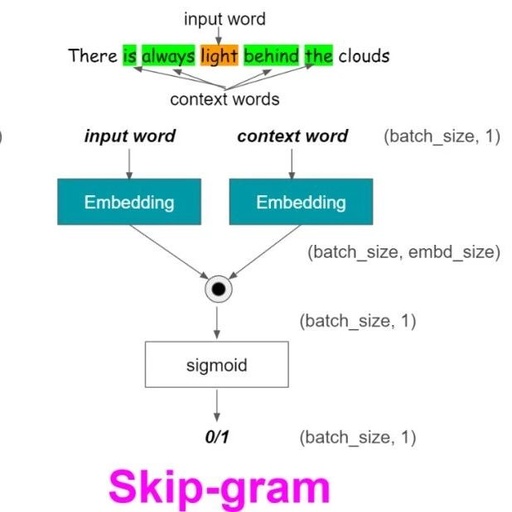
1 Introduction
This article mainly introduces a very classic algorithm in word embedding, Word2Vec. Initially, Word2Vec was primarily used in text-related problems, but now friends participating in competitions should have noticed that almost half of the traditional data competitions involve Word2Vec. Therefore, we must take a good look at what Word2Vec is actually learning, so that we can apply these techniques better in the future.
We will first briefly introduce word embedding models, and then detail Word2Vec, including what Word2Vec does, why to use Word2Vec (what innovations it has compared to the old BOW model), the two common frameworks of Word2Vec and their selection, and finally, we will provide two implementations of Word2Vec based on the Pytorch version.
This article will not list too much mathematics but will mainly discuss the frameworks and implementations. Everyone can think about how to apply it to their own problems. We will also list some related applications in word embedding models.
2 What is Word Embedding?
Word embedding is a representation method for words that can transform different words into different real-valued vectors through many machine learning models. Currently, there are many technologies for Word Embedding, such as Google’s Word2Vec, Stanford’s Glove, Facebook’s Fasttext, and so on.
Word embedding is sometimes referred to as distributed semantic models or vector space models. Therefore, from the name and its transformation method, we can understand that the Word Embedding technology can group similar types of words together. For example, apples, mangoes, and bananas will be closer in the projected vector space, while books and houses will be relatively farther away from words like apples.
3 When to Use Word Embedding Models
So far, word embedding can be used in feature generation, document clustering, text classification, and natural language processing tasks, such as:
-
Calculating similar words: Word embedding can be used to find words that are close to a certain word.
-
Building a group of related words: Clustering different words together to gather related words;
-
Features for text classification: In text classification problems, since words cannot be directly used for training machine learning models, we first project the words into vector space, allowing us to train machine learning models based on these vectors;
-
For document clustering.
The above examples are text-related tasks, but currently, word embedding models have been extended to various aspects. For example:
-
On Weibo, everyone uses a word to represent themselves, constructing embeddings for each person, and then calculating the correlation between people to find the most closely related individuals;
-
In recommendation problems, embedding each product based on each user’s purchase records allows us to calculate the correlation between products and make recommendations;
-
In the Tianchi maritime problem, embedding different ships at the same latitude and longitude allows us to obtain the vectors of each ship, helping us identify ships that frequently operate in certain areas;
It can be said that word embedding has greatly assisted in finding correlations between objects. Nowadays, embedding technology can be seen in almost every data competition. This article mainly focuses on the most commonly used Word2Vec model.
4 What is the Word2Vec Model?
Word2Vec is a method for obtaining word representations that can effectively capture the syntactic and semantic relationships of vocabulary. From a network structure perspective, it is a two-layer shallow network.
That is, it consists of an input layer, a hidden layer, and an output layer.
Compared to latent semantic analysis models, Word2Vec is a better and more efficient solution.
5 What Does Word2Vec Do?
Word2Vec represents words in the vector space, meaning that words are represented as vectors. In the word vector space: words with similar meanings appear together, while different words are located far apart. This is also referred to as semantic relationships.
Neural networks do not understand text but only understand numbers. Word embedding provides a way to convert text into numerical vectors.
Word2Vec works by reconstructing the linguistic context of words. But what is linguistic context? In general life situations, when we communicate through speaking or writing, others will try to figure out the purpose of the sentence. For example, “What is the temperature in India?” Here, the context is that the user wants to know “the temperature in India,” which is the context.
