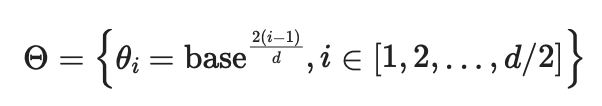MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, covering NLP master’s and doctoral students, university teachers, and corporate researchers.
The vision of the community is to promote communication and progress between the academic and industrial circles of natural language processing and machine learning at home and abroad, especially for beginners.
Reprinted from | Machine Heart
Ten days ago, at the Meta Connect 2024 conference, the open-source field welcomed the lightweight models Llama 3.2 1B and 3B that can run on edge and mobile devices. Both versions are pure text models but also have multilingual text generation and tool invocation capabilities. Meta stated that these models allow developers to build personalized, general applications that run locally on devices—such applications will have strong privacy since data does not need to leave the device.
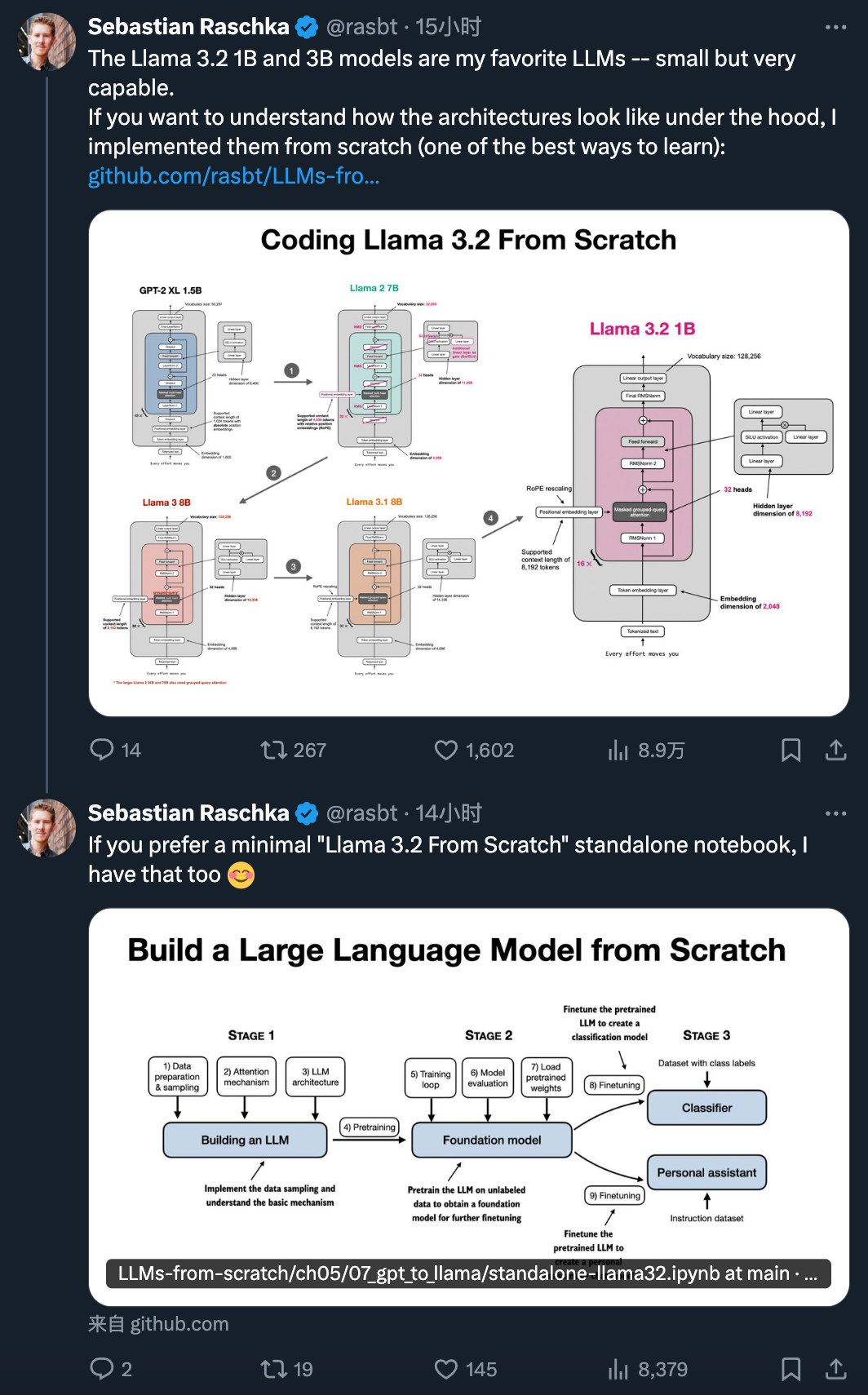
Recently, machine learning researcher Sebastian Raschka released a lengthy tutorial titled “Converting Llama 2 to Llama 3.2 From Scratch” at lightning speed.
