
Kleisi from Aofeisi Quantum Bit | WeChat Official Account QbitAI
With OpenAI’s GPT-4o and Google’s series of powerful models, advanced multimodal large models have been making waves.
Other practitioners, while shocked, have once again begun to ponder how to catch up with these super models.
At this time, a paper by HuggingFace and Sorbonne University in France summarizes the key experiences in building visual large models, pointing developers in a direction.

These experiences cover multiple aspects such as model architecture selection, training methods, and training data. After extensive comparisons, the authors provided a detailed summary, with the core points including:
-
Choosing the right architecture is crucial for building a successful visual large model.
-
The impact of the language model on overall performance is greater than that of the visual module.
-
Using a staged pre-training strategy is more beneficial for building model capabilities.
-
Training data should include various types and pay attention to the balance between them.
It can be said that HuggingFace’s ability to create SOTA visual models of the same scale, Idefics2, relies on these experiences.
Idefics2 is built on Mistral-7B and has a total of 8 billion parameters, capable of accurately recognizing handwritten fonts.

Professionals have stated that this is a very good survey report that is helpful for visual model developers, but they also remind us not to treat it as a one-size-fits-all solution.

Of course, some jokingly say that architecture and data are all clouds; having a GPU is the most critical factor.

There is some truth to that, but jokes aside, let’s take a look at what experiences HuggingFace has provided us.
Insights from SOTA Model Development Practice
The experiences in HuggingFace’s paper come from the development process of the visual model Idefics2.
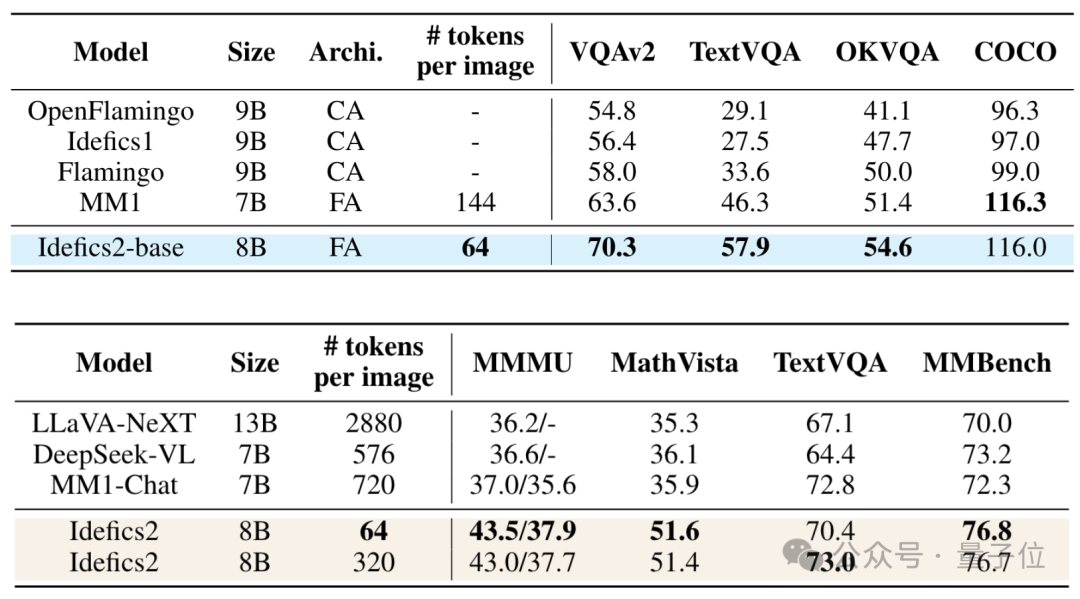
Compared to the previous generation Idefics1 and Flamingo, which are of similar scale, Idefics2 performs excellently on multiple datasets, even surpassing larger 13B models.
At the same time, compared to MM1, which slightly outperforms Idefics2 on the COCO dataset, Idefics2 significantly reduces the number of tokens consumed per image.
From the development practice of Idefics2, HuggingFace brings us experiences that include at least the following aspects:
-
Selection of backbone and architecture
-
Training methods and strategies
-
Diversity of data and processing strategies
The Impact of Language Models on Overall Performance is Greater
Current visual large models mainly adopt a combination of language models and visual encoders for development. The authors evaluated the impact of both on overall performance.
The results show that the quality of the language model is more important than that of the visual model.
With the same parameter count, using a better language model (for example, replacing Llama-7B with Mistral-7B) can significantly enhance the performance of visual large models on downstream tasks.
In contrast, the improvement brought by upgrading the visual encoder is relatively limited; therefore, when trade-offs are necessary, the best practice is to prioritize the stronger language model.

