
Follow our WeChat public account to discover the beauty of CV technology
This article is reprinted from Machine Heart.
After an unexpected leak two days in advance, Llama 3.1 was officially released by Meta last night.
Llama 3.1 has extended the context length to 128K, with three versions: 8B, 70B, and 405B, once again raising the competitive standards in the large model arena.
For the AI community, the significance of Llama 3.1 405B is that it refreshes the capability ceiling of open-source foundational models. Meta claims that its performance can compete with the best closed-source models across a range of tasks.
The table below shows the performance of the current Llama 3 series models on key benchmark tests. It can be seen that the performance of the 405B model is very close to GPT-4o.
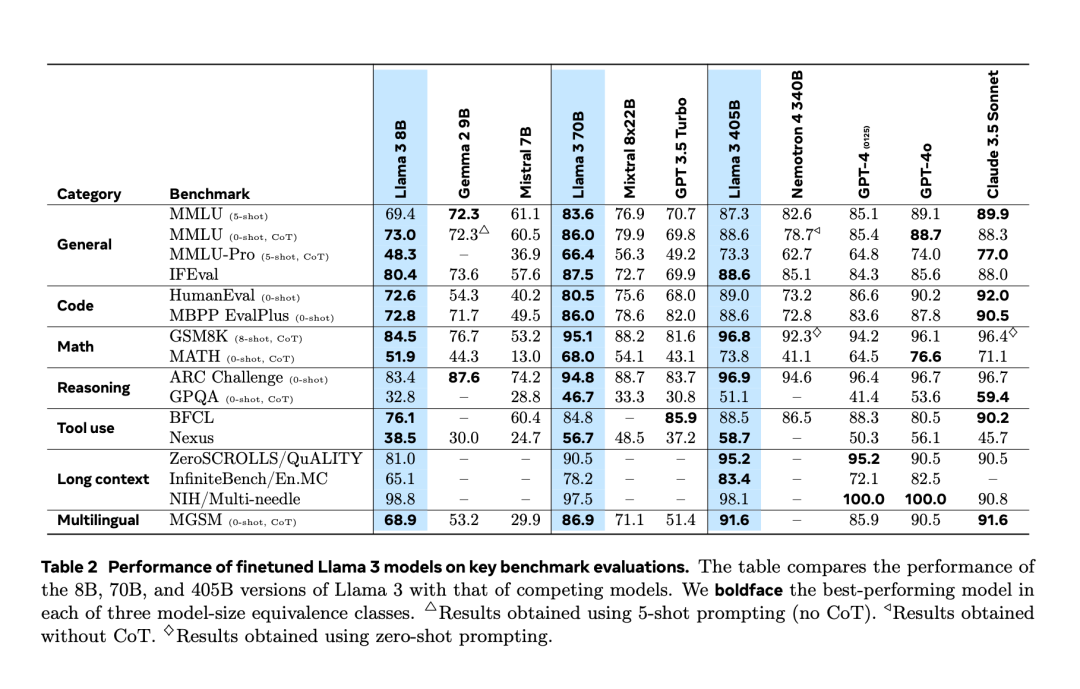
Meanwhile, Meta released the paper “The Llama 3 Herd of Models”, revealing the research details of the Llama 3 series models to date.

Paper link: https://ai.meta.com/research/publications/the-llama-3-herd-of-models/
Next, let’s take a look at the content of the paper.
Highlights of the Llama 3 Paper
1. After pre-training with an 8K context length, Llama 3.1 405B continues training with a 128K context length, supporting multilingual capabilities and tool usage.
2. Compared to previous Llama models, Meta has strengthened the curation pipelines for pre-processing and pre-training data, as well as the quality assurance and filtering methods for post-training data.
Meta believes that the development of high-quality foundational models has three key levers: data, scale, and complexity management.
First, compared to earlier versions of Llama, Meta has improved both the quantity and quality of data used for pre-training and post-training. Llama 3 was pre-trained on approximately 15 trillion multilingual token corpora, while Llama 2 only used 1.8 trillion tokens.
The scale of the model trained this time far exceeds that of previous Llama models: the flagship language model used 3.8 × 10²⁵ floating point operations (FLOPs) for pre-training, nearly 50 times more than the largest version of Llama 2.