In short, the primary goal of a sentence is context. The words or sentences surrounding spoken or written language (disclosure) help determine the meaning of the context. Word2Vec learns the vector representation of words through context.
6 Why Use Word2Vec?
6.1 Before Word Embedding
To understand why Word2Vec is good, we need to look at what methods were used before Word2Vec and what shortcomings those methods had, which will help us understand the benefits of using Word2Vec.
6.2 Problems with Latent Semantic Analysis Methods
Latent semantic analysis methods were the most commonly used methods before word vectors. They use the concept of BOW (Bag of Words), where each word is represented by an encoded vector, and each word is a sparse representation, where the dimension of the vector corresponds to the size of the vocabulary. If a word appears, we count it.
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
data_corpus = ['guru99 is the best size for online tutorials. I love to visit guru99 .']
vocabulary = vectorizer.fit(data_corpus)
X = vectorizer.transform(data_corpus)
print(X.toarray())[[1 1 2 1 1 1 1 1 1 1 1]]print(vocabulary.get_feature_names())[‘best’, ‘for’, ‘guru99’, ‘is’, ‘love’, ‘online’, ‘size’, ‘the’, ‘to’, ‘tutorials’, ‘visit’]
In latent semantic analysis, each row (feature column) represents a certain word, and each column represents the frequency of that word appearing in a certain text.
Later, many scholars discovered that the Countervector method would overlook the occurrence of words in different text corpora. Logically, if certain words frequently appear in different texts, it would be better to reduce the importance of such vocabulary. Thus, the TFIDF method emerged.
-
In TFIDF, the importance of words increases proportionally with their frequency in a document, but decreases inversely with their frequency in the corpus.
However, TFIDF also has many obvious problems, as outlined (see wiki):
The most meaningful words for distinguishing documents should be those that appear frequently in a document but infrequently in other documents in the entire document set. Therefore, if the feature space coordinate system takes the term frequency (tf) as a measure, it can reflect the characteristics of similar texts. Additionally, considering the ability of words to distinguish different categories, the tf-idf method posits that the smaller the frequency of a word appearing in the text, the greater its ability to distinguish different categories of text. Thus, the concept of inverse document frequency (idf) is introduced, using the product of tf and idf as a measure of the feature space coordinate system, which adjusts the weights of tf to highlight important words and suppress less important words. However, in essence, idf is a weighting that attempts to suppress noise, and it simply assumes that words with small text frequency are more important, while words with high text frequency are less useful. This is clearly not entirely correct. The simple structure of idf cannot effectively reflect the importance of words and the distribution of feature words, making it unable to perform the weight adjustment function well, so the precision of the tf-idf method is not very high.
6.3 Problems with BOW Methods
Whether it is Countervector or TFIDF, we find that they both represent text based on the distribution of global vocabulary, so their shortcomings are also obvious.
-
They ignore the order of words within individual text sentences. For example, ‘this is bad’ is represented the same as ‘bad is this’ in BOW;
-
They ignore the context of words. For instance, if we write a sentence, “He loved books. Education is best found in books,” we will not consider the meaning of the previous or following sentence when processing these two sentences, even though there is a relationship between them.
To overcome the above two shortcomings, Word2Vec was developed and used to address these issues.
7 How Does Word2Vec Work?
Word2Vec predicts by learning the context adjacent to a word. For example, to obtain the word vector for ‘Loves’ in the sentence “He Loves Football,” we assume:
loves = Vin. P(Vout / Vin) is calculated
where,
Vin is the input word.
P is the probability of likelihood.
Vout is the output word.Then the word “loves” moves through each word in the corpus. The grammar and semantics between words can be encoded, which greatly helps us find similar and related vocabulary.
