x)
y2 = torch.cos(x)
# Concatenate tensors
plot_x = torch.cat([x, x], dim=1)
plot_y = torch.cat([y1, y2], dim=1)
# Draw stem plot
vis.stem(X=plot_x, Y=plot_y, win="stem plot", env="main",
opts={
"legend" : ["sin", "cos"],
"title" : "Stem Plot"
})
Drawing a heatmap:
# Calculate the correlation matrix of feature vectors in the Iris dataset
iris_corr = torch.from_numpy(np.corrcoef(iris_x, rowvar=False))
# Draw heatmap
vis.heatmap(iris_corr, win="heatmap", env="main",
opts={
"rownames" : ["x1", "x2", "x3", "x4"],
"columnnames" : ["x1", "x2", "x3", "x4"],
"title" : "Heatmap"
})
Visualizing images, here we use a custom env name MyPlotEnv
# Visualize image
img_Image = Image.open("./example.jpg")
img_array = np.array(img_Image.convert("L"), dtype=np.float32)
img_tensor = torch.from_numpy(img_array)
print(img_tensor.shape)
# This time env is custom
vis.image(img_tensor, win="one image", env="MyPlotEnv",
opts={
"title" : "One Image"
})
Visualizing text, also drawn in MyPlotEnv:
# Visualize text
text = "hello world"
vis.text(text=text, win="text plot", env="MyPlotEnv",
opts={
"title" : "Visualized Text"
})
Run the above code, and then start the server by entering <span>python3 -m visdom.server</span> in the terminal. Then access the URL returned by the terminal in the Google browser to see the images.
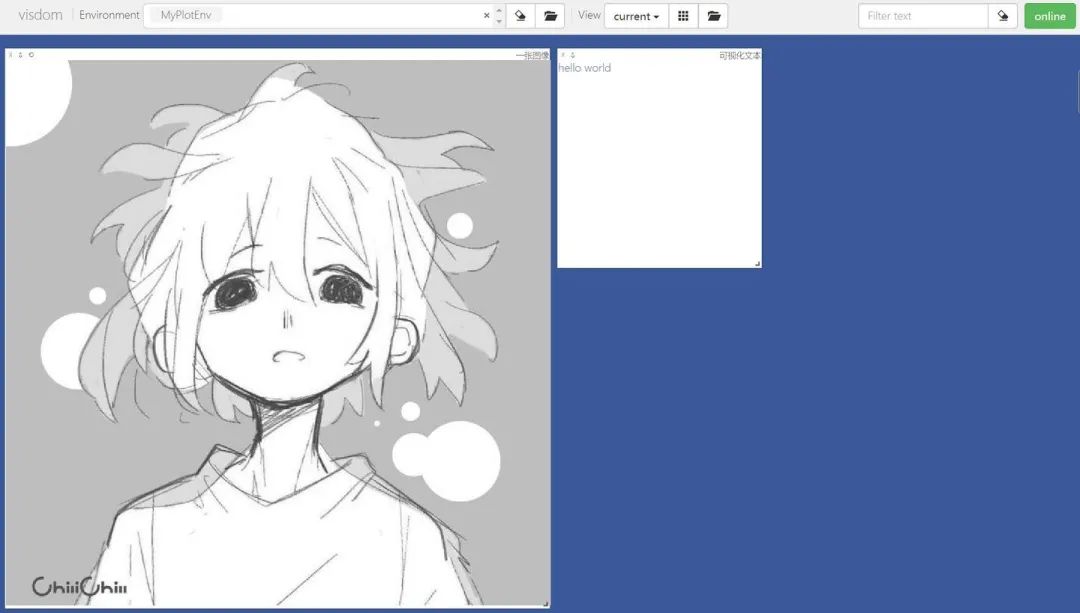
By entering different env parameters in Environment, you can see the images we drew in different environments. This is particularly useful for classification image sets.
Press Ctrl+C in the terminal to terminate the frontend server.