Based on scaling laws, under Meta’s training budget, the current flagship model is approximately computationally optimal in scale, but the training time for smaller models has already far exceeded the computationally optimal duration. The results show that these smaller models perform better under the same inference budget than the computationally optimal models. In the post-training phase, Meta further improved the quality of the 70B and 8B smaller models using the 405B flagship model.
3. To support large-scale production inference with the 405B model, Meta quantized 16-bit (BF16) to 8-bit (FP8), thereby reducing computational requirements and enabling the model to run on a single server node.
4. Pre-training the 405B model on 15.6T tokens (3.8×10²⁵ FLOPs) was a significant challenge. Meta optimized the entire training stack and utilized over 16K H100 GPUs.
As Soumith Chintala, the founder of PyTorch and an outstanding engineer at Meta, stated, the Llama 3 paper reveals many cool details, one of which is the infrastructure building.
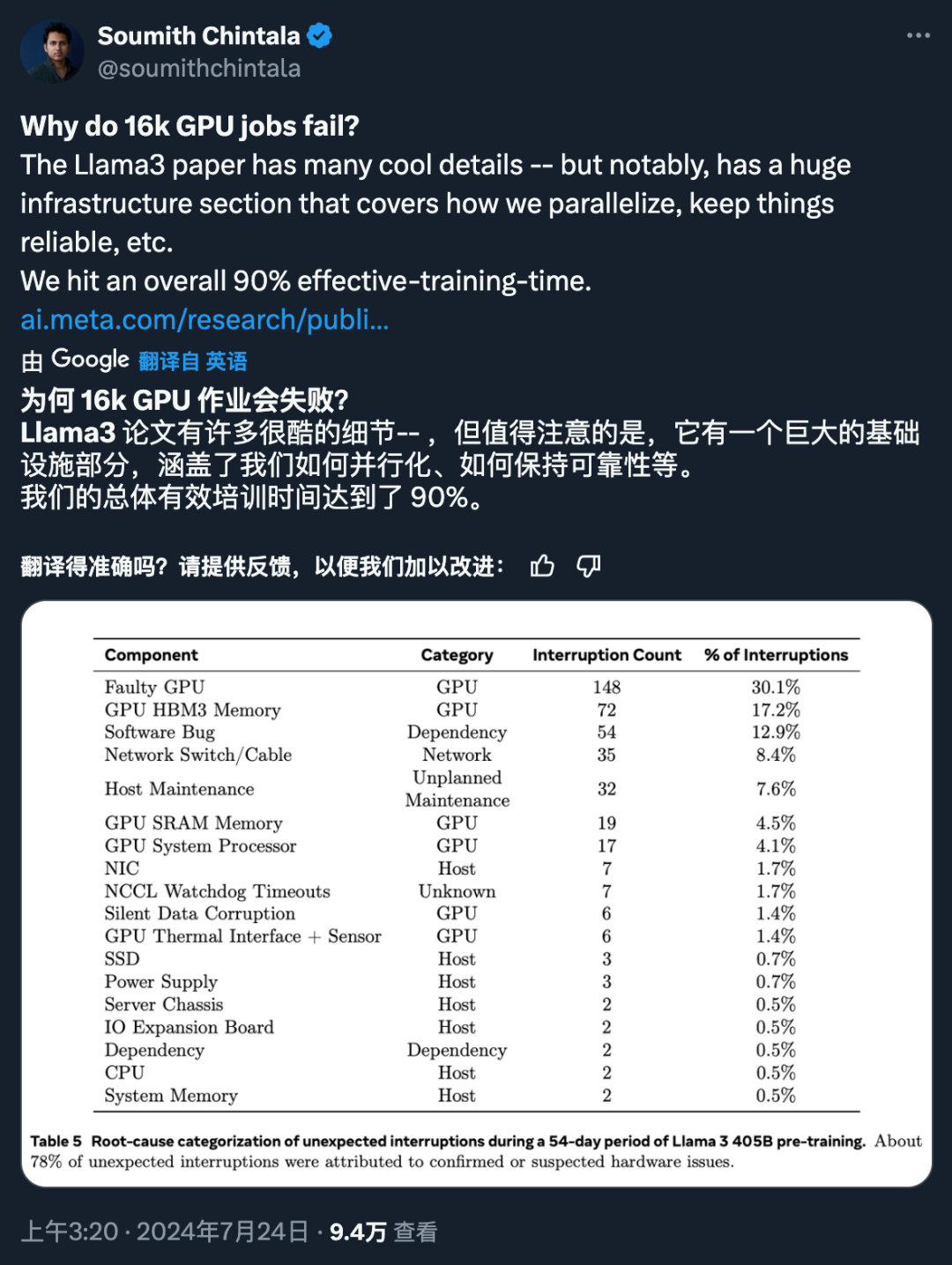
5. In the post-training phase, Meta refined the Chat model through multiple rounds of alignment, including supervised fine-tuning (SFT), rejection sampling, and direct preference optimization. Most SFT samples were generated from synthetic data.
