
Introduction
Text similarity is a fundamental task in the industrialization of NLP. Many applications require calculating the degree of similarity between two texts, including deduplication of similar texts in text retrieval, matching queries with standard template questions in question-answering systems, and semantic judgment of sentence pairs.
This task can be categorized based on different criteria: for example, based on text length, it can be divided into short text similarity (phrase/sentence level) and long text similarity (paragraph/article level); or based on the method of feature engineering, it can be divided into those based on statistical feature generation (TF/TF-IDF/Simhash) and those based on semantic feature models (word2vec, doc2vec). Similarly, there are various methods for calculating similarity, such as minimum edit distance, Euclidean distance, Hamming distance, and cosine distance. This article will introduce the actual development process of a similarity task using news data.
Statistical Features + Hamming Distance
“Detecting Near-Duplicates for Web Crawling”
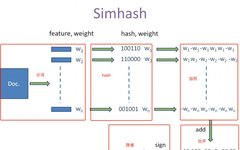
Simhash is a locality-sensitive hashing algorithm proposed by Charikar in 2002. Google utilized this algorithm in 2007 to identify similar content on web pages, demonstrating the practicality of Simhash for such problems. The core idea of Simhash is to use keywords selected from the text to represent an article through tokenization, then hash encode these keywords into a fixed-length binary sequence. After applying predetermined weights to the encoding of the keywords, they are simply merged and reduced to binary data. Finally, the Hamming distance is used to calculate the similarity between different articles. The mathematical derivation of Simhash is detailed in various blogs and will not be reiterated here. Regarding keyword selection and weight settings, the common approach is to calculate the TF-IDF values of each word in the article, select the top N contents as keywords, and use the TF-IDF values as weights.
The aforementioned method of combining statistical features with Hamming distance can reflect the similarity of articles to some extent, but there are still some issues in practical attempts.
The TF-IDF algorithm is based on the hypothesis that the most meaningful words for distinguishing documents are those that occur frequently in the document but infrequently in other documents in the entire collection. If the feature space coordinate system uses tf as a measure, it can reflect the characteristics of similar texts. The concept of inverse document frequency (idf) is introduced, using the product of tf and idf as the measure of the feature space coordinate system, adjusting the weight of tf to highlight important words while suppressing less important ones.
Theoretically, the most crucial step in Simhash is how to select representative keywords. The TF-IDF algorithm used in tokenization essentially attempts to suppress noise through weighting, assuming that words with low text frequency are more important while those with high frequency are less useful, which is evidently not entirely correct. The simple structure of idf does not effectively reflect the importance of words and the distribution of feature words, failing to adequately adjust the weights, hence the precision of the TF-IDF method is not very high.
From actual test results, in the field of medicine, certain keywords may have similar meanings, and some words representing the progress of medical projects or indicating negative semantics can greatly influence the similarity results of two articles. These factors cannot be explicitly considered and controlled in the Simhash algorithm.
Semantic Features + Cosine Distance
“Distributed Representations of Sentences and Documents”
In the initial attempts, it was mentioned that the Simhash algorithm based on TF-IDF cannot provide semantic information from articles or words. To utilize the semantic information in articles or words, word2vec naturally comes to mind. Word2vec is one of the fundamental text representation methods. If an article is embedded, then the word vectors can be averaged directly or weighted averaged using tf-idf to obtain a vector representation of the article. However, considering the analysis of the weighting capability of TF-IDF in Simhash, we still hope to obtain a more granular vector representation method.
The aforementioned article, inspired by word2vec, proposed doc2vec. This model can learn continuous vector representations for long texts and is applicable to different lengths of text data such as sentences, paragraphs, and articles. The specific approach involves proposing a module called the Distributed Memory Model of Paragraph Vectors (PV-DM), which stores feature vectors of different paragraphs, concatenating these vectors with other word vectors in the window and updating the model through gradient descent.
The advantage of doc2vec lies in its ability to train unsupervised on a large corpus, considering word meaning information and possessing local (window size) sequential information. Its disadvantage is that the text vector D’ also requires a backpropagation process. If not randomized and fixed, the text vectors generated each time may vary, affecting the calculation of text similarity. Additionally, from actual results, doc2vec, like word2vec, has an OOV issue, making it easy to produce identical text vectors for texts with different words but similar structures.
