Source: Fresh Dates Classroom
Original Author: Little Date Jun
This article provides a simple and accessible introduction to what large models are, how they are trained, and their applications.
Large models, known in English as Large Model, were also referred to as Foundation Model in the early days.
Large model is an abbreviation, and the full term should be “Artificial Intelligence Pre-trained Large Model.” Pre-training is a technique that we will explain later.
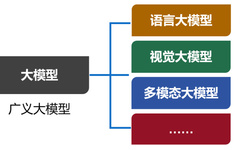
The large models we commonly refer to actually specifically refer to one type of large model, which is the most widely used—Large Language Model (LLM).
In addition to large language models, there are also visual large models, multimodal large models, etc. Currently, the collection of all types of large models is referred to as generalized large models, while language large models are referred to as narrow large models.
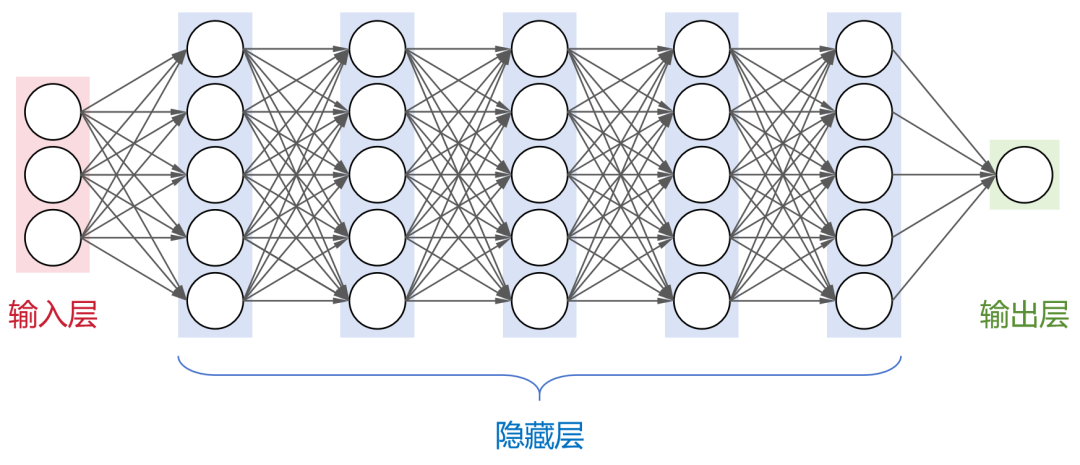
Essentially, a large model is a neural network model that contains an extremely large number of parameters (usually over a billion).
Neural networks are currently the most fundamental computational model in the field of artificial intelligence. They learn from input data and generate useful outputs by simulating the connections between neurons in the brain.
This is a fully connected neural network (where every neuron in one layer is connected to all neurons in the next layer), consisting of one input layer, N hidden layers, and one output layer.
The well-known Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), Long Short-Term Memory Network (LSTM), and transformer architecture all belong to neural network models.
Currently, most large models in the industry use the transformer architecture.
