Follow the WeChat public account “ML_NLP“ and set it as a “starred“, for heavy content delivered first-hand!

Reprinted from | GiantPandaCV
[GiantPandaCV Introduction] In recent years, Attention-based methods have gained popularity in academia and industry due to their interpretability and effectiveness. However, the network structures proposed in papers are often embedded in code frameworks for classification, detection, segmentation, etc., leading to redundancy in code, making it difficult for beginners like me to find the core code of the network, resulting in certain difficulties in understanding the papers and the ideas behind them. Therefore, I have organized and reproduced the core code of the Attention, MLP, and Re-parameter papers I have read recently to facilitate readers’ understanding. This article mainly provides a brief introduction to the Attention part of this project. The project will continue to update the latest paper work, and everyone is welcome to follow and star this work. If there are any issues during the reproduction and organization process, feel free to raise them in the issues section, and I will respond promptly~
Author Information
First-year graduate student majoring in Computer Science at Xiamen University, welcome to follow my GitHub: xmu-xiaoma666, Zhihu: Keep working hard.
Project Address
https://github.com/xmu-xiaoma666/External-Attention-pytorch
1. External Attention
1.1. Citation
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks.—arXiv 2021.05.05
Paper address: https://arxiv.org/abs/2105.02358
1.2. Model Structure
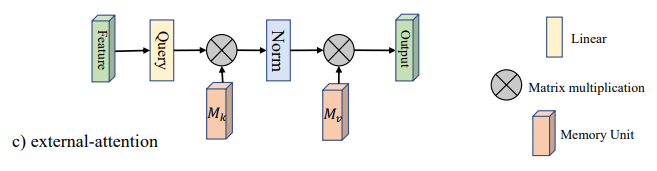
1.3. Introduction
This is a paper uploaded to arXiv in May, mainly addressing two pain points of Self-Attention (SA): (1) O(n^2) computational complexity; (2) SA calculates Attention based on different positions on the same sample, ignoring the connections between different samples. Therefore, this paper uses two concatenated MLP structures as memory units, reducing the computational complexity to O(n); furthermore, these two memory units are learned based on all training data, thus implicitly considering the relationship between different samples.
1.4. Usage
from attention.ExternalAttention import ExternalAttention
import torch
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)
2. Self Attention
2.1. Citation
Attention Is All You Need—NeurIPS2017
Paper address: https://arxiv.org/abs/1706.03762
2.2. Model Structure
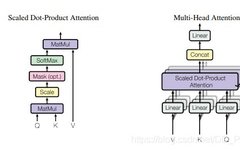
2.3. Introduction
This is a paper published by Google at NeurIPS2017, which has a significant impact in various fields such as CV, NLP, and multi-modal tasks, with over 22,000 citations currently. The Self-Attention proposed in Transformer is a type of Attention used to calculate the weights between different positions in features, thereby updating the features. First, the input feature is mapped through FC to three features Q, K, and V, then the attention map is obtained by dot product of Q and K, and the weighted features are obtained by dot product of the attention map and V. Finally, a new feature is obtained through FC mapping. (There are many excellent explanations about Transformer and Self-Attention online, so I won’t go into detail here.)
2.4. Usage
from attention.SelfAttention import ScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
3. Squeeze-and-Excitation (SE) Attention
3.1. Citation
Squeeze-and-Excitation Networks—CVPR2018
Paper address: https://arxiv.org/abs/1709.01507
3.2. Model Structure
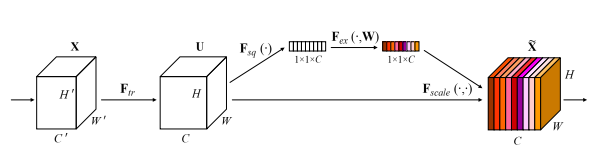
3.3. Introduction
This is a paper from CVPR2018, which is also very influential, with over 7,000 citations. This paper focuses on channel attention, and due to its simple structure and effectiveness, it has sparked a small wave of interest in channel attention. The idea of this paper can be said to be very simple: first, perform AdaptiveAvgPool on the spatial dimension, then learn channel attention through two FC layers, normalize it using Sigmoid to obtain the Channel Attention Map, and finally multiply the Channel Attention Map with the original features to obtain the weighted features.
