
Today I will share the complete implementation of local inference deployment for multimodal models. To facilitate everyone’s understanding of the entire process, I have organized the steps and provided detailed results. Friends who are interested should try it out quickly.
1. Introduction to DeepSeek-R1 andllama3.2-vision Models
DeepSeek R1 is an open-source inference-optimized large language model series launched by the Chinese AI company DeepSeek, whose core technological breakthroughs and open-source strategy have attracted widespread attention in the AI field. The architecture and core technologies of the DeepSeek R1 model include: 1. **Mixture of Experts (MoE)** architecture. The R1 series is based on a **671 billion parameter** MoE architecture, composed of multiple sub-networks, each optimized for specific tasks. During inference, only about **10% of the parameters** are activated, significantly reducing computational costs. It supports decoupled design for multimodal tasks, such as improving efficiency in visual tasks by combining **SigLIP-L** feature extraction with VQ token generation. 2. **Pure Reinforcement Learning Driven**. The R1-Zero version relies entirely on **Reinforcement Learning (RL)** training, without the need for **Supervised Fine-Tuning (SFT)**, achieving self-evolution through the **GRPO algorithm (Group Relative Policy Optimization)**, and possesses the ability to generate long inference chains, self-validation, and reflection. R1 introduces a small amount of cold-start data and a multi-stage training process (including two RL stages and two SFT stages) on the basis of R1-Zero, addressing the repetition issues and language mixing defects of R1-Zero, significantly improving output quality. 3. **Distillation Technology**. By distilling the inference capabilities of R1 into smaller dense models (such as Qwen and Llama series), the generated models with **1.5B to 70B parameters** outperform OpenAI’s o1-mini. DeepSeek R1, with its efficient inference capabilities driven by reinforcement learning, cost advantages of the mixture of experts architecture, and inclusive nature of the open-source ecosystem, has become an important milestone in domestic large model technology. Its performance is on par with the world’s top models, while accelerating the penetration of AI technology from the cloud to the edge through low-cost and lightweight strategies, providing feasible solutions for education, finance, industry, and other fields. The DeepSeek R1 model has multiple versions of parameters, and different model parameters also have different hardware requirements. For beginners, personal developers can start with the **7B-Q4 quantized version** (6.8GB of VRAM) to balance performance and resource consumption. For higher precision, choose the **14B-Q5 quantized version** (10.2GB of VRAM), suitable for code generation and mathematical reasoning. For enterprise-level deployment: **32B/70B models**: paired with the **vLLM framework** and **Flash Attention technology**, enhancing inference speed (e.g., the 70B quantized version can reach **500-1500 tokens/s**). Cloud service integration: Tencent Cloud, Alibaba Cloud, etc., provide pre-configured images supporting one-click deployment and elastic scaling.
Llama 3.2-Vision is an open-source multimodal large language model (MLLM) launched by Meta, combining text and visual understanding capabilities, supporting dual-modal input of images and text, and is the first model in the Llama series to integrate visual functions. Built on a pre-trained pure text model (Llama 3.1 8B/70B), it extracts image features through a **Vision Transformer (ViT-H/14)**, and aligns with the text model through cross-attention layers to achieve joint reasoning of text and images. It offers two versions: **11B (11 billion)** and **90B (90 billion)**, aimed at consumer-grade GPUs and enterprise applications, respectively. The 11B model requires at least **8GB of VRAM** (non-quantized) or **6GB** (4-bit quantized), recommended for **NVIDIA RTX 4090** or **A100**. The 90B model requires over **64GB of VRAM**, typically needing multi-card parallelism (e.g., H100 clusters).
2. Local Inference Deployment for Multimodal Models
1. Download the Ollama tool
Ollama is an open-source local model running tool that allows easy downloading and running of various open-source large models, such as Llama, Qwen, DeepSeek, Gemma, etc. More models can be found here: https://ollama.com/search. Ollama provides efficient and flexible solutions for large model deployment and management, simplifying the deployment process. It supports macOS, Linux, and Windows operating systems, with the installation address: https://github.com/ollama/ollama. Here, I will choose to download the Windows version.
