
This article is adapted from: Foreign Languages, 2024, Issue 4
Citation: Yuan Yulin. Language Processing Mechanism and Theoretical Implications of Large Models like ChatGPT[J]. Foreign Languages, 2024, 47(4): 2-14.
Introduction: Understanding the Source of Large Models’ Language Proficiency
As many may know, modern large language models (LLMs) like ChatGPT possess powerful capabilities in language understanding and generation; however, their working mechanisms, internal mechanisms, and mathematical principles may not be well understood. So how do large language models like ChatGPT achieve this? Can it be explained in a way that linguists can easily understand? What implications does this language processing mechanism of large models have for linguistic theory? These are probably common concerns among many linguists (including graduate students and teachers) and even general internet users.
This article attempts to introduce and answer these questions based on the author’s limited literature reading and superficial professional knowledge. For convenience, we will focus mainly on two aspects: (1) word vector representation based on distributional semantics and its analogical reasoning capabilities, and (2) the attention mechanism and feedforward network working principles of large language models based on transformers.
Examples of ChatGPT’s Semantic Understanding and Common Sense Reasoning
Any linguist who tests it personally will be deeply impressed: ChatGPT’s performance in semantic understanding and common sense reasoning is almost at the level of humans. For example, what are the rules of anaphora for pronouns and antecedents? Are these rules purely syntactic, semantic, pragmatic, cognitive, or a combination of these? This has long been a topic of debate in contemporary linguistic theory, with diverse opinions and no consensus. (See Xu Liejiong 1995: 227−253 for details.) However, ChatGPT can accurately identify the relevant antecedents of pronouns without considering such theoretical assumptions, like a practitioner, providing a correct interpretation of the referential meaning of the pronouns; moreover, it can explain the reasoning behind this judgment. (See Yuan Yulin 2024a, b for details.) For instance, examples (1)-(3) below are partial examples of sentences tested using the Winograd Schema (WS):

It can be seen that ChatGPT can utilize the semantics of “envy” (the desire to be as good as someone else in terms of talent, honor, status, circumstances, etc., but not achieving it, thus resenting that person) and related common sense: the more likely scenario is that unsuccessful people harbor resentment towards successful people, to determine whether “(un)successful” refers to the envier Pete or the envied Martin; thus successfully resolving the referential ambiguity of the pronoun “he” and explaining the reasoning for doing so.
Next, let’s take a look at ChatGPT’s understanding of related Chinese sentences:

It can be seen that ChatGPT not only understands the meaning of the locative word “behind,” the antonyms “(too) tall” and “(too) short,” and the meaning of the negation “cannot see”; it also possesses common sense about whether the height of a person and their position can cause obstruction. Thus, it can comprehensively utilize this knowledge to infer that Deng Zhong is too tall and Chen Liang is too short, ultimately identifying the different referential meanings of the two pronouns “he” in this sentence pair. To verify whether it truly possesses the aforementioned linguistic knowledge about negation, we adapted example (2) into the following affirmative sentence to test ChatGPT:

It can be seen that ChatGPT can accurately interpret the semantics of locative words, antonyms, and the negation expression of action-complement phrases; moreover, it can utilize encyclopedic knowledge about whether the height and position of objects can cause obstruction to resolve possible referential ambiguities of pronouns.
Since large models like ChatGPT possess such powerful language proficiency: they can relatively accurately understand human natural language and generate relatively fluent and natural discourse and text; the next question naturally is: how do large language models achieve this? Below, we will first introduce the working mechanism of large language models from a linguistic perspective.
Probabilistic Language Models and the Architecture of Transformers
Technically speaking, large models like ChatGPT are a type of language model (language model, LM). A language model refers to a mathematical model established for human natural language. In layman’s terms, it is to represent natural language using mathematical formulas. For example, early generative grammar defined language as a set composed of sentences of that language, and then defined sentences using rewriting rules (rewriting rules). For example (see Chomsky 1957: 26−48 for details):


This can be seen as modeling human natural language using phrase structure grammar based on production rules. However, this rule-based definition is discrete, and machines cannot understand it; therefore, it is non-computable and cannot be implemented in digital computers using programs.
