
Original: https://zhuanlan.zhihu.com/p/682253496
Compiled by: Qingke AI
Leave a message in the backend ‘ Exchange ‘, Join the NewBee discussion group
1. Background Introduction
RAG (Retrieval Augmented Generation) method refers to a combination of retrieval-based models and generative models to improve the quality and relevance of generated text. This method was proposed by Meta in the 2020 paper “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”[1], which allows LM (Language Model) to access information beyond internalized knowledge and enables LM to answer questions more accurately based on specialized knowledge bases. In the era of large models, it is a necessary technology to solve various limitations or shortcomings of large models, such as hallucination issues, knowledge timeliness, and ultra-long text problems.
2. Challenges of RAG
RAG mainly faces three challenges: retrieval quality, enhancement process, and generation quality.
2.1 Retrieval Quality
-
• Semantic Ambiguity: Vector representations (e.g., word embeddings) may fail to capture the subtle differences between concepts. For example, the word “apple” may refer to either a fruit or a tech company. The embeddings may confuse these meanings, leading to irrelevant results.
-
• User Input Complexity: Unlike traditional keyword or phrase search logic, user queries are no longer just words or short phrases, but have transformed into natural conversational knowledge with multi-turn dialogue data, making the form of questions more diverse and closely related to context, with a more colloquial input style.
-
• Document Segmentation: Document segmentation mainly has two methods: one is form-based segmentation, such as using punctuation and paragraph endings; the other is meaning-based segmentation according to the content of the document. How to convert these document chunks into a form that can be understood and compared by computers (i.e., “embedding”), which in turn affects how well these chunks match the user’s search content.
-
• Extraction and Representation of Multi-modal Content (e.g., tables, charts, formulas, etc.): How to extract and dynamically represent multi-modal content is a practical issue currently faced, especially in handling ambiguous or negative queries, which significantly impacts the performance of the RAG system.
2.2 Enhancement Process
-
• Integration of Context: The challenge here is to smoothly integrate the context of retrieved paragraphs with the current generation task. If done poorly, the output may appear disjointed or lack coherence.
-
• Redundancy and Repetition: If multiple retrieved paragraphs contain similar information, the generation step may produce repetitive content.
-
• Ranking and Prioritization: Determining the importance or relevance of multiple retrieved paragraphs for the generation task can be challenging. The enhancement process must appropriately weigh the value of each paragraph.
2.3 Generation Quality
-
• Over-reliance on Retrieved Content: The generative model may become overly dependent on enhanced information, exacerbating hallucination issues rather than adding value or providing synthesis.
-
• Irrelevance: This is another concerning issue, where the model’s generated answers fail to address the query.
-
• Toxicity or Bias: This is also another issue, where the model’s generated answers are harmful or offensive.
3. Overall Architecture
3.1 Product Architecture
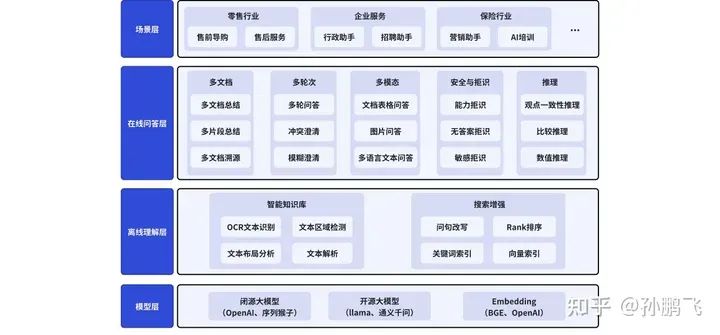
From the figure, it is clear that the entire product architecture consists of the following four layers:
-
• The bottom layer is the Model Layer. In the model layer, the differences between models are masked, supporting not only self-developed sequence monkeys but also open-source large models and third-party models. Additionally, to optimize the embedding effect, a cross-language embedding model is proposed, effectively solving cross-language retrieval issues while improving model performance.
-
• Offline Understanding Layer. This layer is primarily designed around two modules: intelligent knowledge base and search enhancement. The intelligent knowledge base is mainly responsible for processing unstructured text to transform it into a retrieval knowledge base, including text parsing, table recognition, OCR recognition, etc. Search enhancement ensures retrieval accuracy by introducing modules such as question rewriting and reordering.
-
• Online Q&A Layer, in order to meet product design needs, supports multi-document, multi-turn, multi-modal, and security and rejection features, thereby enhancing the product’s competitiveness while meeting user needs in different scenarios.
-
• Scenario Layer, which pre-configures various scenario roles based on the characteristics of different industries, lowering the product’s usage threshold.
3.2 Technical Architecture
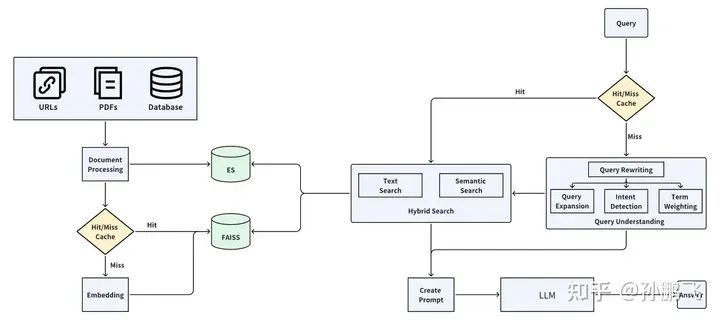
To understand the retrieval-augmented generation framework, we divide it into three main components: query understanding, retrieval model, and generation model.
