Machine Heart reports
“Big model developers, you are wrong.”
“I discovered a bug in the attention formula that no one has found for eight years. All Transformer models, including GPT and LLaMA, are affected.”
Yesterday, a statistician named Evan Miller stirred up a storm in the AI field with his statement.
We know that the attention formula in machine learning is as follows:
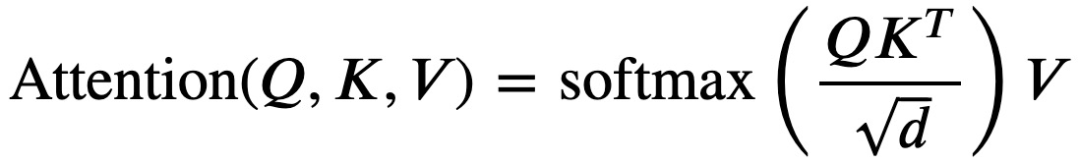
Since the introduction of the Transformer in 2017, this formula has been widely used, but now Evan Miller has discovered that this formula is incorrect and contains a bug!
Evan Miller’s blog explains how currently popular AI models have errors in key positions, making it difficult for all Transformer models to be compressed and deployed.
In summary, Evan Miller introduces a new function called Quiet Attention, also known as Softmax_1, which is an innovative adjustment to the traditional softmax function.
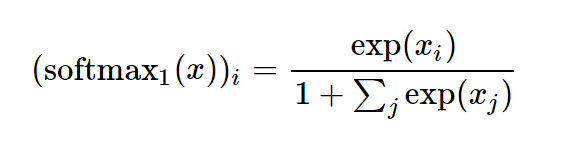
Some netizens summarized a “TL;DR” version of the blog. The blog author suggests adding 1 to the denominator of the softmax formula used in the attention mechanism (not the final output softmax). The softmax in the attention unit allows it to match keys/queries as probabilities; these probabilities support a continuous value version of key-value lookup (the weights we obtain are not a 1/0 output of a lookup, but high weight = desired key-value lookup).
Adding 1 to the denominator will change the attention unit, which will no longer use the true weight probability vector but instead use weights that sum to less than 1. The motivation is that the network can learn to provide high weights, so the adjusted softmax is very close to the probability vector. At the same time, there is a new option to provide all-low weights (which provide all-low output weights), meaning it can choose not to have high confidence in anything.

Some even speculate, “Is this the reason why Microsoft’s RetNet outperforms transformers?”

Other netizens stated that this research could promote improvements in LLMs, greatly compressing weights, allowing smaller models to rival larger ones:
Miller stated: you can use the Softmax_1 function just like the traditional softmax function, as shown below.
import torch
from softmax_one.softmax_one import softmax_one
x = torch.randn(5)
y = softmax_one(x, dim=0)Based on such modifications, Miller also conducted experiments, and the results are as follows:
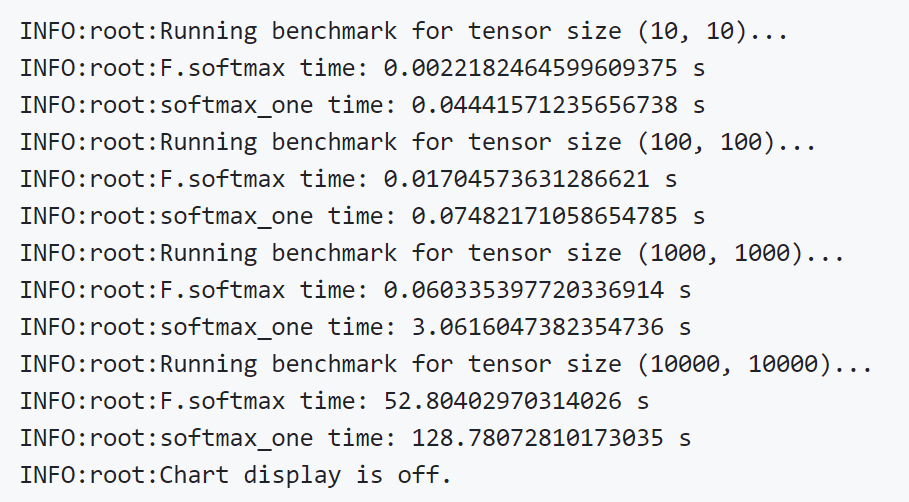
Next, let’s see what error Miller actually discovered.
