Delivering NLP technical insights to you daily!

-
Higher parameter efficiency: a task only requires a small number of parameters, trains faster, occupies less memory, is less prone to overfitting on smaller datasets, and is more conducive to model storage and distribution. -
The forgetting problem in continual learning: adapters freeze the parameters of the original model, ensuring that the original knowledge is not forgotten. -
Multi-task learning: using adapters can also learn multiple tasks with relatively few parameters; compared to traditional multi-task learning, the advantage is that the influence between different tasks is reduced, while the disadvantage is that the mutual supervision brought by different tasks may decrease.
https://adapterhub.ml/

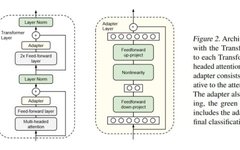
Bottleneck Adapter
-
Fine-tuning only the adapter can achieve performance close to that of fine-tuning the entire model; if the size of the adapter is adjusted according to each task, it can achieve less performance drop. -
The parameter efficiency of using adapters is higher than that of fine-tuning several layers close to the output of BERT, and its performance is better than training only the parameters of layer normalization. -
During the inference phase, pruning an adapter at a certain layer is feasible and will not significantly affect performance. However, pruning multiple layers will lead to a significant drop in performance. Compared to layers closer to the output (top layers), layers closer to the input (bottom layers) are less sensitive to pruning. -
When the standard deviation of the weight initialization distribution is less than 0.01, the effect is better; a larger standard deviation can worsen the effect.