8 Word2Vec Framework
The problem that Word2Vec solves is what has been mentioned above. Here we introduce the two frameworks of Word2Vec:
-
Continuous Bag of Words (CBOW)
-
Skip-gram
We all know that learning word representations is unsupervised, but without targets/labels, it would be very difficult to train the model. Skip-gram and CBOW convert unsupervised representations into a supervised format, making it possible to train the model. Among them:
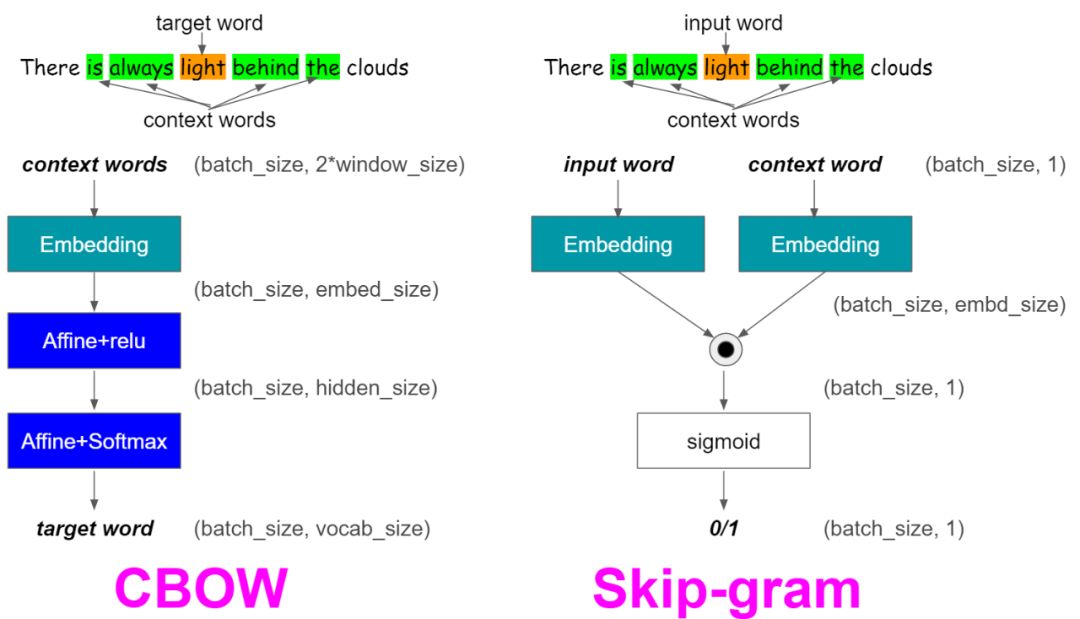
-
CBOW predicts the current word using the surrounding context (a certain window size) words. For example, if $w_{i-1}$, $w_{i-2}$, $w_{i+1}$, $w_{i+2}$ are the given words or context, then our model needs to predict $w_i$.
-
Skip-Gram, on the other hand, means predicting the given sequence or context from the word. If $w_i$ is given, then we use it to predict its context $w_{i-1}$, $w_{i-2}$, $w_{i+1}$, $w_{i+2}$.
The difference between the two can be referenced in the following diagram:
8.1 CBOW
The following is a diagram of CBOW:
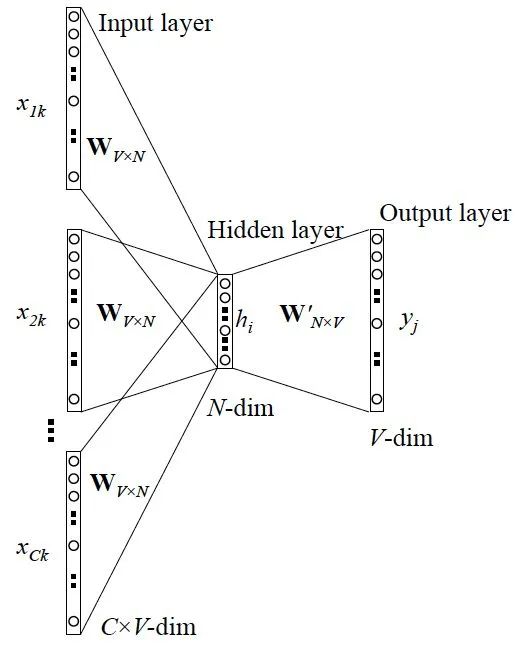
Assuming V is the size of the vocabulary and N is the size of the hidden layer, we define the input as $ extbackslash{ x_{i-1}, x_{i-1}, x_{i+1}, x_{i+2}}$, then we obtain a weight matrix of size $V * N$. That is, we predict our current vocabulary using surrounding vocabulary.