Researchers made some choices in the design to maximize the scalability of the model development process. For example, they chose a standard dense Transformer model architecture with only minor adjustments, rather than adopting a mixture of experts model, to maximize training stability. Similarly, a relatively simple post-training procedure was adopted, based on supervised fine-tuning (SFT), rejection sampling (RS), and direct preference optimization (DPO), rather than more complex reinforcement learning algorithms, as the latter often have poorer stability and are more difficult to scale.
6. As part of the Llama 3 development process, the Meta team also developed multimodal extensions of the model, enabling capabilities in image recognition, video recognition, and speech understanding. These models are still actively being developed and are not ready for release, but the paper showcases preliminary experimental results for these multimodal models.
7. Meta updated the license, allowing developers to use the output results of the Llama model to enhance other models.
At the end of this paper, we also saw a long list of contributors:


These factors ultimately contributed to the creation of the Llama 3 series.
Of course, for ordinary developers, leveraging a model of 405B scale is a challenge that requires substantial computational resources and expertise.
After its release, the ecosystem for Llama 3.1 is ready, with over 25 partners providing services that can be used with the latest model, including Amazon Web Services, NVIDIA, Databricks, Groq, Dell, Azure, Google Cloud, and Snowflake.
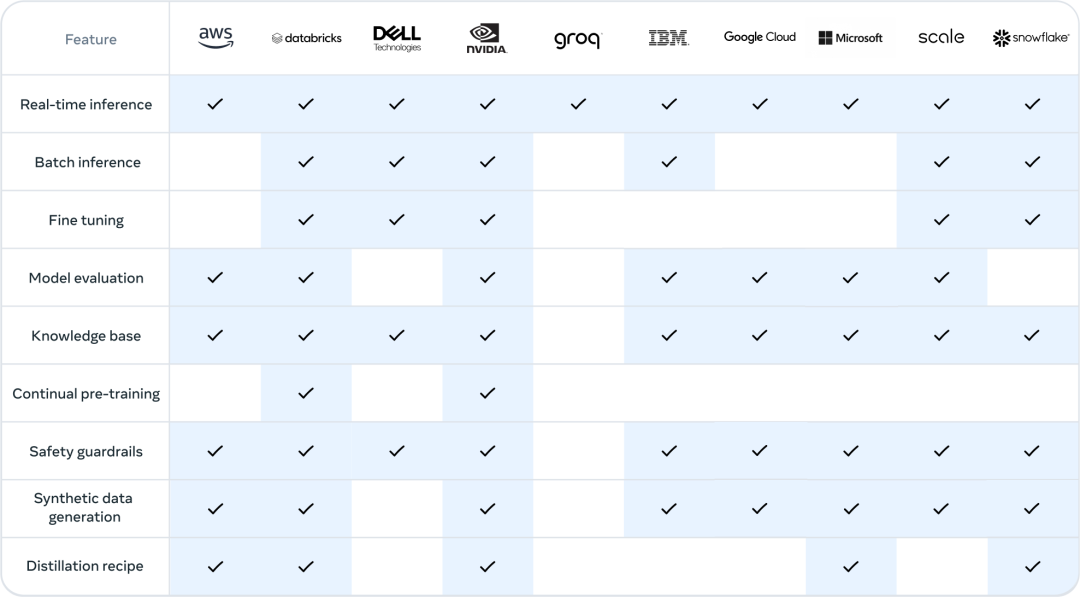
For more technical details, please refer to the original paper.

END