Improvements to Adapter Structure or Training/Inferences Process
-
AdapterFusion [3]: How to better combine multi-task learning and adapters, leveraging the advantages of multi-task learning while avoiding its disadvantages? -
AdapterDrop [4]: How much slower is the speed of adapters during inference? How to prune adapters? -
Compacter [5]: Can adapter layers be made more lightweight without sacrificing performance?
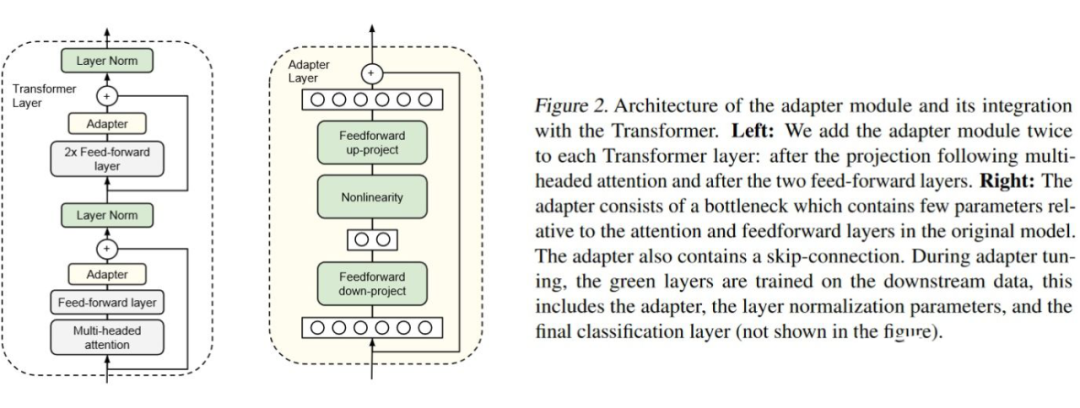
3.1 AdapterFusion
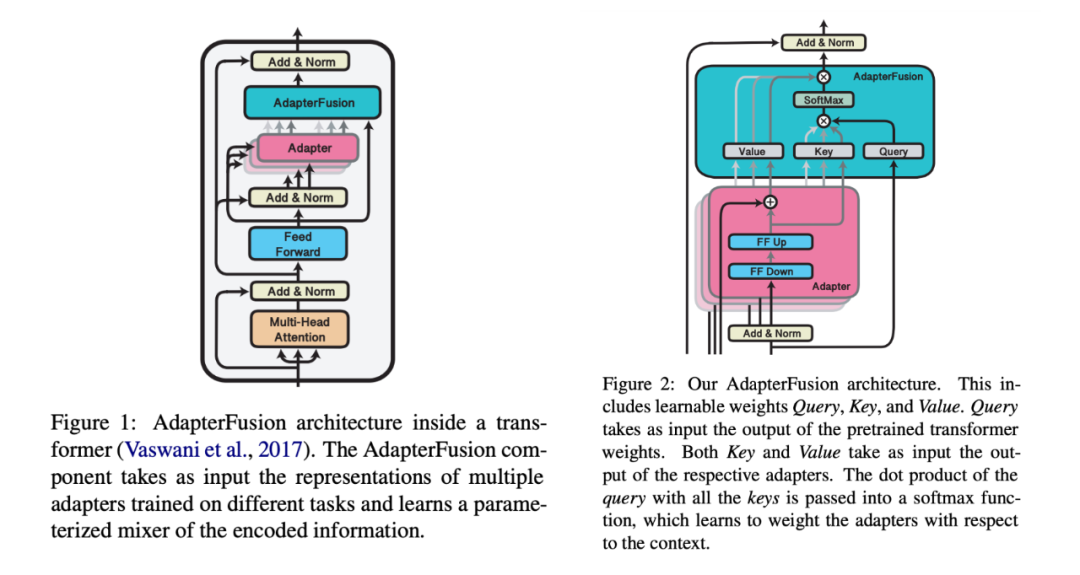
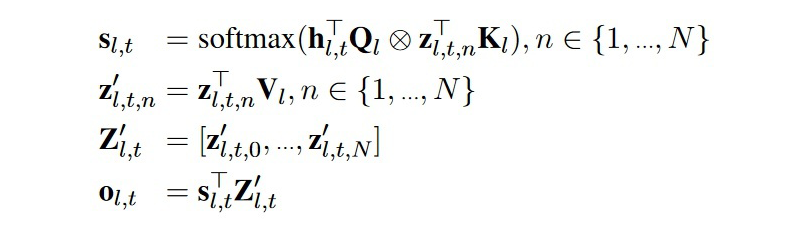
-
First step: Train the adapters for each task. The authors experimented with two methods: (1) each task independently initializes a set of adapter parameters, learning only the current task without updating the parameters of the pre-trained model (ST-A); (2) assemble all adapters together and train all adapters simultaneously using a multi-task learning loss function, while also fine-tuning all pre-trained parameters (MT-A). -
Second step: Assemble all the adapters from the first step (only for ST-A, MT-A is already assembled), then add the AdapterFusion layer, and train on the target task. The dataset used is the same version as that used in the first step. The authors also experimented with using MT-A in the second step as a control.
-
In the first stage of training, using ST-A can achieve performance close to that of fine-tuning the entire model, but using MT-A can somewhat affect performance. The authors explain that training only the adapter serves as a form of regularization, helping generalization. -
In the second stage, the addition of AdapterFusion significantly improves performance for tasks with smaller training sets. -
The best results are achieved by using ST-A in the first stage and AdapterFusion in the second stage, also utilizing the reuse of adapters. If MT-A is used in the first stage, MT-A must also be used in the second stage for some improvement. -
For tasks where AdapterFusion significantly improves performance, each layer of the AdapterFusion layer tends to attend to the adapters of other tasks more.
3.2 AdapterDrop
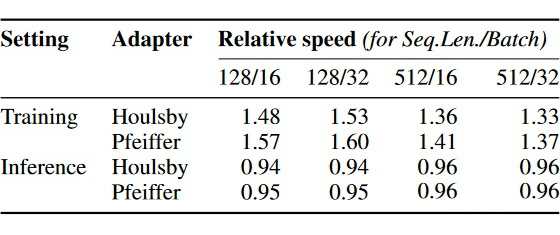

-
Removing the first few AF layers has different impacts on performance across tasks. For example, it has little impact on RTE but is very sensitive for CoLA. This indicates that directly removing AF layers is not a universally good method. -
Pruning adapters that contribute less to the output within each layer. The authors measured the average activation level of each adapter using the training set (which should be the weighted output) and retained only the two highest-contributing adapters per layer, maintaining model performance close to the original while improving inference speed by 68%.
3.3 Compacter
-
Compacter applies the Kronecker product. The Kronecker product of an mxf matrix A and a pxq matrix B is
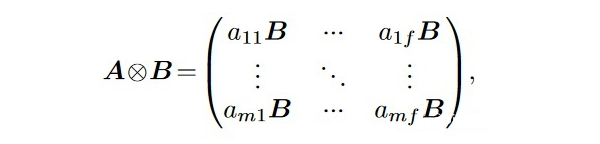
-
Assuming the model hidden state size is k and the bottleneck size is b, the adapter layer in [1] contains two kxb matrices. Compacter first borrows the idea of parameterized hypercomplex multiplication layers, expressing each adapter’s parameters as a Kronecker product of an nxn matrix A and a (k/n)x(d/n) matrix B, significantly reducing the parameter count.
-
On top of this, all adapters are required to share matrix A.
-
Additionally, matrix B is further decomposed into n groups of the product of two low-rank matrices, with sizes (k/n)xr and rx(d/n). To reduce the parameter count, the authors fixed r to 1.
-
The structure of the Compacter layer is shown in the figure below. The figure shows two compacter layers, with the colored parts being the parameters that need to be trained. By expressing the parameters in the adapter layer of [1] in this form, the structure of the compacter is obtained.

