Source: FIN AI Exploration Big Data Digest
This article is approximately 2400 words long and is suggested to be read in 5 minutes.
In the short term, Agents mainly focus on improving efficiency.

In the domestic large language model field, applications are flourishing. Here are a few observations I have made recently:
-
Smaller parameter models may perform better on specific tasks.
Generally, larger model parameters yield better results, but in specific scenarios, it’s essential to test multiple models. Therefore, preparing a validation test set for domain-specific NLP issues is particularly important.
-
NLP modeling remains one of the important solutions.
Even as large models become increasingly powerful, constructing specific NLP models for real-time and higher accuracy scenarios, trained with specific data, remains an indispensable approach. Just like sentiment factors in quantitative investing, while large models can certainly handle them, for real-time and more accurate results, dedicated modeling is still necessary.
-
Are Agents the ultimate solution?
On January 5th, it was reported that OpenAI is about to launch the GPT Store for developers to customize Agents based on different uses of ChatGPT. Imagine that all industries will have Agents, and in the future, once Agents receive user authorization, they will seek out other Agents to solve problems. Given the long-chain issues, large models do not provide effective solutions. I believe that in the short term, Agents will primarily focus on improving efficiency.
Next is a discussion of the above viewpoints.
1. Even if large language models summarize human knowledge, they cannot independently solve domain-specific problems.
ChatGPT is constructing a summary of all human knowledge. Borges’s “Library of Babel” illustrates this with the author’s genius imagination, describing a library consisting of an indeterminate number, possibly infinite, of hexagonal corridors, where each wall of every hexagon is lined with bookshelves…
The universe (which others call a library) consists of an indeterminate number of possibly infinite hexagonal corridors, each wall of every hexagon lined with bookshelves… All books, regardless of how varied they are, are composed of the same elements: spaces, periods, commas, and twenty-two letters. He also cited an undeniable fact confirmed by all travelers: in that vast library, no two books are completely identical. Based on these indisputable premises, he deduced that this library is complete, containing all possible combinations of the twenty or so writing symbols (though numerous, they are not infinite), or all that can be expressed, including everything that can be expressed in words.
On some shelf in a hexagon (as people believe), there must exist a book that is the complete summary or outline of all other books. A librarian has seen it and said it resembles a god.
Isn’t that summary of all knowledge in the universe precisely what large models like ChatGPT aim to achieve? The Tower of Babel was not built in a day, and current technology is still far from generating a summary of all human knowledge. Let us imagine finding that divine book in the Tower of Babel library; would we still need other books?
Just as life is not a track but a wilderness, there is no need for machines to point to a single clear path.
So-called summaries, like statistics, erase diversity. Just as data and algorithms exist, market issues remain. The market is not just about returns, risks, and effective resource allocation; it is also about choices and future solutions. This is also why that summary divine book in the Tower of Babel cannot completely replace other books. As Milan Kundera said, “To move forward means to go anywhere.” Let’s pause here and continue discussing industry-specific solutions.
2. Do data + finetuned domain models still possess the advantages of general large models?
The ideal domain model is one that effectively resolves domain issues through data + finetuning based on ChatGPT, while also possessing the general knowledge of large models.
Researchers at Mata found that simply using 1000 high-quality sample data for finetuning, without any reinforcement learning or human preference modeling, resulted in the 65B LLaMA model exhibiting excellent performance. The paper suggests that the model’s knowledge and capabilities were almost entirely learned during pre-training, while supervised finetuning (SFT) taught it what format to use when interacting with users, achieving expected results with a small amount of high-quality data. This is certainly good news for those of us applying large models, as we can solve problems in the domain using a small amount of high-quality data.
Domain issues, still how to proceed.
Usually, finetuning with a small amount of high-quality sample data can only achieve general performance similar to larger parameters, but when you want to optimize with more high-quality data, problems arise. Finetuning with more high-quality data also struggles to achieve linear improvements. I saw a paper, Mistral 7B (https://arxiv.org/abs/2310.06825), which performed better than larger similar models in various benchmark tests, such as outperforming the 13B Llama 2 model. The sliding window attention mechanism used in Mistral allows only the current token to focus on a specific number of previous tokens. However, you cannot confirm whether the performance improvement of the model is due to model optimization, as it is likely strongly correlated with its training data.