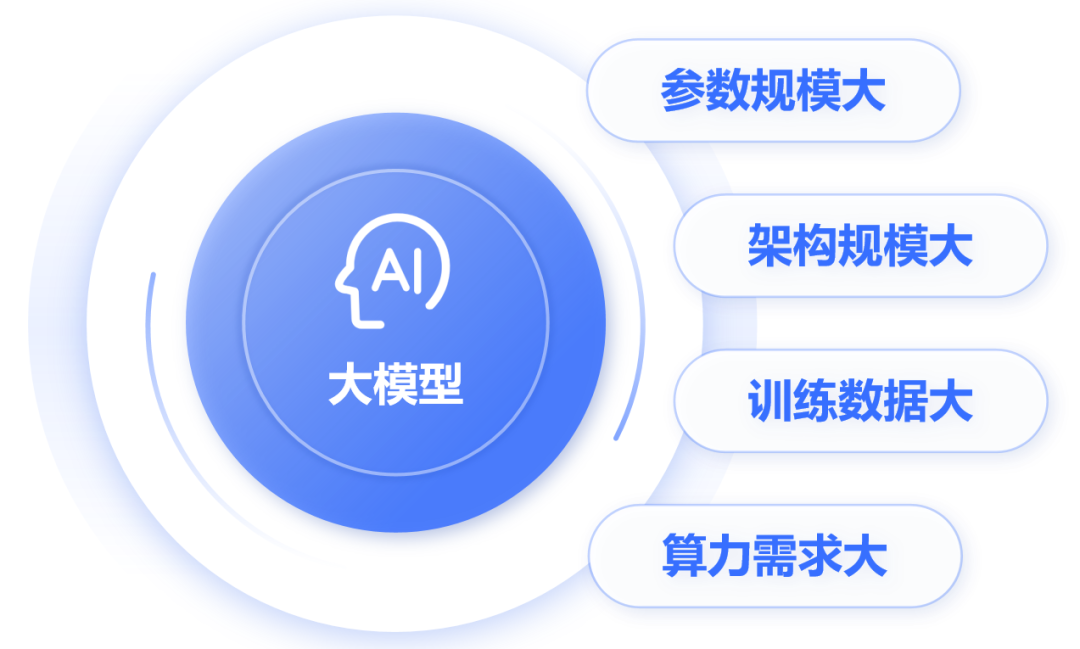
As mentioned earlier, large models contain extremely large parameters. In fact, the “large” in large models refers not only to the parameter scale but also to the architecture scale, training data size, and computational power requirements.
For example, GPT-3 has a total of 96 hidden layers, with 2048 neurons in each layer.
The number of parameters in a large model is related to the number of neuron nodes. Simply put, the more neuron nodes there are, the more parameters there will be. For instance, GPT-3 has approximately 175 billion parameters.
The training data for large models is also enormous.
Taking GPT-3 as an example, it was trained using 45TB of text data. Even after cleaning, there are still 570GB. Specifically, it includes the CC dataset (400 billion words) + WebText2 (19 billion words) + BookCorpus (67 billion words) + Wikipedia (3 billion words), which is undoubtedly massive.
Lastly, there is the computational power requirement.
This is something everyone has probably heard of; training large models requires a lot of GPU computational resources. Moreover, each training session takes a long time.
According to public data, training GPT-3 requires approximately 3640 PFLOP·days (PetaFLOP·Days). If using 512 A100 GPUs (with a single card computational power of 195 TFLOPS), it would take about a month. During training, interruptions may occur, resulting in longer actual training time.
In summary, a large model is a virtual giant, complex in architecture, massive in parameters, reliant on vast amounts of data, and very costly.
In contrast, models with fewer parameters (under a million) and shallower layers are called small models. Small models have advantages such as being lightweight, efficient, and easy to deploy, making them suitable for vertical domain scenarios with smaller data volumes and limited computational resources.
How Are Large Models Trained?
Next, let’s understand the training process of large models.
As everyone knows, large models can learn from massive amounts of data, absorbing the “knowledge” contained within. They can then apply this knowledge, such as answering questions and generating content.
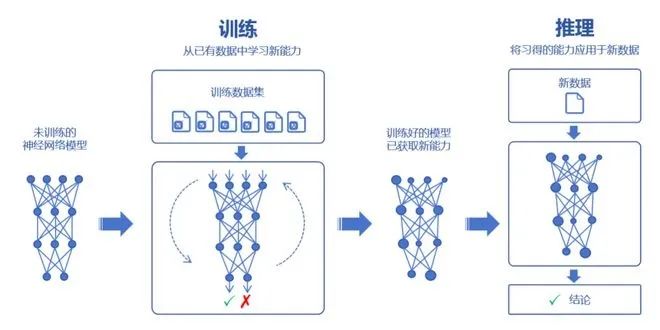
The learning process is called training, while the application process is referred to as inference.