In contrast, computer scientists use statistical probabilistic models to estimate the probability of each sentence occurring in natural language, i.e., the probability distribution. The specific method is to decompose the probability calculation of a sentence into the product of the occurrence probabilities of the individual words that make up the sentence; that is, by multiplying the occurrence probabilities (conditional probabilities) of each word in a series of words that make up the sentence, the probability of the sentence is obtained. The classic formula is:
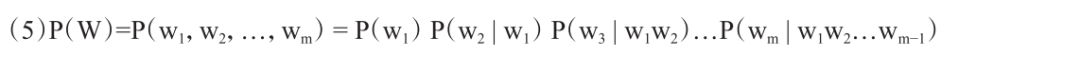
Although this probabilistic model cannot determine whether the sentence is grammatically correct, it can be used to calculate and predict the probability of a certain word appearing at the next position when a sequence of previous words is given. For example, in the formula above, P(w3|w1w2) indicates that through the statistics of a certain scale of real texts, it can calculate the probability of different words appearing at w3 based on the two words that appeared at w1 and w2. Clearly, the statistical method of estimating the occurrence probabilities and conditional probabilities of each word in a large corpus is easy to implement. Compared to (4), which is based on phrase structure grammar, (5) should be considered as a language model based on word grammar or n-gram grammar.
Next, let’s briefly explain the meaning of the name ChatGPT. The prefix “Chat” indicates that this is an artificial intelligence software focused on chatting; the stem “GPT” is an abbreviation for Generative Pre-trained Transformer. The core term “Transformer” refers to a multi-layer neural network with good parallel computing capabilities, capable of processing sequential data (such as text, speech, images, etc.), which is a fundamental component of neural network language models. The transformer generally consists of an encoder and a decoder, where the former is used to convert the input sequential data into a feature representation of the same dimension; that is, a vector representation called hidden state, which captures features and information in the data; the latter generates output data based on the encoder’s output and its own state to complete relevant tasks.
For example, in a translation task, the encoder’s input is a sentence in the source language. Although the encoder can see the entire sentence at once, the decoder can only generate one word at a time. This is because an autoregressive model can only predict itself (the words that have been predicted before) based on itself (the words that are about to be predicted). The decoder uses some outputs from previous moments as inputs at the current moment, shifting one token at a time to the right. Therefore, in the translation task, the output shifted to the right is a sequence of words in the target language corresponding to the source language in the training data, shifted one token at a time. This working order is parallel during the training phase and serial during the prediction phase. The input is encoded into a distributed representation vector through “input embedding,” and then the positional information of each token is encoded through “positional encoding”; because the input has no positional information, the result is that “the dog bites the man” and “the man bites the dog” have no distinction. Then, the multi-headed attention mechanism (MHA) extracts the correlations between tokens. Next, through “Add & Norm,” a “residual connection” and “normalization” are performed. The former connects the input of the previous layers to the current layer to prevent “gradient vanishing”; the latter reduces data differences through averaging to ensure network effectiveness. Then, the encoded result is input into the decoder. The decoder has a structure similar to that of the encoder, but it has an additional masked multi-headed attention mechanism.
The main innovation of the transformer model is the introduction of the attention mechanism MHA. (See Vaswani et al. 2017 for details.) The multi-headed attention mechanism is the core of the transformer, allowing the language model to focus on the most important or relevant parts of the input or output data and capture long-distance dependencies between data, thus enhancing the model’s understanding and generation capabilities, as well as its ability to handle complex problems and objectives. Each attention head contains the same structure—a scaled dot-product attention mechanism—but has independent parameters.