3.4. Usage
from attention.SEAttention import SEAttention
import torch
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
4. Selective Kernel (SK) Attention
4.1. Citation
Selective Kernel Networks—CVPR2019
Paper address: https://arxiv.org/pdf/1903.06586.pdf
4.2. Model Structure
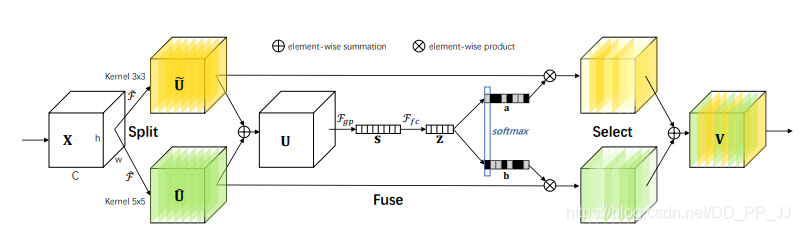
4.3. Introduction
This is a paper from CVPR2019, paying tribute to the idea of SENet. In traditional CNNs, each convolutional layer uses convolution kernels of the same size, limiting the model’s expressive power; the Inception model structure has validated that learning with multiple different convolution kernels can indeed enhance the model’s expressive power. The authors borrowed the idea from SENet, dynamically calculating the channel weights for each convolution kernel, thus dynamically fusing the results of each convolution kernel.
In my opinion, the reason this paper can also be called lightweight is that when performing channel attention on different kernels, the parameters are shared (i.e., because before doing Attention, the features are fused, so the results of different convolution kernels share the parameters of one SE module).
This paper’s method consists of three parts: Split, Fuse, Select. Split is a multi-branch operation using different convolution kernels to obtain different features; the Fuse part uses the SE structure to obtain the channel attention matrix (N convolution kernels can yield N attention matrices, this step shares parameters across all features), thus obtaining the features after SE for different kernels; the Select operation adds these features together.
4.4. Usage
from attention.SKAttention import SKAttention
import torch
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
5. CBAM Attention
5.1. Citation
CBAM: Convolutional Block Attention Module—ECCV2018
Paper address: https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf
5.2. Model Structure
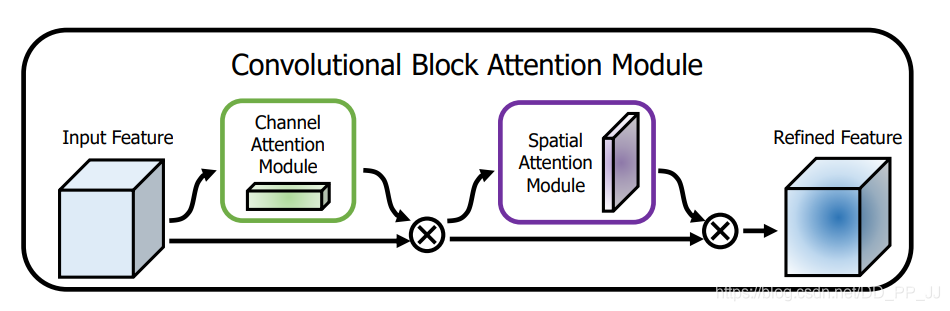
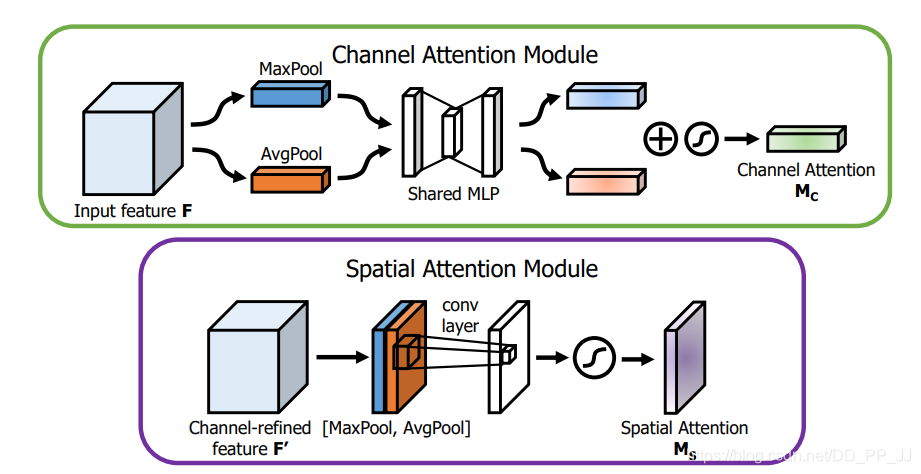
5.3. Introduction
This is a paper from ECCV2018, which simultaneously uses Channel Attention and Spatial Attention, linking the two together (the paper also conducted ablation experiments on parallel and two types of serial connections).
