

Source: DeepHub IMBA
This article is about 1000 words long and is recommended for a 5-minute read.
After reading this article, you will also be able to create a DeepFake video.
-
First, thousands of facial photos of two individuals will be trained using an AI algorithm called an encoder. -
The encoder discovers and learns the similarities between the two faces and simplifies them into shared common features while compressing the images in the process. -
Then, the second AI algorithm called a decoder is taught to recover the faces from the compressed images. -
Since the faces are different, you train one decoder to recover the face of the first person and another decoder to recover the face of the second person. -
To perform the face swap, you simply input the encoded image into the “wrong” decoder. -
For example, inputting the compressed image of person A into the decoder trained on person B. -
The decoder then reconstructs person B’s face with the expressions and orientation of person A. This must be done for every frame to create a convincing video.
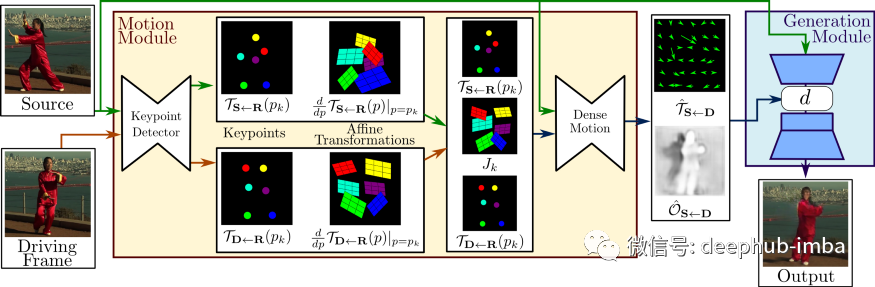
-
Extract motion and facial expressions from the original video and target photo using a facial keypoint detector. -
Match the facial keypoints between the video and photo. -
For each frame in the video, transform each target photo. -
Pass these frames to another model (Dense Motion) to extract the motion and lighting of the source photo. -
In other words, the Dense Motion model generates optical flow and occlusion maps.
https://arxiv.org/abs/2003.00196
https://github.com/AliaksandrSiarohin/first-order-model
https://colab.research.google.com/github/AliaksandrSiarohin/first-order-model/blob/master/demo.ipynb
Editor: Wenjing
