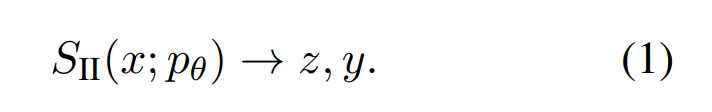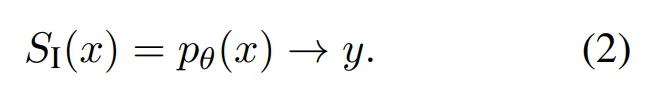When discussing strategies for large language models (LLMs), there are generally two types: System 1 (fast reaction) and System 2 (slow thinking).
System 2 reasoning tends to involve more deliberate thought, generating intermediate reasoning that allows the model (or human) to reason and plan in order to successfully complete tasks or respond to instructions. Effortful mental activity is required in System 2 reasoning, especially in cases where System 1 (more automated thinking) may fail.
Thus, System 1 is defined as an application of Transformers that can directly generate responses based on input without generating intermediate tokens. System 2 is defined as any method that generates intermediate tokens, including performing searches or prompting multiple times before finally generating a response.
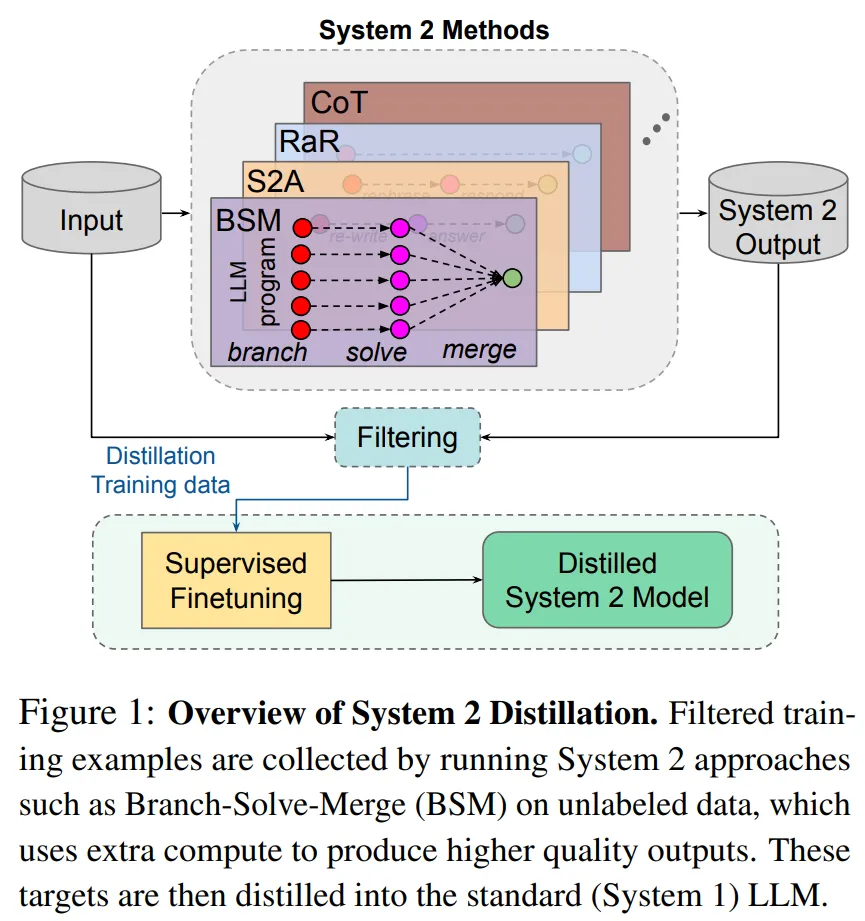
A series of related System 2 techniques have been proposed in the industry, including chain of thought, tree of thought, mind maps, branch-solve-merge, System 2 Attention, Rephrase and Respond (RaR), among others. Thanks to this explicit reasoning, many methods have shown more accurate results, but this often comes with higher reasoning costs and response delays. Therefore, many such methods are not used in production systems, with most relying on System 1.
For humans, the process of learning to transfer skills from deliberate (System 2) to automatic (System 1) is known in psychology as automaticity, along with the use of procedural memory. For instance, when driving to work for the first time, people typically exert conscious effort to plan and make decisions to reach their destination. After repeating the route, the driving process becomes “compiled” into the subconscious. Similarly, sports like tennis can become “second nature”.
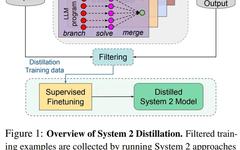
In this paper, researchers from Meta FAIR explore a similar AI modeling approach. This approach performs compilation in an unsupervised manner given a set of unlabeled examples, known as System 2 distillation. For each example, they apply the given System 2 method and then measure the quality of the predictions in an unsupervised manner.
For example, for tasks with unique answers, the researchers apply self-consistency and sample multiple times. For examples sufficiently consistent in System 2, they assume this result should be distilled and add it to the distillation pool. They then fine-tune System 1 to match the predictions of the collected example pool from the System 2 method, without generating intermediate steps. Figure 1 illustrates the overall process of distilling System 2 into System 1.
