Click the above “Beginner Learning Vision” and choose to add “Star” or “Top“.
Heavyweight content delivered first-hand.
Author丨AdamLau@ZhihuSource丨https://zhuanlan.zhihu.com/p/288758894
Introduction
This article, in conjunction with related papers, discusses various CV attention mechanisms (Non-local Neural Networks, Squeeze-and-Excitation Networks, CBAM, DANet), their concepts, characteristics, and related experiments.
CV Attention Mechanisms
Non-local ~ SE ~ CcNet ~ GC-Net ~ Gate ~ CBAM ~ Dual Attention ~ Spatial Attention ~ Channel Attention ~ …
【As long as you can skillfully master the four major rules of addition, multiplication, parallel, and serial, plus know a bit of basic matrix operation rules (e.g., HW * WH = HH) and sigmoid/softmax operations, then you can freely generate many kinds of attention mechanisms.】
- The spatial attention module (look where) adjusts attention for each position in the feature map, a (x,y) 2D adjustment, allowing the model to focus on areas that deserve more attention.
- The channel attention module (look what) allocates resources across various convolution channels, a one-dimensional adjustment along the z-axis.
Non-local Neural Networks
Paper: https://arxiv.org/abs/1711.07971v1
The pioneering work on attention mechanisms in computer vision. It introduces non-local operations, using self-attention mechanisms to establish long-range dependencies. – local operations: convolutions (on local fields), recurrent (on current/previous moments), etc. – non-local operations are used to capture long-range dependencies, i.e., how to establish connections between two pixels at a certain distance in an image, how to establish connections between two frames in a video, how to establish relationships between different words in a sentence, etc. Non-local operations consider the weighted features of all positions when calculating the response at a certain location—these positions can be spatial, temporal, or spatiotemporal.
1. Definition of Non-local
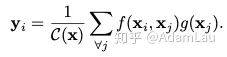
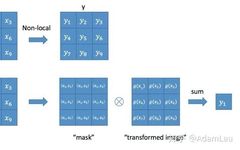
Here, x represents the input signal (image, sequence, video, etc., or their features), y represents the output signal, which has the same size as x. f(xi,xj) is used to calculate the pairwise relationship between i and all possible associated positions j, where a greater distance between i and j results in a smaller f value, indicating that position j has less influence on i. g(xj) is used to calculate the feature value of the input signal at position j. C(x) is the normalization parameter. Understanding: i represents the response at the current position, j represents the global response, and a non-local response value is obtained through weighting.
What are the advantages of Non-local?
- The proposed non-local operations directly capture long-range dependencies by calculating interactions between any two positions, without being limited to adjacent points, effectively constructing a convolution kernel as large as the feature map size, thus maintaining more information.
- non-local can serve as a component and be combined with other network structures. Experiments by the authors have shown that it can be applied to image classification, object detection, instance segmentation, pose recognition, and other visual tasks with varying degrees of improvement.
- Non-local performs very well in video classification; it shows significant results in video classification tasks.
The paper provides a general formula and introduces the instantiation representations of the f and g functions:
- g function: can be viewed as a linear transformation (Linear Embedding) with the following formula:
is the weight matrix that needs to be learned, which can be implemented through a spatial 1×1 convolution (relatively simple to implement).
- f function: this is a function used to calculate the similarity between i and j. The author proposed four specific functions that can be used as f function.
