

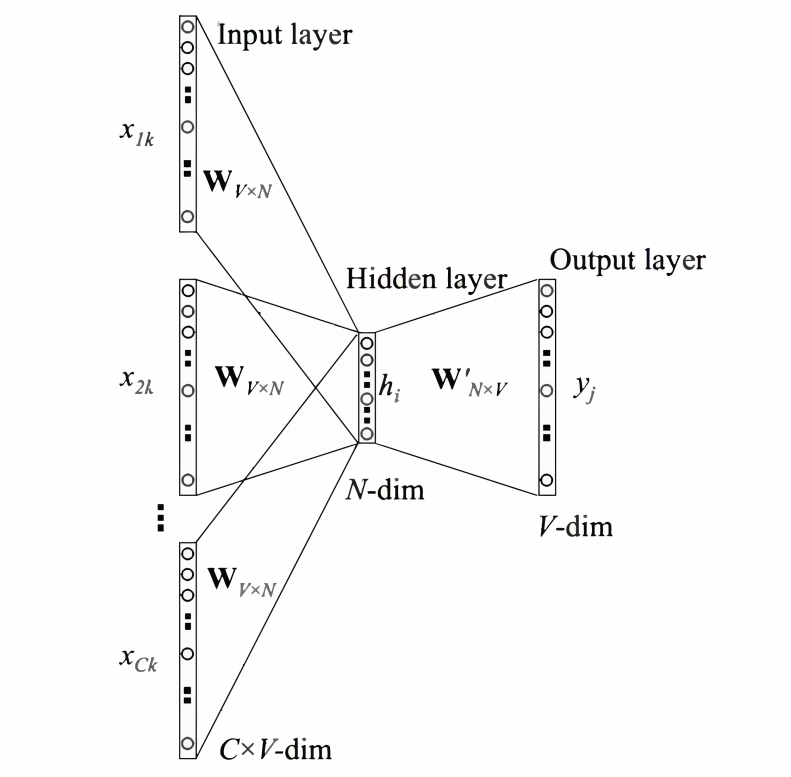
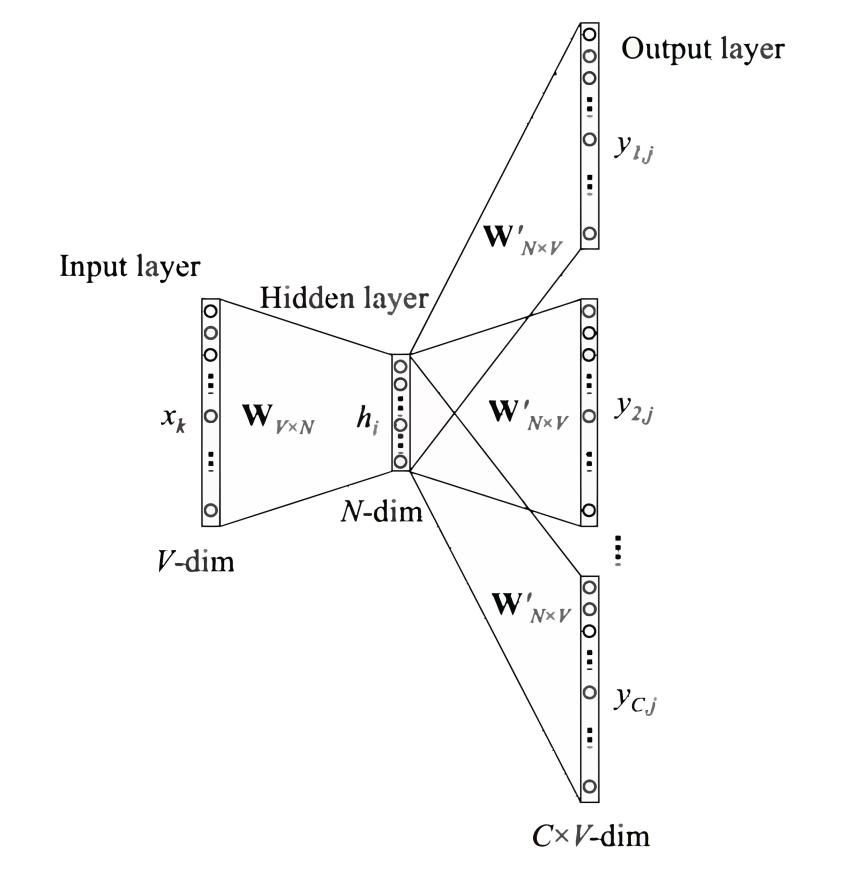
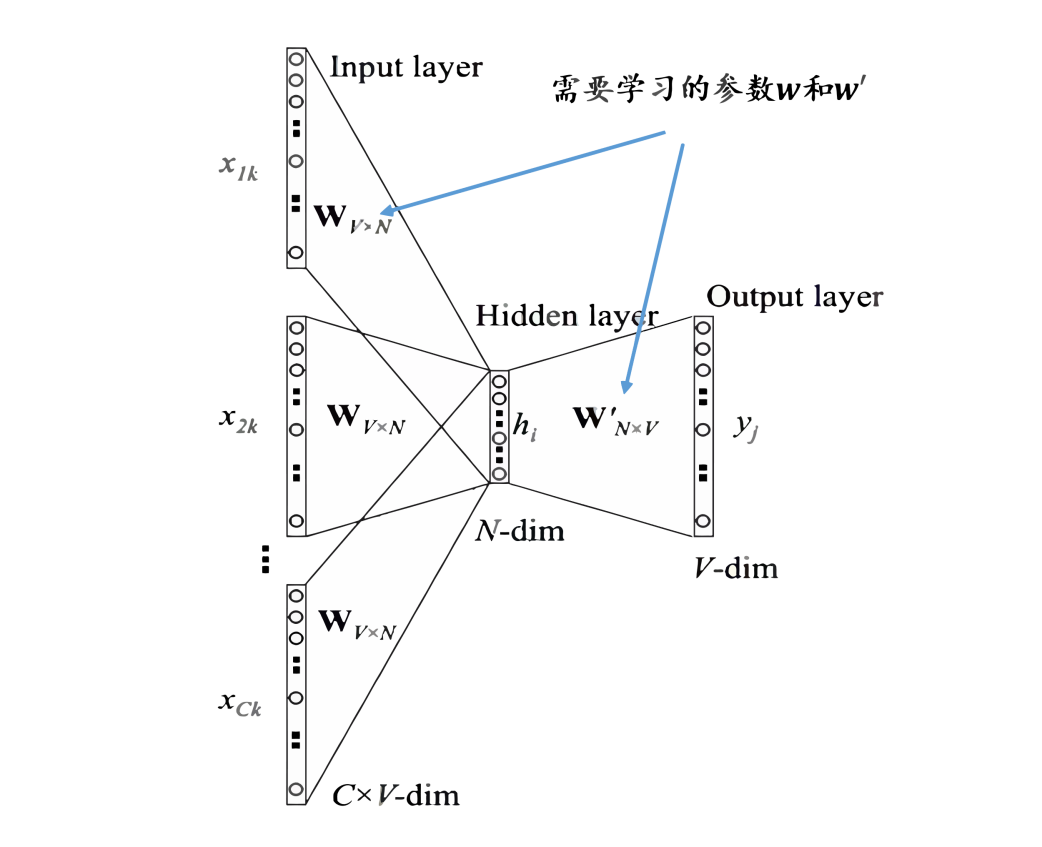
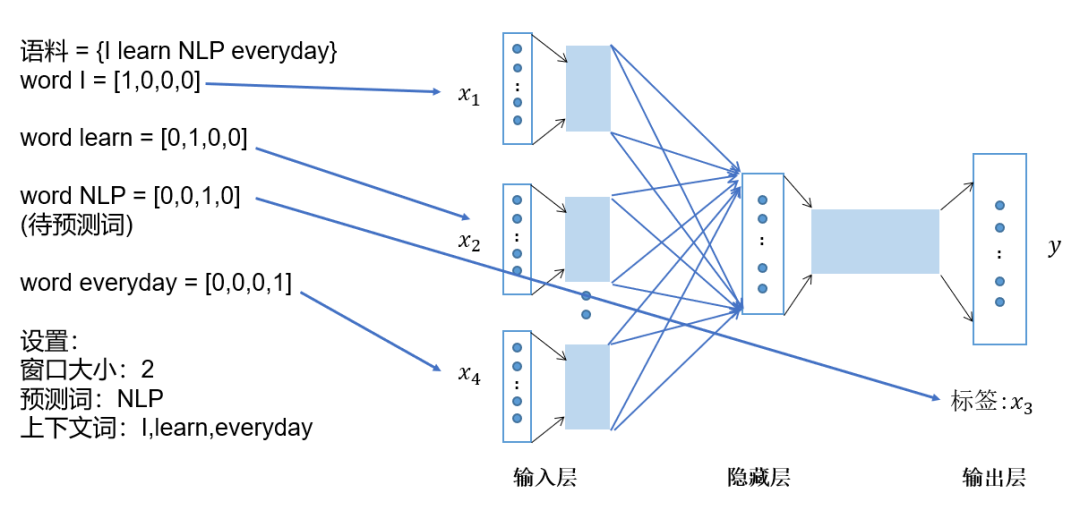
-
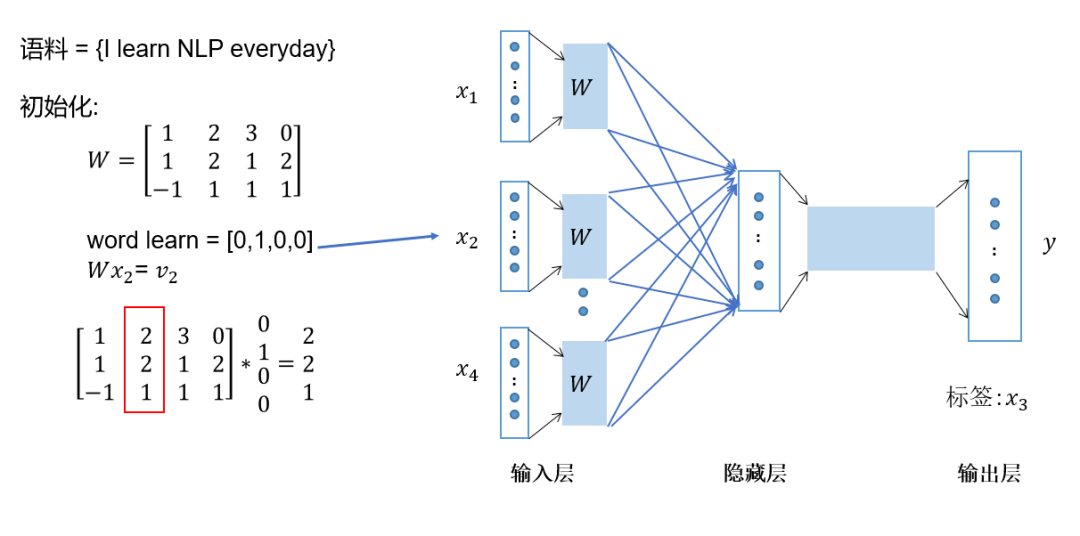
Represent the context words as one-hot vectors as the model’s input, where the dimension of the vocabulary is , and the number of context words is ; -