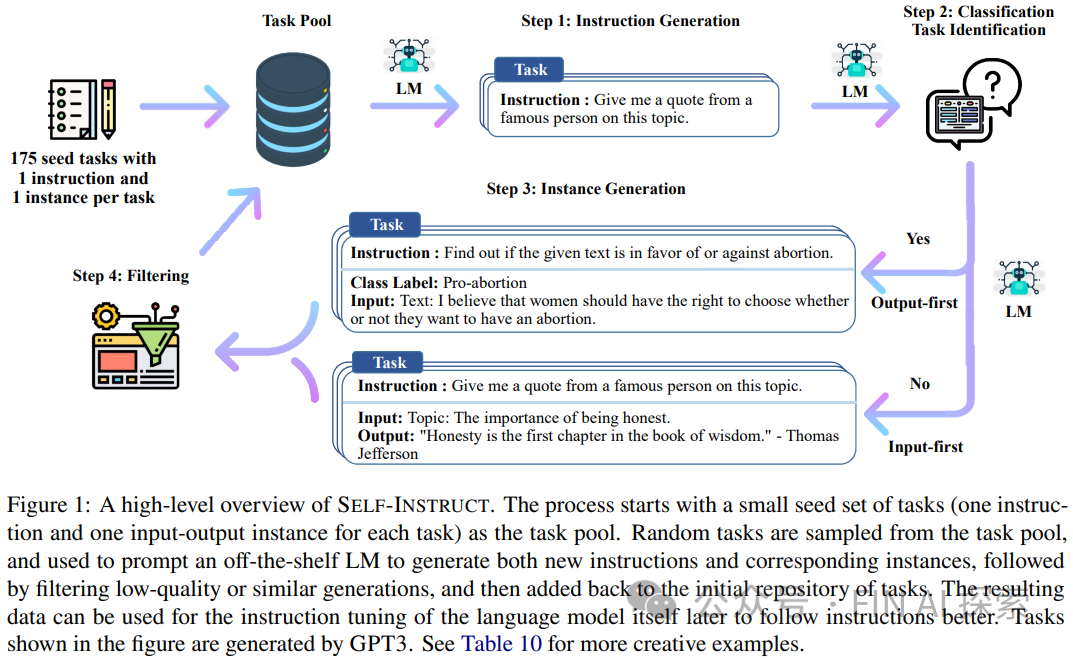
It feels like we’re back to the era of NLP alchemy, where for a problem, we need to find the most suitable and relevant data, using some parameters, techniques, and model tuning on the foundational pre-trained model. The paper Self-Instruct: Aligning Language Model with Self Generated Instructions provides a systematic solution, extracting data from GPT-4 to create a synthetic dataset for training large models. Naturally, this leads to the idea of a hen laying eggs, where based on large parameter models like GPT-4, a set of instructions for generating pre-trained data is created, generating instructions, inputs, and output samples, which are then iteratively pruned and used for finetuning self-owned large models. This is also the training scheme for many domain large models.
This seems like a self-learning process. However, large models already use generative models to produce data, so the effectiveness of such data processing schemes can be imagined.
The original texts of humanity are still paramount.
Chen Yinke is revered as the foremost scholar of the past three hundred years, serving as a professor in history, Chinese, and philosophy at Tsinghua University, mastering over twenty foreign languages. He famously said in class, “What previous scholars have discussed, I will not discuss; what has been recently discussed, I will not discuss; what foreigners have discussed, I will not discuss; what I have discussed in the past, I will not discuss.” His advice on reading is to read original texts, stating, “There are only a little over a hundred genuine classical Chinese texts; all other books are merely references and citations based on these texts.” The 2023 Nobel Prize winner in Physiology or Medicine, Katalin Karikó, also mentioned in an interview: “One of my hobbies is reading classic scientific papers. When I realized that uridine in RNA could trigger immune cells, leading to inflammation and the production of interferon, I wondered if anyone had noticed this before. Sure enough, I found it in a paper from 1963 that RNA isolated from mammalian cells does not induce the production of interferon.”
The original texts of humanity still play an irreplaceable role; machines teaching machines cannot substitute them. Of course, if large models have the ability to predict the next word of an ideal, omnipotent ‘god’ that does not exist, new original texts will emerge? It is conceivable that ChatGPT-5 will also not reach the capability to guess the next word of an omnipotent god.
3. Domain Solutions for Agents
Previously, the OpenAI Assistant API provided persistent threads and code parsers, and the ability to call third-party functions. Systematizing domain processes can also work, but it is not sufficiently general intelligence. We look forward to further solutions from Agents. Domain solutions based on Agents are one of the important directions and are worth looking forward to.
Author’s Bio:
Yuan Junfeng, author of “What Artificial Intelligence Brings to Financial Investment”, Master’s in Finance from Fudan University, FRM financial risk manager, currently employed at a large domestic brokerage firm. This article represents personal views only and should not be taken as investment advice.