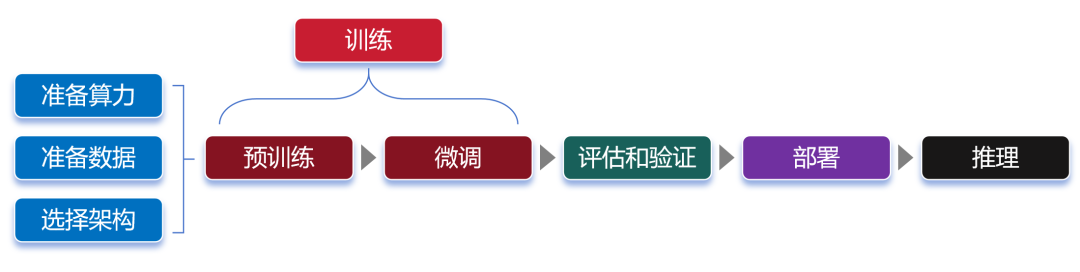
Training is divided into two stages: pre-training and fine-tuning.
During pre-training, we first need to select a large model framework, such as transformer. Then, by “feeding” the aforementioned massive data, the large model learns general feature representations.
So, why can large models possess such strong learning capabilities? Why is it said that the more parameters, the stronger the learning ability?
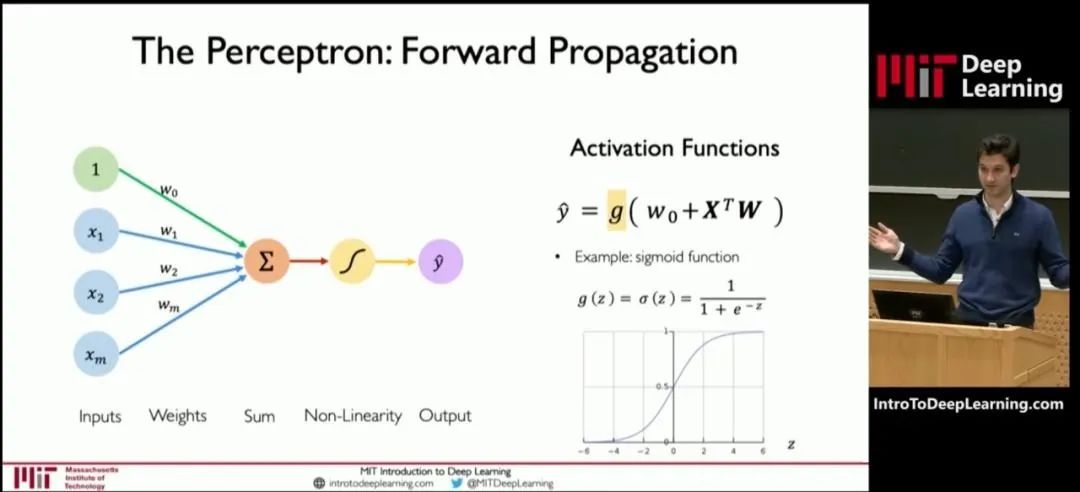
We can refer to a diagram from an MIT open course:
This diagram shows the structure of a neuron in a deep learning model.
The processing of a neuron is essentially a function calculation process. In the formula, x is the input, and y is the output. Pre-training is about solving W through x and y. W is the “weights” in the formula.