However, ChatGPT only has a decoder and no encoder. Thus, it can only predict the next data based on previously generated data and cannot consider the entire data sequence simultaneously. Therefore, it is an autoregressive language model. The modifier “Generative” refers to a machine learning model that contrasts with “discriminative”; the latter classifies samples into corresponding categories by finding a decision boundary, while the former reflects more of the data’s distribution information by learning the boundaries of each category, which can be used to generate samples, making it more universal (see Microstrong 2020 for details). The basic idea of generative language models is to predict the most likely words to appear next based on the previously known words according to distribution probabilities. The modifier “pre-trained” in “pre-trained” refers to the uniform training of language models based on large corpora, without considering specific scenarios and downstream tasks (such as translation, sentence creation, summarization, copywriting, etc.), and after completing pre-training, the language model is fine-tuned (Fine-Tuning, FT) according to the specific conditions of the application scenario and downstream tasks.
Literature usually refers to language models like GPT as “(language) large models,” “large language models,” or “modern large language models” because the structure of such language models is relatively complex, mainly composed of a huge neural network consisting of multiple layers of neurons with numerous parameters. For example, the GPT-3 that underlies ChatGPT has 175 billion parameters, which means that the neural network comprising the transformer has at least 175 billion connections between neural nodes and their weights. However, mathematically speaking, no matter how complex the language model is, it is just a function, which can be abstractly represented as a function form like “f(x)=y.” For instance, if x is an English sentence and y is a French sentence; then f is a language model that translates English into French. Of course, the number of variables contained in large language models is very large.
Since word vectors are the basis for language models representing natural language, the next section will introduce word vectors.
Distributional Semantics and Vectorized Word Embedding Representation
Constrained by the principle of arbitrariness of linguistic signs, the form of a word cannot reflect its meaning, nor can it reflect the similarities and differences and proximity of different words in meaning. For example, we know that the semantic relationship between “cat” and “dog” is closer than that between “fish” and “shrimp,” and the semantic relationship between “grass” and “tree” is closer than that between “rain” and “fog.” The question is, how do we obtain this semantic intuition? Is there an operable way to measure the semantic similarity between words? If we adopt the referential theory’s stance, then the meaning of a word is the thing it refers to; or to put it another way, the meaning of a word is the relationship between it and the thing it refers to. Based on this viewpoint, people can obtain knowledge about the similarity between words based on the similarity of the things represented by the words. However, this understanding under denotational semantics does not easily form an operable way to measure the semantic similarity between words. In contrast, if we adopt Wittgenstein’s (1958) use theory stance, then “the meaning of a word is its use in the language”; or as Firth (1957) said: “You should know a word by the company it keeps!” This viewpoint can be translated into descriptive linguistics as “words that are used and occur in the same contexts tend to purport similar meanings,” which later became the core idea of distributional semantics.
Clearly, this assumption of distributional semantics can serve as the foundation for statistical semantics and is relatively easy to form an operable way to measure the semantic similarity between words: by investigating the similarity of words in the thematic areas (topical regions, such as news, official documents, novels, poetry, blogs, etc.) where they are used, various combinatorial relationships (collocational relationships, specific construction frameworks), and aggregation relationships (substitution relationships and semantic hierarchical relationships, etc.) across specific dimensions, we can set different categories of words in terms of their semantic distance; and project them into a multidimensional (or high-dimensional) meaning space (meaning space) or linguistic feature space (linguistic feature space).
With the concept of meaning space and semantic distance, we can use a method similar to establishing a coordinate system to determine the position and numerical representation of different words in a certain meaning space. It can be seen that the so-called word embedding is to assign a number (generally an array) based on the position of the word in a certain meaning space, ensuring that words that are similar in meaning and use (distribution) are also numerically similar. This is the essence of the embedded vector representation of words. Since the meaning and use (distribution) of words are too complex to be represented in two dimensions; thus, modern language models often use hundreds or even thousands of dimensions of vector space. Therefore, the vector of each word is a long string of numbers (i.e., an array). For example, in 2013, Google released the word2vec language model with over 300 dimensions. The Google research team analyzed millions of documents collected from Google News to find out which words tend to appear in similar sentences. After several rounds of training, they taught the neural network to place category or meaning similar words (such as “cat,” “dog,” and “pet”) in adjacent positions in the vector space. For instance, word2vec represents the English word “cat” as a 300-dimensional array of numbers: [0.0074, 0.0030, -0.0105, 0.0742, 0.0765, -0.0011, 0.0265, 0.0106, …, 0.0002].
