

Reported by New Intelligence
Reported by New Intelligence
[New Intelligence Overview] The highly anticipated NeRF is expected to replace Deepfake as a new generation of visual technology. Let’s see how impressive it really is.
What, you don’t know about NeRF yet?
As the hottest AI technology in the field of computer vision this year, NeRF is widely applicable and has a bright future.
Friends on Bilibili have found new ways to utilize this technology.
Setting the stage
So, what exactly is NeRF?
NeRF (Neural Radiance Fields) is a concept first proposed in the best paper at the 2020 ECCV conference, which elevates implicit representation to a new height, using only 2D posed images as supervision to represent complex three-dimensional scenes.
The impact was significant, and since then, NeRF has rapidly developed and been applied to multiple technical directions, such as ‘new viewpoint synthesis, 3D reconstruction’, etc.
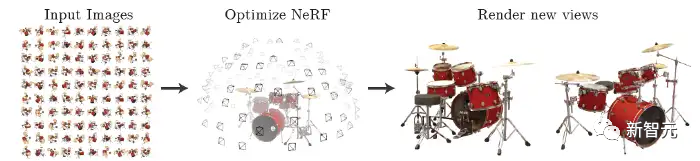
NeRF trains a neural radiance field model using sparse multi-angle posed images as input, allowing rendering of clear photos from any viewpoint, as shown in the figure below. It can also be succinctly summarized as using an MLP to implicitly learn a three-dimensional scene.
Netizens naturally compare NeRF with the equally popular Deepfake.
A recent article published by MetaPhysics reviewed the evolution of NeRF, the challenges it faces, and its advantages, predicting that NeRF will eventually replace Deepfake.
Most of the attention-grabbing topics about deepfake technology refer to the two open-source software packages that became popular after deepfakes entered the public eye in 2017: DeepFaceLab (DFL) and FaceSwap.
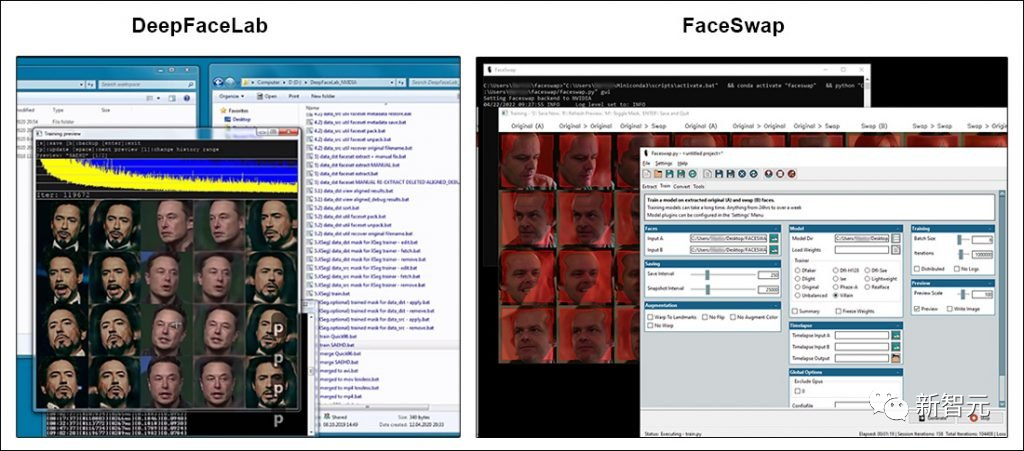
Although both software packages have a wide user base and active developer communities, neither project has deviated significantly from the GitHub code.
Of course, the developers of DFL and FaceSwap have not been idle: they can now use larger input images to train deepfake models, although this requires more expensive GPUs.
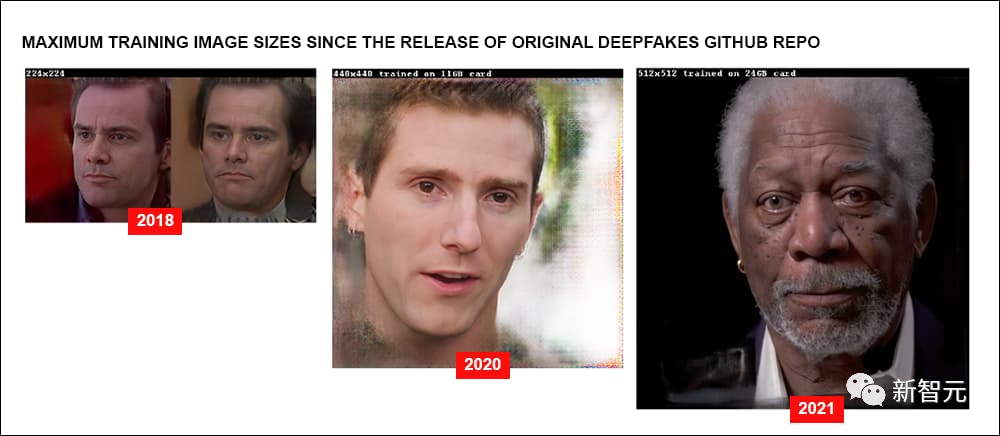
However, in the past three years, the improvement in deepfake image quality touted by the media is mainly attributed to end users.
They have accumulated ‘time-saving and rare’ experience in data collection, as well as the best practices for training models (sometimes a single experiment can take weeks), and learned how to utilize and extend the outer limits of the original 2017 code.
Some in the VFX and ML research community are attempting to break through the ‘hard limits’ of popular deepfake packages by expanding the architecture so that machine learning models can be trained on images up to 1024×1024.