4
『Further』
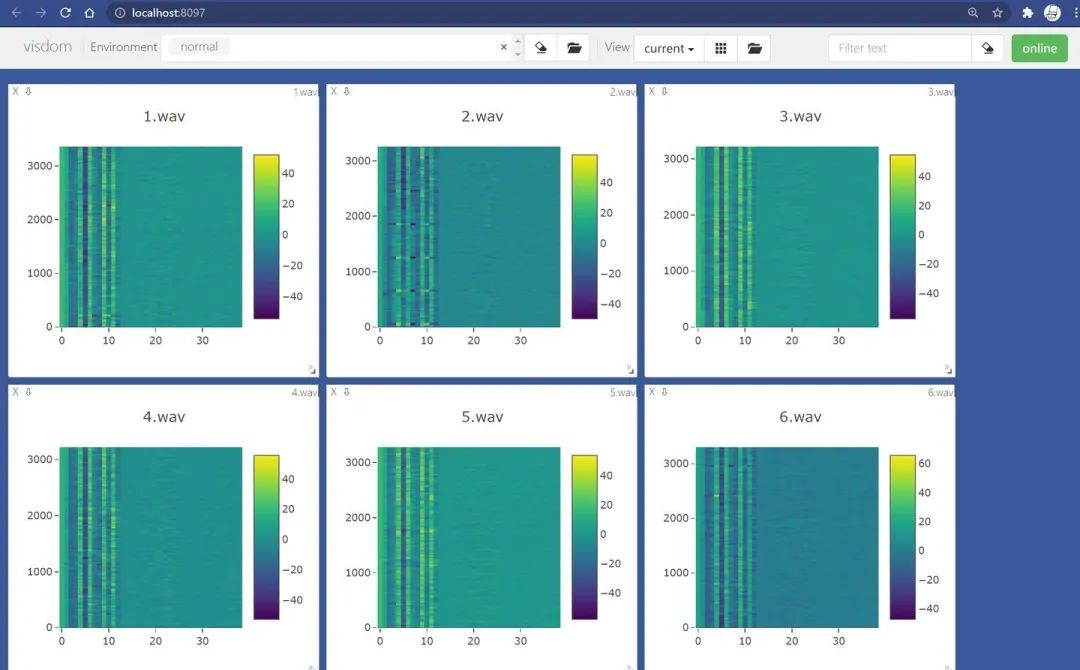
It is important to note that if your frontend server is stopped, all images will be lost, as the image data is stored in memory and not dumped to the local disk. So how can we save the current visualization results in Visdom and reuse them in the future? It is actually very simple. For example, I now have a bunch of hard-earned Mel spectrograms:
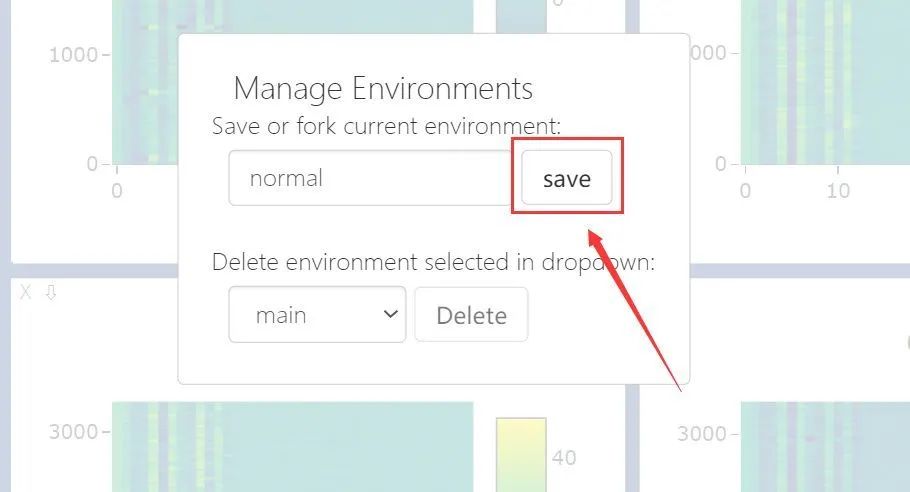
Click Manage Views
Click fork->save: (here I only saved the env named normal)
Then, in your User directory (Windows is C:\Users\account\.visdom folder, Linux is in ~/.visdom folder), you can see the saved env:
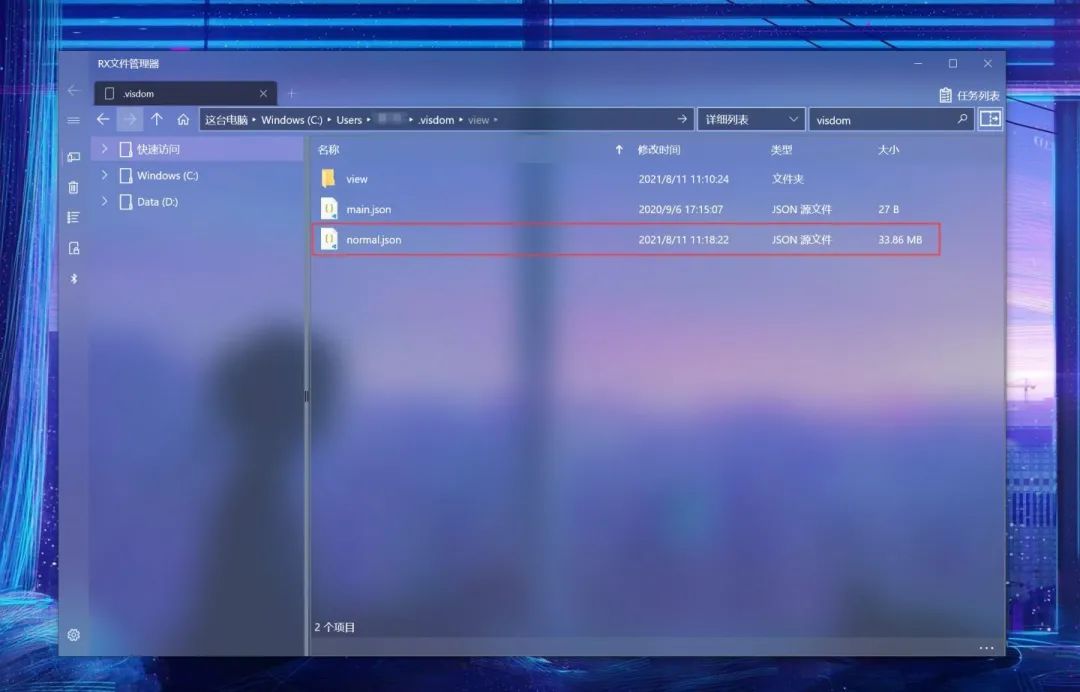
It is saved in json file format, so if you save it and then shut down the current frontend server, the image data will not be lost.
Now, after saving your precious data, please close your Visdom frontend server. Then start it again.
How to view the saved data? It is very simple. The next time you open the Visdom frontend, Visdom will read all the saved data from the .visdom folder and complete the initialization, which means you can see the previously saved data just by starting Visdom, without doing anything else!
So how do you reuse the saved data? Since you know where the saved data in Visdom is, you can directly read this data file using Python’s json package and then parse it. This is method one, as demonstrated below:
import json