In terms of Channel Attention, the basic structure is similar to SE, but the authors proposed that AvgPool and MaxPool have different representational effects, so they performed AvgPool and MaxPool on the original features in the Spatial dimension, then used the SE structure to extract channel attention; note that the parameters are shared here. After adding the two features together and normalizing, the attention matrix is obtained.
Spatial Attention is similar to Channel Attention, first pooling in the channel dimension, then concatenating the two features, and using a 7×7 convolution to extract Spatial Attention (the reason for using 7×7 is that the extracted attention is spatial, thus requiring a sufficiently large kernel). Finally, normalizing gives the spatial attention matrix.
5.4. Usage
from attention.CBAM import CBAMBlock
import torch
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)
6. BAM Attention
6.1. Citation
BAM: Bottleneck Attention Module—BMCV2018
Paper address: https://arxiv.org/pdf/1807.06514.pdf
6.2. Model Structure
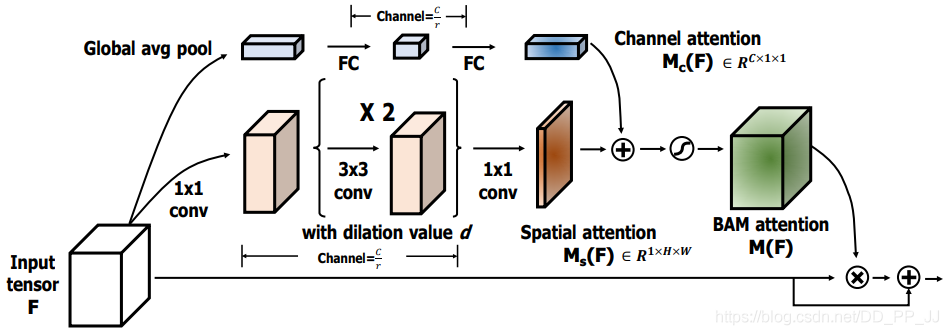
6.3. Introduction
This is a work from the same author as CBAM, and it is also a dual Attention mechanism. The difference is that CBAM concatenates the results of the two attentions, while BAM directly adds the two attention matrices.
In terms of Channel Attention, the structure is basically the same as SE. For Spatial Attention, pooling is performed in the channel dimension, then two dilated convolutions of 3×3 are used, and finally a 1×1 convolution is used to obtain the Spatial Attention matrix.
Finally, the Channel Attention and Spatial Attention matrices are added together (using broadcasting), resulting in the combined attention matrix of spatial and channel.
6.4. Usage
from attention.BAM import BAMBlock
import torch
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)
7. ECA Attention
7.1. Citation
ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks—CVPR2020
Paper address: https://arxiv.org/pdf/1910.03151.pdf
7.2. Model Structure
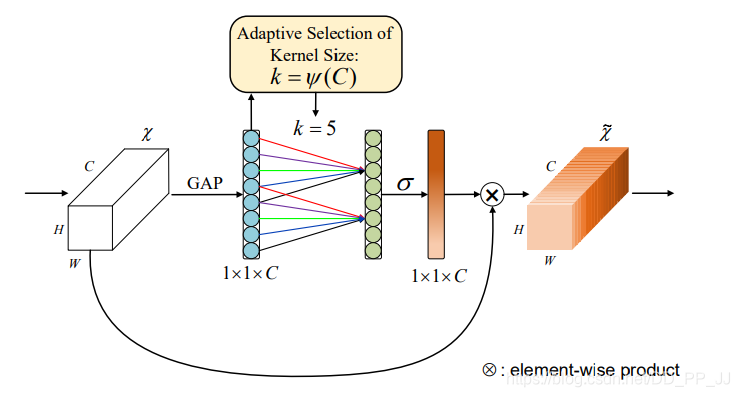
7.3. Introduction
This is a paper from CVPR2020.