Then multiply the one-hot vectors of all context words by the shared input weight matrix; -
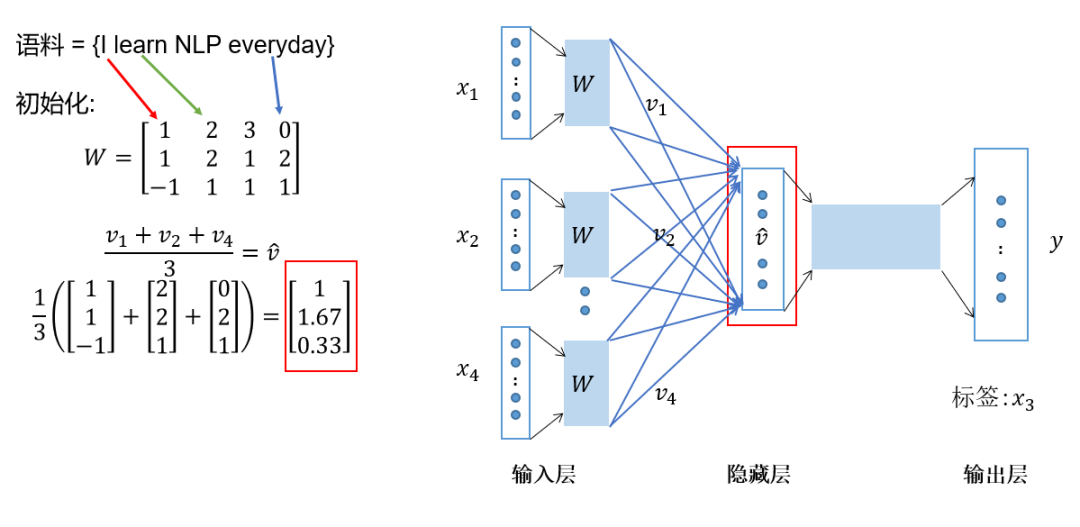
Add and average the vectors obtained in the previous step to form the hidden layer vector; -
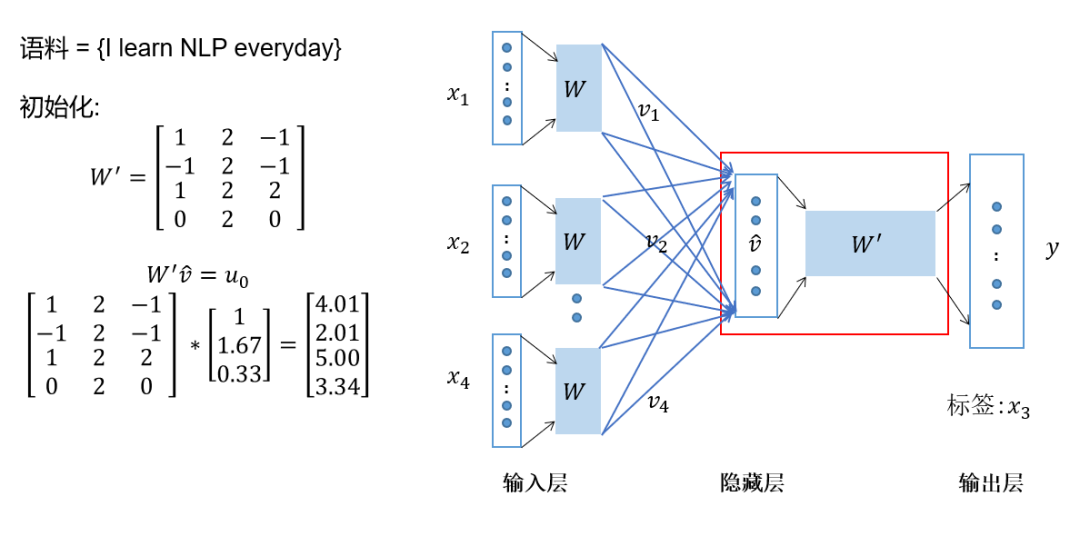
Multiply the hidden layer vector by the shared output weight matrix; -
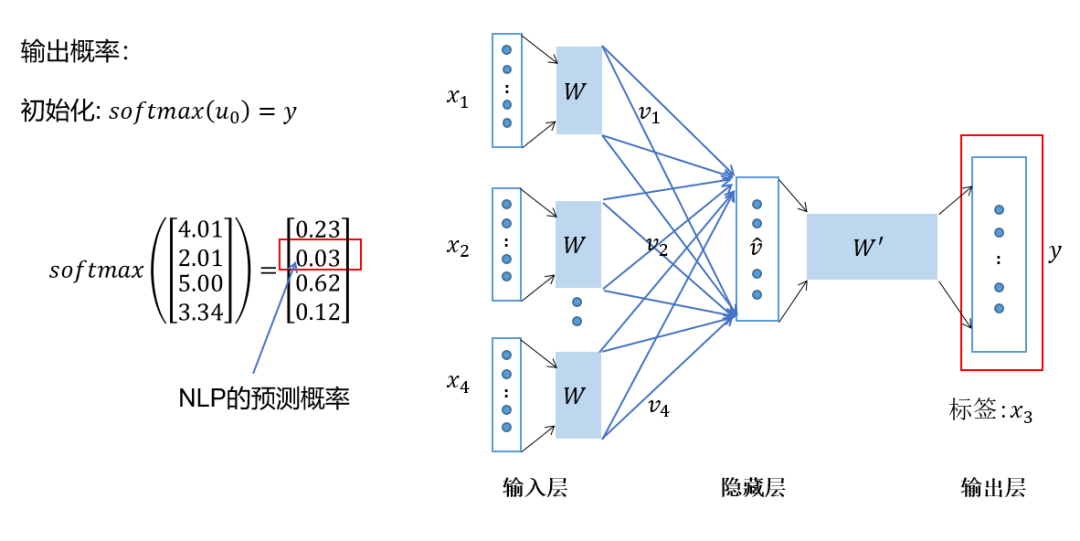
Apply softmax activation to the calculated vector to obtain a probability distribution of dimension , and take the index with the highest probability as the predicted target word.
I am Dong Ge, and I am currently creating the series topic 👉「100 Cool Operations in Pandas」, welcome to subscribe. After subscribing, the article updates will be pushed to the subscription account immediately, and you won’t miss any of them.
Finally, I would like toshare “100 Python E-books”, including Python programming techniques, data analysis, web scraping, web development, machine learning, and deep learning.
Now sharing for free, readers in need can download and study. Just reply with the keyword:Python in the public account “GitHuboy“, and that’s it.