1. Gaussian function 2. Embedded Gaussian 3. Dot product 4. Concatenation
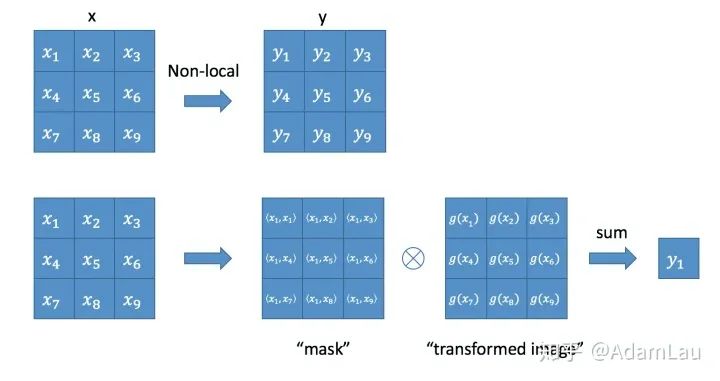
2. Non-local Block
It is essentially a convolution operation, where the output channel count matches that of x. Thus, the non-local operation can serve as a component that can be assembled into any convolutional neural network.
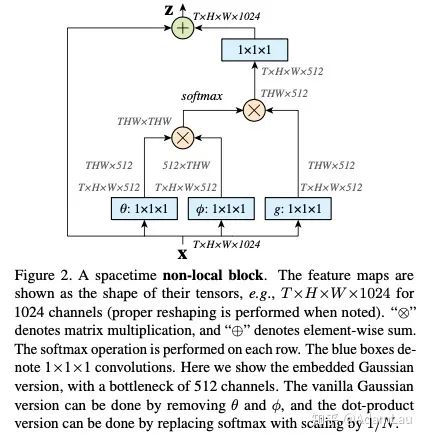
3. Experiments
- The paper proposes four models for calculating similarity, and experiments were conducted on all four methods, finding that the results did not differ significantly. Thus, a conclusion was reached: using non-local improves baseline results, but the differences between various similarity calculation methods are minimal, so any one can be used for experimentation. The paper uses embedding gaussian as the default similarity calculation method.
- The author conducted a series of ablation experiments to demonstrate the effectiveness of non-local NN:
- Comparing four similarity calculation models, no significant differences were found;
- Using Resnet50 as an example: comparing results of adding non-local modules at different stages, significant improvements were observed at stages 2, 3, and 4, possibly due to less spatial information at the fifth layer;
- Comparing results of adding more non-local modules, the more added, the better the performance, but the slower the speed; the author believes this is because more non-local blocks can capture long-distance dependencies multiple times. Information can be transmitted back and forth over long distances in the spatiotemporal domain, which cannot be achieved by local models;
- Non-local applied in time, space, and spatiotemporal domains all shows improvements;
- non-local vs. 3D convolution, non-local is more efficient and performs better;
- non-local and 3D conv can complement each other;
- Longer input sequences show better performance across all models.
Squeeze-and-Excitation Networks
Paper: https://arxiv.org/abs/1709.01507
Many previous works have proposed enhancing network performance in the spatial dimension, such as the inception structure obtaining information from different receptive fields, the inside-outside structure considering more contextual information, spatial attention mechanisms, etc. Is there another dimension to improve performance?
SENet is the first to propose the Squeeze-and-Excitation module from the channel-wise perspective, a channel attention mechanism that can adaptively adjust the feature response values of each channel.
How to apply the network to segmentation?
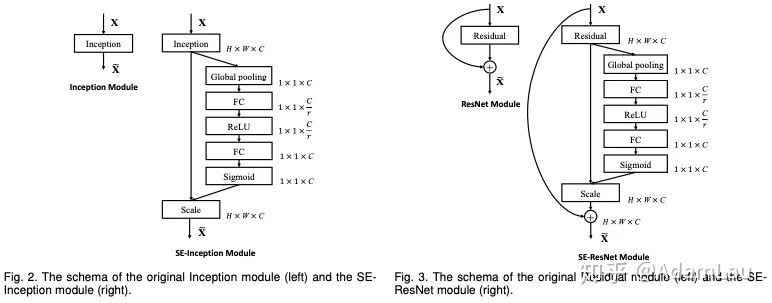
1. SE Module
The network structure is shown below:
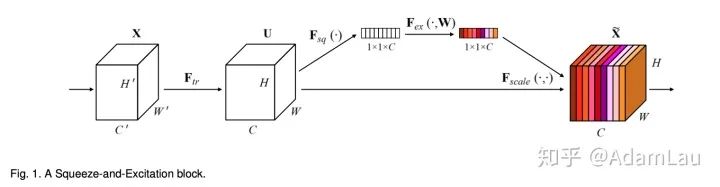
- Squeeze uses global average pooling (other methods can also be used) to generate channel information statistics, achieving channel description;
It compresses global spatial information into a channel descriptor;
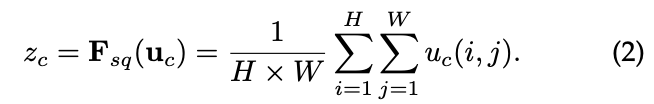
- Excitation must be flexible and learn a non-exclusive relationship
Uses a threshold mechanism with sigmoid activation function to ensure weights lie between (0,1).
