
Author: Prince Changqin (NLP Algorithm Engineer)
Bert, Pre-training of Deep Bidirectional Transformers for Language Understanding Note
Paper: https://arxiv.org/pdf/1810.04805.pdf
Code: https://github.com/google-research/bert
The core idea of Bert: MaskLM utilizes bidirectional context + MultiTask.
Abstract
BERT obtains a deep bidirectional representation of text by jointly training the context across all layers.
Introduction
Two methods to apply pre-trained models to downstream tasks:
-
feature-based: for example, ELMo, using pre-trained representations as additional features
-
fine-tuning: for example, OpenAI GPT, introducing a small number of task-specific parameters, fine-tuning all parameters in downstream tasks
Current technology has a limitation of only using a left-to-right unidirectional mechanism, which is unsuitable for some tasks, such as question answering.
Bert mitigates this limitation through the “masked language model”, which randomly masks some tokens in the input, aiming to predict the original vocabulary id of the masked tokens based only on the context (both left and right).
Additionally, a “next sentence prediction” task is jointly trained to represent text pairs.
Related Work
Unsupervised Feature-based Approaches
-
Word Embedding:
-
Left-to-right language model (Mnih and Hinton, 2009)
-
Distinguishing the correct center word from context (Mikolov, 2013)
-
Sentence Embedding:
-
Ranking a candidate set of next sentences (Jernite, 2017; Logeswaran and Lee, 2018)
-
Generating the next word from a given sentence left-to-right (Kiors, 2015)
-
Denoising autoencoder (Hill, 2016)
ELMo uses both left-to-right and right-to-left language models, where each token’s context representation is associated with both language models.
Melamud (2016) learns context representations through a task predicting a single word from left and right context (using LSTMs).
Unsupervised Fine-tuning Approaches
-
Directly training embeddings from the corpus (Collobert and Weston, 2018)
-
Training context representations from text and fine-tuning in downstream tasks (Dai and Le, 2015; Howard and Ruder, 2018; Radford, 2018)
-
OpenAI GPT (Radford, 2018)
Transfer Learning from Supervised Data
Some effective transfer learning:
-
Natural Language Inference