The pixel resolution is twice that of the current practical range of DeepFaceLab or FaceSwap, closer to useful resolutions in film and television production.
Next, let’s learn more about NeRF~
Unveiling the mystery
NeRF (Neural Radiance Fields), which emerged in 2020, is a method for reconstructing objects and environments by stitching together multiple viewpoint photos within a neural network.
It achieves the best results in synthesizing complex scene views by optimizing an underlying continuous volumetric scene function using a sparse set of input views.
The algorithm also uses a fully connected deep network to represent a scene, where the input is a single continuous 5D coordinate (spatial position (x, y, z) and viewing direction (θ, φ)), and the output is the volumetric density and the corresponding emission brightness at that spatial position.
By querying the 5D coordinates along the camera rays, it synthesizes views and uses classical volume rendering techniques to project the output colors and densities onto an image.
Implementation process:
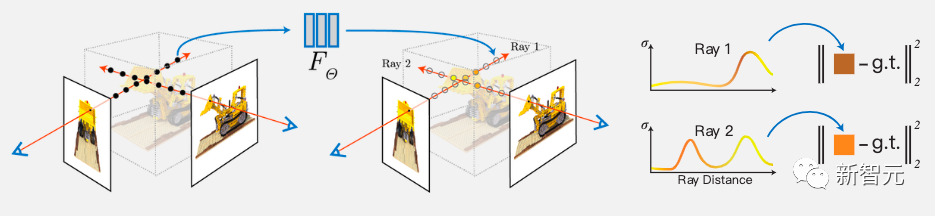
First, a continuous scene is represented as a 5D vector-valued function, where the input is a 3D position and a 2D viewing direction, and the corresponding output is an emitted color c and volumetric density σ.
In practice, a 3D Cartesian unit vector d is used to represent direction. An MLP network approximates this continuous 5D scene representation and optimizes its weights.
Additionally, by constraining the network to predict volumetric density σ as a function of position x, while allowing RGB color c to be predicted as a function of position and viewing direction, it encourages multi-view consistency in representation.
To achieve this, the MLP first processes the input 3D coordinates x with 8 fully connected layers (using ReLU activation and 256 channels per layer) and outputs σ and a 256-dimensional feature vector.
This feature vector is then concatenated with the viewing direction of the camera ray and passed to an additional fully connected layer, outputting the view-dependent RGB color.
Moreover, NeRF introduces two improvements to represent high-resolution complex scenes. The first is positional encoding to help the MLP represent high-frequency functions, and the second is a hierarchical sampling process that enables efficient sampling of high-frequency representations.
As we know, positional encoding in Transformer architectures provides discrete positions of tokens in a sequence as input to the entire architecture. NeRF uses positional encoding to map continuous input coordinates into a higher-dimensional space, making it easier for the MLP to approximate higher-frequency functions.

From the figure, it can be observed that removing positional encoding significantly reduces the model’s ability to represent high-frequency geometry and textures, ultimately leading to an overly smooth appearance.
Since the rendering strategy of densely evaluating the neural radiance field network at N query points along each camera ray is quite inefficient, NeRF finally adopts a hierarchical representation that improves rendering efficiency by allocating samples based on the expected effect of the final rendering.
In short, NeRF no longer uses a single network to represent a scene but optimizes two networks simultaneously, a ‘coarse’ network and a ‘fine’ network.
A promising future
NeRF addresses past shortcomings by using MLP to represent objects and scenes as continuous functions. Compared to previous methods, NeRF can produce better rendering results.
However, NeRF also faces many technical bottlenecks, such as NeRF accelerators sacrificing other relatively useful features (like flexibility) to achieve low latency, more interactive environments, and reduced training time.
Thus, while NeRF is a key breakthrough, achieving perfect results will still take some time.
Technology is advancing, and the future remains promising!
References:
https://metaphysic.ai/nerf-successor-deepfakes/
https://arxiv.org/pdf/2003.08934.pdf