-
• Query Understanding: This module aims to understand the user’s query or generate a structured query from the user’s query, which can query both structured databases and unstructured data, thereby improving recall rates. This module includes four parts: query rewriting, query expansion, and intent recognition. We will introduce each module in detail in the subsequent chapters.
-
• Retrieval Model: This model aims to retrieve relevant information from a given document set or knowledge base. They typically use information retrieval or semantic search techniques to identify the most relevant information based on a given query. Retrieval-based models excel at finding accurate and specific information but lack the ability to generate creative or novel content. Technically, the retrieval model mainly includes document loading, text conversion, embedding, etc. We will elaborate on these in later chapters.
-
• Generation Model: This model aims to generate new content based on a given prompt or context. Currently, generative models can produce creative and coherent text, but they may struggle with factual accuracy or relevance to specific contexts. In the RAG framework, the generative model mainly includes chat systems (long-term memory and short-term memory), prompt optimization, etc. These will also be discussed in subsequent chapters.
In summary, retrieval-augmented generation combines the advantages of retrieval models and generative models, overcoming their respective limitations. In this framework, retrieval-based models are used to retrieve relevant information from a knowledge base or a set of documents based on a given query or context. The retrieved information is then used as input or additional context for the generative model. By integrating the retrieved information, the generative model can leverage the accuracy and specificity of retrieval-based models to generate more relevant and accurate text. This helps the generative model to base its output on existing knowledge, generating text consistent with the retrieved information.
4. Query Understanding
Currently, RAG systems may encounter retrieving content from the knowledge base that is irrelevant to the user’s query. This is due to the following issues: (1) The wording of user questions may not be conducive to retrieval, (2) structured queries may need to be generated from user questions. To address the above issues, we introduce the query understanding module.
4.1 Intent Recognition
Intent recognition refers to receiving the user’s query and a set of “choices” (defined by metadata) and returning one or more selected “choice modules”. It can be used alone (as a “selector module”) or as part of a query engine or retriever (e.g., on top of other query engines/retrievers). It is a simple yet powerful module, currently mainly utilizing LLM to achieve decision-making functionality.
It can be applied in the following scenarios:
-
• Selecting the correct data source among various data sources;
-
• Deciding whether to summarize (e.g., using summary index query engines) or to perform semantic search (e.g., using vector index query engines);
-
• Deciding whether to “try” multiple choices at once and merge the results (using multi-routing functionality).
The core modules have the following forms:
-
• LLM selector dumps choices as text into the prompt and uses LLM to make decisions;
-
• Building traditional classification models, including semantic matching-based classification models, Bert intent classification models, etc.
4.2 Query Rewriting
This module mainly utilizes LLM to rephrase the user’s query rather than directly using the original user query for retrieval. This is because, for RAG systems, the original query in the real world may not always be the best retrieval condition.
4.2.1 HyDE[2]
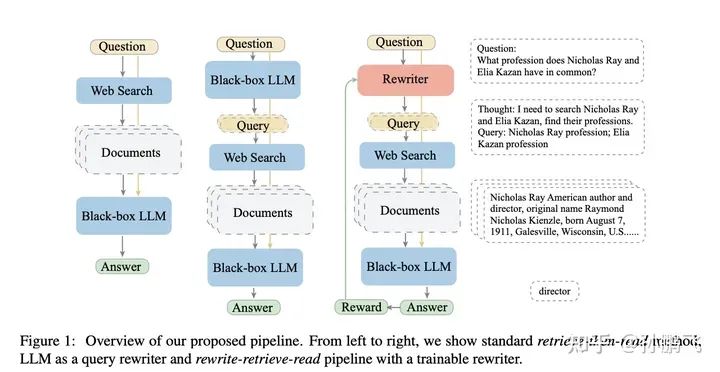
Hypothetical Document Embeddings (HyDE) is a technique for generating document embeddings to retrieve relevant documents without requiring actual training data. First, LLM creates a hypothetical answer in response to the query. While this answer reflects patterns relevant to the query, the information it contains may not be accurate in fact. Next, both the query and the generated answer are converted into embeddings. The system then identifies and retrieves the actual documents closest to these embeddings in the predefined database.
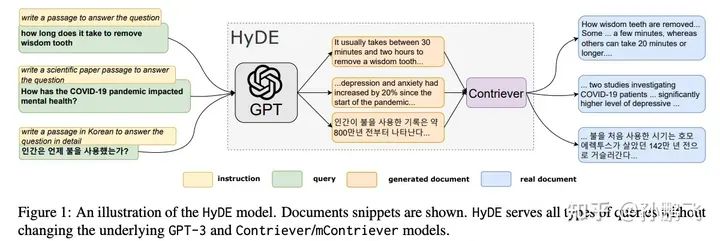
4.2.2 Rewrite-Retrieve-Read[3]
This work introduces a new framework—Rewrite-Retrieve-Read, which improves the retrieval augmentation method from the perspective of query rewriting. Previous research mainly adjusted the retriever or LLM. In contrast, this method focuses on the adaptability of the query. Because for LLM, the original query is not always the best retrieval result, especially in the real world. First, LLM is used to rewrite the query, and then retrieval augmentation is performed. Meanwhile, to further enhance the rewriting effect, a small language model (T5) is applied as a trainable rewriter to adapt the search query to meet the needs of the frozen retriever and LLM. To fine-tune the rewriter, this method also uses pseudo data for supervised warm-up training. Then, the “retrieve-then-generate” pipeline is modeled as a reinforcement learning environment. By maximizing the reward for pipeline performance, the rewriter is further trained as a policy model.