-
Machine Translation
BERT
Two steps:
-
pre-training: based on multi-task
-
fine-tuning: initialize with pre-trained parameters, then refine on supervised tasks
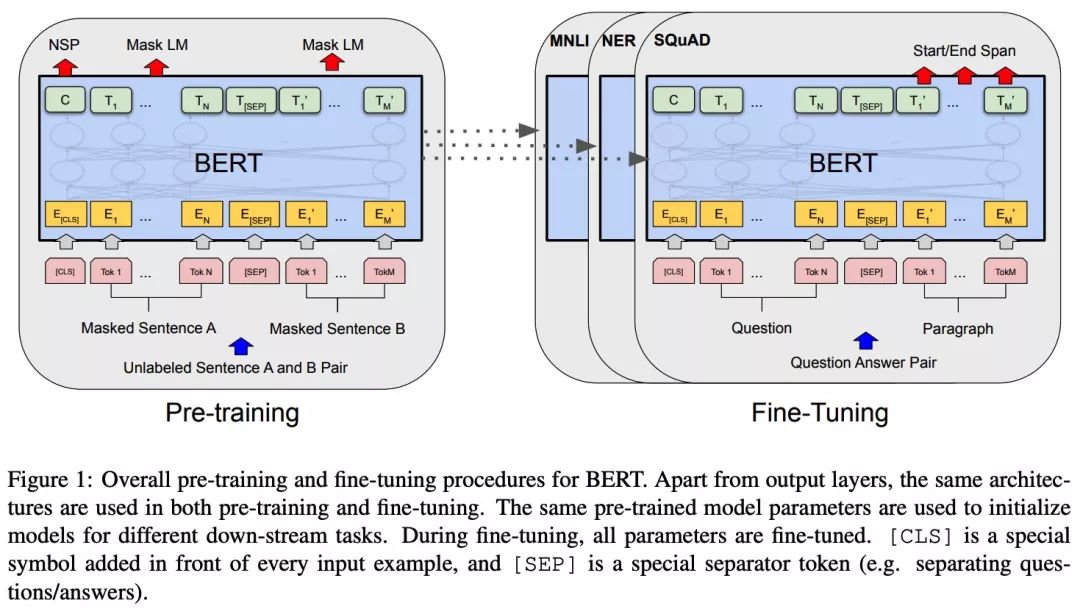
Model Architecture
-
Multi-layer bidirectional Transformer encoder
-
Layer number (Transformer blocks): L (Base 12, Large 24)
-
Hidden size: H (Base 768, Large 1024)
-
Number of self-attention heads: A (Base 12, Large 16)
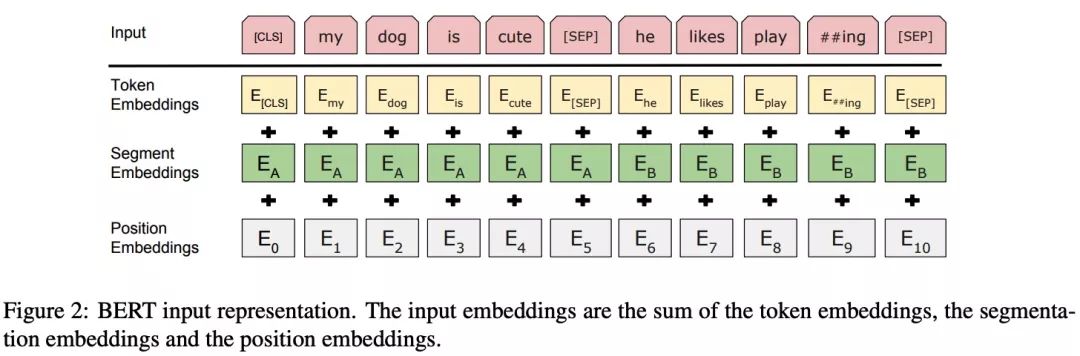
Input/Output Representations
-
Input sentence pairs (for example, “Question, Answer”) as a sequence of tokens, where “sentence” refers to adjacent text, not an actual “sentence”
-
Using WordPiece Embedding (Wu, 2016)
-
The state of the last hidden layer as the representation of the sequence
-
Two methods to process sentence pairs into one sentence: separate with a special token (SEP); or use a new embedding to mark which token belongs to which sentence
-
The input representation of each token consists of token + segment + position embeddings
Pre-training BERT
Instead of using left-to-right or the opposite direction language models, two unsupervised tasks are used.
Task #1: Masked LM (MLM)
Randomly mask a certain percentage (15%) of tokens in the input, then predict these tokens, with the final hidden layer vector fed into softmax.
Only predict the masked tokens, not reconstruct the entire input.
However, there is an issue during fine-tuning when there is no mask, so it’s not simply replacing masked tokens with [MASK]:
-
80% replaced with
[MASK] -
10% choose a random token
-
10% still use the original token
Task #2: Next Sentence Prediction (NSP)
Among all sentence pairs, 50% are related and 50% are random next sentences.
Pre-training data
Uses document-level corpus rather than randomized sentence-level corpus.
Fine-tuning BERT
Sentence A and B from pre-training correspond to different tasks:
-
Paraphrase: sentence pairs
-
Entailment: hypothesis-premise pairs
-
Question Answering: question-paragraph pairs
-
Text Classification, Sequence Labeling: text-empty pairs
Experiments
-
GLUE: A set of natural language understanding tasks.
-
SQuAD v1.1: Question answering task.
-
SQuAD v2.0: Question answering task without short answers.
-
SWAG: Common sense reasoning task.