2. Install Ollama and download the DeepSeek-R1 model and llama3.2-vision model.
The test computer hardware configuration is **i5 + 8 cores**, **64GB of memory**, and a single **3090 graphics card**, so I can choose the **deepseek-r1:14b model** and **llama3.2-vision:11b model**. Use Ollama to pull the deepseek-r1:14b and llama3.2-vision:11b large model files.
ollama pull deepseek-r1:14b
ollama pull llama3.2-vision:11b3. Install the Ollama Python package.
pip install ollama4. Multimodal Medical Dialogue Program.
from ollama import chat
from ollama import ChatResponse
def Chat_Response_llama_vision_inference(path, inputcontent=''):
response_en: ChatResponse = chat(
model='deepseek-r1:14b',
messages=[
{
'role': 'user',
'content': inputcontent + ", translate the above Chinese into English prompts",
},
])
inputcontent_en = response_en['message']['content']
# print(inputcontent_en)
# Pass in the path to the image
# You can also pass in base64 encoded image data
# img = base64.b64encode(Path(path).read_bytes()).decode()
# or the raw bytes
# img = Path(path).read_bytes()
response_descrip: ChatResponse = chat(
model='llama3.2-vision:11b',
messages=[
{
'role': 'user',
'content': inputcontent_en,
'images': [path],
}
],
)
response_descrip_en = response_descrip['message']['content']
# print(response_descrip_en)
response_cn: ChatResponse = chat(
model='deepseek-r1:14b',
messages=[
{
'role': 'user',
'content': response_descrip_en + ", translate the above English into Chinese.",
},
])
return response_cn['message']['content']
if __name__ == '__main__':
response_image_text = Chat_Response_llama_vision_inference(path='Image.png',
inputcontent='Please describe what is in this image?')
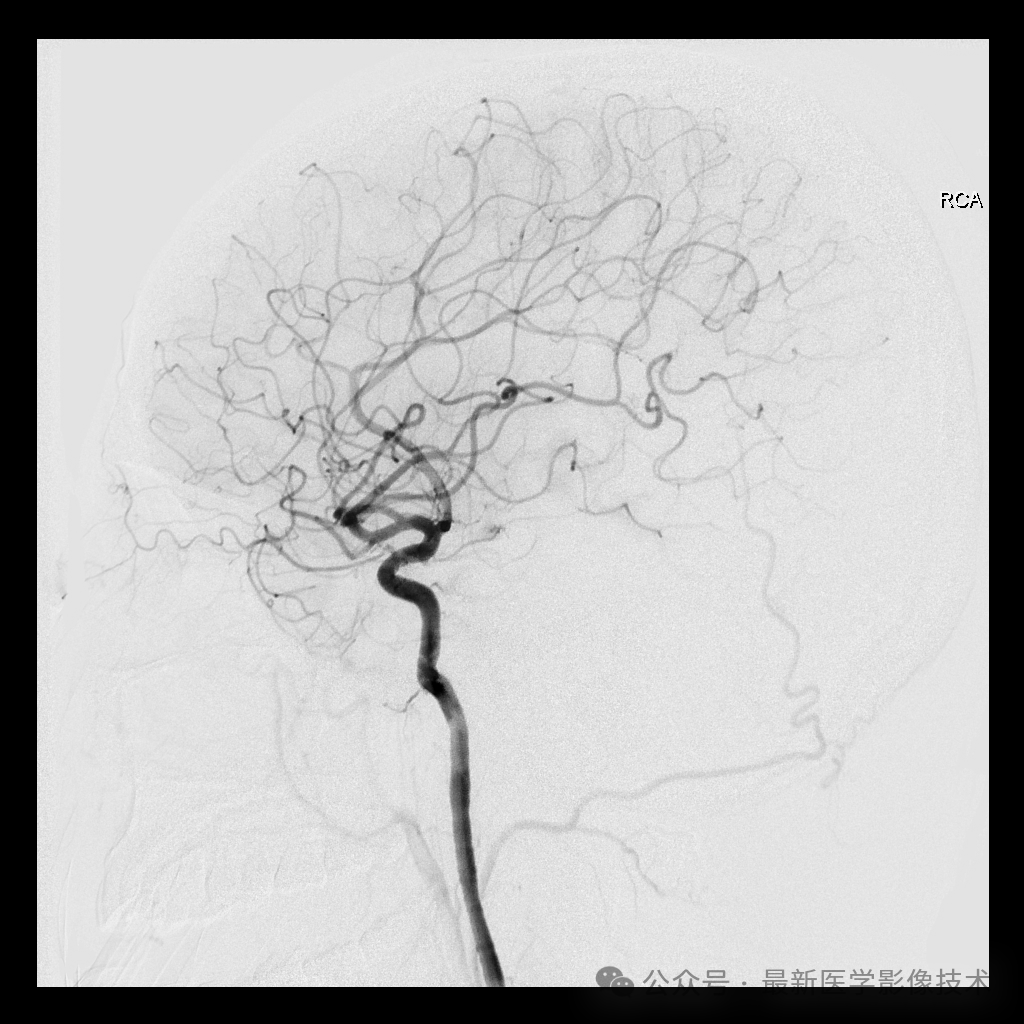
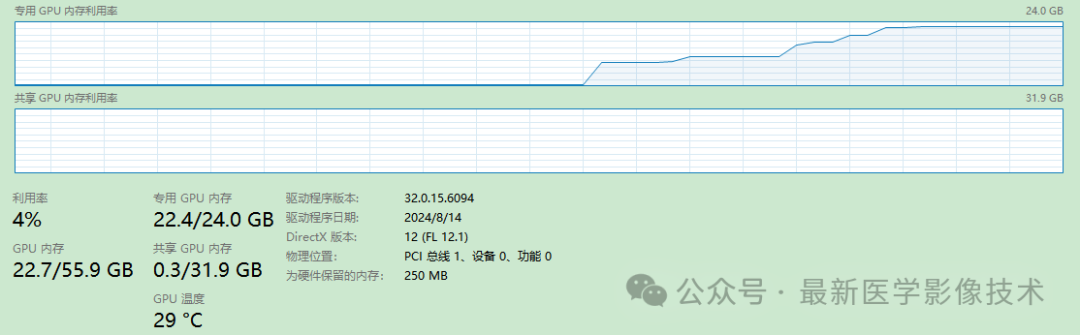
print(response_image_text)The input image is a DSA head angiography image, as shown below. The input prompt is “Please describe what is in this image?” It can be seen that the VRAM usage is already saturated during inference. After running, it can be seen that the given response is quite accurate.
C:\Anaconda3\python.exe D:/cjq/project/python/Ollama_example/ollama_example_chat_mutilmodel.py<think>Okay, now I need to translate the English content provided by the user about cerebral angiography into Chinese. First, I will read the original text to ensure I understand each part's meaning.