4.3 Query Expansion
This module is mainly to decompose complex problems into sub-problems. This technique uses a divide-and-conquer approach to handle complex issues. It first analyzes the problem and breaks it down into simpler sub-problems, each of which retrieves answers from relevant documents that provide partial answers. Then, these intermediate results are collected, and all partial results are combined into the final response.
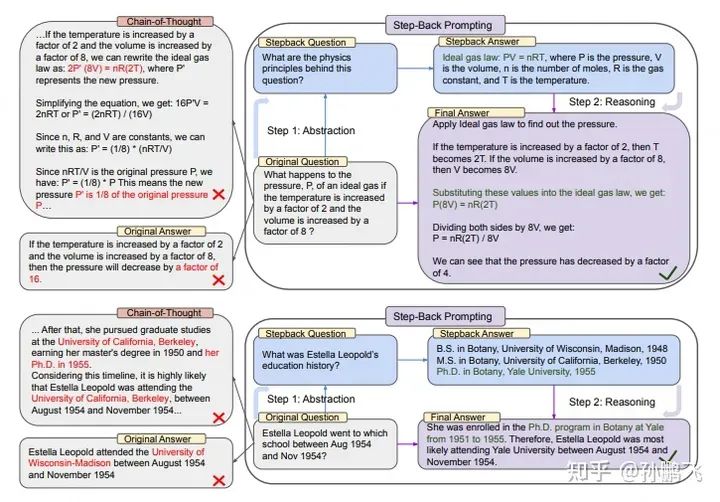
4.3.1 Step-Back Prompting[4]
This work explores how LLM handles complex tasks involving many low-level details through two steps: abstraction and reasoning. The first step is to use LLM to “step back” and generate high-level abstract concepts, building reasoning on the basis of abstract concepts to reduce the probability of errors in intermediate reasoning steps. This method can be used both in retrieval and non-retrieval situations. When used in retrieval, both the abstract concepts and the original problem are used for retrieval, and then these two results are used as the basis for LLM responses.
4.3.2 CoVe[5]
Chain of Verification (CoVe) aims to improve the reliability of answers provided by large language models by systematically verifying and refining responses to minimize inaccuracies, especially in factual question and answer scenarios. The underlying concept is based on the idea that responses generated by large language models (LLMs) can be used to verify themselves. This self-verification process can be used to assess the accuracy of initial responses and make them more precise.
In the RAG system, in response to increasingly complex issues in users’ real scenarios, CoVe technology is referenced to break down complex prompts into multiple independent and search-friendly queries, allowing LLM to perform targeted knowledge base searches for each sub-query, ultimately providing more accurate and detailed answers while reducing hallucination output.

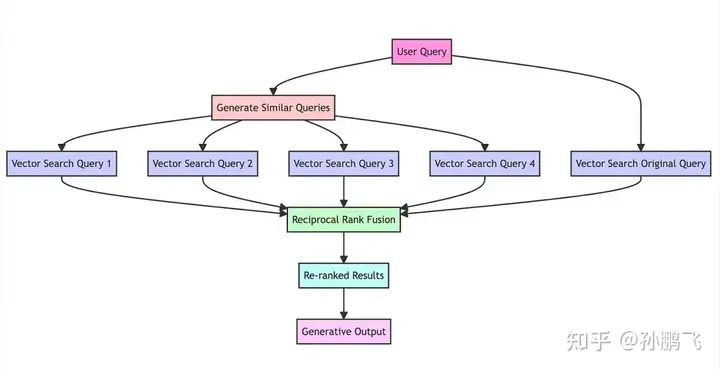
4.3.3 RAG-Fusion[6]
In this method, the original query is processed by LLM to generate multiple queries. These search queries can then be executed in parallel, and the retrieved results are passed together. This method is particularly useful when one question may depend on multiple sub-questions. RAG-Fusion represents this method, which is a search approach aimed at bridging the gap between traditional search paradigms and the multifaceted nature of human queries. This method first uses LLM to generate multiple queries, then uses Reciprocal Rank Fusion (RRF) to reorder them.
4.3.4 ReAct[7]
Recently, in the RAG system, the ReAct concept has been used to break down complex queries into simpler “sub-queries,” where different parts of the knowledge base may answer different “sub-queries” around the entire query. This is particularly useful for composite graphs. In a composite graph, a query can route to multiple sub-indices, each representing a subset of the entire knowledge corpus. By decomposing the queries, we can transform the queries into more suitable questions within any given index.