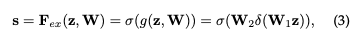
Finally, by scaling the weights obtained, they are multiplied with the original two-dimensional features of each channel.
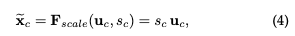
Train a fully connected network to learn the weights of each feature channel, which can explicitly model the correlations between feature channels.
2. Experiments
The SE module can be applied to various structures such as inception and resblock, making it very flexible.
The ablation experiments are very thorough, and the experimental results were state-of-the-art at the time, winning the ILSVRC2017 championship. (For more details, see the paper.)
3. Conclusion
The SE module can dynamically adapt to recalibrate the original features in the channel dimension, focusing for the first time on the dependency relationships at the model channel level. Additionally, whether the feature importance values generated by the SE block can be used for network pruning (model compression).
CBAM: Convolutional Block Attention Module
Paper: https://arxiv.org/pdf/1807.06521.pdf
Code: https://github.com/luuuyi/CBAM.PyTorch
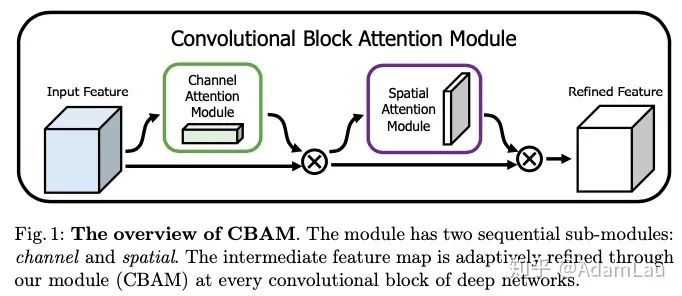
The introduction section of the paper points out three factors that affect the performance of convolutional neural network models: depth, width, and cardinality. It also lists some representative new network structures, such as the depth-related VGG and ResNet series, the width-related GoogLeNet and wide-ResNet series, and the cardinality-related Xception and ResNeXt.
Besides these three factors, there is also a module that can affect network performance: attention—attention mechanisms.
Motivation: Therefore, the article proposes two attention mechanism modules, namely the channel attention module and the spatial attention module. They are connected in a cascade manner. The modules are flexible and can be embedded into ResBlock, etc.
1. Channel Attention Module
The channel attention module mainly explores the relationships between feature maps of different channels. Each channel’s feature map itself acts as a feature detector, and this channel attention module informs the model which parts of the features we should pay more attention to.
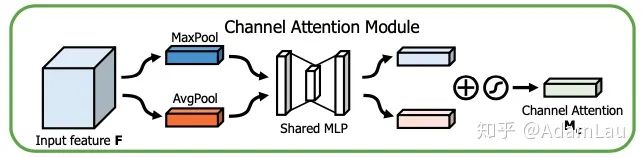
It also aggregates spatial dimension features using average-pooling and max-pooling to produce two spatial dimension descriptors. These are then processed through MLP (fc + Relu + fc) + sigmoid layer (similar to SE-Net, but with an additional max pooling step for the squeeze operation) to generate weights for each channel, which are finally multiplied with the original channel features.