As shown in the figure above, SE achieves channel attention using two fully connected layers, while ECA requires a convolution. The reason the authors did this is that they believe it is unnecessary to compute attention between all channels pairwise, and that using two fully connected layers indeed introduces too many parameters and computational load.
Therefore, the authors performed AvgPool first and then used a one-dimensional convolution with a receptive field of k (equivalent to only computing attention for adjacent k channels), greatly reducing the parameters and computational load (i.e., SE represents a global attention, while ECA represents a local attention).
7.4. Usage:
from attention.ECAAttention import ECAAttention
import torch
input=torch.randn(50,512,7,7)
eca = ECAAttention(kernel_size=3)
output=eca(input)
print(output.shape)
8. DANet Attention
8.1. Citation
Dual Attention Network for Scene Segmentation—CVPR2019
Paper address: https://arxiv.org/pdf/1809.02983.pdf
8.2. Model Structure
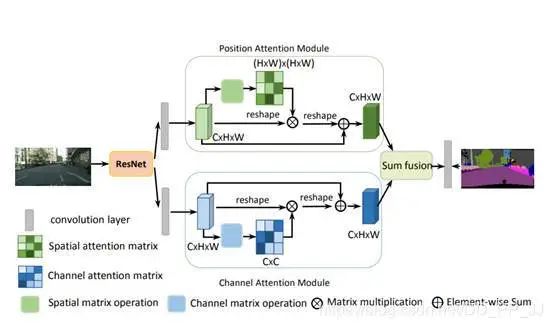
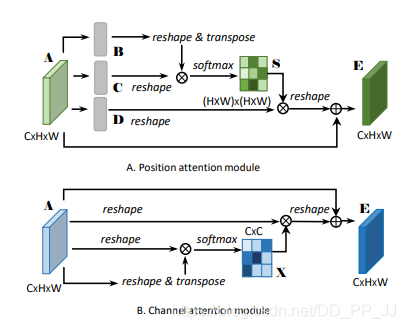
8.3. Introduction
This is a paper from CVPR2019, with a very simple idea: applying self-attention to the task of scene segmentation. The difference is that self-attention focuses on the attention between each position, while this paper extends self-attention to include a channel attention branch, operating similarly to self-attention, but without the three Linear layers that generate Q, K, and V in the channel attention. Finally, the features after both attentions are combined using element-wise sum.
8.4. Usage
from attention.DANet import DAModule
import torch
input=torch.randn(50,512,7,7)
danet=DAModule(d_model=512,kernel_size=3,H=7,W=7)
print(danet(input).shape)
9. Pyramid Split Attention (PSA)
9.1. Citation
EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network—arXiv 2021.05.30
Paper address: https://arxiv.org/pdf/2105.14447.pdf
9.2. Model Structure
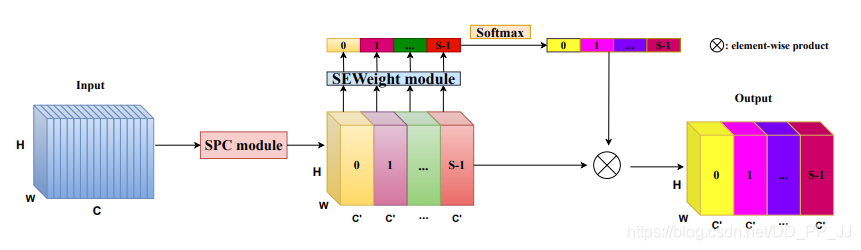
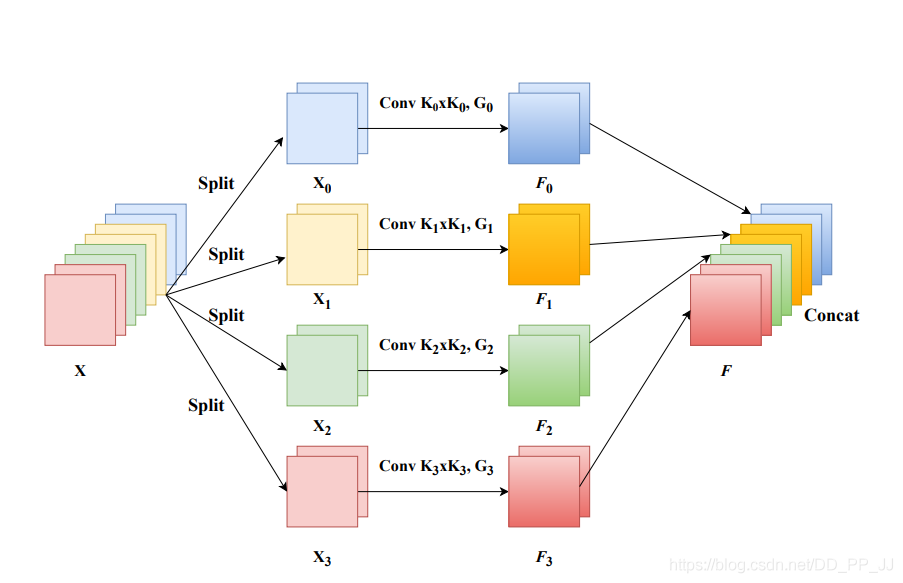
9.3. Introduction
This is a paper uploaded by Shenzhen University on May 30 to arXiv, aiming to explore and enrich feature space by obtaining and exploring spatial information at different scales. The network structure is relatively simple, mainly divided into four steps: first, the original feature is divided into n groups based on channels, and different scales of convolution are performed on different groups to obtain new features W1; second, SE is applied to the original features to obtain different channel attention; third, SOFTMAX is performed on different groups; fourth, the obtained attention is multiplied with the original feature W1.
