
Follow our public account to discover the beauty of CV technology
Introduction
In Convolutional Neural Networks (CNN), convolution operations excel at extracting local features, but there are certain limitations in capturing global feature representations. In Vision Transformers, cascading self-attention modules can capture long-range feature dependencies but tend to overlook the details of local features.
This article proposes a hybrid network structure called Conformer, which leverages convolution operations and self-attention mechanisms to enhance feature representation learning. Conformer relies on Feature Coupling Units (FCU) to interactively fuse local feature representations and global feature representations at different resolutions. Additionally, Conformer adopts a parallel structure to maximize the retention of local features and global representations.
The authors demonstrate through experiments that, under similar parameters and complexity, Conformer outperforms DeiT-B by 2.3% on ImageNet. On the MS-COCO dataset, it surpasses ResNet-101 by 3.7% and 3.6% mAP on object detection and instance segmentation tasks, respectively.
Paper and Code Links

Paper: https://arxiv.org/abs/2105.03889 Code: https://github.com/pengzhiliang/ConformerMotivation
In computer vision tasks such as image classification, object detection, and instance segmentation, CNNs perform exceptionally well. This is largely attributed to convolution operations, which collect local features hierarchically for better image representation.
Despite their advantages in local feature extraction, CNNs still lack the ability to capture global representations, which is crucial for many high-level computer vision tasks. An intuitive solution is to enlarge the receptive field, but this would disrupt the operation of the pooling layers.

Recently, Transformer structures have been applied to visual tasks. The ViT method constructs a series of tokens by splitting each image into patches with positional embeddings, and then uses Transformer Blocks to extract parameterized vectors as visual representations. Due to the self-attention mechanism and multi-layer perceptron (MLP) structure, Vision Transformers can reflect complex spatial transformations and long-range feature dependencies, thereby obtaining global feature representations.
However, Vision Transformers tend to overlook local feature details, reducing the discernibility between background and foreground (as shown in the above images (c) and (g)). Therefore, some works have proposed a tokenization module or utilized CNN feature maps as input tokens to capture the neighboring information of features. However, these methods still do not fundamentally solve the relationship between local modeling and global modeling.
In this paper, the authors propose a dual-network structure called Conformer, which combines CNN-based local features with Transformer-based global representations to enhance representation learning. Conformer consists of a CNN branch and a Transformer branch, which are formed by a combination of local convolution blocks, self-attention modules, and MLP units. During training, the cross-entropy loss function is used to supervise the training of both the CNN and Transformer branches to obtain features that possess both CNN-style and Transformer-style characteristics.
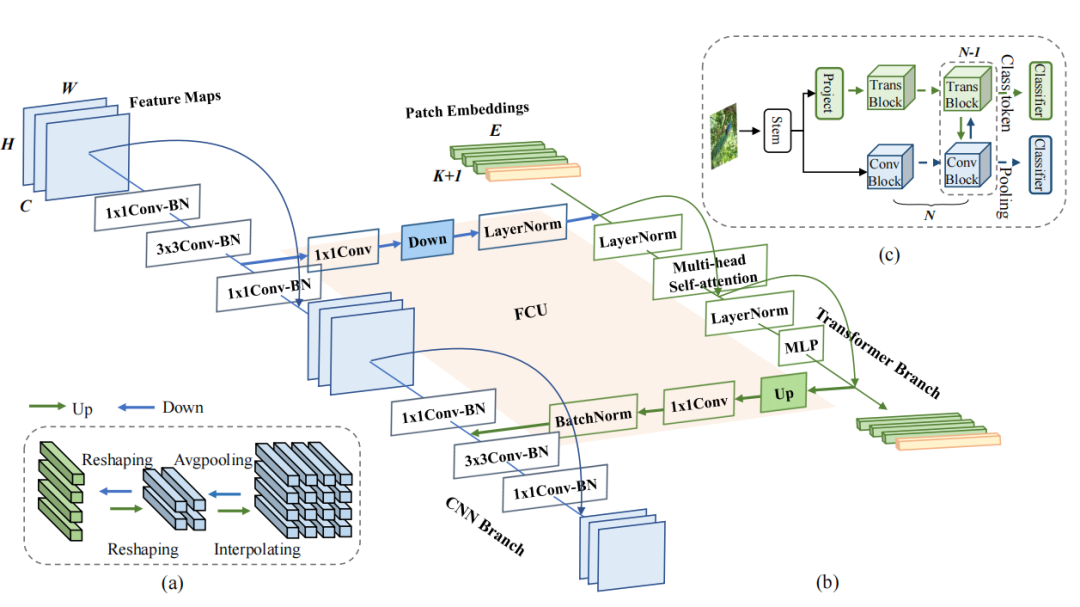
Considering the asymmetry between the features of CNN and Vision Transformer, the authors designed the Feature Coupling Unit (FCU) as a bridge between CNN and Vision Transformer. On one hand, to fuse the features of the two styles, the FCU utilizes 1×1 convolutions to align channel sizes, down/up-sampling strategies to align feature resolutions, and LayerNorm and BatchNorm to align feature values.