It is worth mentioning that as modern language models scale up, the dimensions of the word vectors they use also increase to express richer and more subtle semantic information. For example, OpenAI’s GPT-1 released in 2018 used 768-dimensional word vectors; its transformer had 12 layers of neural networks, with 117 million connection weight parameters between neural nodes. A few months later, GPT-2 was released, with its largest version having 1,600-dimensional word vectors; its transformer had 48 layers of neural networks, with 1.5 billion connection weight parameters. The GPT-3 released in 2020 has 12,288-dimensional word vectors; its transformer has 96 layers of neural networks, with 175 billion connection weight parameters. Thus, language models can not only distinguish between homophones (such as “bank”) with different meanings (bank vs. riverbank) but also differentiate polysemous words (such as “magazine”) with different meanings (magazine vs. publishing house).
The semantic space of words based on distributional semantics can reflect not only the proximity of words in conceptual meaning but also the positional relationships of different word classes in a two-dimensional feature space; particularly, certain parallel propagation relationships between words in the semantic space can be reduced to a two-dimensional plane for clear and intuitive revelation. The figure is omitted (see Wolfram 2023 for details).
Thus, the word vectors reflecting the coordinate points in the high-dimensional semantic space of words can capture many parallel or opposing semantic relationships, and also allow for vector arithmetic and reasoning about the relationships between the meanings of words. For example, the Google research team used the vector of “biggest” minus the vector of “big,” plus the vector of “small,” to obtain a vector closest to “smallest.” In other words, the vector of “biggest” minus the vector of “big” yields a vector close to the superlative “-est”; adding the vector of “small” to the superlative “-est” naturally results in a vector closest to “smallest.” Similarly, reasoning with vectors based on “man” and “woman” is similar to “king” and “queen,” allowing for learning gender roles as well as the concept of “royal” (the vector of “king” minus the vector of “man” is approximately equal to the vector of “queen” minus the vector of “woman” is approximately equal to the vector of “royal”). Extending this, one can learn the concept of “nationality” from “Indian” and “India” similar to “American” and “America”; the concept of “capital” from “Paris” and “France” similar to “Berlin” and “Germany”; the concept of “antonym relationship” from “immoral” and “moral” similar to “impossible” and “possible”; the concept of “plural form” from “mice” and “mouse” similar to “dollars” and “dollar.” In summary, word vectors encode subtle and important relationships between words and have become an essential foundation for modern language models.
How Transformer Language Models Perform Next-Word Prediction
As mentioned above, the transformer of the predecessor model GPT-3 has 96 layers of neural networks; each layer is a transformer that receives a series of vectors corresponding to the input text as input; moreover, each layer adds information based on context and other factors to help clarify the meanings of ambiguous or vague words to better predict the next likely word. For example, assume the input text is “John wants his bank to cash the.” These words are first represented as vectors in the style of word2vec and sent to the first transformer; this transformer may determine based on contextual information that both “wants” and “cash” are verbs; then the model modifies the word vectors to store this information. These new vectors are called “hidden states” and are sent to the second transformer. This second transformer may add contextual information from the other two words to help clarify that “bank” refers to a bank and not a riverbank; and that “his” refers back to the antecedent “John.” Thus, it generates another set of hidden state vectors. These vectors reflect all the information the model has previously learned. Research has indicated that the earlier layers of the GPT-3 model focus on understanding the syntax of sentences and resolving ambiguities as shown above; the later layers focus on understanding higher-level information of entire paragraphs, such as the gender, age, relationships with other characters, current and previous positions, personality, goals, etc. However, to date, researchers do not fully understand how large language models track this information; they can only logically infer that the model must pass information between layers of neural networks by modifying the hidden state vectors.