Outliers
Evan Miller discovered this bug while reading a paper on quantization. Currently, memory and storage have become important factors limiting the development of artificial intelligence. People have been trying to compress models and run large language models (LLMs) on the cloud and edge devices.
In computers, information is stored as binary data streams. If the data stream is highly predictable, for example, always within a limited range, we can store them with relatively few bits. Conversely, if a string of numbers is unpredictable, potentially enormous numbers, we need more binary digits to encode and store them. Transformer models contain some outlier weights.
In a paper published by Qualcomm AI Research in June titled “Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing”, the research team traced the existence of these outliers back to the softmax function of the attention mechanism.
 Qualcomm paper link: https://arxiv.org/abs/2306.12929
Qualcomm paper link: https://arxiv.org/abs/2306.12929
This sounds surprising, but Evan Miller believes it is correct and further discovered that there is an error in the softmax function.
Let’s see how Evan Miller explains that the softmax function is not a suitable tool in the attention mechanism.
Problems Introduced by Softmax
Why is softmax unsuitable for the attention mechanism? We need to start from what the attention mechanism can do.
In general, numerical errors are usually caused by programming errors; however, when the program is error-free, it is necessary to spend a lot of time fixing complex mathematical formulas.
Evan Miller probably read about 50 arXiv papers to get some clues. Miller started from “input embeddings”; we can understand “input embeddings” as a floating-point vector representing a word in the input string.
For example, Meta’s recently launched LLaMA 2 model uses an embedding vector of length 3204, represented as half-precision floating-point numbers, just to represent one word in the vocabulary, which typically contains 30,000 to 50,000 entries. This means that the embedding vector for one word occupies over 6KB of storage. As technology advances, the length of “input embeddings” has gradually increased, and so has the storage space occupied.
If you are a C programmer who is very sensitive to storage usage, you might find it unacceptable that something that could be stored in 2 bytes is taking up 6KB. If calculated at 2 bytes, if the vocabulary is less than 2^16=65384, we only need 16 bits to represent an entry.
However, in reality, the Transformer works like this: it converts the input vector into an output vector of the same size, and the final 6KB output vector is used to predict the next token. During operation, each layer of the Transformer adds information to the original word vector. In this process, residual connections are also used: all attention mechanisms add supplementary materials to the original two-byte information, allowing LLMs to analyze longer contexts.
The final step of the Transformer is to multiply this output vector by a rectangular matrix and compress the resulting vocabulary-length vector into a softmax function, treating these exponentiated outputs as the probabilities of the next token. This is reasonable, but it is well known that this is not entirely correct because we cannot be sure that these output probabilities are correct. Instead, each Transformer implementation and its derived versions use sampling mechanisms to hide the fact that softmax over-represents low probabilities.
Next, Miller introduces the history of softmax. Softmax first appeared in statistics, originally as a method for predicting state distributions based on energy levels, in the following form:
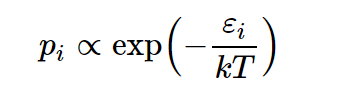
Later, economists modified it to
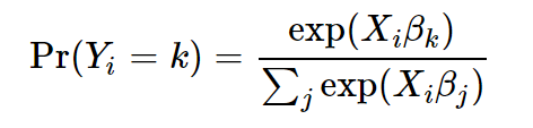
This modification gave softmax the multinomial logistic function. Due to Miller’s deep research on the softmax function, he could identify inappropriate uses of softmax.
Softmax is widely used; in physics, it is very effective; in economics, it may not be so accurate; but when applied to machine learning, it seems to always be effective as long as it involves discrete choices:
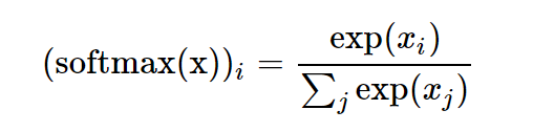
Miller further states that the key to softmax is that if you do not want to retain some items, you must modify softmax; otherwise, the results will become distorted.
For example, in the context of LLMs, the distortion arises from heavily weighting non-semantic tokens (such as commas), leading to high weights that become difficult to compress outliers, making research more challenging. Researchers from Qualcomm have also observed this phenomenon, where over 97% of outlier activations occur at the positions of spaces and punctuation.
Next, Miller explains how softmax is used in attention, revealing where the problems arise:
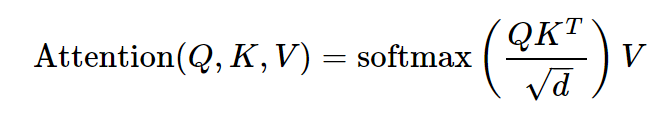
Breaking down the above formula, in a decoder-only model, 𝑄, 𝐾, and 𝑉 come from the same input sequence. They are not exactly the same, as they are projected differently. However, at each layer, they all start with the same annotated embedding vector.
The 𝑄𝐾^𝑇 term is used to find the correlation between token vectors at different positions, effectively constructing a correlation matrix (scaled by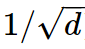 ), where each column and row corresponds to a token position. Then, a softmax operation is performed on each row of this square matrix, and the resulting probabilities are used as a mixing function for the value vectors in the 𝑉 matrix. The mixed 𝑉 is then added to the input vector, and the sum is passed to the neural network for further processing.
), where each column and row corresponds to a token position. Then, a softmax operation is performed on each row of this square matrix, and the resulting probabilities are used as a mixing function for the value vectors in the 𝑉 matrix. The mixed 𝑉 is then added to the input vector, and the sum is passed to the neural network for further processing.
Multi-head attention executes the above process in parallel multiple times at each layer. Essentially, this method divides the embedding vector, with each head using information from the entire vector to annotate a (non-overlapping) segment of the output vector. This is the concatenation operation in the original Transformer paper.
The problem with using softmax is that it forces each attention head to annotate even when there is no information to add to the output vector.
Softmax_1 and QuietAttention
Here comes Softmax Super-Mod, which has ignited the LLM hacker channel.
A bit disappointing, right? What Miller did was simply add 1 to the denominator. If desired, this can make the vector approach 0 overall. Otherwise, it will only slightly reduce the values, and the reduced values will be compensated during normalization, which occurs after attention.
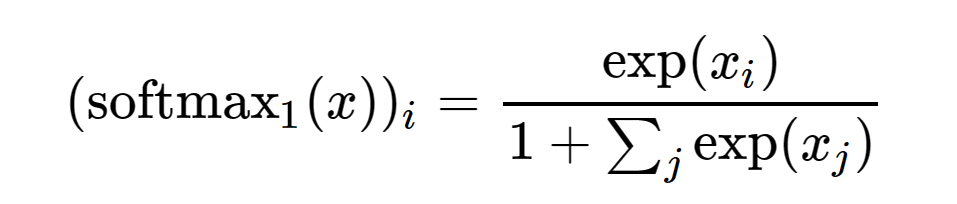
When entries in 𝑥 are significantly less than zero and the model tries to avoid annotations entirely, the main difference lies in the negative value constraints. The limiting behavior of the original softmax is as follows:

Compared to the new, improved softmax_1.