The first paragraph talks about the basic information of cerebral angiography, which is an X-ray examination using contrast agents to show the blood vessels in the brain. It mentions specific arteries and veins, as well as the Circle of Willis. I need to accurately translate these professional terms, such as "cerebral angiogram" should be "脑血管造影", and "contrast dye" is "对比染料".
Next, the second paragraph explains the uses of this image, including diagnosing diseases such as strokes and aneurysms. I need to ensure the accuracy of these medical terms while keeping the sentences smooth and natural.
During the translation process, I need to balance professionalism and comprehensibility, for example, "arteriovenous malformation (AVM)" can be translated as "动静脉畸形", while keeping the abbreviation in English may be more appropriate since many professionals are familiar with this abbreviation.
Also, pay attention to adjusting sentence structures. In English, some long sentences may need to be split or reorganized in Chinese to fit Chinese expression habits. For instance, compound sentences can be divided into several short sentences to make it easier for readers to understand.
Finally, check whether the entire translation accurately conveys the original message while ensuring no key points are omitted. Also, proofread for grammar and wording to avoid errors that affect professionalism.
Overall, this translation needs to consider the accuracy of professional terms and the fluency of the language, ensuring that the Chinese translation is both faithful to the original meaning and easy for the target audience to understand.</think>
This image shows a cerebral angiogram, which is an X-ray examination using contrast dye to visualize the blood supply in the brain. The image displays the arteries and veins of the brain, including the **internal carotid artery**, **middle cerebral artery**, **anterior cerebral artery**, **posterior cerebral artery**, and **vertebral artery**. Additionally, the Circle of Willis, a network of vessels at the base of the brain responsible for supplying oxygen-rich blood to the cerebral hemispheres, can also be seen.
This image is likely used for diagnostic purposes to identify any blockages or abnormalities in the blood vessels of the brain. It may be used to diagnose conditions such as strokes, aneurysms, arteriovenous malformations (AVM), and cerebral vasculitis.Clicking to read the original text can access the Ollama project. If you think this project is good, I hope you give it a star and fork it, so that more people can learn. If you have any questions, feel free to leave me a message, and I will reply promptly.