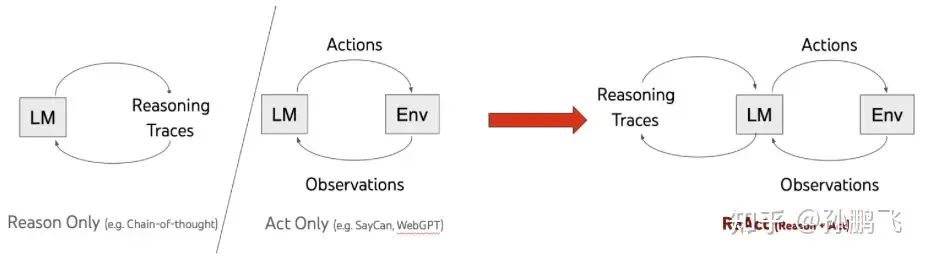
The ReAct model is illustrated in the above figure, combining Chain of Thought (CoT) prompting with Action plan generation to enhance and complement each other, improving the ability of large models to solve problems. The reasoning tracking of CoT helps the model induce, track, and update action plans while handling anomalies. Action operations allow it to interface with external sources such as knowledge bases or environments and gather additional information.
4.4 Query Reconstruction
Considering the overall pipeline efficiency of the Query Understanding module, we have developed a Query Reconstruction module based on the core ideas of Query Rewriting and Query Expansion. This module emphasizes rewriting, decomposing, and expanding the original user’s input of complex problems through a single request, digging deeper into the user’s underlying sub-questions, thereby leveraging the higher retrieval effectiveness of sub-questions to address the issue of retrieval quality deviation for complex problems, aiming to improve the accuracy and efficiency of queries.
5. Retrieval Model
5.1 Challenges of Retrieval Model
-
• Dependency on whether the vectorization of the embedding model is accurate
-
• Dependency on whether the external data has reasonable segmentation (not all knowledge can be transformed into one vector, but data needs to be segmented and then transformed before being stored in the vector database)
-
• Dependency on prompt concatenation, when we rank the most similar documents returned and send them to the large model along with the user’s question, we actually want the large model to accurately recognize and locate the appropriate content to answer within the long context.
The paper “Lost in the Middle: How Language Models Use Long Contexts”[8] points out that performance is often highest when relevant information appears at the beginning or end of the input context, while performance significantly declines when the model must retrieve relevant information from the middle of a long context, even for clearly defined long context models.
5.2 Architecture
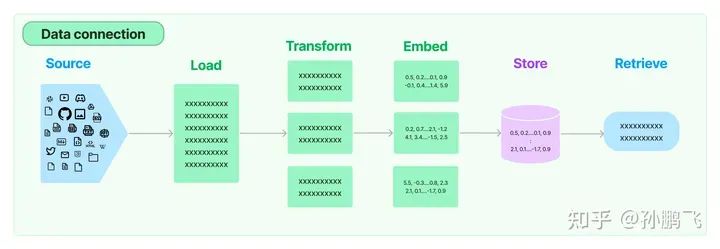
5.3 Document Loader
The document loader provides a “loading” method to load document data from configured sources. Document data consists of a piece of text and relevant metadata. Document loaders can load documents from various sources. For example, some document loaders can load simple .txt files or load the text content of any webpage, even loading transcripts of YouTube videos. Additionally, document loaders can choose to implement “lazy loading” to load data into memory lazily.
5.4 Text Converter
A key part of retrieval is to only obtain relevant parts of the document. When documents are loaded, they usually need to be converted to better fit the application. This involves several conversion steps to prepare the retrieved documents. One of the main steps is to segment (or chunk) large documents into smaller blocks, i.e., the text converter. The simplest example is when long texts need to be processed, it is necessary to break the text into several chunks so that it can fit into the model’s context window. Ideally, semantically related text segments are grouped together. This sounds simple, but the potential complexity is significant.
5.4.1 How It Works
-
• Segment the text into semantically meaningful small chunks (usually sentences).
-
• Start combining these small chunks into a larger chunk until a certain size is reached (using some function to measure).
-
• Once a certain size is reached, that chunk is treated as its own text, then new chunks with some overlap are created (to maintain context between chunks).
5.4.2 Common Types of Text Converters
| Name | Splits On | Adds Metadata | Description |
| Recursive | A list of user-defined characters | Recursively splits text. Splitting text recursively serves the purpose of trying to keep related pieces of text next to each other. This is the recommended way to start splitting text. | |
| HTML | HTML specific characters | ✅ | Splits text based on HTML-specific characters. Notably, this adds in relevant information about where that chunk came from (based on the HTML) |
| Markdown | Markdown specific characters | ✅ | Splits text based on Markdown-specific characters. Notably, this adds in relevant information about where that chunk came from (based on the Markdown) |
| Code | Code (Python, JS) specific characters | Splits text based on characters specific to coding languages. 15 different languages are available to choose from. | |
| Token | Tokens | Splits text on tokens. There exist a few different ways to measure tokens. | |
| Character | A user-defined character | Splits text based on a user-defined character. One of the simpler methods. | |
| [Experimental] Semantic Chunker | Sentences | First splits on sentences. Then combines ones next to each other if they are semantically similar enough. Taken from Greg Kamradt |
5.4.3 Evaluating Text Converters
You can use the Chunkviz tool created by Greg Kamradt to evaluate text converters. Chunkviz is a tool for visualizing how text converters work. It can show you how the text is segmented and help you adjust the segmentation parameters.