-
Blog link: https://github.com/rasbt/LLMs-from-scratch/blob/main/ch05/07_gpt_to_llama/converting-llama2-to-llama3.ipynb
This article is a continuation of “Converting a From-Scratch GPT Architecture to Llama 2”, with updated content on how to gradually convert Meta’s Llama 2 architecture model to Llama 3, Llama 3.1, and Llama 3.2. To avoid unnecessary length, this article intentionally shortens the explanatory part and focuses on the main code.
Machine Heart has compiled the article content without changing its original meaning:
1 Step-by-Step Conversion of Llama Model Implementation
If you are implementing the LLM architecture for the first time, it is recommended to start with Chapter 4 of “Build a Large Language Model From Scratch” (https://github.com/rasbt/LLMs-from-scratch/blob/0972ded5309c25dc5eecc98b62897d677c6c36c4/ch04/01_main-chapter-code/ch04.ipynb), which will guide you step-by-step in implementing the original GPT architecture.
Then you can refer to “Converting a From-Scratch GPT Architecture to Llama 2” (https://github.com/rasbt/LLMs-from-scratch/blob/0972ded5309c25dc5eecc98b62897d677c6c36c4/ch05/07_gpt_to_llama/converting-gpt-to-llama2.ipynb), to implement Llama-specific components such as the RMSNorm layer, SiLU and SwiGLU activations, RoPE (Rotary Positional Embedding), and SentencePiece tokenizer.
This notebook adopts the Llama 2 architecture and converts it to the Llama 3 architecture in the following ways:
-
-
Implement grouped query attention
-
Use a customized GPT-4 tokenizer
Subsequently, we will load the original Llama 3 weights shared by Meta into the architecture:
1.1 Reusing Llama 2 Components
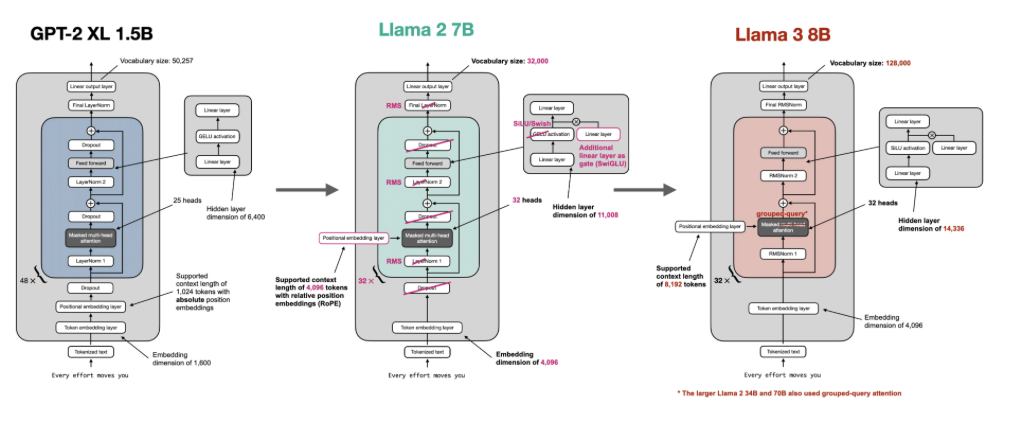
Llama 2 is actually very similar to Llama 3, as described above and shown in the images at the beginning of this article.
This means we can import multiple building blocks from the Llama 2 notebook using the following code:
import os
import sys
import io
import nbformat
import types
def import_from_notebook():
def import_definitions_from_notebook(fullname, names):
current_dir = os.getcwd()
path = os.path.join(current_dir, fullname + ".ipynb")
path = os.path.normpath(path)
# Load the notebook
if not os.path.exists(path):
raise FileNotFoundError(f"Notebook file not found at: {path}")
with io.open(path, "r", encoding="utf-8") as f:
nb = nbformat.read(f, as_version=4)
# Create a module to store the imported functions and classes
mod = types.ModuleType(fullname)
sys.modules[fullname] = mod
# Go through the notebook cells and only execute function or class definitions
for cell in nb.cells:
if cell.cell_type == "code":
cell_code = cell.source
for name in names:
# Check for function or class definitions
if f"def {name}" in cell_code or f"class {name}" in cell_code:
exec(cell_code, mod.__dict__)
return mod
fullname = "converting-gpt-to-llama2"
names = ["precompute_rope_params", "compute_rope", "SiLU", "FeedForward", "RMSNorm", "MultiHeadAttention"]
return import_definitions_from_notebook(fullname, names)
imported_module = import_from_notebook()
# We need to redefine precompute_rope_params
# precompute_rope_params = getattr(imported_module, "precompute_rope_params", None)
compute_rope = getattr(imported_module, "compute_rope", None)
SiLU = getattr(imported_module, "SiLU", None)
FeedForward = getattr(imported_module, "FeedForward", None)
RMSNorm = getattr(imported_module, "RMSNorm", None)
# MultiHeadAttention only for comparison purposes
MultiHeadAttention = getattr(imported_module, "MultiHeadAttention", None)
The RoPE used in Llama 3 is similar to that in Llama 2; see the RoPE paper (https://arxiv.org/abs/2104.09864).
However, there are some subtle differences in the RoPE settings between the two. Llama 3 now supports up to 8192 tokens, which is double that of Llama 2 (4096).
The base value of RoPE (see the formula below) has increased from 10000 (Llama 2) to 50000 (Llama 3), as shown in the following formula (adapted from the RoPE paper):
These values are a set of predefined parameters used to determine the rotation angles in the rotation matrix, where the dimensions correspond to the dimensions of the embedding space.
Increasing the base from 10000 to 50000 results in a slower decay rate of the frequency (or rotation angle) across the dimensions, meaning that the higher the dimension, the larger the angle (essentially decompressing the frequency).
Additionally, we have introduced a freq_config section in the code below to adjust the frequency; however, it is not needed in Llama 3 (only in Llama 3.1 and Llama 3.2), so we will revisit this freq_config later (default set to “none” and ignored).
import torch
def precompute_rope_params(head_dim, theta_base=10000, context_length=4096, freq_config=None):
assert head_dim % 2 == 0, "Embedding dimension must be even"
# Compute the inverse frequencies
inv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim // 2) / (head_dim // 2)))
################################ NEW ################################################
# Frequency adjustments
if freq_config is not None:
low_freq_wavelen = freq_config["original_context_length"] / freq_config["low_freq_factor"]
high_freq_wavelen = freq_config["original_context_length"] / freq_config["high_freq_factor"]
wavelen = 2 * torch.pi / inv_freq
inv_freq_llama = torch.where(wavelen > low_freq_wavelen, inv_freq / freq_config["factor"], inv_freq)
smooth_factor = (freq_config["original_context_length"] / wavelen - freq_config["low_freq_factor"]) / (freq_config["high_freq_factor"] - freq_config["low_freq_factor"])
smoothed_inv_freq = ((1 - smooth_factor) * (inv_freq / freq_config["factor"]) + smooth_factor * inv_freq)
is_medium_freq = (wavelen <= low_freq_wavelen) & (wavelen >= high_freq_wavelen)
inv_freq_llama = torch.where(is_medium_freq, smoothed_inv_freq, inv_freq_llama)
inv_freq = inv_freq_llama
#####################################################################################
# Generate position indices
positions = torch.arange(context_length)
# Compute the angles
angles = positions[:, None] * inv_freq[None, :] # Shape: (context_length, head_dim // 2)
# Expand angles to match the head_dim
angles = torch.cat([angles, angles], dim=1) # Shape: (context_length, head_dim)
# Precompute sine and cosine
cos = torch.cos(angles)
sin = torch.sin(angles)
return cos, sin
In summary, the new features of Llama 3 compared to Llama 2 are the “context length” and the theta base parameter:
# Instantiate RoPE parameters
llama_2_context_len = 4096
llama_3_context_len = 8192
llama_2_theta_base = 10_000
llama_3_theta_base = 50_000
In Llama 2, the usage remains the same:
# Settings
batch_size = 2
num_heads = 4
head_dim = 16
# Instantiate RoPE parameters
cos, sin = precompute_rope_params(head_dim=head_dim, theta_base=llama_3_theta_base, context_length=llama_3_context_len)
# Dummy query and key tensors
torch.manual_seed(123)
queries = torch.randn(batch_size, llama_3_context_len, num_heads, head_dim)
keys = torch.randn(batch_size, llama_3_context_len, num_heads, head_dim)
# Apply rotary position embeddings
queries_rot = compute_rope(queries, cos, sin)
keys_rot = compute_rope(keys, cos, sin)
1.3 Grouped Query Attention
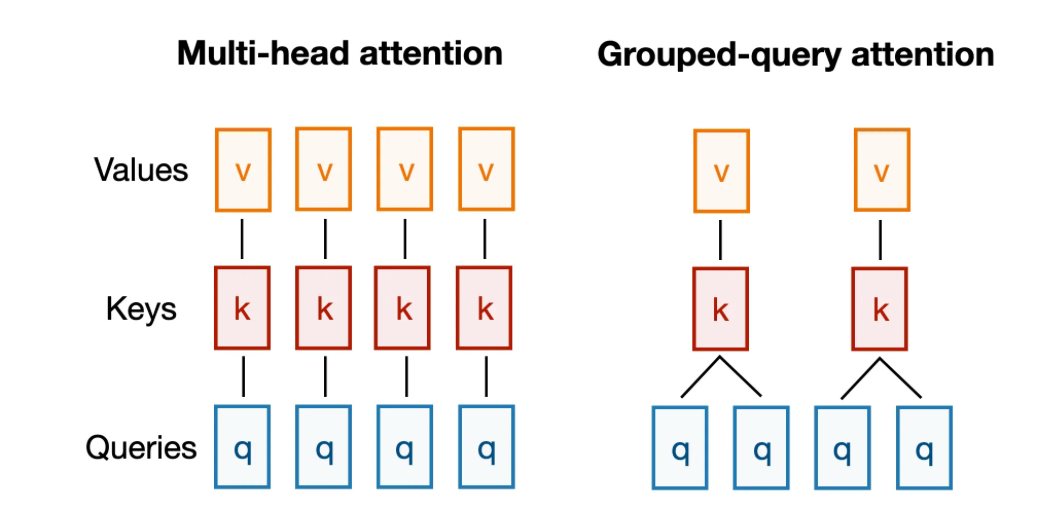
This section will replace multi-head attention (MHA) with an alternative mechanism called grouped query attention (GQA). In short, GQA can be seen as a more computationally and parameter-efficient version of MHA.
In GQA, the number of key and value projections is reduced by sharing them among multiple attention heads, where each attention head still has its unique query, but these queries focus on the same group of keys and values.
Here’s an example of GQA with 2 key-value groups:
The main idea of GQA is to reduce the number of unique query groups associated with key-value pairs, thereby reducing the size of certain matrix multiplications and the number of parameters in MHA without significantly degrading modeling performance.
In brief, the main change in GQA is that each query group needs to be repeated to match the number of heads associated with it, implemented as follows:
import torch.nn as nn
class GroupedQueryAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, num_heads,
num_kv_groups, # NEW
rope_base=10_000, # NEW
rope_config=None, # NEW
dtype=None):
super().__init__()
assert d_out % num_heads == 0, "d_out must be divisible by num_heads"
assert num_heads % num_kv_groups == 0, "num_heads must be divisible by num_kv_groups"
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads
############################# NEW #############################
# self.W_key = nn.Linear(d_in, d_out, bias=False, dtype=dtype)
# self.W_value = nn.Linear(d_in, d_out, bias=False, dtype=dtype)
self.W_key = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)
self.W_value = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)
self.num_kv_groups = num_kv_groups
self.group_size = num_heads // num_kv_groups
################################################################
self.W_query = nn.Linear(d_in, d_out, bias=False, dtype=dtype)
self.out_proj = nn.Linear(d_out, d_out, bias=False, dtype=dtype)
self.register_buffer("mask", torch.triu(torch.ones(context_length, context_length), diagonal=1))
cos, sin = precompute_rope_params(
head_dim=self.head_dim,
theta_base=rope_base, # NEW
freq_config=rope_config, # NEW
context_length=8192
)
self.register_buffer("cos", cos)
self.register_buffer("sin", sin)
def forward(self, x):
b, num_tokens, d_in = x.shape
queries = self.W_query(x) # Shape: (b, num_tokens, d_out)
keys = self.W_key(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)
values = self.W_value(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)
# Reshape queries, keys, and values
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
##################### NEW #####################
# keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
# values = values.view(b, num_tokens, self.num_heads, self.head_dim)
keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim)
values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim)
################################################
# Transpose keys, values, and queries
keys = keys.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)
values = values.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)
queries = queries.transpose(1, 2) # Shape: (b, num_query_groups, num_tokens, head_dim)
# Apply RoPE
keys = compute_rope(keys, self.cos, self.sin)
queries = compute_rope(queries, self.cos, self.sin)
##################### NEW #####################
# Expand keys and values to match the number of heads
# Shape: (b, num_heads, num_tokens, head_dim)
keys = keys.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)
values = values.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)
# For example, before repeat_interleave along dim=1 (query groups):
# [K1, K2]
# After repeat_interleave (each query group is repeated group_size times):
# [K1, K1, K2, K2]
# If we used regular repeat instead of repeat_interleave, we'd get:
# [K1, K2, K1, K2]
################################################
# Compute scaled dot-product attention (aka self-attention) with a causal mask
# Shape: (b, num_heads, num_tokens, num_tokens)
attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head
# Original mask truncated to the number of tokens and converted to boolean
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
# Use the mask to fill attention scores
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
assert keys.shape[-1] == self.head_dim
# Shape: (b, num_tokens, num_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2)
# Combine heads, where self.d_out = self.num_heads * self.head_dim
context_vec = context_vec.reshape(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec) # optional projection
return context_vec
For parameter savings, refer to the following multi-head attention example from GPT and Llama 2 code:
# Settings
batch_size = 1
