Guest Speaker: Wei Tianwen, Xiaomi AI Department
Edited by: Li Shuna
Source: DataFunTalk
Introduction: Xiao Ai is an intelligent voice system developed by Xiaomi, widely used in smartphones, bands, speakers, TVs, and other electronic products, supporting various voice interaction scenarios such as casual conversation, Q&A, and voice control. The accuracy of Automatic Speech Recognition (ASR) in recognizing voice content is a key constraint affecting the development of intelligent voice products. The text of user queries is usually generated by the ASR system converting users’ voice commands. However, due to technical reasons, the text generated by ASR may contain errors, leading to deviations in subsequent user intent understanding. How to utilize NLP technology to preprocess and correct the ASR query text has become an urgent problem to be solved.
This presentation will introduce the technical explorations conducted by the Xiao Ai algorithm team based on the popular BERT pre-training model in recent years regarding this issue, as well as its implementation in business scenarios. The main content includes:
Introduction to ASR Error Correction Issues
1. Voice Interaction Process
Before discussing the relevant issues of voice error correction, let’s briefly introduce the voice usage process of Xiao Ai: First, we need to wake up Xiao Ai, for example, by pressing a button or using a voice wake-up. After waking up, it enters the recording module, where Voice Activity Detection (VAD) is activated before recording starts to detect whether there is any speech. If there isn’t, it ignores it; if there is, it records the speech and passes it to the next module, which is the most focused on Automatic Speech Recognition (ASR), responsible for converting speech into text.
We are responsible for the next module after ASR, which is the Natural Language Understanding (NLU) module. Its main purpose is to try to understand the text converted by ASR, accurately identify the user’s intent, and then provide a corresponding skill execution plan, with the final step being skill execution.
In this voice interaction process, the first three steps all involve voice-related work, and errors such as recording noise or recognition errors can easily occur. For example, mistakenly activating the wake-up command could record noise; or during the speech recording process, a certain sound may be misidentified as human speech and recorded, leading to incorrect text during recognition. Additionally, even in pure human speech, the ASR model conversion process can still have certain errors.
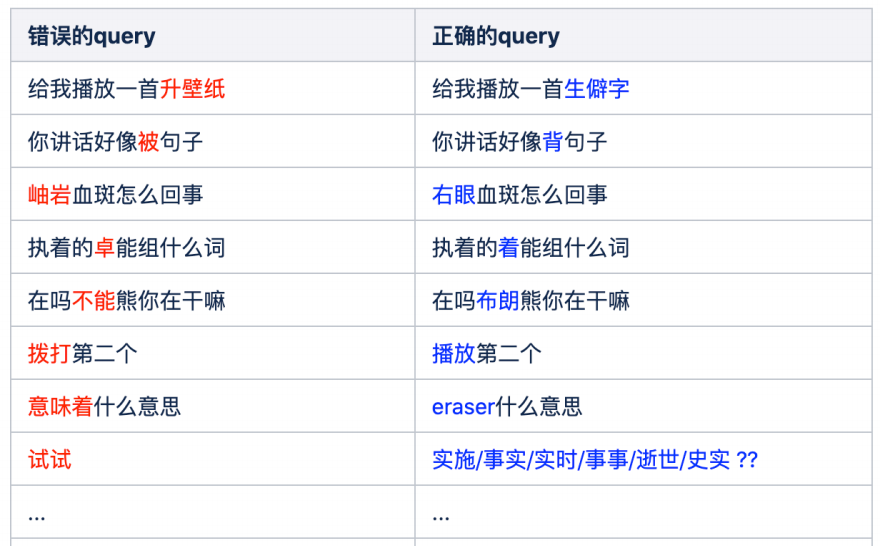
2. Examples of ASR Errors
The table displays common error examples during ASR recognition. When the user asks “Play a song Sheng Pi Zi“, the recognized text result is “Play a song Sheng Bi Zhi“. There are also cases where Chinese contains English, such as: “eraser means what”, where the recognized text result is “yiwei means what”. By analyzing these erroneous cases, it is found that the speech recognition process has difficulty accurately recognizing words with similar pronunciations. Our work’s goal is to identify the erroneous queries generated by ASR and replace them with the correct queries.
 At this point, we need to consider whether ASR error correction is a well-defined problem, which means that under the current given information, it is solvable or that the accuracy obtained from classification using a Bayesian classifier is very high. From the cases, it can be seen that to correct these queries, some can be corrected based on the sentence structure. For example, “You speak as if be a sentence” can be corrected by analyzing the grammatical structure, knowing that “be” is inappropriate here and should be “back”. Others require background knowledge to correct, such as “Sheng Pi Zi” being a song, “Right Eye Blood Spot” being common knowledge, and “Brown Bear” being a skill of Xiao Ai (Brown Bear dances). Some grammatical errors may not be correctable without the original audio, such as “Play the second one” vs. the recognized text “Dial the second one”, or “eraser” recognized as “yiwei”; some may not even be correctable by listening to the audio, as many Chinese words have the same pronunciation tones, requiring contextual information to determine which word it is. Therefore, error correction requires combining a lot of information. If all knowledge, audio, and contextual environments are considered, it is essentially equivalent to redoing an ASR recognition system. However, ASR itself is limited by physical conditions such as memory and throughput, making it difficult for acoustic and language models to handle large processing volumes. The comprehensive consideration of ASR’s language model is still based on the traditional n-gram model. However, using NLP technology has inherent advantages, allowing the use of powerful pre-trained models without needing audio for error correction.