Imagine that the strongest version of GPT-3 uses word vectors with 12,288 dimensions; that is, each word is represented by a list of numbers containing 12,288 digits. Thus, various relevant information about each word’s context is recorded and can be read and modified by subsequent network layers. This not only deepens the model’s understanding of the meanings of the input text (including newly generated text through next-word prediction) but also facilitates the final layer of the network to output a hidden state containing all necessary information to accurately predict the next word.
Now, let’s take a look at the internal workings of each transformer. When updating the hidden state of each word in the input paragraph, the transformer mainly has two processing steps: 1) In the attention step, the neural network observes around each word, looking for other words with relevant backgrounds that share information with each other. 2) In the feedforward step, the neural network “thinks” about the information collected from the attention step for each word and attempts to predict the next word. To visualize, one can think of the attention mechanism as a matchmaking service between words. The neural network sets three vectors (equivalent to three checklists) for each word: one is the query vector, describing the characteristics of the word it is searching for; one is the key vector, describing the characteristics of the word itself; and the last is the value vector, reflecting the attention-weighted word vector. The neural network finds the best matching word by comparing each key vector with each query vector (by calculating the dot product). Once a match is found, the neural network transfers the relevant information of the word that produced the key vector to the word that produced the query vector. For example, in processing the aforementioned sentence “John wants his bank to cash the,” the internal processing of the transformer may be as follows: the query vector of “his” may represent ‘looking for a noun describing a male,’ while the key vector of “John” may represent ‘this is a noun describing a male.’ The network detects that these two vectors match, and thus transfers the vector information of “John” to the vector of “his.”
As mentioned earlier, each attention layer has multiple “attention heads.” This allows the information exchange process described above to occur multiple times in parallel at each layer, with each attention head focusing on different tasks: some match nouns with pronouns to establish anaphoric relationships; others parse homophones or polysemous words to eliminate lexical ambiguities; and others connect several words like “Joe” and “Biden” to identify relevant names or named entities. Thus, the output of an operation in one attention layer serves as input for an attention head in the next layer. In fact, the tasks mentioned above often require the use of multiple attention heads. One can imagine that the strongest version of GPT-3 has 96 layers, each with 96 attention heads; therefore, each time it predicts the next word, GPT-3 performs 9,216 attention operations.
According to researchers from Redwood Research, Wang et al. (2022) studied how the predecessor GPT-2 predicts the next word. They found that for a paragraph like “When Mary and John went to the store, John gave a drink to,” three types of attention heads contributed to predicting the next word “Mary”: 1) Three attention heads they called “Name Move Heads” copied information from “Mary”‘s vector to the vector of the last input word “to”; 2) Four attention heads they termed “Subject Inhibition Heads” marked the vector of the second “John,” preventing the Name Move Heads from copying the subject’s name “John”; 3) Two attention heads they called “Duplicate Token Heads” marked the vector of the second “John” as a duplicate of the first “John”‘s vector, helping the Subject Inhibition Heads decide that “John” should not be copied. The functions of these last two types of attention heads were discovered by reverse engineering the calculation process of GPT-2 step by step. The collaborative effect of these three attention heads enabled GPT-2’s neural network to determine that “Mary” is the correct next word. In other words, these nine attention heads allowed GPT-2 to understand that “John gave a drink to Mary” makes sense, while “John gave a drink to John” does not. To this end, they published a 25-page paper explaining how they identified and validated these attention heads. This reflects that fully explaining the working mechanisms of modern large language models like GPT will be an immense project that humanity is unlikely to complete in a short time.
As mentioned above, after the information is transferred between attention heads and word vectors, the feedforward network “thinks” about each word vector and attempts to predict the next word. At this stage, although there is no exchange of information between words, the feedforward layer independently analyzes each word and can access any information previously copied by the attention heads. The neurons in the feedforward layer are mathematical functions that compute the weighted sum of their inputs. The power of the feedforward layer lies in its numerous connections. For instance, the output layer has 12,288 neurons (corresponding to the model’s 12,288-dimensional word vectors), and the hidden layer has 49,152 neurons, each with 12,288 input values (thus each neuron has 12,288 weight parameters). This means that each feedforward layer has (49,152 × 12,288 + 12,288 × 49,152 =) 1.2 billion weight parameters. Thus, 96 feedforward layers collectively have (1.2 billion × 96 =) 116 billion parameters. This is equivalent to two-thirds of the parameter count of GPT-3.5, which serves as the foundation for ChatGPT (175 billion).