2. Spatial Attention Module
The spatial attention module generates a spatial attention map to utilize the spatial relationships between different feature maps, allowing the model to focus on which spatial positions in the feature maps are important.
How to apply the network to segmentation?
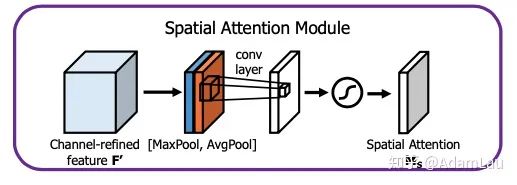
- This time, global MaxPooling and AvgPooling operations are performed on the same pixel values at the same locations across different feature maps, obtaining two spatial attention maps that are concatenated, shaped [2, H, W].
- A 7×7 convolution is then applied to this feature map, followed by a sigmoid function. This results in a spatial matrix with the same dimensions as the language feature map, augmented by the spatial attention weights.
- Finally, the obtained spatial attention matrix is multiplied with the original feature map to produce a new feature map.
3. Experiments
- Comparison of different channel attention methods:

Using max pooling combined with avg pooling yields better results than SENet (which only uses avg pooling).
- Comparison of different spatial attention methods:
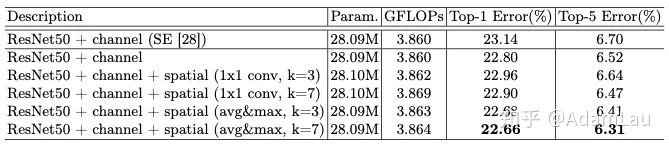
The reason for using a 7×7 convolution kernel is to achieve a larger receptive field, and it is believed that smaller convolution kernels may cause some confusion in the feature maps.
- Combining methods of channel and spatial attention:

Ablation experiments overall.
Dual Attention Network for Scene Segmentation
Paper: https://arxiv.org/pdf/1809.02983.pdf
While context fusion helps capture objects of different scales, it cannot leverage the relationships between objects in the global view. This may easily overlook inconspicuous objects or fail to comprehensively consider the connections and correlations of various positions, resulting in intra-class inconsistencies in segmentation and mis-segmentation. For semantic segmentation, each channel’s map is equivalent to the response of each category, so the inter-channel correlation should also be emphasized.
To address this issue, the Dual Attention Network (DANet) is proposed, based on self-attention mechanisms to capture feature dependency relationships in both spatial and channel dimensions. Specifically, this paper attaches two attention modules to dilated FCN, modeling the semantic dependency relationships in spatial and channel dimensions.
Applied to segmentation, the spatial attention module and the channel attention module are connected in parallel, and the results of the two modules are ultimately combined through elementwise operation. In feature extraction, the author made the following changes to ResNet: canceling the final downsampling and using dilated convolutions to achieve both an enlarged receptive field and maintain high spatial resolution, resulting in the final feature map being enlarged to 1/8 of the original image.