5.5 Text Embedding Model
Another key part of retrieval is the document embedding model. The document embedding model creates a vector representation of a piece of text. It can capture the semantics of the text, allowing you to quickly and efficiently find similar other segments within the text. This is very useful because it means we can think of text in vector space and perform operations such as semantic search.
Ideally, the retriever should have the ability to correlate translated texts in different languages (cross-language retrieval capability), correlate long original texts with short summaries, correlate texts with different expressions but the same semantics, correlate different questions with the same intent, and correlate questions with possible answer texts. Additionally, to provide the large model with the highest quality knowledge snippets, the retriever should also provide as many relevant snippets as possible, and truly useful snippets should be positioned higher, filtering out low-quality text snippets. Finally, we expect our model to cover as many fields and scenarios as possible, achieving a model that seamlessly integrates multiple business scenarios, allowing users to obtain a plug-and-play model without needing further fine-tuning.
5.6 Vector Database
With the rise of embeddings, there is a growing need for vector databases to support the efficient storage and search of these embeddings. One of the most common methods for storing and searching unstructured data is to embed the data and store the resulting embedding vectors, then embed the unstructured query during querying and retrieve the embedding vectors that are “most similar” to the embedded query. The vector database is responsible for storing embedded data and performing vector searches.
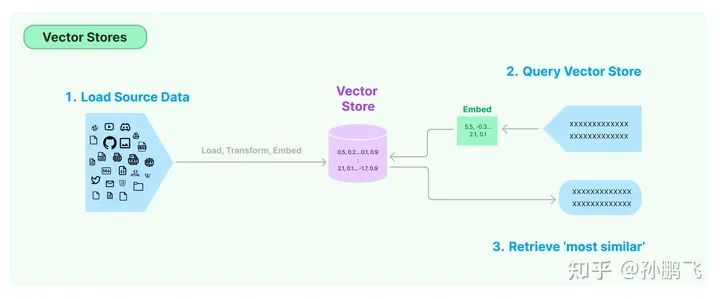
5.7 Indexing
After the previous data reading and text chunking operations, the processed data needs to be indexed. Indexing is a data structure used for rapid retrieval of text content relevant to user queries. It is one of the core foundational components of retrieval-augmented LLMs.
Below are several common indexing structures. To illustrate different indexing structures, the concept of a node (Node) is introduced. Here, a node is the text chunk generated from the document segmentation in previous steps. The following index structure diagram comes from LlamaIndex’s “How Each Index Works”[9].
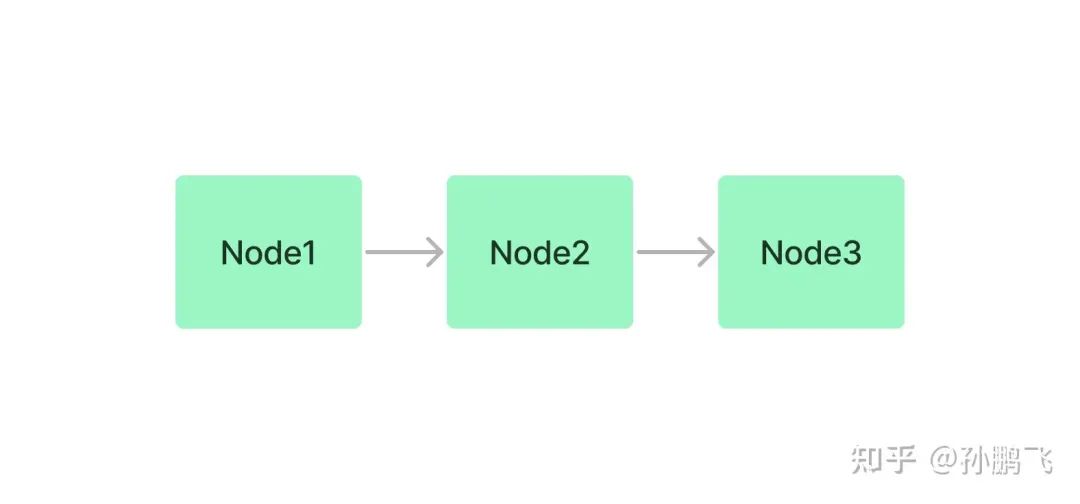
5.7.1 Summary Index (formerly known as Chain Index)
Summary index simply stores nodes as a sequential chain. In subsequent retrieval and generation phases, all nodes can be simply traversed sequentially, or filtered based on keywords.