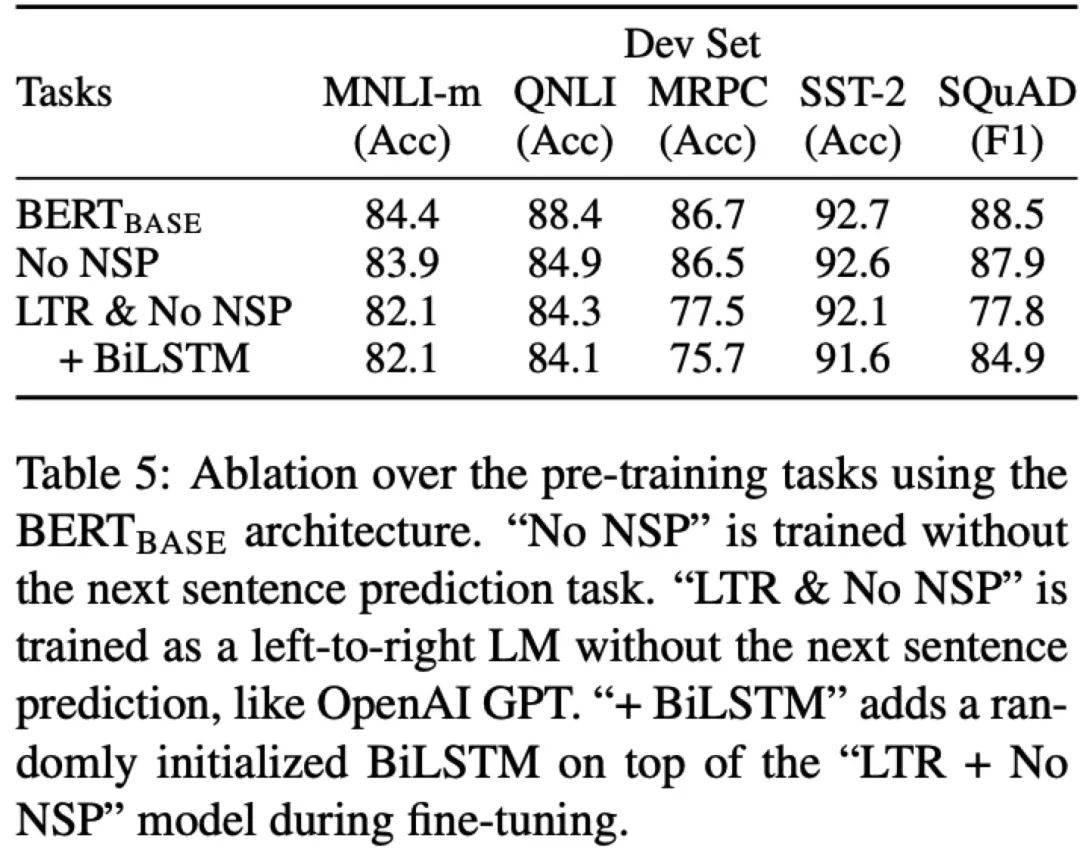
Ablation Studies
Effect of Pre-training Tasks
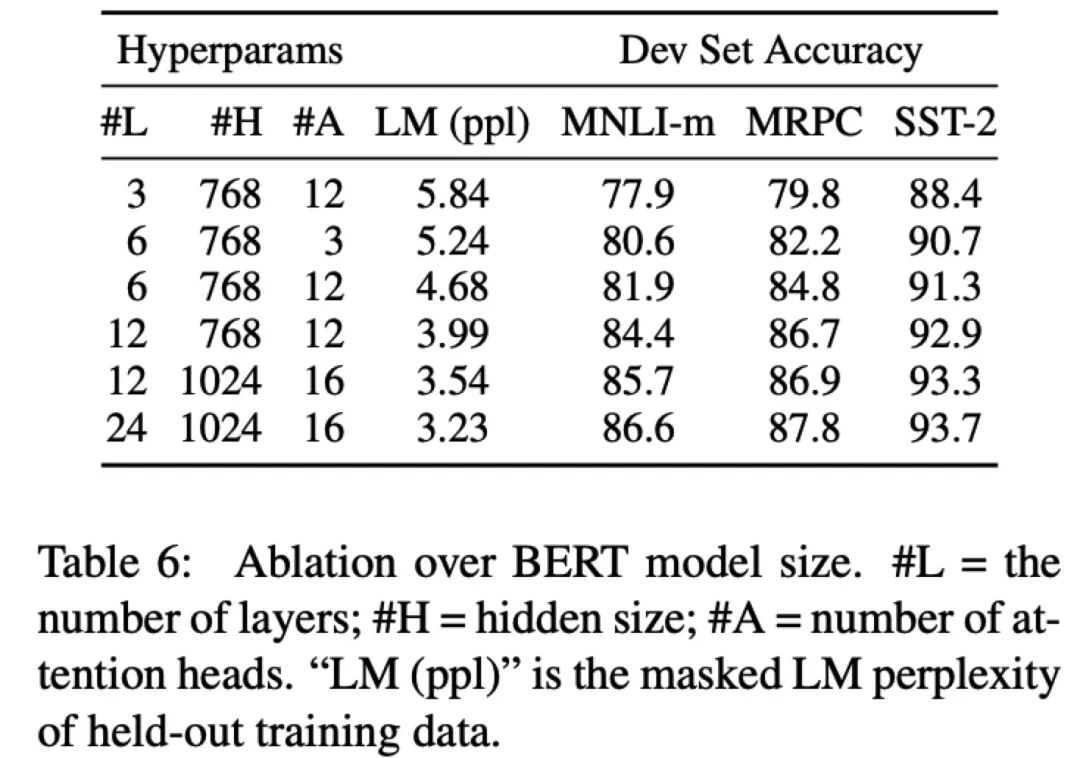
Effect of Model Size
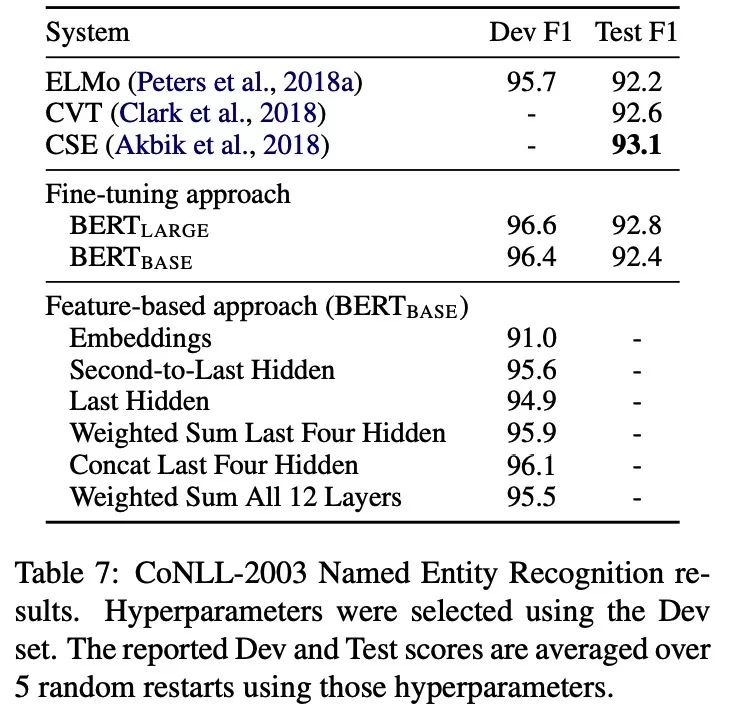
Feature-based Approach with BERT
Original link:
This article is authorized by the author and originally published on the AINLP public account platform. Click ‘Read the original text’ to go directly to the original link. Submissions are welcome, AI and NLP are both acceptable.