Semantic Features + Topic Information + Cosine Distance
“P-SIF: Document Embeddings Using Partition Averaging”
Combining the data content designed for specific tasks, we find that compared to traditional text content, news data expresses a clearly defined event, such as the progress of a certain product development by a pharmaceutical company or collaborations between different pharmaceutical companies. Therefore, incorporating topic information into vector representations can also influence the similarity of articles.
The aforementioned article suggests that using traditional weighted averaging of word vectors has good effects on representing the semantic information of sentences, but the same method does not perform well for article-level semantic representation. The main reason is that the text contains words representing different topics, and the weight factors of word vectors under different topics vary. Thus, the author proposes P-SIF, which generates different weight factors under different topics through topic clustering, concatenating the word vectors under each topic as the final vector representation of that word.

The figure illustrates the distribution of topic weights under five different text themes, showing that different topics have different weight distributions. The word vectors corresponding to a single topic are represented as the product of w2v, tf-idf, and the topic weight factor, with the final text representation being the weighted sum of all word vectors. The topic weight factor is obtained through ksvd decomposition, requiring the specification of the number of topics.
During actual testing, it was found that incorporating the topic variable allows for a more granular representation of the text, which is an improvement over the tf-idf-based w2v representation; however, the main drawbacks include OOV issues, difficulties in determining the number of topics, insufficient semantic representation capability, and particularly the challenge of balancing the key role of individual words in the text representation formed by the weighted sum of word vectors. For example, for two articles that are essentially identical but differ in a particular keyword, the similarity of the two articles may be relatively high. If this word was not included in the vocabulary during the training phase, it could result in a similarity score of 1. Therefore, it is necessary to employ subsequent keyword recognition strategies to differentiate between texts and address the issue of insufficient representation capability.
Semantic Features + Topic Information + Cosine Distance + Entity Information
If we delve deeper into the characteristics of news data, we must consider the key elements of standard news, which typically include five basic elements: Time, Location, Event, Cause, and People (or Organizations). Therefore, if we can extract these key factors from the lead or title of the news, we can more accurately determine the similarity between two news articles. Thus, in the actual development process, we attempted to enhance the “Semantic Features + Topic Information + Cosine Distance” approach by adding the extraction of general entity types.
The extraction of entity content plays a supportive role in this task. Therefore, this module has not been tightly integrated with the article’s embedding representation. For the NER extraction task, please refer to our previous discussion in “Chinese NER Insights – Discussing Vocabulary Enhancement and Entity Nesting”, which will not be elaborated on here.
Pre-trained Language Models for Obtaining Semantic Features
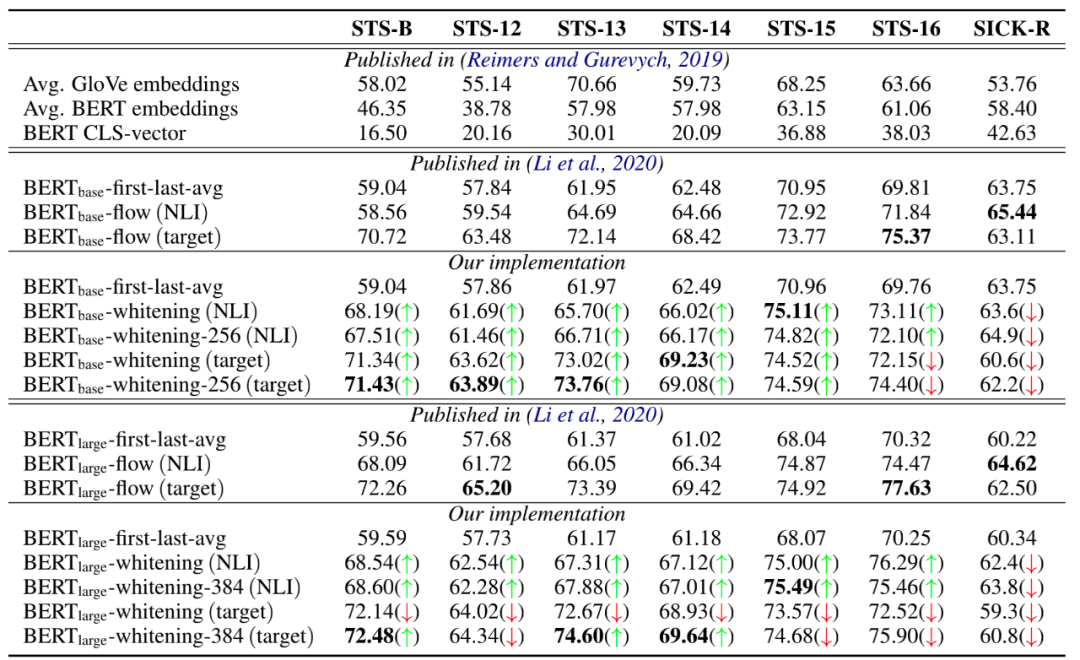
For tasks involving semantic similarity, it is challenging to obtain a large amount of labeled data for supervised training in industrial production. To enhance the model’s semantic representation capability, we can also turn our attention to large-scale pre-trained language models. Here, we only provide an idea to try using unsupervised semantic similarity methods like BERT-flow or BERT-whitening to obtain semantic features.