-
On T5-base, the adapter layers in [3] performed better than those in [1]. Both AdapterDrop or merely low-rank decomposition of the adapter layers performed worse than fine-tuning the entire model. -
Three innovations in Compacter allow it to achieve performance comparable to full model fine-tuning while training only around 0.1% new parameters. -
Compared to full model fine-tuning, Compacter performs better when the training set is smaller (0.1k-4k).

Applications of Adapters and Improvements for Specific Applications
4.1 Bapna & Firat (2019)
-
Adapter Structure: This paper uses a similar structure to that of [3] (but this work was done before [3]), inserting an adapter layer only at the end of each transformer layer. Additionally, the authors reinitialize the parameters of layer normalization (unlike [1], which continues training with the pre-trained layer norm parameters). -
Domain Adaptation: The authors trained on WMT En-Fr, then froze the parameters, inserted an adapter, and transferred to IWSLT’15 and JRC. The model’s performance surpassed that of LHUC [7], being close to that of full model fine-tuning. -
Multilingual NMT: The authors first trained a model for English <=> 102 other languages, then froze the parameters and fine-tuned by inserting an adapter for each source-target language pair. The main baseline method compared was the model trained only on the data of the (source language, target language) pair. The results showed that when English is the source language, most target languages performed comparably or better than the baseline; however, when English is the target language, there is a significant improvement in languages with less training data, while performance declines in languages with more training data.
4.2 K-Adapter
-
Model Structure: K-Adapter does not modify the original transformer layers but instead inserts adapter layers between two transformer layers. Within each adapter layer, two transformer layers are added between the fully connected layers that project down and up (left in the figure below), enhancing the expressiveness of the module. Each adapter layer’s input can see the output of the previous adapter and the output of the nearest previous transformer layer (right in the figure below).

▲Structure of K-Adapter (left) and training method (right)
-
Pre-training: Insert adapter layers, fix the parameters of the original model, concatenate the output of the last layer of the original model with the output of the last adapter as features, and then learn on specific pre-training tasks. -
Factual Knowledge: Trained on relationship classification tasks, with a total of 430 classes and 5.5M sentences. By learning to predict the relationships between entities, the model can learn some basic facts and common sense. -
Linguistic Knowledge: Trained on dependency classification tasks, the authors prepared approximately 1M training samples using Stanford’s parser. By learning to predict the head position corresponding to each token, the model can acquire some syntax/semantics-related knowledge.
-
Downstream Fine-tuning: The parameters added for each task are trained on the output of the last adapter layer. If multiple adapters are used simultaneously, their outputs are concatenated as features. Additionally, the parameters of the original pre-trained model are also fine-tuned. -
Downstream tasks mainly cover relationship classification, entity type recognition, and question answering. -
The baseline models include not only the previously effective language model + knowledge model but also the original RoBERTa model, the original RoBERTa model + randomly initialized adapter parameters, and the model obtained from multi-task learning of the original RoBERTa model on two tasks. The experimental results show that using both adapters simultaneously yields the best results. For the last two downstream tasks, factual knowledge is more beneficial, while linguistic knowledge is more beneficial for the first task.
4.3 MAD-X
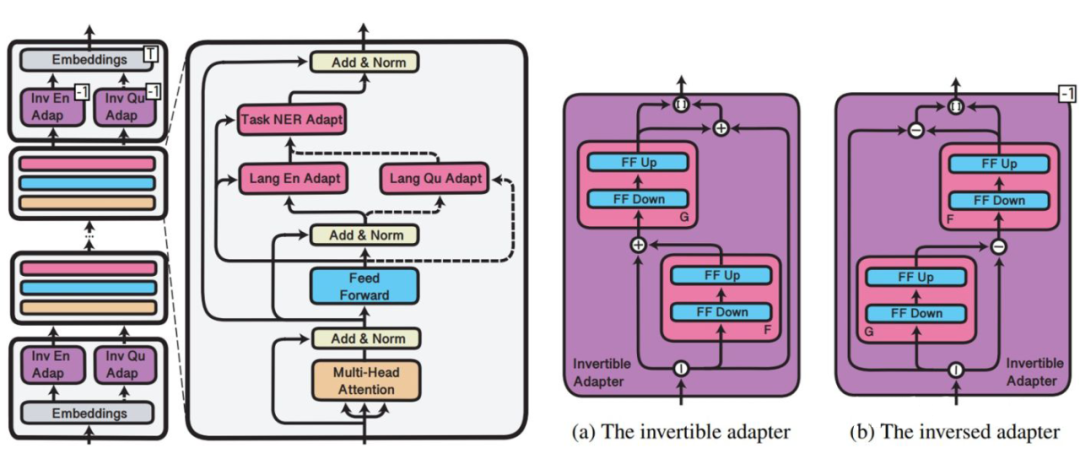
▲Placement of the three types of adapters in MAD-X (left) and the structure of the invertible adapter (right)
First, train language adapters and invertible adapters for each language using the MLM task. Then insert task-specific adapters and train on the training set of the source language using the language adapter and invertible adapter. During inference, use the language adapter and invertible adapter for the target language, along with the task adapter for the source language.
4.4 Other Applications
-
UDapter [10]: Uses adapters to train parameter-efficient multilingual dependency parsing models. -
Philip et al. (2020) [11]: Similar to [6], focusing on multilingual machine translation tasks, but introducing adapter parameters for each language instead of one adapter for each language pair like [6]. -
Lauscher et al. (2020) [12]: Similar to [8], using adapters to modularly introduce knowledge.