This does not mean that upgrading the visual encoder is ineffective; under suitable conditions, choosing a better visual encoder can also bring performance improvements.
Additionally, it is crucial to select encoders that match the downstream tasks. For instance, for text recognition tasks, a visual encoder that supports variable resolution should be used; if the task requires high inference speed, a lighter model can be selected.
In practical applications, inference speed and memory usage are also factors to consider. The SigLIP-SO400M used in Idefics2 strikes a good balance between performance and efficiency.
Choosing Architecture Types Based on Needs
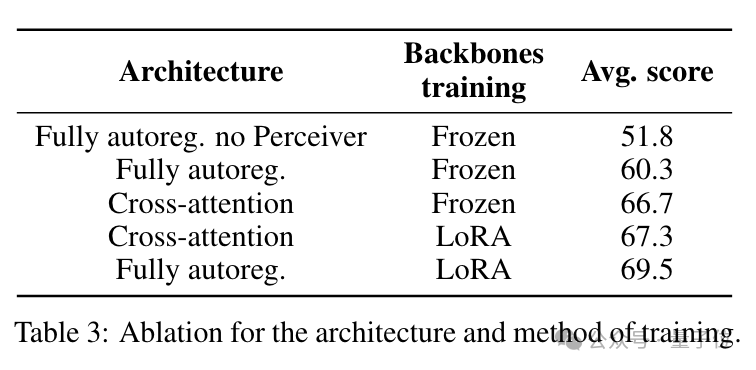
Regarding architecture selection, this paper discusses two common types: fully autoregressive and cross-attention.
The fully autoregressive architecture generates each output in an autoregressive manner, considering the dependencies of the entire sequence; the latter allows the model to dynamically attend to different parts of another modality while processing one modality, achieving more flexible inter-modal interaction.
In practical work, the authors found that which architecture performs better depends on whether the pre-trained backbone is frozen.
(In simple terms, if the pre-trained backbone participates in the formal training process, it is considered non-frozen; if it does not, it is frozen.)
If not frozen, the fully autoregressive architecture performs better; conversely, if frozen, the cross-attention architecture is superior.
Whether to freeze the backbone depends on the developer’s focus and requirements.
In resource-constrained conditions, if high performance and sensitivity to latency are needed, freezing is more appropriate; if higher flexibility and adaptability of the model are desired, a non-frozen training method should be chosen.
For Idefics2, a non-frozen backbone was selected, thus adopting a fully autoregressive architecture.
Training Phase Experiences
Choosing the right architecture is undoubtedly important, but the training process is equally essential. During the training of Idefics2, the authors summarized these experiences for our reference:
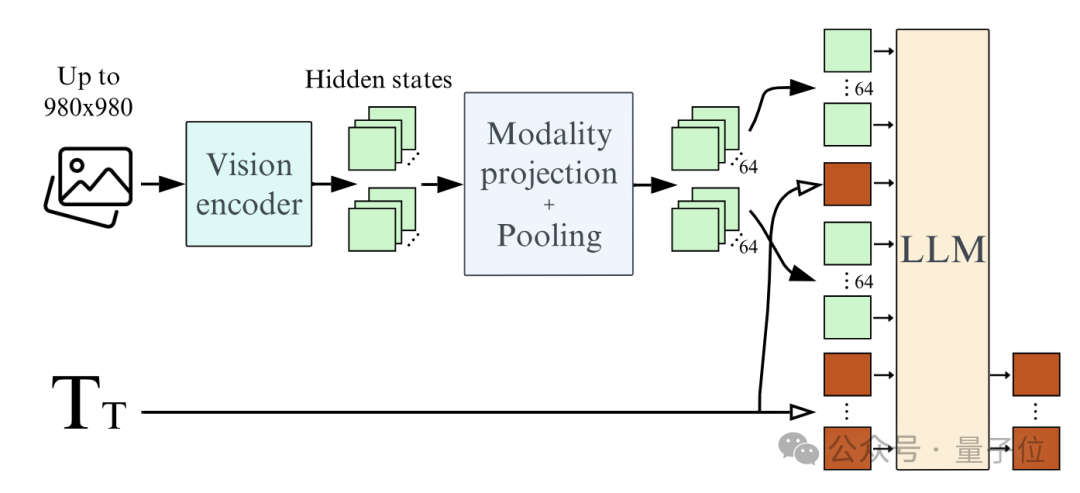
First, an overall staged pre-training strategy is adopted, initially using images of lower resolution, and then introducing higher resolution PDF documents. This approach can gradually build various capabilities of the model.
Second, using Learned Pooling instead of directly feeding image features into the language model can greatly reduce the number of image tokens, significantly enhancing training and inference efficiency, while also improving performance.
Third, data augmentation is employed, where images are split into multiple sub-images during training, allowing for stronger performance at inference by trading off computation time. This is particularly effective for tasks like text recognition, though not all images need to be processed this way.
Fourth, using more diverse data and tasks during instruction fine-tuning can enhance the model’s generalization and robustness.
Additionally, to stabilize training, when the pre-trained unimodal backbone is involved in training (non-frozen), the authors used LoRA technology to adapt the pre-trained parameters.
Diversity of Data and Processing Strategies
Besides the training process itself, the choice of data also significantly affects the model’s performance.
From the collection stage, it is important to select various types of data. For instance, Idefics2 utilized three types of data—document-image alignment (like web pages), image-text pairs (like image captions), and OCR-labeled PDF documents.
The proportions of various data types should also be balanced according to actual needs, rather than simply dividing them equally.
As for the scale of data, it should be as large as possible, provided that low-quality data is filtered out.
Of course, collection is just one step in obtaining training data; to train the model well, some processing is also necessary.
Different preprocessing and augmentation strategies should be applied to different types of data. For example, using higher resolution images for OCR data is necessary, while other data can use lower resolutions.
It is important to note that when processing images, the original aspect ratio and resolution should be preserved, which can significantly save computational costs for training and inference while enhancing model adaptability.
If you find these experiences enlightening, you can read the original paper for more details, and we welcome you to share your development experiences in the comments section.
Paper link:https://arxiv.org/abs/2405.02246
— The End —
Quantum Bit’s Annual AI Theme Planning is currently open for submissions!
We welcome submissions for the special topic One Thousand and One AI Applications, 365 AI Implementation Solutions
or share with us the AI products you are looking for, or the new trends in AI you have discovered.

Click here👇 to follow me, and remember to bookmark it!~
One-click “Share”, “Like”, and “View”
Stay updated on cutting-edge technology every day ~