“On the Sentence Embeddings from Pre-trained Language Models”
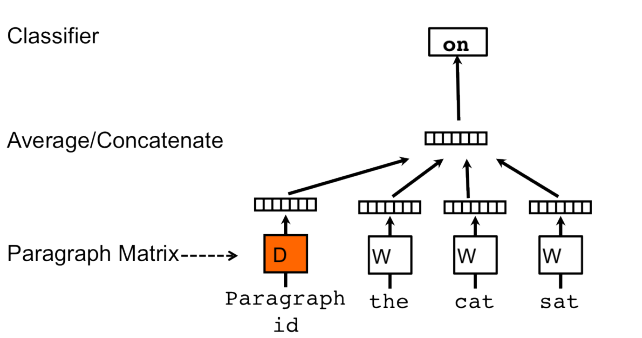
Considering that after obtaining the vector representation of sentences, cosine similarity is often used for comparison or ranking. However, cosine similarity is applied in a standard orthogonal basis. Therefore, if we want to use the sentence vectors obtained from BERT to measure the similarity between sentences, the basis of the vector space must be uniform and independent across all components, exhibiting an “isotropic” property. The flow model is essentially a vector transformation model, and the author’s main idea is to use the flow model to correct the distribution of the sentence vectors obtained from BERT.
“Whitening Sentence Representations for Better Semantics and Faster Retrieval”
BERT-whitening posits that the inverse transformation and Jacobian determinant calculations involved in the flow model need to meet the characteristics of being simple and easy to compute. Therefore, the non-linear transformation capability of each layer is “very weak”; to ensure sufficient fitting capability, the model must be very deep. However, the model used in BERT-flow has a considerable computational load. Hence, the author proposes a simple linear transformation (equivalent to whitening) to shallowly transform BERT’s vectors, achieving effects comparable to or even surpassing those of BERT-flow.

Conclusion
The representation of long news texts can be used for similarity calculation, text classification, text aggregation, and other directions. Currently, the author’s focus is on similarity deduplication, which involves discovering similar medical news from a vast number of news articles to enhance the efficiency of collecting and processing key data. Similar news includes two meanings: on one hand, character-level similarity can be directly compared using character-based methods like Simhash and edit distance, with challenges arising from articles having different lengths and slightly varying keywords. On the other hand, it involves the similarity of events covered in the news, where character similarity may not be high. This requires not only a certain level of semantic understanding but also the identification of key entities. The understanding of semantics based on large-scale trained language models is inherently superior to character-based and w2v-based methods, and the breakthroughs in complexity and effectiveness of pre-trained models for long texts will directly bring new directions for downstream processing of long texts.
References
[1] “Detecting Near-Duplicates for Web Crawling”
[2] “Distributed Representations of Sentences and Documents”
[3] “P-SIF: Document Embeddings Using Partition Averaging”
[4] “Delving Deep into Regularity: A Simple but Effective Method for Chinese Named Entity Recognition”
[5] “On the Sentence Embeddings from Pre-trained Language Models”
[6] “Whitening Sentence Representations for Better Semantics and Faster Retrieval”
To join the technical group, please add the AINLP assistant on WeChat (id: ainlp2)
Please specify the specific direction + related technology points
About AINLP
AINLP is an interesting AI natural language processing community, focusing on the sharing of technologies related to AI, NLP, machine learning, deep learning, recommendation algorithms, etc. Topics include text summarization, intelligent Q&A, chatbots, machine translation, automatic generation, knowledge graphs, pre-trained models, recommendation systems, computational advertising, recruitment information, and job experience sharing, etc. Welcome to follow! To join the technical group, please add the AINLP assistant on WeChat (id: ainlp2), specifying your work/research direction + group joining purpose.
If you have read this far, please share, like, or view 🙏