8.2 Skip-Gram
The following is a diagram of Skip-Gram:
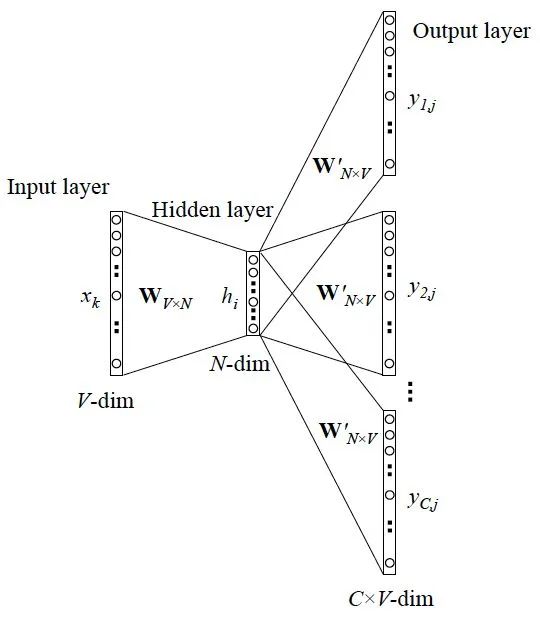
Skip-Gram model and CBOW are opposite; we predict surrounding vocabulary using the current vocabulary.
8.3 How to Choose Between CBOW and Skip-Gram
-
CBOW trains much faster than Skip-Gram;
-
CBOW provides a better representation for common words compared to Skip-Gram;
-
Skip-Gram can represent rare words or phrases with a small training dataset;
8.4 Understanding Word Vectors
Word2Vec aims to map words into word vector space, which requires such a mapping. How to reasonably understand this? During training, we first map the original word into a V-dimensional space, where V is the number of different words in the vocabulary. For example, if we input a one-hot encoder for a simple word x: [1,0,0,…,0], then during the weight update from the input layer to the hidden layer, only the weight corresponding to the position of 1 is activated. The number of these weights corresponds to the number of hidden layer nodes, thus forming a vector vx to represent x. Since the position of 1 in the one-hot encoder for each word is different, this vector vx can uniquely represent x.
9 Code Demonstration
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
torch.manual_seed(1)Construct a mapping to map words to integers
CONTEXT_SIZE = 2 # 2 words to the left, 2 to the right
text = """We are about to study the idea of a computational process.
Computational processes are abstract beings that inhabit computers.
As they evolve, processes manipulate other abstract things called data.
The evolution of a process is directed by a pattern of rules called a program.
People create programs to direct processes. In effect, we conjure the spirits of the computer with our spells.""".split()
split_ind = (int)(len(text) * 0.8)
vocab = set(text)
vocab_size = len(vocab)
print('vocab_size:', vocab_size)
w2i = {w: i for i, w in enumerate(vocab)}
i2w = {i: w for i, w in enumerate(vocab)}Construct the data format required for CBOW and SkipGram
# context window size is two
def create_cbow_dataset(text): data = [] for i in range(2, len(text) - 2): context = [text[i - 2], text[i - 1], text[i + 1], text[i + 2]] target = text[i] data.append((context, target)) return data
def create_skipgram_dataset(text): import random data = [] for i in range(2, len(text) - 2): data.append((text[i], text[i-2], 1)) data.append((text[i], text[i-1], 1)) data.append((text[i], text[i+1], 1)) data.append((text[i], text[i+2], 1)) # negative sampling for _ in range(4): if random.random() < 0.5 or i >= len(text) - 3: rand_id = random.randint(0, i-1) else: rand_id = random.randint(i+3, len(text)-1) data.append((text[i], text[rand_id], 0)) return data
cbow_train = create_cbow_dataset(text)
skipgram_train = create_skipgram_dataset(text)
print('cbow sample', cbow_train[0])
print('skipgram sample', skipgram_train[0])Construct the model framework
class CBOW(nn.Module): def __init__(self, vocab_size, embd_size, context_size, hidden_size): super(CBOW, self).__init__() self.embeddings = nn.Embedding(vocab_size, embd_size) self.linear1 = nn.Linear(2*context_size*embd_size, hidden_size) self.linear2 = nn.Linear(hidden_size, vocab_size) def forward(self, inputs): embedded = self.embeddings(inputs).view((1, -1)) hid = F.relu(self.linear1(embedded)) out = self.linear2(hid) log_probs = F.log_softmax(out) return log_probs