Researchers from Tel Aviv University found that the feedforward layers work through pattern matching; each neuron in the hidden layer can match specific patterns in the input text, such as sequences of words ending with “substitutes,” military-related sequences ending with “base” or “bases,” sequences ending with time ranges (e.g., “between 3 PM and 7 PM”), sequences related to television programs (e.g., “the original NBC daytime version, archived”), etc. The basic tendency is that the earlier layers match specific words, while the later layers match broader semantic categories of phrases. When a neuron matches one of these patterns, it adds information to the word vector. Although this information is not easy to interpret at present, in many cases, it seems to serve as a temporary prediction for the next word. Researchers from Brown University found that the feedforward layers sometimes use vector operations as shown above for analogical reasoning to accurately predict the next word. Examples are omitted.
It can be seen that the aforementioned attention mechanism and feedforward layers have a certain division of labor: the former focuses on retrieving information from prompts and other previously generated parts, while the latter enables the language model to “remember” the information learned from training data. Among them, the earlier feedforward layers are more likely to encode facts related to specific words, such as “Trump” often appearing after “Donald”; while the later feedforward layers encode more complex relationships, such as adding a certain vector to change a country’s name to its capital’s name.
How Large Language Models Are Trained
The above introduced the working principles of the attention mechanism and feedforward neural networks of large language models; now let’s briefly introduce how this model with hundreds of billions of parameters is trained.
Abstractly speaking, in natural language processing, experts usually view a text as a sequence of tokens. Given a corpus, the probability distribution of the tokens in it is denoted as Pdata, and the language model aims to adjust its output probability distribution Pθ to fit the data’s probability distribution Pdata. The autoregressive language model models the joint probability as the product of conditional probabilities, with the formula:

Its optimization objective is maximum likelihood (Maximum Likelihood). The formula is:

In an ideal situation, the model converges to the optimal, i.e., Pθ=Pdata (see Qin Bing 2023 for reference). In other words, the training of the language model is completed.
However, in practice, training is fraught with challenges. Fortunately, large language models have a successful innovation: they do not require manually labeled data for training; instead, they learn human natural language by predicting the next word in the text or the masked words in the middle. The accuracy of this next word prediction can be verified in the corpus. Thus, high-quality unlabeled corpora become a “labeled” training database providing standard answers. This type of corpus is easy to obtain and vast in quantity, thus significantly promoting the scale and quality of large model training. For example, a large model receives the input “I like my coffee with cream and” and attempts to predict that the next word is “sugar.” In other words, it learns to construct sentences like a primary school student filling in the blanks at the end or in the middle of a sentence, thereby learning the grammar of a language. Furthermore, this next-word prediction training is equivalent to performing information compression (the subsequent information is effectively packed into the preceding sequence of tokens); and fundamentally, it is also performing knowledge compression (thus, appropriate prompts can awaken and recall information that may exist in the corpus). Of course, an initialized model performs poorly in this regard because each of its weight parameters initially starts from a random number; later, as the model “sees” more examples (often hundreds of billions of words of text data), its weight parameters are gradually adjusted, slowly approaching or achieving correct predictions. This situation is somewhat akin to adjusting the direction of the faucet’s handle before taking a shower on the first day of your hotel stay, trying to touch the water flow: if the water temperature is too hot or too cold, you will turn the handle in the opposite direction; the closer you get to the desired water temperature, the smaller the adjustments you make.