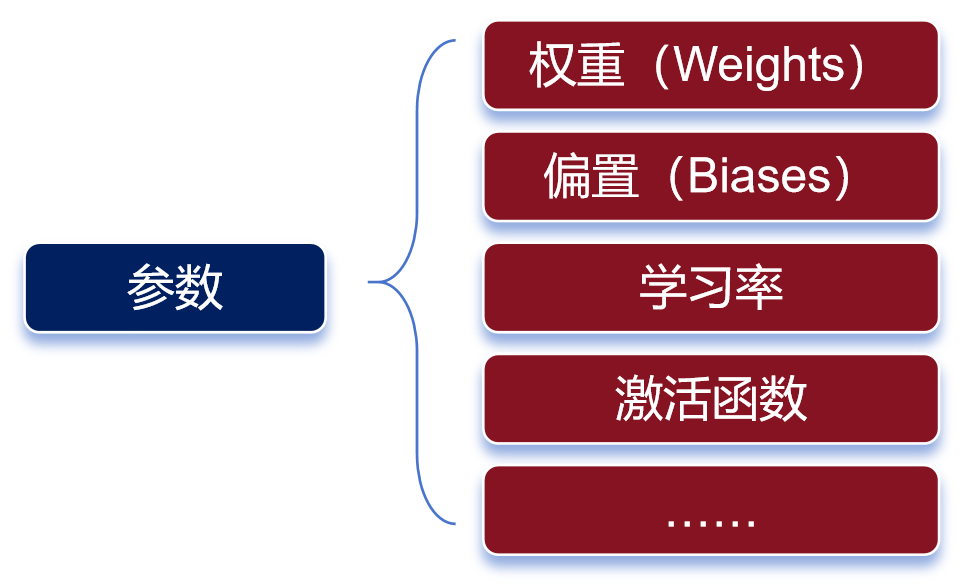
Weights determine the extent to which input features influence the model’s output. The purpose of repeated training is to obtain the weights, which is the significance of training.
Weights are one of the main categories of parameters. In addition to weights, another important category of parameters is biases.
There are many types of parameters
Weights determine the influence of input signals on neurons, while biases can be understood as the “tolerance” of neurons, indicating their sensitivity to input signals.
In simple terms, the pre-training process is about repeatedly “calculating” the most reasonable weights and biases (i.e., parameters) through input and output data. Once training is completed, these parameters are saved for subsequent use or deployment of the model.
The more parameters there are, the more complex patterns and features the model can typically learn, resulting in stronger performance across various tasks.
We often say that large models have two characteristic abilities—emergent ability and generalization ability.
As the training data and parameters of the model continue to expand, reaching a certain critical scale will result in the emergence of some unpredictable and more complex abilities and characteristics. The model can automatically learn and discover new, higher-level features and patterns from the original training data. This ability is referred to as “emergent ability.”
“Emergent ability” can be understood as the large model suddenly “waking up,” no longer merely reciting knowledge but being able to understand it and think divergently.
Generalization ability refers to the large model’s capability to learn complex patterns and features from massive data and make accurate predictions on unseen data.
While increasing the parameter scale makes the large model stronger, it also leads to greater resource consumption and may increase the risk of “overfitting.”
Overfitting refers to the model learning the training data too precisely, to the extent that it starts capturing and reflecting the noise and details in the training data rather than the overall trends or patterns. In simple terms, the large model becomes a “bookworm” that can only memorize without integrating knowledge.
We also need to clarify the data used for pre-training.
The data used for pre-training is a massive amount of unlabeled data (tens of TB).
The reason for using unlabeled data is that there is a vast amount of such data available on the internet, making it easy to obtain. In contrast, labeled data (which relies on manual annotation) consumes a lot of time and money, making it too costly.
Pre-trained models can learn general features and representations from unlabeled data through unsupervised learning methods (such as autoencoders, generative adversarial networks, masked language modeling, contrastive learning, etc., which you can learn about separately).
Moreover, the data is not randomly downloaded from the internet. The entire dataset needs to go through processes of collection, cleaning, anonymization, and classification. This helps remove outliers and erroneous data, as well as delete private information, making the data more standardized and beneficial for the subsequent training process.
Methods for acquiring data are also diverse.
For individuals and academic research, data can be obtained from official forums, open-source databases, or research institutions. For enterprises, they can either collect and process data themselves or purchase it directly from external channels (there are specialized data providers in the market).