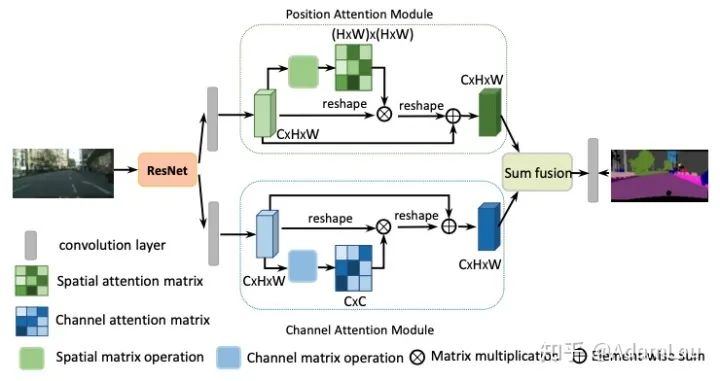
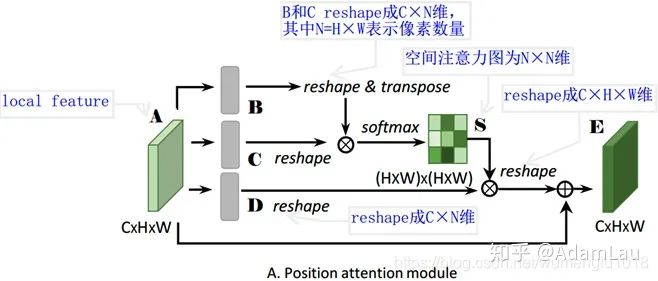
1. Position Attention Module (PAM)
The position attention module aims to utilize the associations between any two feature points to mutually enhance their feature representations.
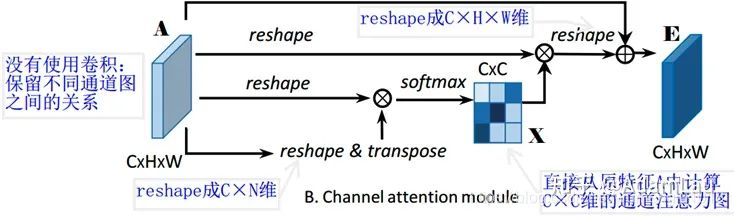
2. Channel Attention Module (CAM)
Each high-level feature’s channel map can be viewed as a class-specific response. By exploring the interdependencies between channel maps, we can highlight the interdependent feature maps and enhance the representation of specific semantics.
To further obtain the feature of global dependencies, the outputs of the two modules are combined through addition to obtain the final feature for pixel classification.
3. Summary
In summary, the main idea of the DANet network is the fusion deformation of CBAM and non-local. It performs spatial-wise self-attention on deep feature maps while also performing channel-wise self-attention, and finally combines the two results through element-wise sum.
In CBAM, the idea of performing spatial and channel self-attention is directly operated using the self-correlation matrix Matmul of non-local, avoiding the complex operations of manually designing pooling and multi-layer perceptrons as in CBAM.
References:
- https://blog.csdn.net/elaine_bao/article/details/80821306
- https://zhuanlan.zhihu.com/p/102984842
- https://zhuanlan.zhihu.com/p/93228308
- https://zhuanlan.zhihu.com/p/106084464
- https://blog.csdn.net/wumenglu1018/article/details/95949039
- https://blog.csdn.net/xh_hit/article/details/88575853
Download 1: OpenCV-Contrib Extension Module Chinese Tutorial Reply in the “Beginner Learning Vision” public account backend: Chinese Tutorial for Extension Modules, to download the first Chinese version of the OpenCV extension module tutorial covering more than twenty chapters including extension module installation, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, etc.Download 2: 52 Lectures on Python Vision Practical Projects Reply in the “Beginner Learning Vision” public account backend: Python Vision Practical Projects, to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, facial recognition, to help quickly learn computer vision.Download 3: 20 Lectures on OpenCV Practical Projects Reply in the “Beginner Learning Vision” public account backend: 20 Lectures on OpenCV Practical Projects, to download 20 practical projects based on OpenCV, achieving advanced learning in OpenCV.
Group Chat
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D Vision, Sensors, Autonomous Driving, Computational Photography, Detection, Segmentation, Recognition, Medical Imaging, GAN, Algorithm Competitions (which will gradually be subdivided later). Please scan the WeChat ID below to join the group, and note: “Nickname + School/Company + Research Direction”, for example: “Zhang San + Shanghai Jiao Tong University + Visual SLAM”. Please follow the format; otherwise, you will not be approved. After successfully adding, you will be invited into the relevant WeChat group based on your research direction. Please do not send advertisements in the group, or you will be removed. Thank you for your understanding~