The researchers experimented with four different System 2 LLM methods and five different tasks. The results show that the method in this paper can distill System 2 reasoning back into System 1 across various settings, sometimes even outperforming the results of the System 2 teacher. Furthermore, these predictions now incur only a fraction of the computational cost.
For instance, they found that successful distillation applies to tasks dealing with biased opinions or irrelevant information (System 2 Attention), clarifying and improving responses in certain reasoning tasks (RaR), and fine-grained evaluations of LLMs (branch-solve-merge).
However, not all tasks can be distilled into System 1, especially complex mathematical reasoning tasks that require chain of thought. This also reflects in humans, as certain tasks cannot be performed without the deliberate reasoning of System 2.
Paper Title:
Distilling System 2 into System 1
https://arxiv.org/pdf/2407.06023
Distilling System 2 Back to System 1
Setup: System 1 and System 2 Models
Given an input x, the researchers consider setting up a single model, in their case a large language model (LLM), capable of achieving two response modes:
Formally, the researchers view the System 2 model S_II as a function that takes LLM p_θ and input x, and can repeatedly call LLM to generate intermediate tokens z using specific algorithms, then return output y:
System 2 methods may involve multiple prompts, branching, iterations, and searches, while using LLM to generate intermediate results for further processing. In contrast, System 1 models only consider the raw input x and directly call LLM pθ to generate output y:
Method: System 2 Distillation
The first step of the method in this paper is to use the System 2 model to generate responses for unlabeled input X:
Then, these responses y^i_S_II can be directly used as the distillation target for fine-tuning the System 1 model. However, they are susceptible to noise: some of these responses may be of high quality, while others may be of low quality or incorrect. For short question-and-answer and reasoning tasks involving short responses (usually with a unique correct but unknown answer), the researchers consider adopting unsupervised management steps to try to improve the quality of the training data. They considered the following two variants that rely on self-consistency criteria:
-
Output self-consistency: Sample S_II (x^i ; p_θ) a total of N times and accept the majority voting response; if there is no majority voting winner, discard the example.
-
Input perturbation self-consistency: Perturb input x^i in a way that keeps the output unchanged, such as changing the order of multiple-choice questions in the prompt, and compute S_II for each perturbation; if the output is inconsistent, discard the example.
Afterwards, the researchers obtained a synthetic dataset (X_S_II , Y_S_II), where X_S_II is a filtered subset of X, and the target is Y_S_II. The final step is to use this distilled training set to supervise fine-tune the LLM with parameters p_θ. The researchers typically initialize this model from the current state p_θ and then continue training with the new dataset. After fine-tuning, they obtain an LLM 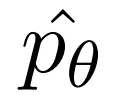 , which is a System 1 model expected to provide outputs and performance improvements similar to the evaluated System 2 model.
, which is a System 1 model expected to provide outputs and performance improvements similar to the evaluated System 2 model.
Experimental Results
Training and Evaluation Setup
The researchers used Llama-2-70B-chat as the base model for all experiments. They needed a base model with sufficient capability to operate as efficiently as the System 2 model while also having open weights that could be fine-tuned, hence this choice.
At the same time, the researchers considered several System 2 methods, including System 2 Attention, RaR, branch-solve-merge, and chain of thought, focusing on tasks where each method demonstrated strong performance.
For System 1, the researchers used the instruction-tuned base model as a standard baseline for zero-shot reasoning. They reported task-specific metrics for each task, along with the “#Tokens” metric, which measures the average number of tokens generated per input in the evaluation set. The System 2 methods included intermediate token generation as well as final output token generation.
Rephrase and Respond Distillation
RaR is a System 2 method that first prompts the language model to rephrase the original question in a more elaborative manner, then generates a response based on the rephrased question, aiming to provide better output.
For the distilled data, the researchers used output self-consistency to build the RaR System 2 distilled dataset. For each input, they performed eight sampling iterations on the last letter task, and similarly for each stage of the coin flip task, then used majority voting to determine the final output.