class SkipGram(nn.Module): def __init__(self, vocab_size, embd_size): super(SkipGram, self).__init__() self.embeddings = nn.Embedding(vocab_size, embd_size) def forward(self, focus, context): embed_focus = self.embeddings(focus).view((1, -1)) embed_ctx = self.embeddings(context).view((1, -1)) score = torch.mm(embed_focus, torch.t(embed_ctx)) log_probs = F.logsigmoid(score) return log_probsConduct model training
embd_size = 100
learning_rate = 0.001
n_epoch = 30
def train_cbow(): hidden_size = 64 losses = [] loss_fn = nn.NLLLoss() model = CBOW(vocab_size, embd_size, CONTEXT_SIZE, hidden_size) print(model) optimizer = optim.SGD(model.parameters(), lr=learning_rate)
for epoch in range(n_epoch): total_loss = .0 for context, target in cbow_train: ctx_idxs = [w2i[w] for w in context] ctx_var = Variable(torch.LongTensor(ctx_idxs))
model.zero_grad() log_probs = model(ctx_var)
loss = loss_fn(log_probs, Variable(torch.LongTensor([w2i[target]])))
loss.backward() optimizer.step() total_loss += loss.data losses.append(total_loss) return model, losses
def train_skipgram(): losses = [] loss_fn = nn.MSELoss() model = SkipGram(vocab_size, embd_size) print(model) optimizer = optim.SGD(model.parameters(), lr=learning_rate) for epoch in range(n_epoch): total_loss = .0 for in_w, out_w, target in skipgram_train: in_w_var = Variable(torch.LongTensor([w2i[in_w]])) out_w_var = Variable(torch.LongTensor([w2i[out_w]])) model.zero_grad() log_probs = model(in_w_var, out_w_var) loss = loss_fn(log_probs[0], Variable(torch.Tensor([target]))) loss.backward() optimizer.step()
total_loss += loss.data losses.append(total_loss) return model, losses cbow_model, cbow_losses = train_cbow()
sg_model, sg_losses = train_skipgram()Model Testing
def test_cbow(test_data, model): print('====Test CBOW===') correct_ct = 0 for ctx, target in test_data: ctx_idxs = [w2i[w] for w in ctx] ctx_var = Variable(torch.LongTensor(ctx_idxs))
model.zero_grad() log_probs = model(ctx_var) _, predicted = torch.max(log_probs.data, 1)# print(predicted,int(predicted[0])) predicted_word = i2w[int(predicted[0])] print('predicted:', predicted_word) print('label :', target) if predicted_word == target: correct_ct += 1 print('Accuracy: {:.1f}% ({:d}/{:d})'.format(correct_ct/len(test_data)*100, correct_ct, len(test_data)))
def test_skipgram(test_data, model): print('====Test SkipGram===') correct_ct = 0 for in_w, out_w, target in test_data: in_w_var = Variable(torch.LongTensor([w2i[in_w]])) out_w_var = Variable(torch.LongTensor([w2i[out_w]]))
model.zero_grad() log_probs = model(in_w_var, out_w_var) _, predicted = torch.max(log_probs.data, 1) predicted = predicted[0] if predicted == target: correct_ct += 1
print('Accuracy: {:.1f}% ({:d}/{:d})'.format(correct_ct/len(test_data)*100, correct_ct, len(test_data)))
test_cbow(cbow_train, cbow_model)
print('------')
test_skipgram(skipgram_train, sg_model)10 References
-
tf-idf: https://zh.wikipedia.org/wiki/Tf-idf
-
word2vec-pytorch: https://github.com/jojonki/word2vec-pytorch
-
[NLP] Understand the essence of word vectors Word2vec: https://zhuanlan.zhihu.com/p/26306795
-
Word Embedding Tutorial: word2vec using Gensim [EXAMPLE]: https://www.guru99.com/word-embedding-word2vec.html
-
Implementing word2vec in PyTorch (skip-gram model): https://towardsdatascience.com/implementing-word2vec-in-pytorch-skip-gram-model-e6bae040d2fb
-
https://gist.github.com/mbednarski/da08eb297304f7a66a3840e857e060a0
-
Tutorial: Build your own Skip-gram Embeddings and use them in a Neural Network: https://blog.cambridgespark.com/tutorial-build-your-own-embedding-and-use-it-in-a-neural-network-e9cde4a81296
AI learning routes and quality resources, reply “AI” in the background to obtain