On the other hand, since the CNN and Vision Transformer branches tend to capture different levels of features (local and global), the FCU is inserted into each block to continuously interactively eliminate the semantic differences between them. This fusion process can greatly enhance the global perception ability of local features and the local detail of global representations.
As shown in the above images, the feature representations of each branch of Conformer are better than those obtained by using CNN or Transformer structures alone. Traditional CNNs tend to retain distinguishable local areas, while the CNN branch of Conformer can also activate the full extent of objects. The features from the Vision Transformer struggle to differentiate between objects and backgrounds, while the Conformer branch captures local detail information more effectively.
Method
3.1. Overview
Local features and global features have been extensively studied in computer vision tasks. Local features are compact vector representations of local image neighborhoods and have always been a component of many computer vision algorithms. Global representations include contour representations, shape descriptors, and long-distance object representations, etc.
In deep learning, CNNs collect local features hierarchically through convolution operations, retaining local cues as features. Vision Transformers are considered to aggregate global representations in a soft manner between compressed patch embeddings through cascading Self-Attention modules.
To leverage local features and global representations, the authors designed a concurrent network structure called Conformer, as shown in the above image (c). Considering the complementarity of the two features, the authors send the global features from the Vision Transformer branch into the CNN to enhance the global perception ability of the CNN branch.
Similarly, local features from the CNN branch are sent into the Vision Transformer to enhance the local perception ability of the Vision Transformer branch. This process constitutes the interaction effect.

Specifically, Conformer consists of a stem module, dual branches, the FCU bridging the two branches, and classifiers (FC) on each branch. The stem module is a 7×7 convolution with a stride of 2 and a 3×3 max pooling with a stride of 2, used to extract initial local features, which are then sent to the two branches. The CNN and Transformer branches consist of N repeated convolution and Transformer blocks, respectively (specific settings are as shown in the above table).
This concurrent structure means that the CNN and Transformer branches can respectively maximize the retention of local features and global representations. The FCU is proposed as a bridging module to fuse the local features of the CNN branch with the global representations of the Transformer branch, as shown in the above image (b). Along these branch structures, the FCU will interactively and progressively fuse feature maps and patch embeddings.
Finally, for the CNN branch, all features are merged and then input to a classifier. For the Transformer branch, the [cls] token is extracted and sent to another classifier for classification. During training, the authors use two cross-entropy losses to supervise these two classifiers separately. The importance weights of the loss functions are set to be the same. During inference, the authors simply add the outputs of these two classifiers as the prediction results.
3.2. Network Structure
3.2.1. CNN Branch
As shown in the above image (b), the CNN branch adopts a feature pyramid structure, where the resolution of feature maps decreases with increasing network depth, while the number of channels increases with increasing network depth. The authors divide the entire CNN branch into four stages (as shown in the above table). Each stage consists of multiple convolution blocks, with each convolution block containing a bottleneck. In the experiments, the first convolution block is set to 1, and in the subsequent N−1 convolution blocks, it is set to.