9.4. Usage
from attention.PSA import PSA
import torch
input=torch.randn(50,512,7,7)
psa = PSA(channel=512,reduction=8)
output=psa(input)
print(output.shape)
10. Efficient Multi-Head Self-Attention (EMSA)
10.1. Citation
ResT: An Efficient Transformer for Visual Recognition—arXiv 2021.05.28
Paper address: https://arxiv.org/abs/2105.13677
10.2. Model Structure
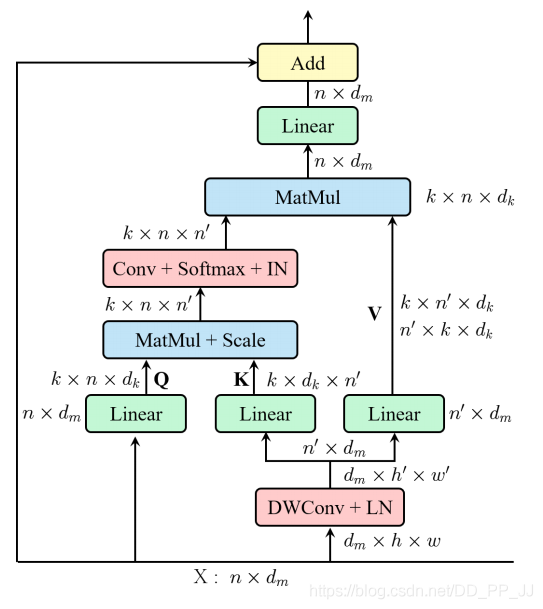
10.3. Introduction
This is a paper uploaded by Nanjing University on May 28 to arXiv. The main issues addressed in this paper are two pain points of SA: (1) the computational complexity of Self-Attention is squarely related to n (where n is the size of the spatial dimension); (2) each head only has partial information of q, k, v, and if the dimensions of q, k, v are too small, it leads to a loss of continuous information and thus performance loss. The approach proposed in this paper is also very simple: in SA, before the FC layer, a convolution is used to reduce the spatial dimensions, thus obtaining smaller K and V in the spatial dimension.
10.4. Usage
from attention.EMSA import EMSA
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,64,512)
emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)
output=emsa(input,input,input)
print(output.shape)
[Final Thoughts]
Currently, the Attention work organized in this project is indeed not comprehensive enough, and as the reading volume increases, I will continue to improve this project. Everyone is welcome to star and support. If there are any inappropriate expressions or errors in the code implementation in the article, please feel free to point them out~
Recommended Reading:
Visual Enhancement Word Vectors: I Am Word Vector, I Opened My Eyes!
Transformer has grown up, what about its siblings? (Including detailed knowledge points about Transformers)
ERICA: A Unified Framework for Enhancing Pre-trained Language Models' Understanding of Entities and Relationships
Click the card below to follow the public account “Machine Learning Algorithms and Natural Language Processing” for more information: