
Introduction
Recently, Andrew released a brand new video tutorial that details the entire process of pretraining GPT-2 from scratch. This four-hour video covers model construction, loading training data, evaluation methods, and DDP training in a distributed framework. Inspired by this video, I decided to use the LLaMA3 architecture to pretrain a large language model from scratch and compare the performance improvements under different model parameters. All related code will be open-sourced at:
https://github.com/hengjiUSTC/learn-llm/tree/main/pretrain
Next, let’s get straight to the point.
Model Construction and Evaluation
To have a reference effect and ensure the correctness of the LLaMA model that we will implement from scratch, we first evaluate the model using HellaSwag by loading Huggingface’s official LLaMA3 model.
The code is open-sourced at:
https://github.com/hengjiUSTC/learn-llm/blob/main/pretrain/play_with_llama.ipynb
Model Loading

HellaSwag Evaluation
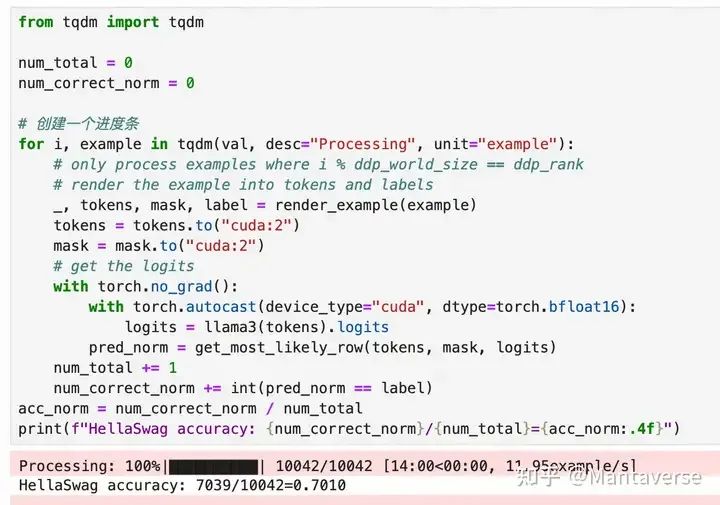
We can see that the original LLaMA3-8B model scored 70 points. This result is consistent with the officially released model results:
https://paperswithcode.com/sota/sentence-completion-on-hellaswag
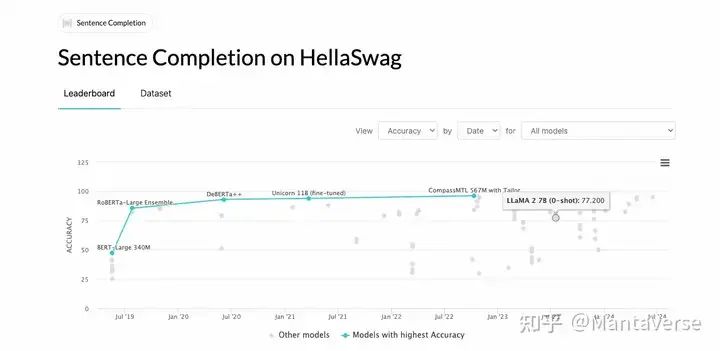
With this benchmark, we can start implementing our own LLaMA model from scratch.
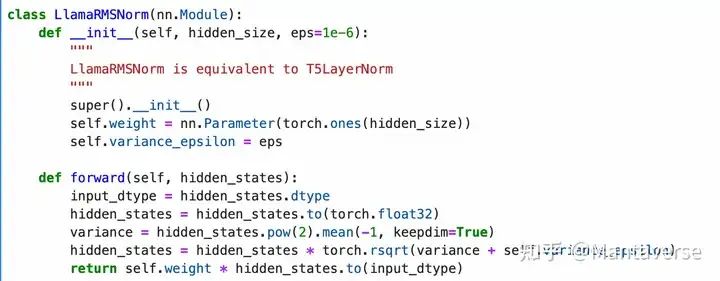
RMSNorm Layer
RMSNorm (Root Mean Square Normalization) is a normalization method used to stabilize and accelerate the training process.
-
• Input:
A tensor with shape (batch_size, sequence_length, hidden_dim) representing the input hidden state.
-
• Output:
A tensor with the same shape as the input, but each hidden state is normalized.
-
• Function:
RMSNorm normalizes the input by calculating the root mean square value of each element in the input tensor and using it for normalization. This effectively controls the output range of each layer, preventing gradient explosion or disappearance.
RotaryEmbedding
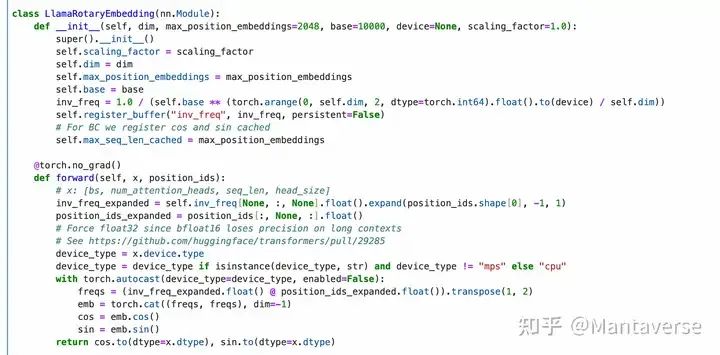
RotaryEmbedding is a positional encoding technique used to introduce positional information.
-
Input:
A tensor with shape (batch_size, sequence_length, hidden_dim) representing the input query (q) or key (k) vectors.
-
Output:
A tensor with the same shape as the input, but each vector is processed with rotational encoding.
-
Function:
By generating rotation vectors corresponding to position IDs, RotaryEmbedding can introduce positional information without explicitly using positional encoding, allowing the model to better understand the positional information in the sequence.
Essentially, RotaryEmbedding generates a set of rotation vectors corresponding to position IDs, representing how data at different positions should be rotated.
Attention Layer
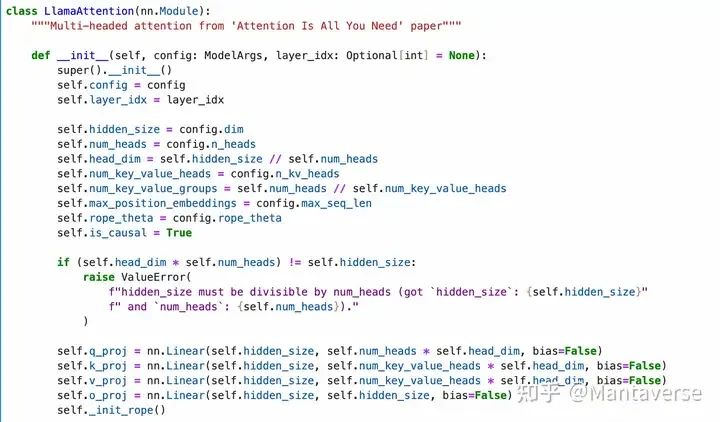
The Attention Layer is used to calculate the relevance of each element in the input sequence and weight the input based on that relevance.
-
Input:
A tensor with shape (batch_size, sequence_length, hidden_dim) representing the input hidden state.
-
Output:
A tensor with shape (batch_size, sequence_length, hidden_dim) representing the output processed by the attention mechanism.
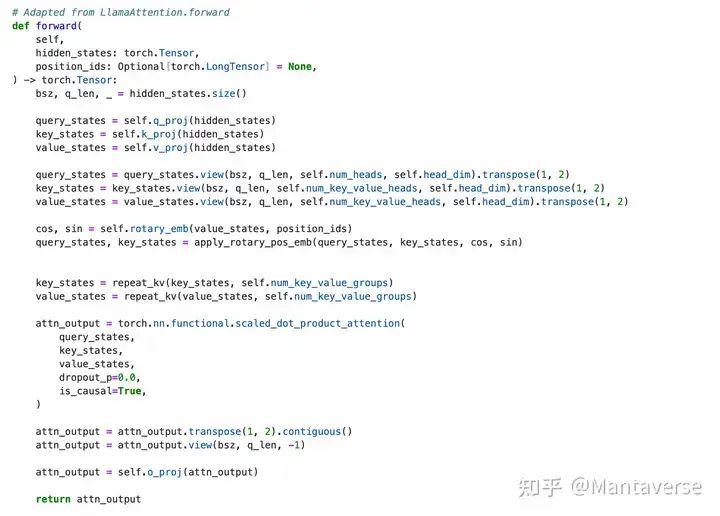
Calculation Process:
-
• Projection: The input data is linearly projected using q_proj, k_proj, and v_proj to generate query, key, and value vectors.
-
• Rotational Projection: Queries and keys undergo rotational projection to introduce positional information.
-
• Calculate Attention Values: The attention values are calculated using the dot product of the query and key vectors (q @ k.transpose()).
-
• Weighted Sum: The value vectors are weighted and summed using the attention values.
-
• Linear Projection: Finally, the results are output through o_proj linear projection.
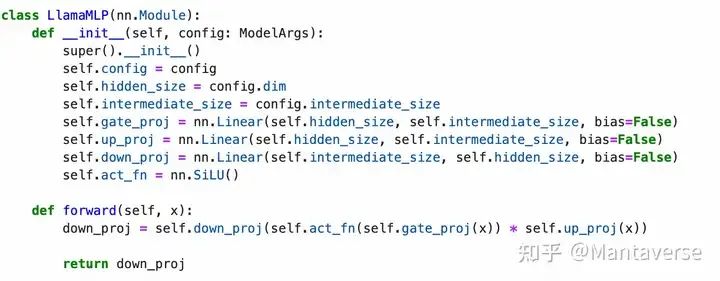
MLP
The MLP layer (Multi-Layer Perceptron) is used for nonlinear transformations of the input.
-
• Input:
A tensor with shape (batch_size, sequence_length, hidden_dim) representing the hidden state processed by Attention.
-
• Output:
A tensor with shape (batch_size, sequence_length, hidden_dim) representing the output after nonlinear transformation.
-
• Function:
The MLP layer usually consists of two linear projections and a nonlinear activation function (such as SiLU) to enhance the model’s expressiveness. The specific steps are:
-
• The input is passed through the first linear projection to generate an intermediate representation.
-
• The intermediate representation is activated using the SiLU activation function.
-
• The activated representation is passed through the second linear projection to generate the final output.
Block Assembly
Completing an assembly involves a residual connection aimed at improving the quality and efficiency of gradient propagation.

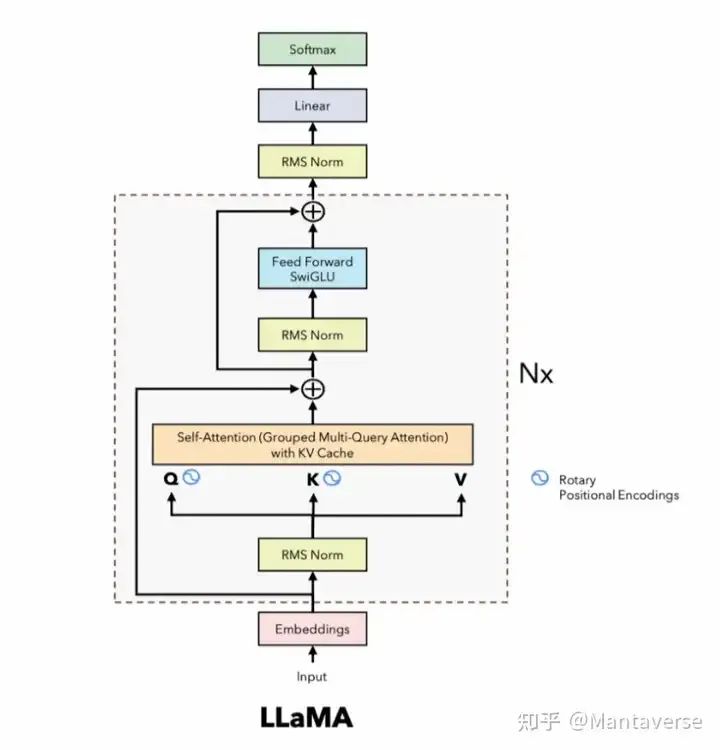
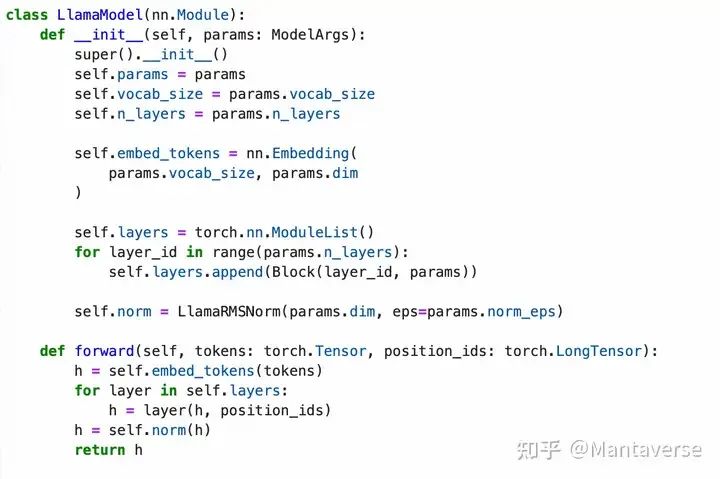
Overall Model Structure
The final LLaMA3 model structure includes:
-
• Input embedding layer, converting input vocabulary to hidden states.
-
• Multiple repeated Blocks, each containing RMSNorm layer, RotaryEmbedding layer, Attention Layer, and MLP layer.
-
• Output linear layer, converting hidden states to output.
Through this structure, the model can process input data layer by layer and gradually generate the final prediction results.
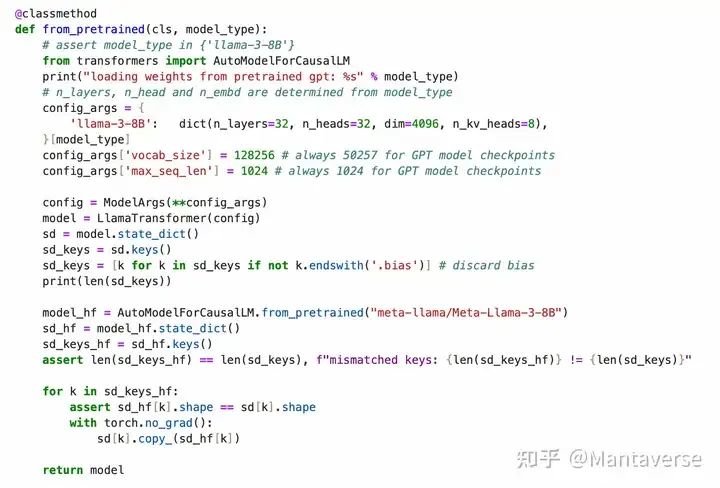
After the entire process, we need to verify the correctness of the model construction. We will copy all parameters of Huggingface’s LLaMA3 model into our model and then evaluate whether our own LLaMA3 model can achieve the same effect through HellaSwag.
When initializing our llama3 model, we copy the weights of the original llama3 model from huggingface.
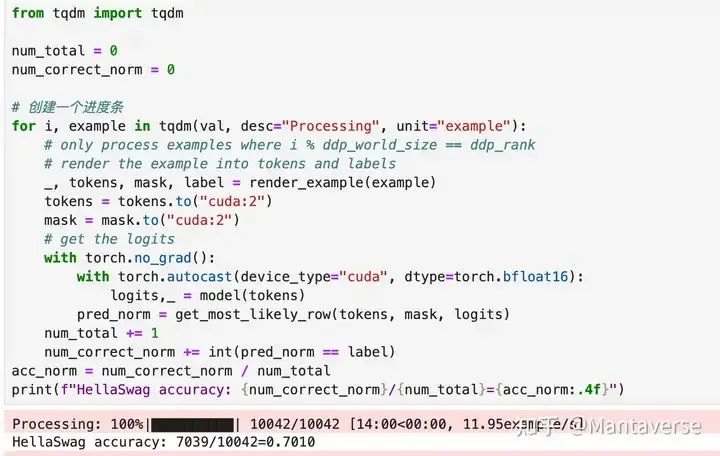
Through evaluation, we found that the scores were completely consistent with the Huggingface model! This proves that our implementation is correct.
Pretraining from Scratch
To pretrain the model, we used FineWeb’s 10TB data for training, with a training duration of one epoch. To accommodate the pretraining scenario, we created a custom data Dataloader and accelerated training through DDP (Distributed Data Parallel). Otherwise, the training process would consume a lot of time.
The training code is open-sourced at:
https://github.com/hengjiUSTC/learn-llm/blob/main/pretrain/train_llama.py
Using Multiple GPUs for Parallel Training
To utilize multiple GPUs for parallel training, we used the DDP module provided by PyTorch to load the model onto multiple GPUs for parallel training.
DDP (Distributed Data Parallel): DDP is a commonly used distributed training module in PyTorch, used for parallel training of models across multiple GPUs. DDP achieves parallel accelerated training by running a training process on each GPU and synchronizing parameters after each gradient computation. The problems solved by DDP include:
-
• Data Parallelism: Splitting data into multiple batches, distributing them to different GPUs for parallel processing, thus improving training speed.
-
• Gradient Synchronization: Synchronizing parameters of each GPU after each gradient update to ensure model consistency.
First, we need to initialize the DDP environment. For the machine number specified when we run the code
torchrun --standalone --nproc_per_node=4 train_llama.pyPyTorch will automatically allocate the corresponding environment variables to each training subprocess.
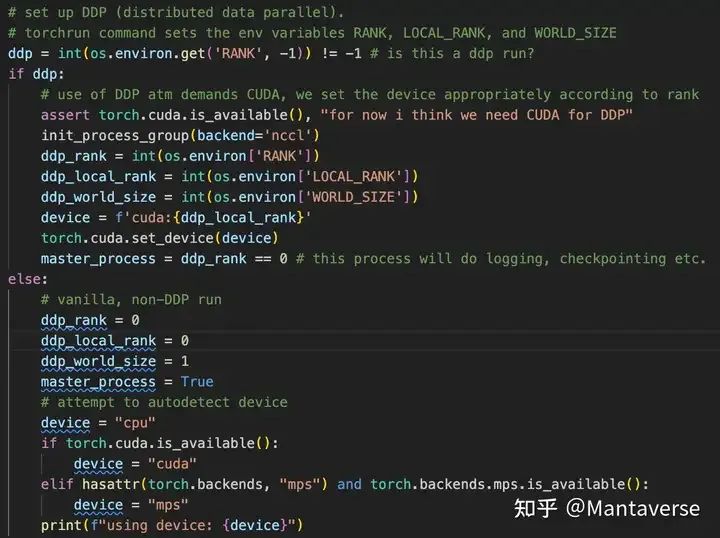
After loading the model, use DDP to wrap the model

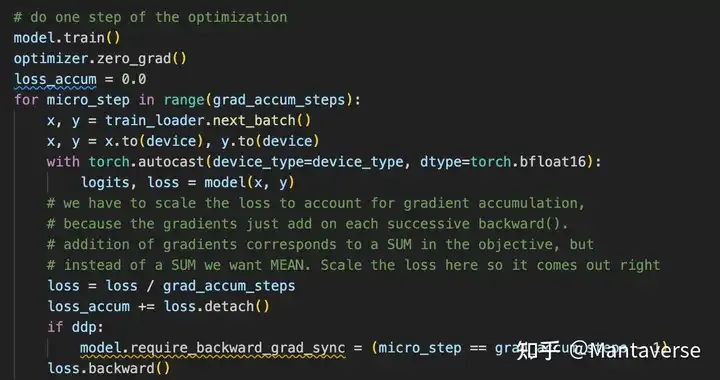
During the training phase, we can build the code in the same way as training a single model. After obtaining the loss, use loss.backward() to accumulate gradients. The require_backward_grad_sync here essentially optimizes training speed by reducing gradient synchronization across GPUs when the gradient accumulation step is not 1.
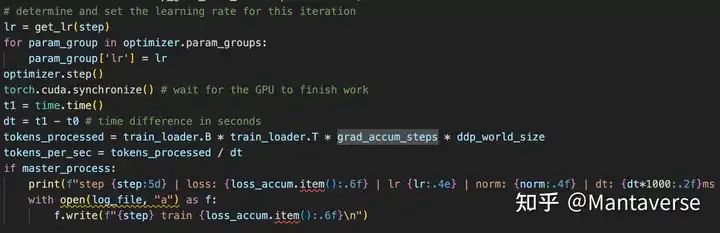
Subsequently, continue to use the optimizer to iterate the model weights. The purpose of using torch.cuda.synchronize() is to synchronize parallel GPUs so that all GPUs complete this round of training during each iteration.
Since we are using multi-GPU training, we need to adjust the DataLoader to ensure that each GPU receives different training data. Our DataLoader will load data using the method of B * T * self.process_rank based on the GPU number. For example, if we have 4 GPUs, the 0th DataLoader loads data from chunks 0, 4, 8, 12, while the 1st GPU loads from chunks 1, 5, 9, 13, and so on.
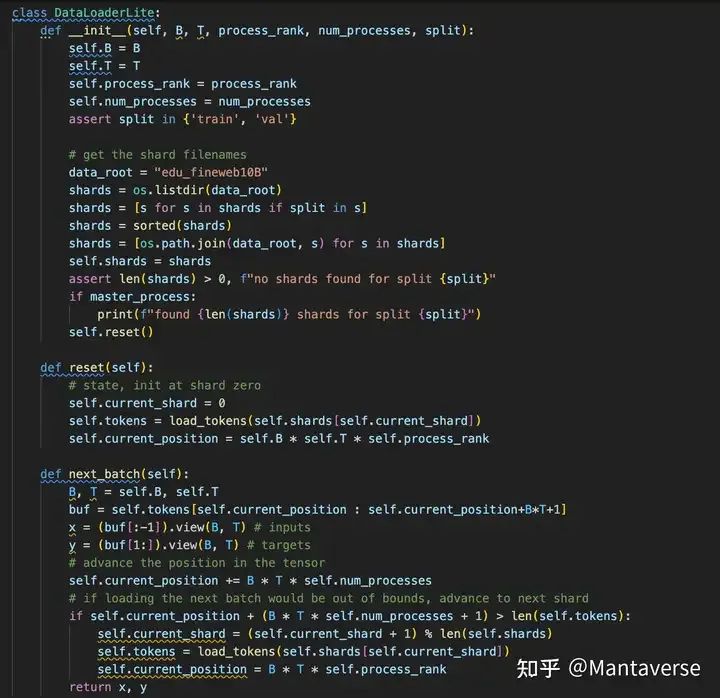
With this structure, we can start training. Of course, don’t forget to generate the 10TB training data we need in advance through the fineweb.py script.
Training Results
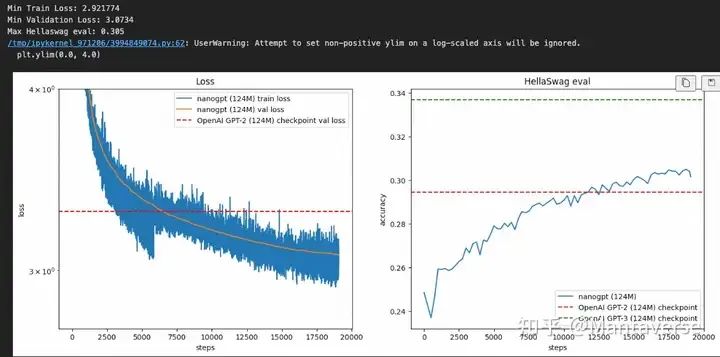
In the comparison, we first compared with Andrew’s GPT-2 demo. Under the same model configuration (12 layers, 12 heads), after training for one epoch on FineWeb data, Andrew’s GPT-2 model achieved a training loss of 2.9, surpassing the original version of GPT-2 from OpenAI. Meanwhile, in the HellaSwag evaluation task, the model scored 0.305, also exceeding GPT-2’s 0.294, but still not reaching GPT-3’s 0.337. We believe that the FineWeb dataset played an important role; its quality has surpassed that of the training data for GPT-2, but there is still a gap compared to GPT-3.
For our own LLaMA architecture model, the training results are as follows: under the same configuration of 12 layers and 12 heads, after one epoch of training, the LLaMA3 architecture scored better than Andrew’s GPT-2, with a training loss of 0.269 (Andrew’s GPT-2 was 0.29), and a HellaSwag score of 0.33 (Andrew’s GPT-2 was 0.305), getting closer to GPT-3. We believe this is mainly due to the quality of the FineWeb dataset, which, although not as good as GPT-3, benefits from the LLaMA architecture’s use of Rotary Position Embedding, while GPT-2 uses Learnable Position Embedding.
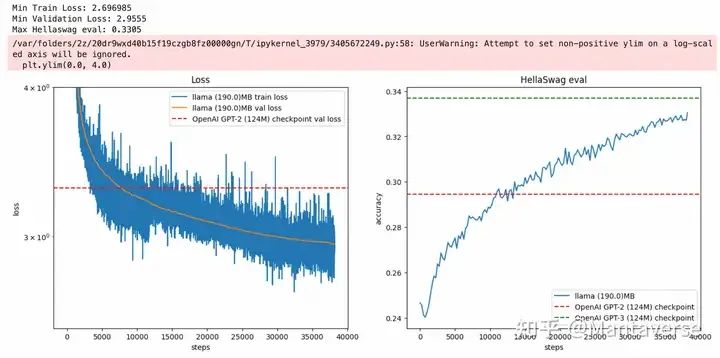
Training results of the same scale LLaMA3 architecture
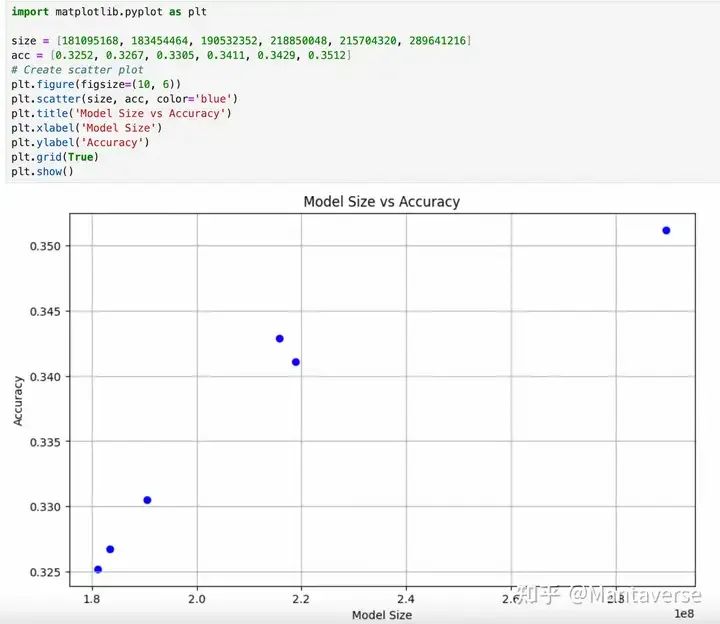
Further testing the effects of models of different sizes can give us a glimpse into the Scaling Law. The following figure shows the HellaSwag performance under the same training configuration for different model parameter sizes. It can be seen that when the model parameter size is small, architectural details are not very important; larger model parameter sizes yield better training results. In cases where parameter sizes are close, a more reasonable architecture may yield subtle differences. However, the current industry trend still tends to enhance LLM capabilities through larger-scale models. I also believe that over-optimizing architecture on small-scale models is less effective than seeking more fundamental research directions.
Conclusion
In this exploration, we pretrained a language model from scratch. Although there are many knowledge points involved in this article that are not explained in detail, I will release more related practical articles in the future to supplement these contents.
-
• DDP training and FSDP and TP: We discussed how to use DDP for training. I made simple adjustments to the DDP llama training code, and there is an FSDP implementation [1]. FSDP greatly reduces the memory usage of each GPU through model sharding. Additionally, there are large-scale concurrent training structures such as TP (Tensor Parallelism) that can significantly enhance training efficiency and model scale.
-
• MoE models and multimodal models: There have been many new developments in MoE (Mixture of Experts) models and multimodal models, which is also a very interesting discussion direction. We can further explore the applications and optimizations of these models through practice.
Reference Links
[1] FSDP implementation: https://github.com/hengjiUSTC/learn-llm/blob/main/pretrain/train_llama_fsdp.py

Scan the QR code to add the assistant on WeChat
About Us