ASR error correction is also different from ordinary typo correction; ordinary typo correction is based on character similarity, such as “valve” and “threshold”. ASR error correction is based on phonetic similarity, where similar pronunciations lead to difficulty recognizing the correct content. Therefore, ASR error correction and ordinary typo correction face different problems and data distributions. Additionally, the scope of ordinary typo correction is broader than ASR correction, but this does not mean that ordinary typo correction can be used for ASR correction. “There is no such thing as a free lunch,” meaning no model can perform well across different data distributions. For example, correcting the text “de”, “di”, “de”; if all other words in the sentence are correct, only “de” needs to be corrected to “de”, but using a model that does not combine prior information for correction will likely lead to other originally correct words being corrected to incorrect ones, thereby affecting the model’s accuracy. The correct approach is to create a correction model that can adapt to the current data distribution based on prior conditions. The same applies to the ASR correction model; phonetic similarity is a limiting condition for ASR correction. We need to combine the ordinary typo model with this limiting condition to design a correction model for ASR-recognized text data.
3. ASR Error Correction Problem Setting
Next, we make the following preliminary settings for the ASR error correction problem:
At this point, we need to consider whether ASR error correction is a well-defined problem, which means that under the current given information, it is solvable or that the accuracy obtained from classification using a Bayesian classifier is very high. From the cases, it can be seen that to correct these queries, some can be corrected based on the sentence structure. For example, “You speak as if be a sentence” can be corrected by analyzing the grammatical structure, knowing that “be” is inappropriate here and should be “back”. Others require background knowledge to correct, such as “Sheng Pi Zi” being a song, “Right Eye Blood Spot” being common knowledge, and “Brown Bear” being a skill of Xiao Ai (Brown Bear dances). Some grammatical errors may not be correctable without the original audio, such as “Play the second one” vs. the recognized text “Dial the second one”, or “eraser” recognized as “yiwei”; some may not even be correctable by listening to the audio, as many Chinese words have the same pronunciation tones, requiring contextual information to determine which word it is. Therefore, error correction requires combining a lot of information. If all knowledge, audio, and contextual environments are considered, it is essentially equivalent to redoing an ASR recognition system. However, ASR itself is limited by physical conditions such as memory and throughput, making it difficult for acoustic and language models to handle large processing volumes. The comprehensive consideration of ASR’s language model is still based on the traditional n-gram model. However, using NLP technology has inherent advantages, allowing the use of powerful pre-trained models without needing audio for error correction.
ASR error correction is also different from ordinary typo correction; ordinary typo correction is based on character similarity, such as “valve” and “threshold”. ASR error correction is based on phonetic similarity, where similar pronunciations lead to difficulty recognizing the correct content. Therefore, ASR error correction and ordinary typo correction face different problems and data distributions. Additionally, the scope of ordinary typo correction is broader than ASR correction, but this does not mean that ordinary typo correction can be used for ASR correction. “There is no such thing as a free lunch,” meaning no model can perform well across different data distributions. For example, correcting the text “de”, “di”, “de”; if all other words in the sentence are correct, only “de” needs to be corrected to “de”, but using a model that does not combine prior information for correction will likely lead to other originally correct words being corrected to incorrect ones, thereby affecting the model’s accuracy. The correct approach is to create a correction model that can adapt to the current data distribution based on prior conditions. The same applies to the ASR correction model; phonetic similarity is a limiting condition for ASR correction. We need to combine the ordinary typo model with this limiting condition to design a correction model for ASR-recognized text data.
3. ASR Error Correction Problem Setting
Next, we make the following preliminary settings for the ASR error correction problem:
-
Only consider medium-length queries of more than 6 characters: Short queries cannot reflect sufficient contextual information, making correction difficult.
-
Do not consider contextual dialogue information: Contextual dialogue information is more complex, and in Xiao Ai’s dialogue information, multi-turn dialogue only accounts for 1%, so we will not consider multi-turn dialogue scenarios for now.
-
Do not consider audio information: As a downstream correction product of ASR, we only consider textual information.
-
Only consider one-to-one correction: Based on the BERT model for correction, one-to-one is easier to implement; later, we can relax the restrictions.
-
Only use unsupervised corpus: Unsupervised corpus saves labor costs and allows the use of pre-trained models. The head corpus of the data distribution can be embedded into the model, but it may not benefit the correction of tail data, meaning that for information that has not appeared in the corpus, it is unlikely to be corrected.
These settings are consistent with the conditions set in some current ASR error correction literature.
Related Work on Error Correction
1. Introduction to the BERT Model
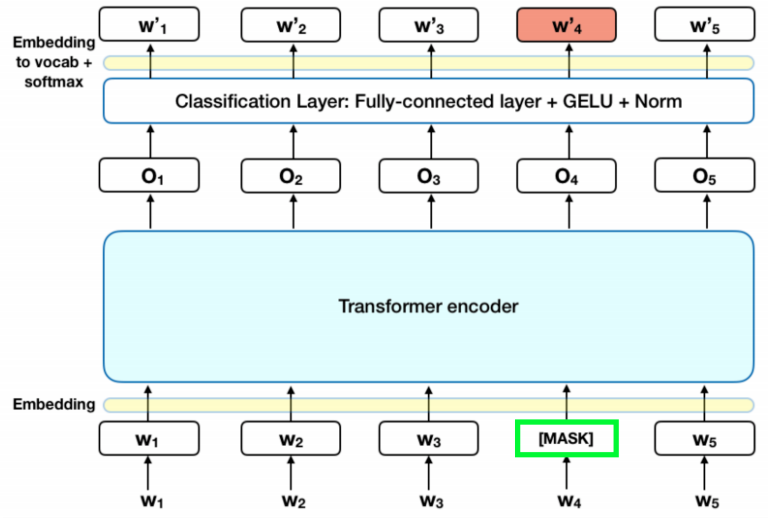
BERT is currently the best-performing pre-trained language representation model, introducing a bidirectional Transformer-encoder structure, with trained model networks including 12-layer BERT-small and 24-layer BERT-large. BERT includes two training tasks: one is the Masked Language Model (MLM), and the other is Next Sentence Prediction (NSP). The BERT model is mainly used as a pre-trained model to extract features and obtain semantically meaningful word vector representations, enhancing the performance of downstream tasks.
In the BERT model, the part related to the ASR error correction task is the MLM part. During the MLM training phase, 15% of tokens are randomly replaced with [MASK] (a placeholder), and the model needs to learn to predict these replaced tokens based on the context of [MASK]. For example, for the input sentence “Tomorrow’s weather in Wuhan is [MASK]”, the model needs to predict that the original token at [MASK] is “weather”.
If only the MASK mechanism is used for training, there are some transfer issues, as there are no MASK conditions in other tasks, making it difficult to use as a pre-training task for other tasks. Thus, the authors optimized the approach using MASK.
-
Among them, 10% of [MASK] will be randomly replaced with another token. At this time, “Tomorrow’s weather in Wuhan is [MASK]” will change to “Tomorrow’s weather in Wuhan is micro-weather”, and the model needs to learn to correct “micro” to “weather” during training.
-
Additionally, another 10% of [MASK] will be “restored”. At this time, “Tomorrow’s weather in Wuhan is [MASK]” will be restored to “Tomorrow’s weather in Wuhan is weather”, and the model needs to learn whether the “weather” needs correction based on the context during training.
-
The remaining 80% of [MASK] retains the placeholder state. The loss calculated during the BERT training process only includes the losses of the tokens involved in the MASK mechanism, not the entire sentence’s loss.
MLM actually includes the error correction task, so the native BERT has correction capabilities. However, the MASK positions in BERT are randomly selected from 15% of tokens, so it is not good at detecting where errors occur in sentences; furthermore, BERT’s error correction does not consider constraint conditions, resulting in low accuracy. For example, “Xiao Ai today [ming] how’s the weather” has a MASK position at “today”; thus, the correction task needs to yield “today”. However, since most people’s queries in the training data are “ming how’s the weather”, without constraint conditions, the correction result is likely to be “ming“, which, although structurally reasonable, is clearly incorrect.
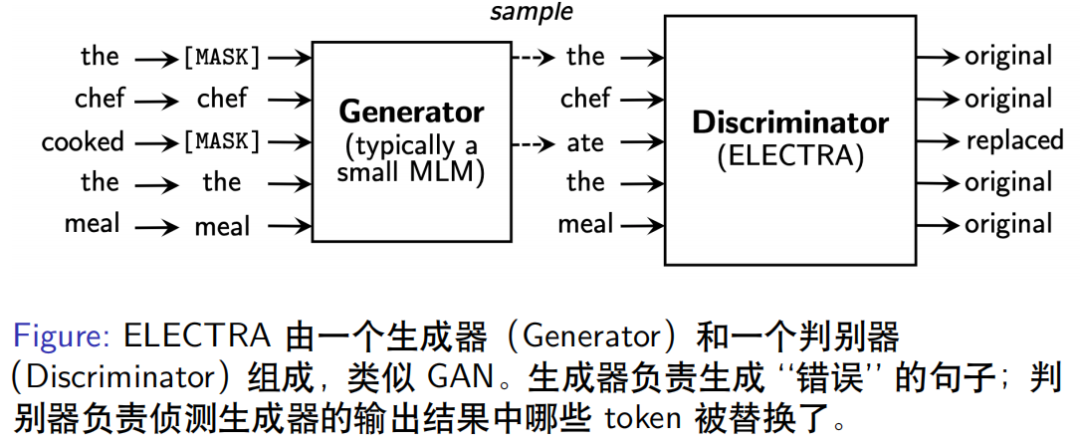
The ELECTRA model was proposed by a Stanford University team, consisting of a generator and a discriminator, resembling a GAN structure but not belonging to GAN models.