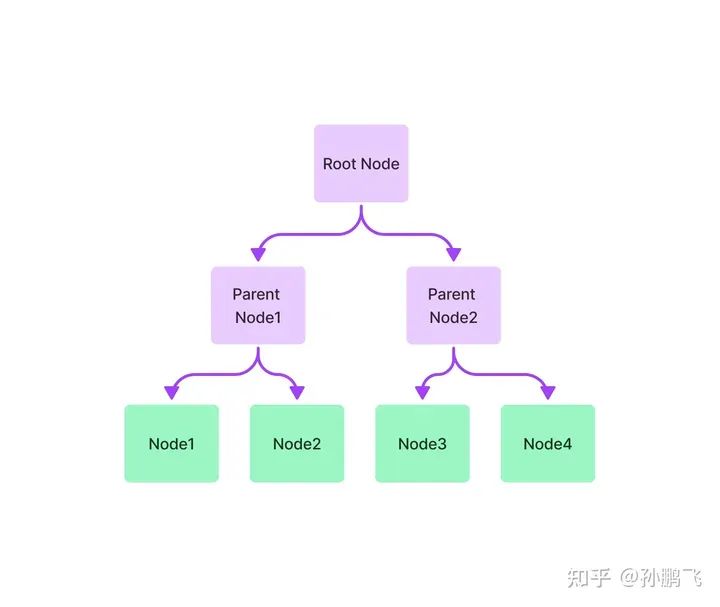
5.7.2 Tree Index
Tree index builds a hierarchical tree index structure from a set of nodes (text chunks), constructed upwards from leaf nodes (original text chunks), where each parent node is a summary of its child nodes. In the retrieval phase, traversal can be performed from the root node downwards or directly using the information from the root node. Tree indexing provides a more efficient way to query long text chunks and can also be used to extract information from different parts of the text. Unlike chain indexing, tree indexing does not require sequential querying.
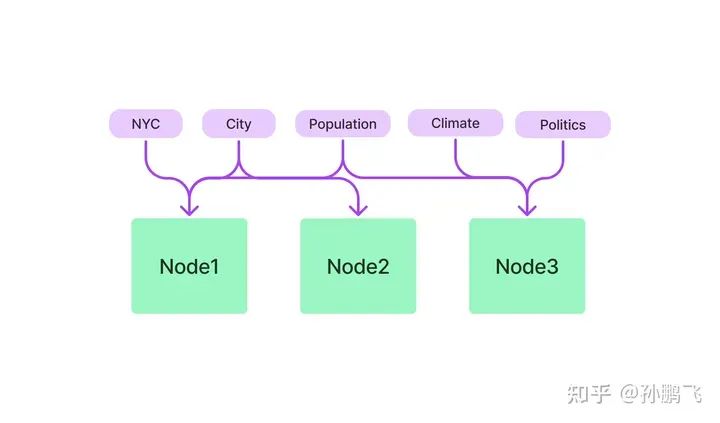
5.7.3 Keyword Table Index
Keyword table index extracts keywords from each node, constructing a many-to-many mapping from each keyword to the corresponding nodes, meaning each keyword may point to multiple nodes, and each node may contain multiple keywords. In the retrieval phase, nodes can be filtered based on keywords present in the user’s query.
5.7.4 Vector Index
Vector index is currently one of the most popular indexing methods. This method typically uses text embedding models to map text chunks into a fixed-length vector, which is then stored in a vector database. During retrieval, the user query text is mapped into a vector using the same embedding model, and then the most similar one or more nodes are retrieved based on vector similarity calculation.
5.8 Ranking and Post-processing
After the previous retrieval process, many relevant documents may be obtained, which need to be filtered and ranked. Common filtering and ranking strategies include:
-
• Filtering and ranking based on similarity scores
-
• Filtering based on keywords, such as limiting to include or exclude certain keywords
-
• Allowing LLM to re-rank based on the returned relevant documents and their relevance scores
-
• Filtering and ranking based on time, such as only selecting the most recent relevant documents
-
• Weighting similarity by time and then performing sorting and filtering
6. Generation Model
6.1 Reply Generation Strategies
The retrieval module retrieves relevant text blocks based on user queries, and the reply generation module allows LLM to utilize the retrieved relevant information to generate replies to the original queries. Here are some different reply generation strategies.
-
• One strategy is to sequentially combine each retrieved relevant text block, continuously correcting the generated reply each time. In this case, the number of independent relevant text blocks will result in that many LLM calls.
-
• Another strategy is to fill as many text blocks as possible into the prompt during each LLM call. If a prompt cannot accommodate them, similar operations can be used to construct multiple prompts, and multiple prompts can adopt the same reply correction strategy as the previous one.
6.2 Prompt Concatenation Strategy
This is used to combine different parts of prompts together. You can use string prompts or chat prompts to do this. Constructing prompts in this way makes it easy to reuse components.
6.2.1 String Prompts
When using string prompts, each template is concatenated together. You can directly use prompts or strings (the first element in the list must be a prompt). For example, the prompt template provided by langchain[10].
6.2.2 Chat Prompts
Chat prompts consist of a list of messages. Purely for developer experience, we have added a convenient way to create these prompts. In this pipeline, each new element is a new message in the final prompt. For example, the AIMessage, HumanMessage, SystemMessage provided by langchain[11].
7. Plugins (Demonstration Retriever for In-Context Learning)
In-context learning is an emerging paradigm that refers to making predictions for given test inputs by providing some demonstrative input-output pairs (examples) without updating the model parameters. Its unique ability to operate without parameter updates allows in-context learning methods to unify various natural language processing tasks through reasoning of a language model, making it a promising alternative to supervised fine-tuning.
However, while this method performs well in various natural language processing tasks, its performance depends on the given demonstrative input-output pairs. Specifying demonstrative examples for each task in the model’s prompt affects the length of the prompt, leading to increased costs for each call to the large language model, even exceeding the model’s input length. Therefore, this brings a new research direction—contextual learning based on demonstration retrieval. Such methods mainly retrieve candidate demonstrative examples that are similar to the test input in text (or semantics), adding the user’s input and obtaining similar demonstrative examples into the model prompt as the model’s input, allowing the model to provide correct predictions. However, the aforementioned single retrieval strategy results in low recall rates, causing demonstrative examples to be inaccurately recalled, leading to suboptimal model performance.