Now, let’s use this analogy to imagine: first, there are over 50,000 faucets, each corresponding to a specific word in a vocabulary list of over 50,000 words; your goal is to let only the faucet corresponding to the next word in the given sequence flow (that is, to connect the correct word). Secondly, behind the faucets are a multitude of interconnected pipes, with numerous valves on top. Therefore, if water flows from the wrong pipe (i.e., an incorrect word), you cannot just adjust the faucet handle. What to do? If you are a magician, or if you can use magic; then you can send a sprite or a “squirrel army” to track each pipe and adjust every valve they find along the way. Since the same pipe usually supplies multiple faucets, the sprites or squirrels need to carefully consider how to determine which valves to tighten or loosen and to what degree. Of course, this analogy is too crazy because the strongest version of GPT-3 has 175 billion parameters, and it is impossible to build a network of pipes with 175 billion valves. However, thanks to Moore’s Law, modern computers can and indeed operate at this scale.
In reality, the attention heads and feedforward layers of large language models are implemented as a series of simple mathematical functions (mainly matrix multiplication), with their behaviors determined by adjustable weight parameters. Just like the sprites or squirrel army in the imagined story controlling the water flow by tightening or loosening valves, training algorithms control the flow of information in the neural network by increasing or decreasing the weight parameters of the language model.
The training process is divided into two steps: first, a “forward pass” is performed, equivalent to opening the water source and checking whether the water flows from the correct faucet. Then the water source is closed, and a “backward pass” is performed, where the sprites or squirrels quickly move along each pipe and tighten or loosen the valves. In digital neural networks, the role of the sprites or squirrels is played by an algorithm known as “backward propagation.” This algorithm “walks backwards” through the network, using calculus to estimate how much each weight parameter needs to be changed. Completing such a process (i.e., performing a forward pass on an example followed by a backward pass to improve the neural network’s performance on this example) requires hundreds of billions of mathematical operations. Therefore, training a language model mainly involves adjusting the connection weight parameters between the neural neurons, referred to as “tuning parameters,” or jokingly called “alchemy.” Training a large language model like GPT-3 requires repeating this process billions of times, as every word in each training data must be trained. According to OpenAI’s estimates, training GPT-3 requires over 300 billion floating-point computations (approximately 20 trillion floating-point calculations for each weight parameter), which requires dozens of high-end computer chips running for months.
For ChatGPT, its longest path has about 400 core layers and millions of neurons, totaling about 175 billion connections, so it also has 175 billion weight parameters. It is important to note that every time ChatGPT generates a new token, it must perform calculations involving each weight parameter. In practice, these calculations can be organized into highly parallel array operations, which can be conveniently performed on a GPU. However, for each generated token, 175 billion calculations still need to be performed (and a little more at the end). Therefore, it is understandable that generating a long text with ChatGPT often takes a considerable amount of time.
The Success of Large Language Models Helps Us Reassess Language
Physicist Richard Phillips Feynman (1918—1988) once said, “What I cannot create, I do not understand” (What I cannot create, I do not understand). I interpret this as, “The best way to understand something is to create it” (The best way to understand something is to create it). Following this logic, the best way to understand the structural mechanisms and working principles of human natural language is to create a machine capable of generating and understanding natural language to reflect on and test the theories linguists have about the structure and function of language. Whether it is fortunate or unfortunate, software engineers have, after more than 70 years of relentless effort, created powerful modern language models like ChatGPT for us. In this context, rather than sitting in armchairs critiquing and criticizing ChatGPT for its “false promises” (i.e., providing illusory prospects), linguists might consider: what insights can the success of modern language models like ChatGPT bring to contemporary linguistics? The success of large models, by “recreating language,” reminds us of the noteworthy features of human natural language. Accordingly, what reflections should our syntactic and semantic theoretical constructions and research directions undergo?
Summarizing the views of scholars and relevant literature, we can find that these insights include at least the following five points:
1) The word embedding vector representation based on distributional semantics is very effective for capturing and representing the meanings of language. It is precisely the recognition that the specific meanings of words depend on the context, and the method of using previous context information to predict the next word that makes this possible; and it enables language models to learn how human language operates by finding the most suitable next word. Of course, there are still regrets, namely: the internal workings of the artificial intelligence system ultimately cannot be fully understood by human experts; in other words, modern large language models have not yet reached the scientific realm of “explainable artificial intelligence” with transparent mechanisms.