-
The generator’s role is to input a correct sentence and generate an incorrect version, such as “the chef cooked the meal”. After randomly masking 15% of tokens within the generator, it predicts the positions of these MASKs, outputting “the chef ate the meal”. The language model within the generator ensures that the generated incorrect sentence remains reasonably similar to the original sentence.
-
The discriminator (ELECTRA) is used to determine which positions of tokens in the generator’s output have been altered, labeling each token’s position as original/replaced, such as “cooked” becoming “ate”, marked as “replaced”, while the other positions remain labeled as “original”, similar to a sequence labeling task. The discriminator’s output is 0 or 1.
Although the ELECTRA model’s discriminator can detect errors, it is not designed for error correction but rather to extract better feature representations under limited computational resources, achieving better results. The article indicates that it performs significantly better than BERT on the GLUE dataset.
A variant of ELECTRA, the ELECTRA-MLM model, does not output 0 and 1 but predicts the probability of the correct token at each MASK position. If the vocabulary size is 10,000, then the output for each position is a corresponding 10,000-dimensional vector distribution, where the maximum probability corresponds to the correct token’s result, thus transforming the native ELECTRA from error detection to a model with error correction capabilities.
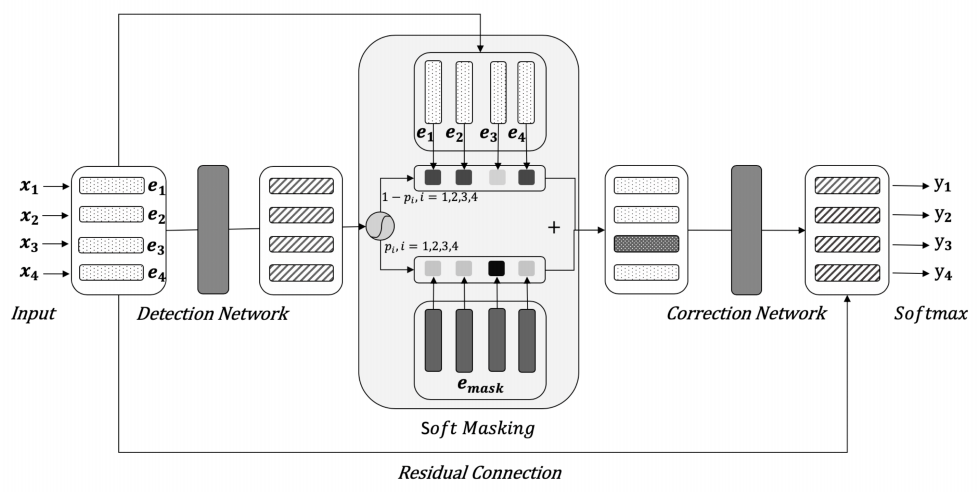
3. Soft-Masked BERT Error Correction Model
A recently published error correction model is Soft-Masked BERT, which generates error samples randomly based on simple rules such as homophone replacement from the collected corpus, obtaining error-correct pairs as training data. This network model concatenates a detection model (BiGRU) and an error correction model (BERT). The bidirectional GRU model outputs the probability of each token position being an erroneous word, and when the error probability is 1, it degenerates to the native BERT model for correction.
The innovation of this model lies in the fact that the word vectors input to BERT are not the original input tokens, but the weighted average of the token’s embedding and the [MASK]’s embedding, where the weights are the error probabilities output by the BiGRU model for each position. Thus, when masking, it acts as a soft mask. For example, if the GRU believes that the word at a certain position has an error probability of 1, then the word vector input to BERT is the [MASK] word vector; if the detection model considers a certain position’s word to be correct, with an error probability of 0, the word vector input to BERT is the token’s vector. However, if the detection model outputs an error probability of 0.5 for a certain position, the word vector input to BERT is the weighted result of both ( (1-0.5)* token_embedding + 0.5*[MASK]_embedding ). Unlike previous detectors that output 0/1, only using the Hard-Mask approach of MASK and non-MASK, this model is called Soft-Mask BERT, which reportedly improves error correction performance by about 3% over the native BERT model.
However, our work did not reference this model before the paper, and we will consider it according to actual conditions in the future. This concludes the introduction to the literature on error correction models, and next, we will introduce our work content.
03
Our Work
Our error correction model structure is also similar to a generator and discriminator pattern, as shown in the figure above.
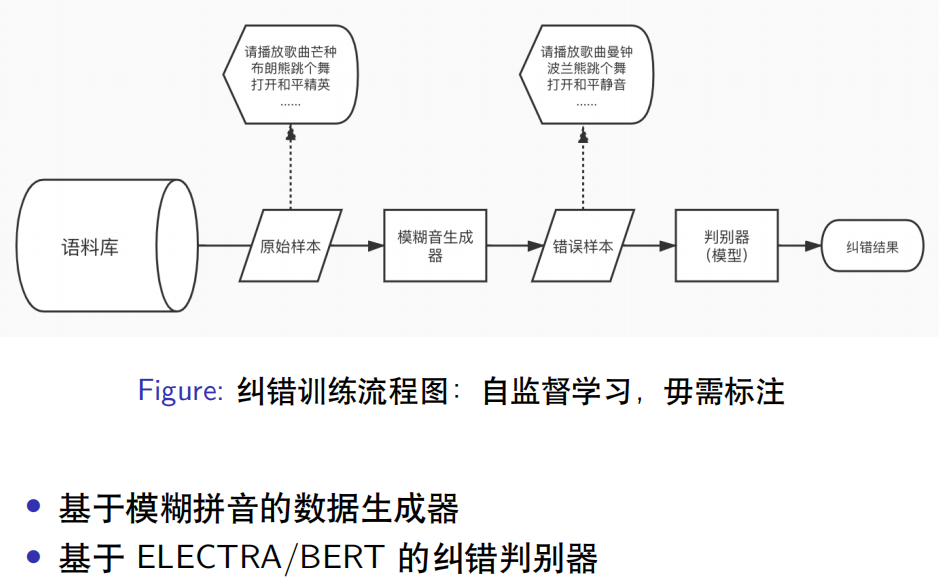
The corpus includes Chinese Wikipedia, Chinese Zhihu, some crawled news corpus, and user logs from Xiao Ai’s operation, totaling nearly 100 million pieces of data. We sampled original samples from the corpus, similar to “Please play the song Mang Zhong“, “Brown Bear dances”, “Open Peace Elite” and so on. We developed a dedicated fuzzy sound generator to simulate ASR-generated erroneous data, processing original samples based on fuzzy pinyin to generate erroneous samples, resulting in outputs like “Please play the song Mang Zhong“, “Poland Bear dances”, “Open Peace Mute” etc. The constructed correct and erroneous sample pairs are input into the discriminator model, which performs end-to-end error correction by inputting erroneous samples and outputting correct samples.
By analyzing the patterns of ASR erroneous samples, we defined fuzzy levels and fuzzy candidate sets in the fuzzy sound generator, as shown in the figure above.
Based on the similarity of fuzzy sounds, we classified them into 5 levels. The higher the level, the less similar the pronunciation. For example, level 1 has completely identical pronunciations (“ai” and “ai”), level 2 has the same pronunciation but different tones (“ji” and “ji”), level 3 involves common flat retroflex and front-back nasal sound confusions (“shi” and “si”, “l” and “n”), level 4 has a pinyin edit distance of 1, and level 5 has a pinyin edit distance greater than 1, where the pronunciations are basically different.
The calculation of the pinyin edit distance adopts a non-standard pinyin scheme. For example, “sui” uses “suei”, as “sui” is an abbreviation. The pronunciation of “si” in “si” uses “I” because “i” in “si” and in “di” are pronounced differently, hence “I” is used to replace “i” in “si”. Similarly, “you” (“you” uses “iou”) is because “y” is not truly a consonant. When “i” is a consonant, “y” replaces “i”, which restores this actual phonetic rule. Moreover, “wa” (“wa” uses “ua”) is because “w” as a consonant is actually pronounced as “u”.
The standard pinyin scheme does not accurately reflect the pronunciation similarity of Chinese characters. For example, “wa” and “hua” have very similar pronunciations. If the standard pinyin scheme is used, the pinyin edit distance would be 2 (“wa”, “hua”), whereas using our defined non-standard scheme, the edit distance is 1 (“ua”, “hua”). Therefore, adopting a non-standard pinyin scheme can more accurately describe the patterns of ASR speech errors and find an appropriate edit distance calculation scheme.
 The workflow of the fuzzy sound generator is shown in the figure above. The input text is “Xiao Ai, please play music”. Suppose the MASK position randomly lands on “ai”. At fuzzy level 1, the candidates with the same pronunciation as “ai” are {“ai”, “ai”, “ai”, “ai”, …}. Based on the n-gram language model, the most likely replacement word is chosen from the fuzzy candidate set. If the computed word sequence probability is highest for “ai”, then “ai” is replaced with “ai”, and the final output is “Xiao Ai, please play music”.
We manually labeled some ASR erroneous sample data, studying the characteristics of initials and finals, such as the recognition errors arising from flat retroflex and front-back nasal sounds. Given the limited amount of manually annotated data, we adjusted the hyperparameters of the fuzzy sound generator (number of MASKs, ratio of fuzzy sounds, etc.) to make the distribution of generated erroneous samples as close as possible to the actual data distribution of erroneous samples in the ASR system, so that the error correction model can be more easily applied to the ASR recognition correction task.
3. Error Correction Discriminator
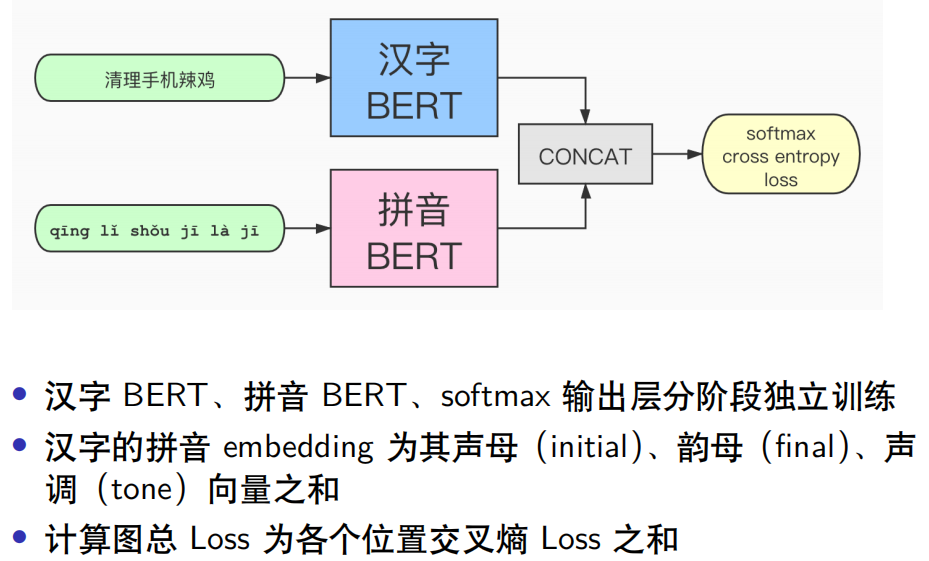
The structure of the error correction discriminator is shown in the figure above. The input data consists of features from Chinese characters and pinyin, where the Chinese characters are processed through the BERT pre-training model to obtain word vectors, and the pinyin data is retrained using the BERT model to obtain word vectors about pinyin. The two are concatenated and passed through a Softmax layer to calculate cross-entropy loss.
Why use pinyin data? This is because the correct pronunciation of characters is generally quite similar, allowing the use of pinyin to narrow the search range for the correct words. Hence, pinyin is an important feature. Moreover, after experimentation, training pinyin and Chinese characters separately and then concatenating the extracted features yielded better results than other combinations. This approach is similar to an Ensemble model. First, an end-to-end error correction model BERT is trained using Chinese character corpus, followed by training a pinyin-to-Chinese decoder model. The two models are concatenated and trained through the output layer softmax for cross-entropy loss at each position. This differs from the native BERT model, which only calculates the loss at MASK positions, resembling the loss function of the ELECTRA model.
Regarding the processing of pinyin features, a reasonable approach is to split pinyin into initials, finals, and tones, obtaining embedding representation vectors based on pronunciation features, ensuring that embedding vectors for similar pronunciations are as close as possible. Since there are only a limited number of pinyin representations, the grid formed by all initials and finals is also limited, and since the writing of pinyin does not vary much, it is reasonable to split into initials, finals, and tones for embedding. If training is done directly on pinyin, the resulting embedding vectors cannot represent similar pronunciations.
4. Performance of Evaluation Set
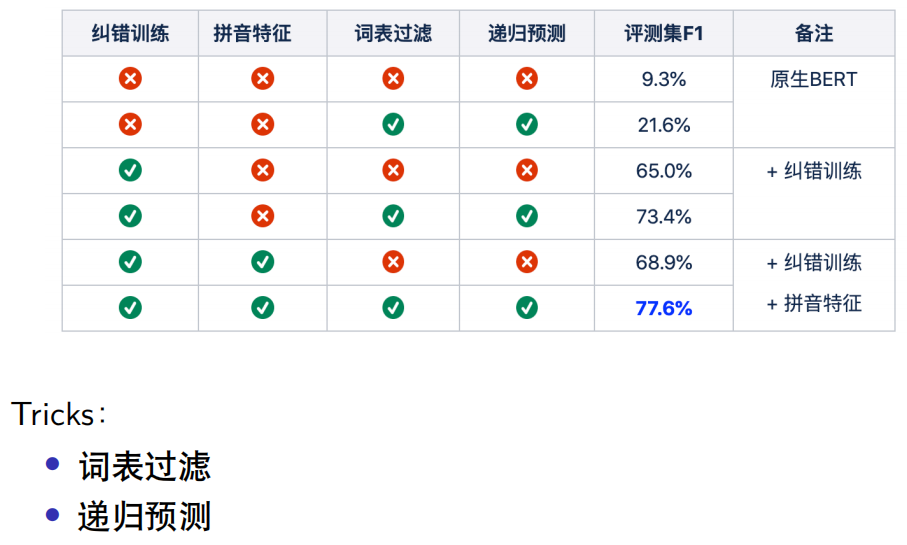
The model utilized two tricks:
If the vocabulary is large, such as 10,000 dimensions, to limit the search range of the end-to-end error correction model during correction, vocabulary constraints can be added, allowing selection only from the filtered 300 or even dozens of similar words. Theoretically, this may result in a loss of recall, but the accuracy of corrections significantly improves, and this level of filtering can be adjusted. Practical evaluations show that adding vocabulary filtering significantly enhances the model’s effectiveness and performance.