Adapter-Like Structures
-
BERT and PAL [13]
-
Prefix Tuning [14]
-
LoRA [15]
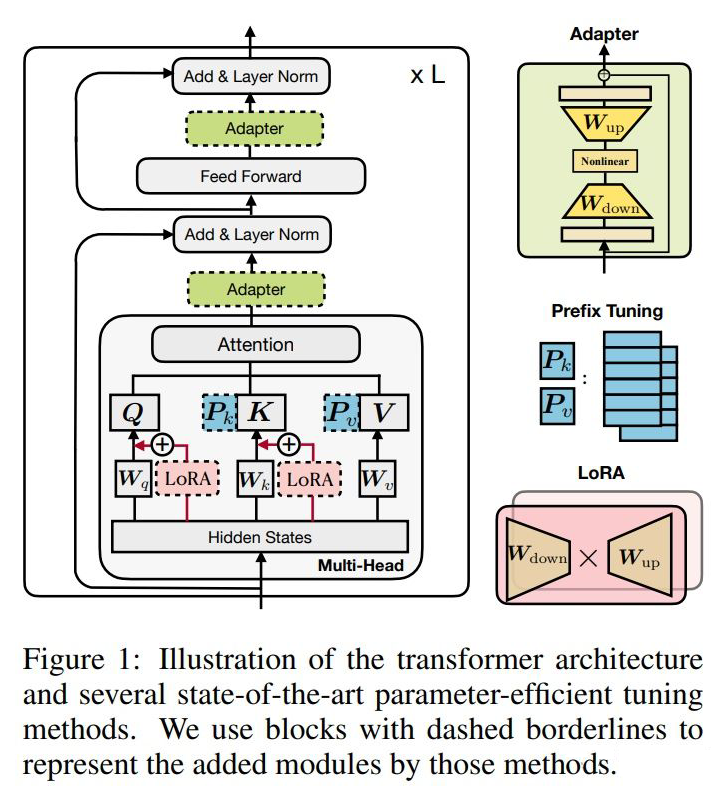
▲Structures of three types of adapters (adapter, prefix tuning, LoRA), image from [16].