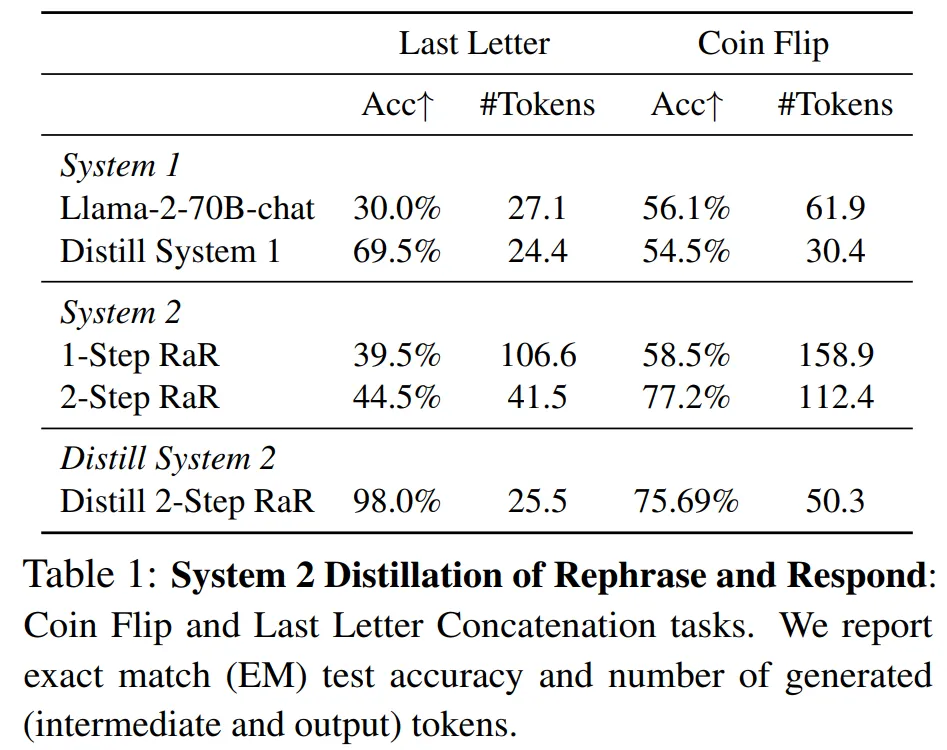
First, let’s look at Last Letter Concatenation Task. This task focuses on symbolic reasoning, requiring the model to concatenate the last letter of a given word. The overall results are shown in Table 1.
The baseline System 1 model (Llama-2-70B-chat) achieved an accuracy of 30.0%, lower than the System 2 1-Step and 2-Step RaR methods (39.5% and 44.5%, respectively). By distilling the 2-Step RaR method back to the System 1 Llama-2-70B-chat model using the unsupervised technique in this paper, an astonishing accuracy of 98.0% was achieved.
Compared to the zero-shot chat model, the model can effectively learn how to solve tasks from this training data. The distillation of RaR effectively inherits the advantages of both System 2 and System 1, retaining the accuracy advantage of System 2 while having reasoning costs comparable to System 1.
Next, let’s look at Coin Flip Reasoning Task. This symbolic reasoning task is frequently tested in research, involving determining the final face of a coin (heads or tails) starting from a known initial position, going through a series of flips described in natural language, such as “the coin is heads up”.
The overall results are shown in Table 1. Llama-2-70B-chat (zero-shot) had a success rate of 56.1% on this task, while the success rates for 1-Step and 2-Step RaR were 58.5% and 77.2%, respectively. Thus, the 2-Step method achieved significant improvement. By distilling the 2-Step RaR back to System 1 Llama-2-70B-chat using the unsupervised technique in this paper, a result of 75.69% was obtained.
Therefore, the performance provided by the distilled System 2 model is comparable to that of System 2 (2-Step RaR), but does not require executing the LLM program with 2 prompts.
System 2 Attention Distillation
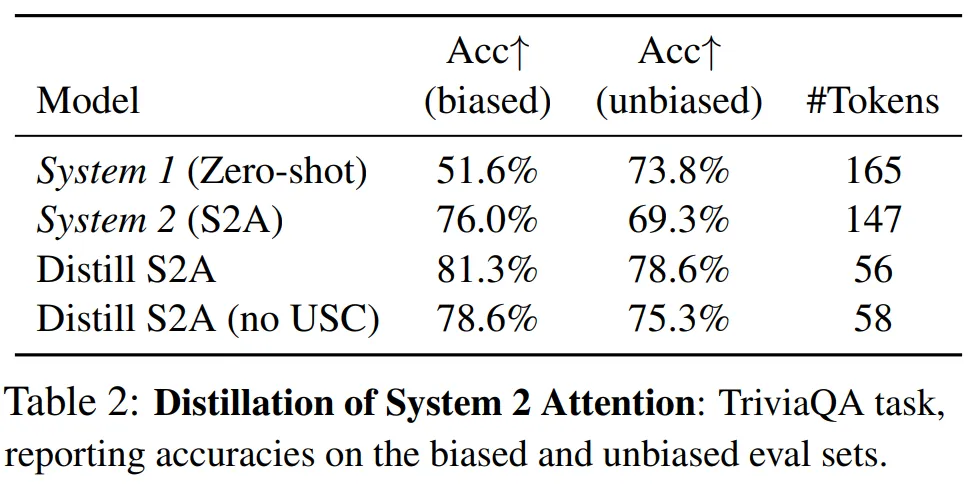
Weston and Sukhbaatar (2023) proposed System 2 Attention (S2A), which helps reduce reasoning pitfalls in the model, such as reliance on biased information in the input or focusing on irrelevant context.
The researchers validated the feasibility of distilling S2A into System 1, particularly for SycophancyEval question-answering tasks that contain biased information in the input known to degrade LLM performance.
The results are shown in Table 2, reporting the average accuracy across three random seeds. As expected, the baseline (System 1) LLM had lower accuracy on the biased portion, being easily influenced by biased inputs. S2A significantly improved performance on biased inputs. System 2 distillation exhibited robust performance similar to that of System 2 methods.
For more experimental results, please refer to the original paper.