context_len = 3000
max_context_len = 8192
embed_dim = 4096
num_heads = 32
example_batch = torch.randn((batch_size, context_len, embed_dim))
mha = MultiHeadAttention(d_in=embed_dim, d_out=embed_dim, context_length=max_context_len, num_heads=num_heads)
mha(example_batch)
print("W_key:", mha.W_key.weight.shape)
print("W_value:", mha.W_value.weight.shape)
print("W_query:", mha.W_query.weight.shape)
W_key: torch.Size([4096, 4096])
W_value: torch.Size([4096, 4096])
W_query: torch.Size([4096, 4096])
Now, if we switch to grouped query attention and use 8 kv groups (Llama 3 8B uses 8 kv groups), we can see that the number of rows in the key and value matrices is reduced by 4 times (since 32 attention heads divided by 8 kv groups equals 4):
gqa = GroupedQueryAttention(d_in=embed_dim, d_out=embed_dim, context_length=max_context_len, num_heads=num_heads, num_kv_groups=8, rope_base=llama_3_theta_base)gqa(example_batch)
print("W_key:", gqa.W_key.weight.shape)
print("W_value:", gqa.W_value.weight.shape)
print("W_query:", gqa.W_query.weight.shape)
W_key: torch.Size([1024, 4096])
W_value: torch.Size([1024, 4096])
W_query: torch.Size([4096, 4096])
By the way, to make grouped query attention equivalent to standard multi-head attention, the number of query groups (num_kv_groups) can be set equal to the number of heads (num_heads).
Finally, let’s compare the number of parameters below:
print("Total number of parameters:")
mha_total_params = sum(p.numel() for p in mha.parameters())
print(f"MHA: {mha_total_params:,}")
gqa_total_params = sum(p.numel() for p in gqa.parameters())
print(f"GQA: {gqa_total_params:,}")
Total number of parameters:
MHA: 67,108,864
GQA: 41,943,040
# Free up memory:
del mha
del gqa
1.4 Update TransformerBlock Module
Next, update the Transformer block. Here, we simply swap MultiHeadAttention with GroupedQueryAttention and add the new RoPE settings:
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = GroupedQueryAttention( # MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
context_length=cfg["context_length"],
num_heads=cfg["n_heads"],
num_kv_groups=cfg["n_kv_groups"], # NEW
rope_base=cfg["rope_base"], # NEW
rope_config=cfg["rope_freq"], # NEW
dtype=cfg["dtype"]
)
self.ff = FeedForward(cfg)
self.norm1 = RMSNorm(cfg["emb_dim"], eps=1e-5)
self.norm2 = RMSNorm(cfg["emb_dim"], eps=1e-5)
def forward(self, x):
# Shortcut connection for attention block
shortcut = x
x = self.norm1(x)
x = self.att(x.to(torch.bfloat16)) # Shape [batch_size, num_tokens, emb_size]
x = x + shortcut # Add the original input back
# Shortcut connection for feed-forward block
shortcut = x
x = self.norm2(x)
x = self.ff(x.to(torch.bfloat16))
x = x + shortcut # Add the original input back
return x
Fortunately, when setting up the model class, we don’t need to do much; we just need to update the name to Llama3Model
# class Llama2Model(nn.Module):
class Llama3Model(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"], dtype=cfg["dtype"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])]
)
self.final_norm = RMSNorm(cfg["emb_dim"], eps=1e-5)
self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False, dtype=cfg["dtype"])
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx)
x = tok_embeds
x = self.trf_blocks(x)
x = self.final_norm(x)
logits = self.out_head(x.to(torch.bfloat16))
return logits
2 Initialize Model
Now we can define a Llama 3 configuration file (for comparison, the Llama 2 configuration file is displayed):
LLAMA2_CONFIG_7B = {"vocab_size": 32_000, # Vocabulary size
"context_length": 4096, # Context length
"emb_dim": 4096, # Embedding dimension
"n_heads": 32, # Number of attention heads
"n_layers": 32, # Number of layers
"hidden_dim": 11_008, # Size of the intermediate dimension in FeedForward
"dtype": torch.bfloat16 # Lower-precision dtype to save memory}
LLAMA3_CONFIG_8B = {"vocab_size": 128_256, # NEW: Larger vocabulary size
"context_length": 8192, # NEW: Larger context length
"emb_dim": 4096, # Embedding dimension
"n_heads": 32, # Number of attention heads
"n_layers": 32, # Number of layers
"hidden_dim": 14_336, # NEW: Larger size of the intermediate dimension in FeedForward
"n_kv_groups": 8, # NEW: Key-Value groups for grouped-query attention
"rope_base": 50_000, # NEW: The base in RoPE's "theta" was increased to 50_000
"rope_freq": None, # NEW: Additional configuration for adjusting the RoPE frequencies
"dtype": torch.bfloat16 # Lower-precision dtype to save memory}
Using these settings, we can now initialize the Llama 3 8B model.