References

[1] Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., Laroussilhe, Q. D., Gesmundo, A., Attariyan, M., & Gelly, S. (2019). Parameter-Efficient Transfer Learning for NLP. Proceedings of the 36th International Conference on Machine Learning, 2790–2799. https://proceedings.mlr.press/v97/houlsby19a.html
[2] Rebuffi, S. A., Bilen, H., & Vedaldi, A. (2017). Learning multiple visual domains with residual adapters. Advances in neural information processing systems,30. https://proceedings.neurips.cc/paper/2017/file/e7b24b112a44fdd9ee93bdf998c6ca0e-Paper.pdf
[3] Pfeiffer, J., Kamath, A., Rücklé, A., Cho, K., & Gurevych, I. (2021). AdapterFusion: Non-Destructive Task Composition for Transfer Learning. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, 487–503. https://doi.org/10.18653/v1/2021.eacl-main.39
[4] Rücklé, A., Geigle, G., Glockner, M., Beck, T., Pfeiffer, J., Reimers, N., & Gurevych, I. (2021). AdapterDrop: On the Efficiency of Adapters in Transformers. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 7930–7946. https://doi.org/10.18653/v1/2021.emnlp-main.626
[5] Karimi Mahabadi, R., Henderson, J., & Ruder, S. (2021). Compacter: Efficient Low-Rank Hypercomplex Adapter Layers. Advances in Neural Information Processing Systems, 34, 1022–1035. https://proceedings.neurips.cc/paper/2021/hash/081be9fdff07f3bc808f935906ef70c0-Abstract.html
[6] Bapna, A., & Firat, O. (2019). Simple, Scalable Adaptation for Neural Machine Translation. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 1538–1548. https://doi.org/10.18653/v1/D19-1165
[7] Vilar, D. (2018). Learning Hidden Unit Contribution for Adapting Neural Machine Translation Models. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), 500–505. https://doi.org/10.18653/v1/N18-2080
[8] Wang, R., Tang, D., Duan, N., Wei, Z., Huang, X., Ji, J., Cao, G., Jiang, D., & Zhou, M. (2021). K-Adapter: Infusing Knowledge into Pre-Trained Models with Adapters. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, 1405–1418. https://doi.org/10.18653/v1/2021.findings-acl.121
[9] Pfeiffer, J., Vulić, I., Gurevych, I., & Ruder, S. (2020). MAD-X: An Adapter-Based Framework for Multi-Task Cross-Lingual Transfer (arXiv:2005.00052). arXiv. http://arxiv.org/abs/2005.00052
[10] Üstün, A., Bisazza, A., Bouma, G., & van Noord, G. (2020). UDapter: Language Adaptation for Truly Universal Dependency Parsing. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2302–2315. https://doi.org/10.18653/v1/2020.emnlp-main.180
[11] Philip, J., Berard, A., Gallé, M., & Besacier, L. (2020). Monolingual Adapters for Zero-Shot Neural Machine Translation. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 4465–4470. https://doi.org/10.18653/v1/2020.emnlp-main.361
[12] Lauscher, A., Majewska, O., Ribeiro, L. F. R., Gurevych, I., Rozanov, N., & Glavaš, G. (2020). Common Sense or World Knowledge? Investigating Adapter-Based Knowledge Injection into Pretrained Transformers. Proceedings of Deep Learning Inside Out (DeeLIO): The First Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, 43–49. https://doi.org/10.18653/v1/2020.deelio-1.5
[13] Stickland, A. C., & Murray, I. (2019). BERT and PALs: Projected Attention Layers for Efficient Adaptation in Multi-Task Learning. Proceedings of the 36th International Conference on Machine Learning, 5986–5995. https://proceedings.mlr.press/v97/stickland19a.html
[14] Li, X. L., & Liang, P. (2021). Prefix-Tuning: Optimizing Continuous Prompts for Generation. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 4582–4597. https://doi.org/10.18653/v1/2021.acl-long.353
[15] Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2021). LoRA: Low-Rank Adaptation of Large Language Models (arXiv:2106.09685). arXiv. http://arxiv.org/abs/2106.09685
[16] He, J., Zhou, C., Ma, X., Berg-Kirkpatrick, T., & Neubig, G. (2022). Towards a Unified View of Parameter-Efficient Transfer Learning (arXiv:2110.04366). arXiv. http://arxiv.org/abs/2110.04366
📝Submit your paper interpretation to let your article reach more people from different backgrounds and fields, and perhaps increase your citations significantly~ To submit, add “submission” in the WeChat remarks below.
Recent Articles
Which conference to submit to: EMNLP 2022 or COLING 2022?
A new and easy-to-use unified model based on Word-Word relationships for NER
Alibaba + Peking University | Amazing effects of simple masking on gradients
ACL’22 | Kuaishou + Chinese Academy of Sciences propose a data augmentation method: Text Smoothing
For submission or exchange of learning, please note:Nickname-School (Company)-Direction, join the DL&NLP exchange group.
There are many directions:Machine Learning, Deep Learning, Python, Sentiment Analysis, Opinion Mining, Syntactic Analysis, Machine Translation, Human-Computer Dialogue, Knowledge Graph, Speech Recognition, etc..

Remember to note!
Organizing is not easy, please give it a look!