BERT performs one-to-one corrections. If a sentence contains multiple erroneous positions, the end-to-end model may only correct one position during a single Feed Forward process. To achieve overall correction of the sentence, the corrected results must be reintegrated into the sentence and input back into the model for recursive correction. If the results of two recursive predictions are the same, the recursive correction stops; otherwise, it can be recursively corrected up to 3 times.
Results show that after fine-tuning the native BERT model directly for correction, the model evaluation index was 9.3%. After adding vocabulary filtering and recursive prediction, the F1 score increased to 21.6%. After adding error correction training, the F1 score significantly increased to 65%. With the addition of tricks, it further improved to 73.4%, and after incorporating pinyin feature data, the effect improved significantly, raising the F1 score to 77.6%.
5. Performance of Error Correction
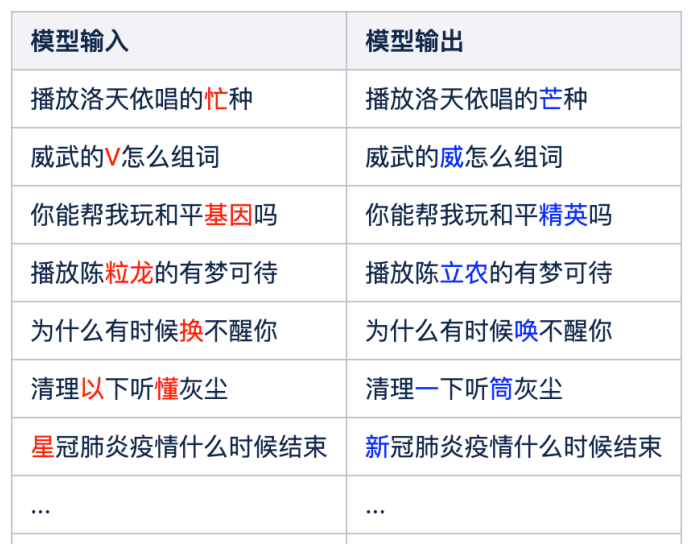
From the examples of error correction in the table, it can be seen that the previously analyzed ASR recognition error types of queries can basically be corrected, such as “Play the song Lu Tianyi sings Mang Zhong” being corrected to “Play the song Lu Tianyi sings Mang Zhong“, “Can you help me play Peace Gene?” corrected to “Can you help me play Peace Elite?”, and “Clean up listening dust” corrected to “Clean up listening earpiece” etc.
Although no knowledge base was introduced, the model still manages to correct high-frequency knowledge in the data distribution, such as “Mang Zhong”, “Peace Elite”, and “COVID-19”, which have a relatively high representation in the corpus. However, for tail knowledge, the model’s correction effectiveness is not ideal.
The workflow of the fuzzy sound generator is shown in the figure above. The input text is “Xiao Ai, please play music”. Suppose the MASK position randomly lands on “ai”. At fuzzy level 1, the candidates with the same pronunciation as “ai” are {“ai”, “ai”, “ai”, “ai”, …}. Based on the n-gram language model, the most likely replacement word is chosen from the fuzzy candidate set. If the computed word sequence probability is highest for “ai”, then “ai” is replaced with “ai”, and the final output is “Xiao Ai, please play music”.
We manually labeled some ASR erroneous sample data, studying the characteristics of initials and finals, such as the recognition errors arising from flat retroflex and front-back nasal sounds. Given the limited amount of manually annotated data, we adjusted the hyperparameters of the fuzzy sound generator (number of MASKs, ratio of fuzzy sounds, etc.) to make the distribution of generated erroneous samples as close as possible to the actual data distribution of erroneous samples in the ASR system, so that the error correction model can be more easily applied to the ASR recognition correction task.
3. Error Correction Discriminator
The structure of the error correction discriminator is shown in the figure above. The input data consists of features from Chinese characters and pinyin, where the Chinese characters are processed through the BERT pre-training model to obtain word vectors, and the pinyin data is retrained using the BERT model to obtain word vectors about pinyin. The two are concatenated and passed through a Softmax layer to calculate cross-entropy loss.
Why use pinyin data? This is because the correct pronunciation of characters is generally quite similar, allowing the use of pinyin to narrow the search range for the correct words. Hence, pinyin is an important feature. Moreover, after experimentation, training pinyin and Chinese characters separately and then concatenating the extracted features yielded better results than other combinations. This approach is similar to an Ensemble model. First, an end-to-end error correction model BERT is trained using Chinese character corpus, followed by training a pinyin-to-Chinese decoder model. The two models are concatenated and trained through the output layer softmax for cross-entropy loss at each position. This differs from the native BERT model, which only calculates the loss at MASK positions, resembling the loss function of the ELECTRA model.
Regarding the processing of pinyin features, a reasonable approach is to split pinyin into initials, finals, and tones, obtaining embedding representation vectors based on pronunciation features, ensuring that embedding vectors for similar pronunciations are as close as possible. Since there are only a limited number of pinyin representations, the grid formed by all initials and finals is also limited, and since the writing of pinyin does not vary much, it is reasonable to split into initials, finals, and tones for embedding. If training is done directly on pinyin, the resulting embedding vectors cannot represent similar pronunciations.