Note that this requires about 34 GB of memory (for comparison, Llama 2 7B requires about 26 GB of memory)
model = Llama3Model(LLAMA3_CONFIG_8B)
total_params = sum(p.numel() for p in model.parameters())
print(f"Total number of parameters: {total_params:,}")
Total number of parameters: 8,030,261,248
As shown above, the model contains 8 billion parameters. Additionally, we can use the code below to calculate the memory requirements of this model:
def model_memory_size(model, input_dtype=torch.float32):
total_params = 0
total_grads = 0
for param in model.parameters():
# Calculate total number of elements per parameter
param_size = param.numel()
total_params += param_size
# Check if gradients are stored for this parameter
if param.requires_grad:
total_grads += param_size
# Calculate buffer size (non-parameters that require memory)
total_buffers = sum(buf.numel() for buf in model.buffers())
# Size in bytes = (Number of elements) * (Size of each element in bytes)
# We assume parameters and gradients are stored in the same type as input dtype
element_size = torch.tensor(0, dtype=input_dtype).element_size()
total_memory_bytes = (total_params + total_grads + total_buffers) * element_size
# Convert bytes to gigabytes
total_memory_gb = total_memory_bytes / (1024**3)
return total_memory_gb
print(f"float32 (PyTorch default): {model_memory_size(model, input_dtype=torch.float32):.2f} GB")
print(f"bfloat16: {model_memory_size(model, input_dtype=torch.bfloat16):.2f} GB")
float32 (PyTorch default): 68.08 GB
bfloat16: 34.04 GB
Finally, if applicable, we can also transfer the model to NVIDIA or Apple Silicon GPUs:
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
model.to(device);
3 Load Tokenizer
In this section, we will load the tokenizer for the model.
Llama 2 used Google’s SentencePiece tokenizer instead of OpenAI’s BPE tokenizer based on the Tiktoken library. However, Llama 3 reverts to using Tiktoken’s BPE tokenizer; specifically, it uses the GPT-4 tokenizer with an extended vocabulary. We can find the original Tiktoken adapter in Meta AI’s official Llama 3 repository.
Below is the rewritten tokenizer code to make it more readable and suitable for this notebook (but the performance should be similar):
import os
from pathlib import Path
import tiktoken
from tiktoken.load import load_tiktoken_bpe
class Tokenizer:
def __init__(self, model_path):
assert os.path.isfile(model_path), f"Model file {model_path} not found"
mergeable_ranks = load_tiktoken_bpe(model_path)
num_base_tokens = len(mergeable_ranks)
self.special_tokens = {
"<|begin_of_text|>": 128000,
"<|end_of_text|>": 128001,
"<|start_header_id|>": 128006,
"<|end_header_id|>": 128007,
"<|eot_id|>": 128009,
}
self.special_tokens.update({
f"<|reserved_{i}|>": 128002 + i for i in range(256) if (128002 + i) not in self.special_tokens.values()
})
self.model = tiktoken.Encoding(
name=Path(model_path).name,
pat_str=r"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^
ext{L} ext{N}]? ext{L}+| ext{N}{1,3}| ?[^ ext{s} ext{L} ext{N}]+[
]*| ext{s}+(?! ext{S})| ext{s}+",