2) The basic assumption of distributional semantics: the more semantically similar two words are, the more similar their distributions will be, resulting in them being more likely to appear in similar contextual environments. This assumption not only helps software engineers solve the “data sparsity problem” encountered in computational modeling (see Wishart et al. 2017 for details) by modeling data-sparse words using distributional data-rich words from synonym or near-synonym sets; but also helps cognitive scientists address the “poverty of stimulus problem” in child language acquisition (i.e., how do children quickly learn a language in relatively sparse input?) (see Yarlett 2008 for details). In other words, we have reason to assume: children may use synonyms or near-synonyms for analogy and generalization (generalization) to learn a language from limited input corpora. We know that Chomsky firmly believed in the necessity of innate universal grammar based on the “poverty of stimulus problem.” Extending this, human analogy and generalization abilities can also be used to answer the “Plato’s problem” (i.e., how do humans acquire such rich knowledge in the absence of available examples?).
3) Since the semantic distribution hypothesis can explain the phenomenon of generalization in language learning, it naturally can explain why humans can learn to complete various language tasks with only a few examples. For instance, transforming statements into questions or turning active sentences into passive sentences, etc. Notably, when OpenAI launched GPT-3 in 2020, a 75-page paper titled “Language Models are Few-Shot Learners” led by Tom Brown, including Ilya Sutskever and 30 other authors, demonstrated that it only takes showing a few example prompts (i.e., few-shot) for the language model to complete tasks such as translating English words into corresponding French words, which is known as the in-context learning prompt strategy. The simple idea behind this is that “humans do not require large supervised datasets to learn most language tasks” (see Brown et al. 2020 for details). In other words, this analogy and generalization is based on general cognitive abilities of humans. Therefore, the hypothesis of innate specialized language abilities and universal grammar is not necessary.
4) Language itself is predictable, and the structural rules of language are much simpler than we usually think. This is because the regularity of language is often linked to the regularity of the material world; thus, when language models learn the semantic relationships between words, they usually also implicitly learn the relationships between things in the external world. Otherwise, if human natural language truly had the complex hierarchical structure depicted in contemporary formal syntax and formal semantics, artificial neural network language models would likely be unable to process it. Consequently, the ensuing question is whether contemporary formal syntax’s tree structures of nested layers accurately capture the essence of natural language? Is there empirical evidence and theoretical or technical necessity for such analyses? Similarly, does the multiple implicit operator constraints of contemporary formal semantics on sentence semantics have meaningful expression and logical technical necessity? (See Yuan Yulin 2019 for details.)
5) The use of language itself is a predictive process, as the human brain is a “predictive machine”; good predictions and representations of the environment are prerequisites for biological adaptation to the environment. Therefore, prediction should be fundamental to both biological intelligence and artificial intelligence. In the processing of linguistic information, predicting subsequent text is also essential. This area of research is more common in psycholinguistics, but rarely seen in theoretical linguistics. We hope that the exploration of emerging linguistic theoretical categories such as expectation, counter-expectation, and surprise can absorb relevant research on language prediction from artificial intelligence and psycholinguistics, actively opening new academic growth points for linguistic research in the era of artificial intelligence.
6) Lastly, but certainly not least, language ability may not be unique to humans (language maybe not unique to human beings). The language proficiency of large models like ChatGPT has already approached human levels (see Yuan Yulin 2024b for details). This may discomfort some people, feeling that human self-esteem is hurt; because it challenges the “uniqueness of language,” making language seem no longer exclusively belonging to humans. However, we believe that this mechanical creation capable of “recreating language” does not offend our “human nature.”
References omitted
Author Profile: Yuan Yulin, PhD, Professor, Doctoral Supervisor. Research areas: theoretical linguistics and Chinese linguistics, especially syntax, semantics, pragmatics, Chinese information processing, and computational linguistics.