To address the above issues, we propose a hybrid demonstration retrieval-based contextual learning method. This method fully considers the strengths and weaknesses of different retrieval models and proposes a fusion algorithm that utilizes text retrieval (e.g., BM25 and TF-IDF) and semantic retrieval (e.g., OpenAI embedding-ada and sentence-bert) for multi-route recall, solving the problem of low recall rates from single routes. However, this brings new challenges in how to fuse different recall results. This is because the score ranges of different retrieval algorithms do not match, for example, text retrieval scores usually range between 0 and some maximum value (which specifically depends on the relevance of the query); while semantic search (e.g., cosine similarity) generates scores between 0 and 1, making it tricky to sort recall results directly. Therefore, we also propose a reordering method based on reciprocal rank fusion, which combines the results of different retrieval algorithms without needing to adjust the model, while considering that large models perform best when relevant information appears at the beginning or end of the input context, designing a reordering algorithm to yield high-quality fusion results.
The specific model architecture is shown in the figure below, which includes retrieval modules, reordering modules, and generation modules.
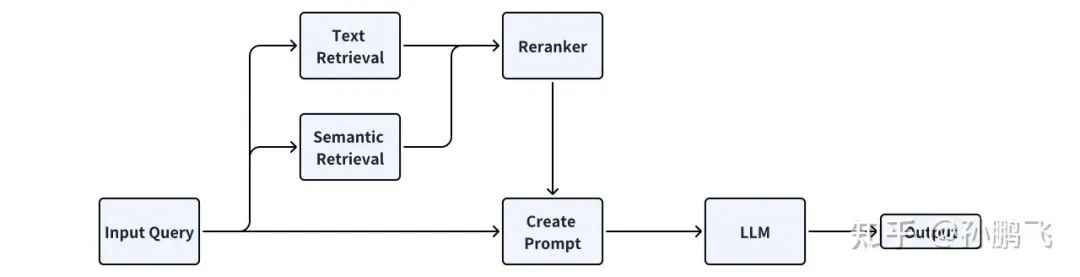
7.1 Retrieval Module
The retrieval module is further divided into text retrieval and semantic retrieval.
Semantic retrieval uses a dual-tower model, employing OpenAI’s embedding-ada as the representation model to represent the user’s input and each task’s candidate examples, obtaining semantic vectors, and then using the k-nearest neighbor algorithm (KNN) to compute semantic similarity and ranking candidate results based on similarity. For each task’s candidate example, we use offline representation and store it in the vector database, as once a task is confirmed, the candidate examples for each task remain fixed. For the user’s input, we use real-time representation to improve computational efficiency since user inputs are diverse and not fixed.
For text retrieval, we first preprocess the text of each task’s candidate examples to remove stop words, special characters, etc. Meanwhile, we employ inverted indexing technology to accelerate queries and utilize BM25 to compute text similarity, finally ranking based on similarity.
7.2 Reordering Module
For the reordering module, we propose a reordering algorithm based on reciprocal rank fusion. This method first addresses the score range mismatch issue of different recall algorithms by introducing a reciprocal rank fusion algorithm to merge and rank multi-route recall results. Although the reciprocal rank fusion algorithm can effectively merge multi-route recalls, this ranking does not satisfy the characteristic of large models performing best when relevant information appears at the beginning or end of the input context. This makes simply using reciprocal rank fusion for output ineffective. Therefore, we further reorder the results after fusion ranking, with the sorting strategy being based on the results of fusion ranking for padding at both ends. For example, the original order of [1,2,3,4,5] becomes [1,3,5,4,2] after reordering.
7.3 Generation Module
The generation module can produce creative and coherent text, aiming to generate new content based on a given prompt or context. Here, we have designed a prompt assembly module that combines the system prompt with the retrieved relevant information. Additionally, the assembly module incorporates long-term and short-term dialogue records for prompt encapsulation.
8. Citation or Attribution Generation
8.1 What is Citation or Attribution
In the context of RAG’s knowledge Q&A scenario, as more and more documents, webpages, and other information are injected into applications, more developers realize the importance of information sources, which can align the content generated by the model with the content of reference information, provide evidence sources, ensure information accuracy, and make the large model’s answers more authentic.
8.2 The Role of Attribution
-
• User Perspective: It can verify whether the model’s answers are reliable.
-
• Model Perspective: Improves accuracy and reduces hallucination.
8.3 How to Achieve Attribution
8.3.1 Model Generation
Directly let the model generate attribution information. You can add prompts like “Each generated evidence must be cited in the reference information.” This method is the simplest but also requires high instruction-following capability from the model, generally using GPT-4 for answers, or fine-tuning the model to learn to include citations in generated responses. The drawbacks are also apparent, as it heavily relies on the model’s capability (and citations may even be fabricated), and the repair cycle for bad cases encountered in real scenarios is long, with weak intervention capability.
