
Machine Heart Column
Author: Xiaomi AI Lab NLP Team
When a technology is applied in practice, it often encounters various challenges. Taking BERT as an example, when adapting to business needs, engineers need to make various adjustments according to specific scenarios. This article introduces the practical exploration of the Xiaomi AI Lab NLP team in applying BERT.

-
Query Text/Slot Labels: Play Zhang Jie/b-music_artist/b-mobileVideo_artist Zhang/i-music_artist/i-mobileVideo_artist’s song
-
Intent Category: music
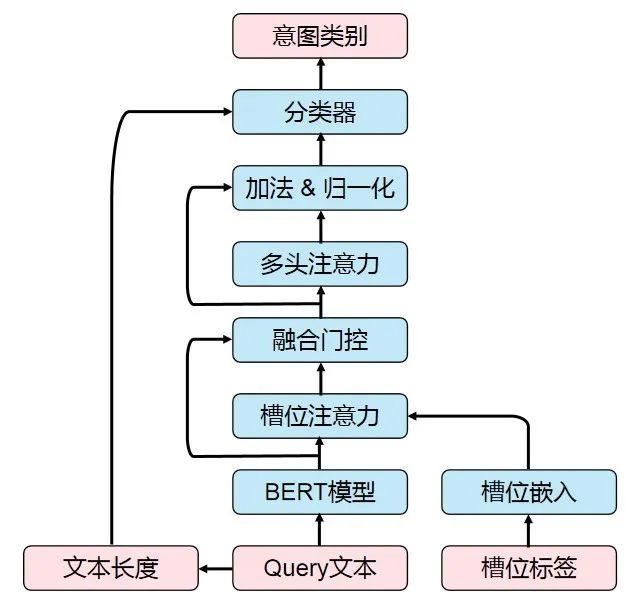
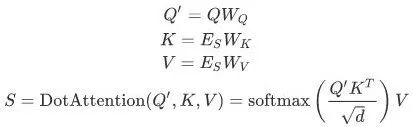
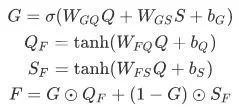
-
Query Text: Play Zhang Jie’s
-
Completion Label: incomplete
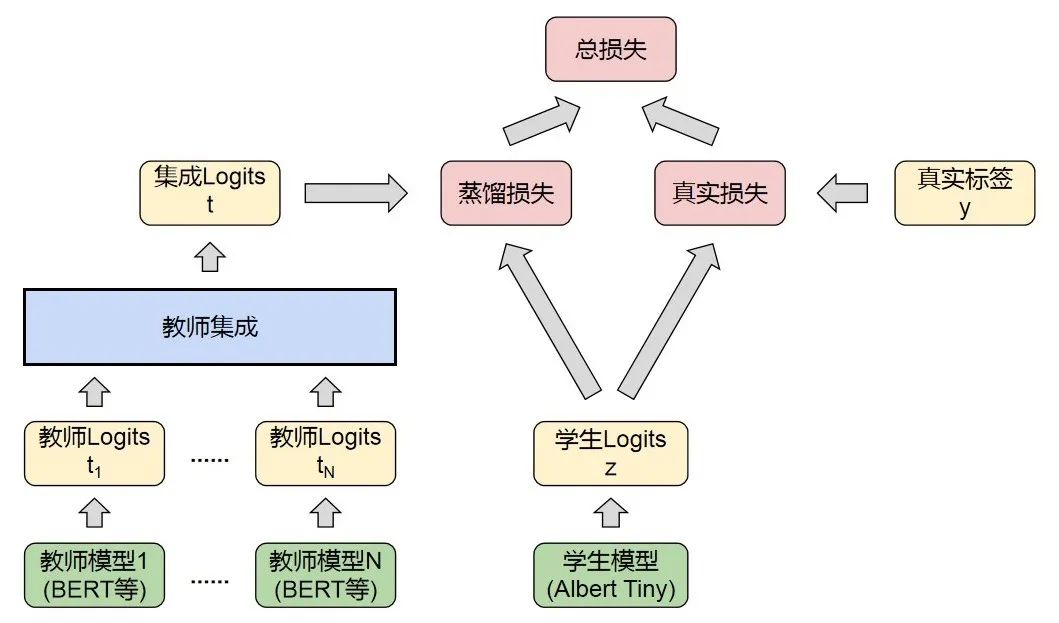
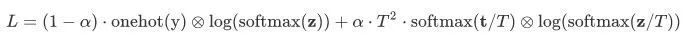
-
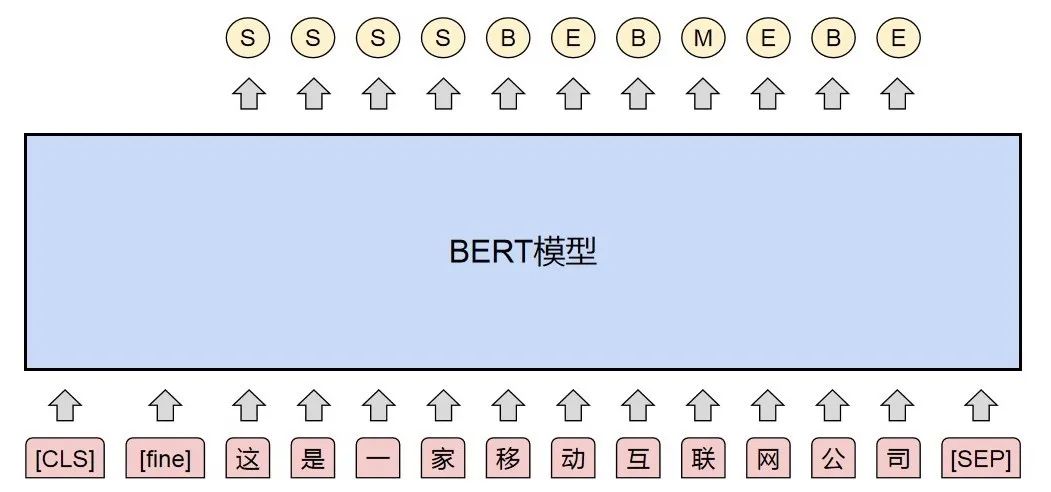
Text: This is a mobile internet company
-
Coarse Granularity Segmentation: This/Is/A/Mobile Internet/Company
-
Fine Granularity Segmentation: This/Is/A/Company/Mobile/Internet
-
Fine Granularity Segmentation Labels: This/S Is/S A/S Company/Mobile/B Internet/E Company/E