4. Performance of Evaluation Set
The model utilized two tricks:
If the vocabulary is large, such as 10,000 dimensions, to limit the search range of the end-to-end error correction model during correction, vocabulary constraints can be added, allowing selection only from the filtered 300 or even dozens of similar words. Theoretically, this may result in a loss of recall, but the accuracy of corrections significantly improves, and this level of filtering can be adjusted. Practical evaluations show that adding vocabulary filtering significantly enhances the model’s effectiveness and performance.
BERT performs one-to-one corrections. If a sentence contains multiple erroneous positions, the end-to-end model may only correct one position during a single Feed Forward process. To achieve overall correction of the sentence, the corrected results must be reintegrated into the sentence and input back into the model for recursive correction. If the results of two recursive predictions are the same, the recursive correction stops; otherwise, it can be recursively corrected up to 3 times.
Results show that after fine-tuning the native BERT model directly for correction, the model evaluation index was 9.3%. After adding vocabulary filtering and recursive prediction, the F1 score increased to 21.6%. After adding error correction training, the F1 score significantly increased to 65%. With the addition of tricks, it further improved to 73.4%, and after incorporating pinyin feature data, the effect improved significantly, raising the F1 score to 77.6%.
5. Performance of Error Correction
From the examples of error correction in the table, it can be seen that the previously analyzed ASR recognition error types of queries can basically be corrected, such as “Play the song Lu Tianyi sings Mang Zhong” being corrected to “Play the song Lu Tianyi sings Mang Zhong“, “Can you help me play Peace Gene?” corrected to “Can you help me play Peace Elite?”, and “Clean up listening dust” corrected to “Clean up listening earpiece” etc.
Although no knowledge base was introduced, the model still manages to correct high-frequency knowledge in the data distribution, such as “Mang Zhong”, “Peace Elite”, and “COVID-19”, which have a relatively high representation in the corpus. However, for tail knowledge, the model’s correction effectiveness is not ideal.
04
Future Directions

-
Despite following the current settings for NLP error correction models, there are still certain limitations in correction. Future considerations could include BERT-Decoder structured models like GPT series models, as BERT-Decoder is a seq2seq model that is not limited to one-to-one correction.
-
The current model’s domain knowledge is reflected by the corpus used in training, so it cannot correct niche or long-tail distribution data. To address this issue, we can refer to ASR’s Contextual attention-based methods to introduce domain knowledge into the correction model through a specific structural model, forcing the model to rely on domain knowledge for error correction.
-
The model needs real-time updates; for example, the trending topic “The Rumored Chen Qianqian” is recognized by ASR as “The Rumored Cheng Xianxian”, which is caused by the ASR model’s delayed response to current events. If the NLP corpus used for correction is also historical information, it becomes difficult to correct such problems. If we merely collect new corpus to update the entire model, it becomes challenging to achieve real-time updates for such large and cumbersome models. Therefore, we need to explore a structure or mechanism that allows the model to adapt to the latest trending topics by updating only a small amount of information.
These three directions are key considerations for the future. Additionally, we can replace the n-gram language model used in the model with other strong language models, increasing the task difficulty, which may improve the performance of the error correction task.
That’s all for today’s presentation, thank you all!

Wei Tianwen
Xiaomi AI Department | Head of Xiao Ai Basic Algorithm Team
Graduated with a bachelor’s degree from the Mathematics Department of Wuhan University and a PhD from the Mathematics Department of Lille 1 University in France. His main research areas include Independent Component Analysis, Unsupervised Representation Learning, Language Models, etc., with several papers published in renowned academic journals or conferences such as IEEE Trans. Information Theory, IEEE Trans. Signal Processing, ICASSP, etc. Wei Tianwen joined Xiaomi AI Department in 2018 and is currently responsible for the R&D and implementation of algorithms related to Xiao Ai’s language model.
05
References
1.S. Shalev-Shwartz and S. Ben-David (2014) . Understanding Machine Learning: From Theory to Algorithm.
2.Devlin J, Chang M W, Lee K, et al(2017). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J].
3.K.Clark et al (2019) .ELECTRA: Pretraining Text Encoders as Discriminators Rather Than Generators.
4.Zhang Shaohua et al (2020) Spelling Error Correction with Soft-Masked BERT.
At the end of the article, please share, like, and give a thumbs up~
Conference Recommendation:

The annual DataFun conference is now online, with over 100 guests participating in informative sharing. Click the image for details~
Community Recommendation:
Welcome to join the DataFunTalk NLP discussion group for face-to-face exchanges with peers. If you would like to join the group, please scan the QR code below and follow the prompts to join the group independently.
Natural Language Understanding in the Music Domain
About Us:
DataFunTalk focuses on sharing and communicating applications of big data and artificial intelligence technologies. Initiated in 2017, over 100 offline salons, forums, and summits have been held in cities like Beijing, Shanghai, Shenzhen, and Hangzhou, inviting nearly 500 experts and scholars to share. Its WeChat public account DataFunTalk has produced over 300 original articles, with over a million readings and more than 60,000 precise followers.

🧐Share, like, and give a thumbs up, and give a triple hit! 👇