8.3.2 Dynamic Calculation
During the model generation process, attribution information is appended. The specific operation is to judge semantic units (such as periods, paragraph breaks, etc.) in a streaming generation scenario, and when a complete semantic unit appears, match that semantic unit with each reference source in the reference information (keywords, embeddings, etc.), using a thresholding method to find the Top-N reference sources, thus appending the reference sources to the return. This method is much simpler to implement than the first method, and the repair cycle for bad cases is also short, but it is limited by the matching method and threshold, and there is a prerequisite assumption: that the model’s generated text is sourced from the reference information.
More research on attribution can refer to: A Survey of Large Language Models Attribution[12]
9. Evaluation
For developers, whether they have used TDD (Test-Driven Development) or not, they have certainly heard of its fame. Similarly, when developing large model applications, there should be a corresponding concept of MDD (Metrics-Driven Development). The most comfortable position is to pre-define the business scenarios, the data used, the set metrics, and the scores to be achieved, then proceed step by step to achieve the set goals, boosting employee morale and making the boss happy!
However, there is always a tangle between ideals and reality. For most large model development tasks, the more common situation is unclear scenario definitions, and data cleaning alone can exhaust the team, let alone the necessary metrics and goals? They haven’t even thought about it! This time, we will fill in what should have been considered from the very beginning: how to quantify business metrics for large model applications, specifically, how to quantify and prove that your RAG is indeed better than those of your competitors!
Several aspects affecting the performance of RAG systems:
-
• Position Bias: LLMs may give higher attention to content in specific positions within the text, such as content at the beginning and end of paragraphs being more likely to be adopted.
-
• Relevance of Retrieved Content: Due to the diversity of query expressions, RAG systems may retrieve irrelevant content, which adds noise to LLMs’ understanding and increases the model’s burden.
9.1 Evaluation Metrics
-
• Faithfulness refers to the measurement of whether the generated answers are faithful to contexts, which is crucial to avoid hallucinations and ensure that the retrieved context can serve as a rationale for generating answers.
-
• Answer Relevance indicates that the generated answers should address the actual questions posed.
-
• Context Relevance means that the retrieved context should highlight key points, containing as little irrelevant information as possible. Ideally, the retrieved context should only include basic information necessary for addressing the provided query. The less redundant information included, the higher the context relevance.
9.2 Evaluation Methods
9.2.1 RGB (Benchmarking Large Language Models in Retrieval-Augmented Generation)[13]
This work systematically studies the impact of retrieval-augmented generation on large language models. It analyzes the performance of different large language models in the four fundamental capabilities required by RAG, including noise robustness, refusal to answer, information integration, and counterfactual robustness, and establishes benchmarks for retrieval-augmented generation. Moreover, current RAG implementations are pipeline-based, involving multiple stages such as chunking, relevance recall, and refusal to answer, each of which can be evaluated separately. The four capabilities mentioned can indeed reflect each stage.
9.2.2 RAGAS (RAGAS: Automated Evaluation of Retrieval Augmented Generation)[14]
This work proposes a framework for reference-less evaluation of the retrieval-augmented generation (RAG) pipeline. This framework considers the ability of the retrieval system to identify relevant and key contextual paragraphs, the ability of LLMs to utilize these paragraphs faithfully, and the quality of the generation itself. Currently, this method has been open-sourced, and specific details can be found on GitHub: GitHub – exploding gradients/ragas: Evaluation framework for your Retrieval Augmented Generation (RAG) pipelines.
9.2.3 LlamaIndex-Evaluating[15]
LlamaIndex provides key modules for measuring the quality of generated results. At the same time, it also provides key modules for measuring retrieval quality.
10. Conclusion
The wave of LLM has indeed spawned many technologies; to truly excel in each aspect and align with enterprise applications, we may need to study for a long time and constantly practice to refine and produce high-quality products. This article summarizes the key modules in RAG practice over the past year, and we hope this summary will be of some help to everyone.
I want to learn and improve with you! The NewBeeNLP community has established several different discussion groups (such as Machine Learning / Deep Learning / Natural Language Processing / Search Recommendation / Graph Networks / Interview Discussions / etc.), with limited spots available. Hurry up and add the WeChat below to join the discussion! (Be sure to note your information to pass through)

Citation Links
[1] : https://arxiv.org/abs/2005.11401v4[2] : https://boston.lti.cs.cmu.edu/luyug/HyDE/HyDE.pdf[3] : https://arxiv.org/pdf/2305.14283.pdf?ref=blog.langchain.dev[4] : https://arxiv.org/pdf/2310.06117.pdf?ref=blog.langchain.dev[5] : https://arxiv.org/pdf/2309.11495.pdf[6] : https://github.com/Raudaschl/rag-fusion[7] : https://arxiv.org/pdf/2210.03629.pdf[8] : https://arxiv.org/pdf/2307.03172.pdf[9] : https://docs.llamaindex.ai/en/latest/module_guides/indexing/index_guide.html[10] : https://python.langchain.com/docs/modules/model_io/prompts/composition[11] : https://python.langchain.com/docs/modules/model_io/prompts/composition[12] : https://arxiv.org/pdf/2311.03731.pdf[13] : https://arxiv.org/pdf/2309.01431.pdf[14] : https://arxiv.org/pdf/2309.15217.pdf[15] : https://docs.llamaindex.ai/en/latest/module_guides/evaluating/root.html