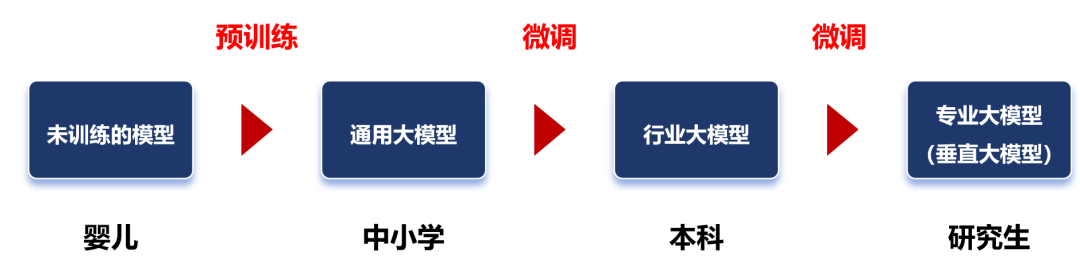
After pre-training, we obtain a general large model. This model usually cannot be used directly, as it often performs poorly on specific tasks.
At this point, we need to fine-tune the model.
Fine-tuning involves providing the large model with a labeled dataset specific to a certain domain, making minor adjustments to the pre-trained model parameters to enable the model to better perform specific tasks.
After fine-tuning, the large model can be referred to as an industry large model. For example, fine-tuning based on a financial securities dataset can yield a financial securities large model.
If further fine-tuning is done in more specialized fields, it becomes a specialized large model (also known as a vertical large model).
We can think of the general large model as a middle school student, the industry large model as an undergraduate, and the specialized large model as a graduate student.
During the fine-tuning phase, since the data volume is much smaller than in the pre-training phase, the computational power requirements are significantly lower.
It’s important to note that for most large model vendors, they typically only conduct pre-training and not fine-tuning. On the other hand, industry clients usually only perform fine-tuning and not pre-training.
The “pre-training + fine-tuning” phased approach to large model training can avoid redundant investments, save a significant amount of computational resources, and significantly improve the training efficiency and effectiveness of large models.
Once both pre-training and fine-tuning are complete, the large model needs to be evaluated. By using actual data or simulated scenarios, the large model is assessed to verify its performance, stability, and accuracy to ensure they meet design requirements.
Once the evaluation and verification are completed, the large model is considered successfully created. Next, we can deploy this large model for inference tasks.
In other words, at this point, the large model has been “shaped,” and its parameters no longer change, allowing it to truly start working.
The inference process of the large model is the process of using it. By asking questions or providing prompts, we can have the large model answer our questions or generate content as required.
Finally, here is a complete flowchart:
What Are the Functions of Large Models?
Based on the types of training data and application directions, we typically classify large models into language large models (trained with text data), audio large models (trained with audio data), visual large models (trained with image data), and multimodal large models (which include both text and images).
Language large models excel in natural language processing (NLP) and can understand, generate, and process human language. They are commonly used in text content creation (generating articles, poetry, code), literature analysis, summarization, machine translation, and other scenarios. The well-known ChatGPT belongs to this type of model.
Audio large models can recognize and produce speech content, commonly used in voice assistants, voice customer service, and smart home voice control.
Visual large models excel in computer vision (CV) and can recognize, generate, or even repair images, commonly used in security monitoring, autonomous driving, medicine, and astronomical image analysis.
Multimodal large models combine the capabilities of NLP and CV by integrating and processing information from different modalities (text, images, audio, and video), enabling them to handle cross-domain tasks, such as generating images from text, generating videos from text, and cross-media searches (searching for text descriptions related to an uploaded image).
This year, the rise of multimodal large models has been very evident and has become a focal point of industry attention.
If classified by application scenarios, there are even more categories, such as financial large models, medical large models, legal large models, educational large models, code large models, energy large models, government large models, communication large models, and so on.
For example, financial large models can be used for risk management, credit assessment, transaction monitoring, market prediction, contract review, customer service, etc. There are many functions and roles, which will not be elaborated further.
END
Reprinted content only represents the author’s views
It does not represent the position of the Institute of Semiconductors, Chinese Academy of Sciences
Editor: Yuzu Lu
Responsible Editor: Mu Xin
Submission Email: [email protected]
1.Exploring Photolithography: The Core Tool of Chip Manufacturing
2.Confocal Sensor Distance Measurement
3.High-K Metal Gate (HKMG)
5.Finding the Cause of Information Loss in Superconducting Qubits
6.3D-NAND Floating Gate Transistor Structure