The Vision Transformer projects an image patch into a feature vector through a simple patch embedding step, leading to the loss of local details. However, in CNNs, the convolution kernel slides over overlapping feature maps, maximizing the retention of local features. Therefore, the CNN branch can continuously provide local feature details to the Transformer branch.
3.2.2. Transformer Branch
In the Transformer branch, there are N repeated Transformer blocks. As shown in the above image (b), each Transformer block consists of a Multi-head Self-Attention module and an MLP module, with LayerNorm applied for normalization in each layer’s Self-Attention and MLP blocks.
For tokenization, the authors compress the feature maps generated by the stem module in the CNN into non-overlapping patch embeddings of size 14×14 (through a 4×4 convolution with a stride of 4), then add a [cls] token for classification. Since the CNN branch (3×3 convolution) simultaneously encodes local features and spatial positional information, there is no need for position encoding here.
3.2.3. Feature Coupling Unit
How to eliminate the feature misalignment between the feature maps in the CNN branch and the patch embeddings in the Transformer branch is an important issue. To address this problem, the authors propose the FCU to continuously and interactively combine local features and global representations.
On one hand, the authors recognize that the feature dimensions of CNN and Transformer are inconsistent. The dimensions of CNN features are C×H×W (C, H, and W represent channels, height, and width, respectively), while the dimensions of Transformer patch embeddings are (K + 1) × E (K, 1, and E represent the number of image patches, the number of [cls] tokens, and embedding dimensions, respectively).
When inputting to the Transformer branch, it is first necessary to align the channel dimensions through 1×1 convolutions, followed by downsampling (as shown in the above image (a)). When sending from the Transformer branch to the CNN branch, it is also necessary to align the channel dimensions through 1×1 convolutions and perform upsampling (as shown in the above image (a)). Additionally, LayerNorm and BatchNorm are used for feature normalization.
On the other hand, there is a significant semantic gap between CNN features and Patch Embeddings, as CNN feature maps are obtained through local convolution operations, while Patch Embeddings are aggregated through a global self-attention mechanism. Therefore, the FCU is applied to each block to gradually fill the semantic information gap.
Experiments
4.1. Image Classification
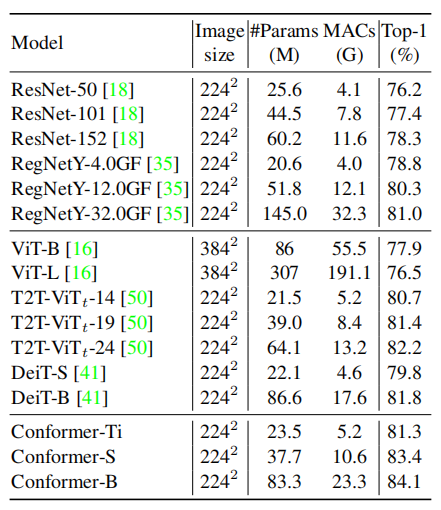
As shown in the above table, the performance of Conformer outperforms CNN and Vision Transformer under similar parameter counts and computational loads.
4.2. Object Detection and Instance Segmentation
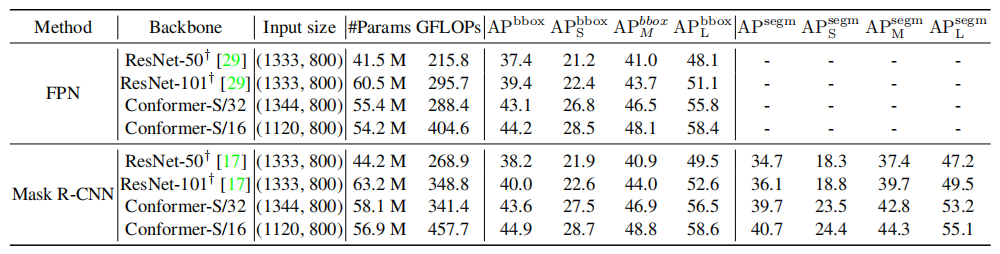
As shown in the above table, Conformer significantly improves performance in.