with open(r"...\.visdom\normal.json", "r", encoding="utf-8") as f:
dataset : dict = json.load(f)
jsons : dict = dataset["jsons"] # Here stores the data you want to recover
reload : dict = dataset["reload"] # Here stores information about window size
print(jsons.keys()) # View all wins
out:
dict_keys(['jsons', 'reload'])
dict_keys(['1.wav', '2.wav', '3.wav', '4.wav', '5.wav', '6.wav', '7.wav', '8.wav', '9.wav', '10.wav', '11.wav', '12.wav', '13.wav', '14.wav'])
However, this method is not very elegant, so Visdom has encapsulated a second method. You can certainly check the current available env by accessing the .visdom folder, but you can also do this:
from visdom import Visdom
vis = Visdom()
print(vis.get_env_list())
out:
Setting up a new session...
['main', 'normal']
After obtaining the available environment names, you can use the get_window_data method to obtain the image data under the specified env and win. Note that this method returns str, so it needs to be parsed using json:
from visdom import Visdom
import json
vis = Visdom()
window = vis.get_window_data(win="1.wav", env="normal")
window = json.loads(window) # window is str, needs to be parsed into a dictionary
content = window["content"]
data = content["data"][0]
print(data.keys())
out:
Setting up a new session...
dict_keys(['z', 'x', 'y', 'zmin', 'zmax', 'type', 'colorscale'])
By indexing these keys, I believe it will not be difficult to reuse the original image data.
Click below
Follow us