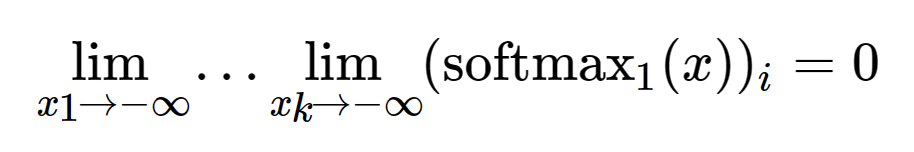
Vanilla softmax will always release the same total weight; softmax_1 looks mostly the same but has an “escape hatch” in the negative quadrant. It is important to clarify that the core issue here is essentially mathematical rather than numerical. Additional precision cannot save softmax; all Transformers will be affected.
You can also observe other aspects of softmax_1. The derivative is positive, so there is always a non-zero gradient, and its sum is between 0 and 1, so the output does not explode. The function retains the following property:
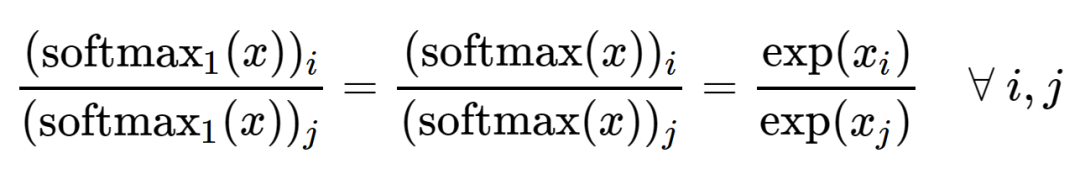
That is, the relative values in the output vector remain unchanged.
Initially, Miller intended to call this function ghostmax because you could think of it as having an additional zero-value entry in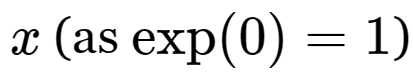 and a zero vector in the V matrix that can attenuate the result.
and a zero vector in the V matrix that can attenuate the result.
Although softmax_1 may seem boring on the surface, Miller is 99.44% confident that it will solve the outlier feedback loop, making quantization a subject of cascading research. Miller stated that if you want to conduct some experiments to prove he is correct, you can contact him. He will write a paper.
The improved mechanism can be called QuietAttention, which allows attention heads to remain “silent”.
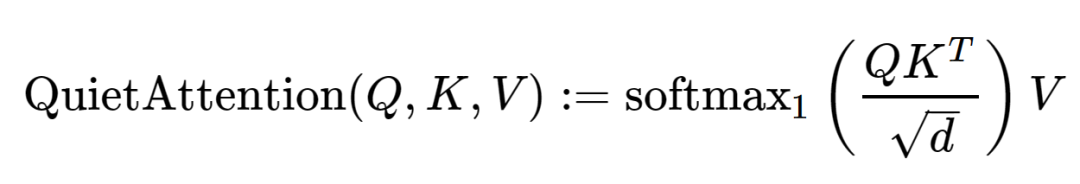
Miller believes that a test can be integrated soon: if you add a zero vector to the front of each input context and ensure that the chosen neural network does not add any bias (including positional encodings), then the zero will not change as it passes through, and adding unity to the denominator of each subsequent softmax will have an effect. This way, you won’t lose your mind over processing gradient code. Miller believes this can be accomplished using fixed embeddings and special prefix tokens in the LLaMA model.
You will still need to retrain the model, so don’t try this on a Raspberry Pi (RPi) for now. But Miller is curious about what these weight kurtosis and activation infinity norms look like after running several times. He believes this will become influential research, whether it’s the Qualcomm AI Research team’s paper or someone in the LLM hacker channel calculating biblatex but discovering it first.
-
Project link: https://github.com/kyegomez/AttentionIsOFFByOne
-
Blog link: https://www.evanmiller.org/attention-is-off-by-one.html?continueFlag=5d0e431f4edf1d8cccea47871e82fbc4

© THE END
For reprints, please contact this public account for authorization
Submission or seeking reports: [email protected]