4.3. Ablation Studies
4.3.1. Number of Parameters.
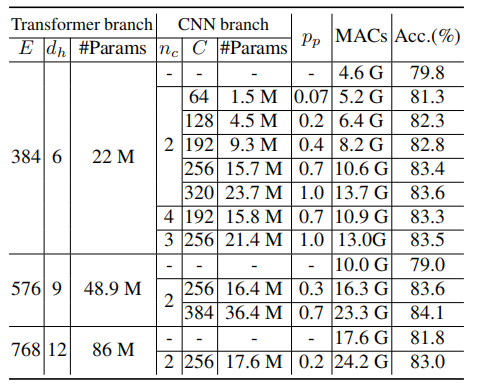
The above table shows the performance under different parameter counts. It can be seen that by increasing the parameter counts of either the CNN or Vision Transformer branches, accuracy can be improved.
4.3.2. Dual Structure
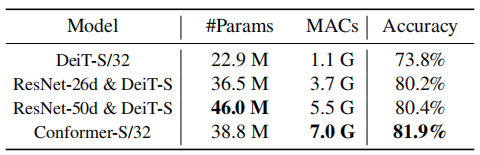
It can be seen that under comparable computational loads, Conformer-S/32 outperforms serial structures.
4.3.3. Positional Embeddings
When the Positional Embedding is removed, the accuracy of DeiT-S drops by 2.4%, while the accuracy of Conformer-S decreases slightly.
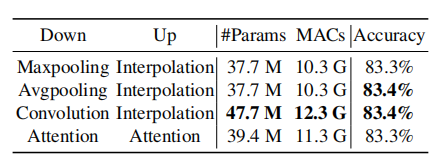
4.3.4. Sampling Strategies
The above table presents results of different up/down sampling strategies, including max-pooling, mean-pooling, convolution, and attention-based sampling.
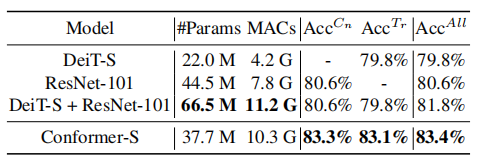
4.3.5. Comparison with Ensemble Models
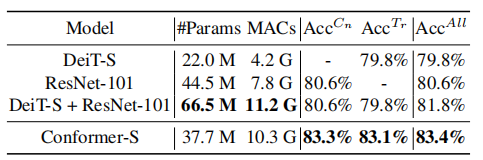
As shown in the above figure, the accuracy of the CNN branch, Transformer branch, and Conformer-S are 83.3%, 83.1%, and 83.4%, respectively. The accuracy of the ensemble model of CNN and Transformer is only 81.8%.
4.3.5. Generalization Capability
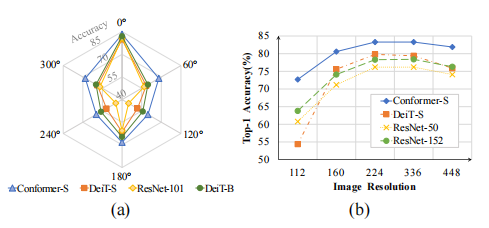
The above image illustrates the generalization performance of different models under various rotation angles and resolutions.
Conclusion
In this paper, the authors propose the first dual-backbone network that combines CNN with Vision Transformer, called Conformer. In Conformer, the authors utilize convolution operators to extract local features and self-attention mechanisms to capture global representations. Additionally, the authors design the Feature Coupling Unit (FCU) to fuse local features and global representations, thereby enhancing the capability of visual representation in an interactive manner.
Experiments show that Conformer outperforms traditional CNNs and Vision Transformers under similar parameters and computational loads. Conformer also demonstrates great potential to serve as a simple and effective backbone network across various downstream tasks.
▊ Author Biography
Master’s student of the 20th cohort in the Department of Artificial Intelligence at Xiamen University
Research area: Operator of the FightingCV public account, focusing on multimodal content understanding, with an emphasis on solving tasks that combine visual and linguistic modalities to promote the practical application of Vision-Language models.
Zhihu/Public Account: FightingCV
END, Join the group👇 Note:TFM
