

Our group’s recent work DeCo: Decoupling Token Compression from Semantic Abstraction in Multimodal Large Language Models has deeply analyzed the issues with the Q-former structure.

Paper Title:
DeCo: Decoupling Token Compression from Semantic Abstraction in Multimodal Large Language Models
Paper Link:
https://arxiv.org/abs/2405.20985
First, let’s state the viewpoint:
1. Under sufficient training resources, we can choose Linear Projector/MLP in multimodal large language models as a visual-text modality bridge, which is the route of LLaVA. The Linear Projector does not lose visual information, converges quickly in training, and performs well. The only issue is that it leads to a long image token sequence, which can be overcome when training resources like GPUs are sufficient.
2. We want to emphasize that, under limited training resources (limited GPUs, training data, etc.), Q-former is merely an “inefficient” compressor. If we want to reduce the number of image tokens to lower training costs, a simple Adaptive Average Pooling is sufficient.
Our DeCo work found that in terms of reducing image tokens, a simple average pooling performs better than Q-former and converges faster in training. Concurrent work PLLaVA has also demonstrated the advantages of adaptive pooling in experimental results.
The more important question here is “why is simple average pooling better than the Q-former structure?” Below, I will briefly introduce the ideas of DeCo, hoping to inspire everyone from a new perspective.
Design of the Q-former Structure
We need to start with the design of the Q-former structure. Its core is to use a set of predefined, learnable, fixed number (M) of Query tokens to fuse the information from the image encoder through the cross-attention layer. Since the number of Query tokens M is a hyperparameter, we can flexibly set a number smaller than the original image tokens number, thus reducing the image tokens.
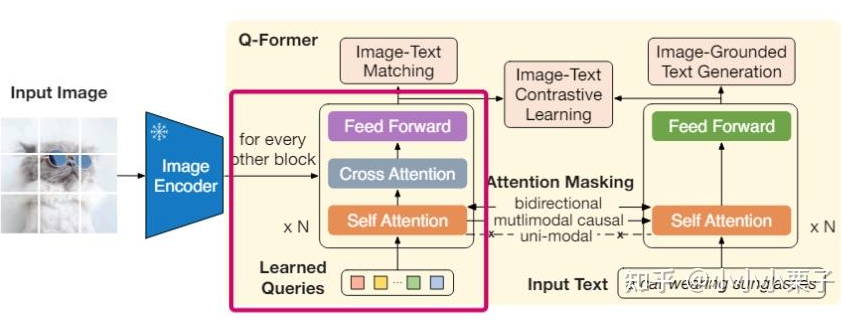
▲ Q-former structure
This design is very similar to a classic work in object detection tasks, DETR. In DETR, this set of query tokens is used to extract object proposals, meaning that the input image features allow the query tokens to extract semantic-level object concepts.
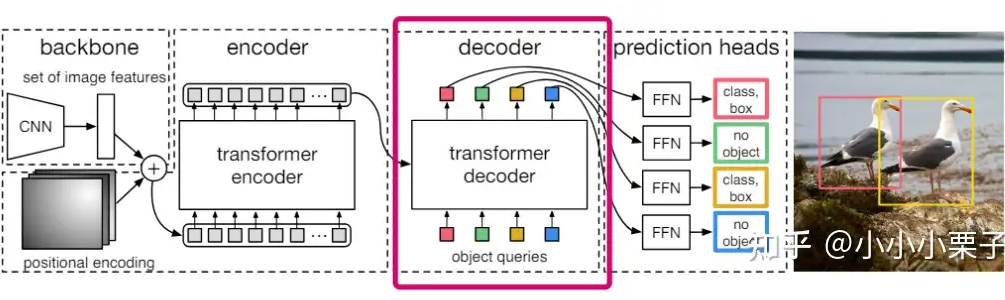
▲ DETR structure
Visualization of the learned query tokens in DETR (from GAE):

▲ Visualization of different queries in DETR
What Does Q-former Learn in MLLM?
Similarly, we can infer that the Q-former in MLLM also reduces the number of image tokens by extracting visual concepts, and the expected output tokens of Q-former should represent a set of visual concepts.
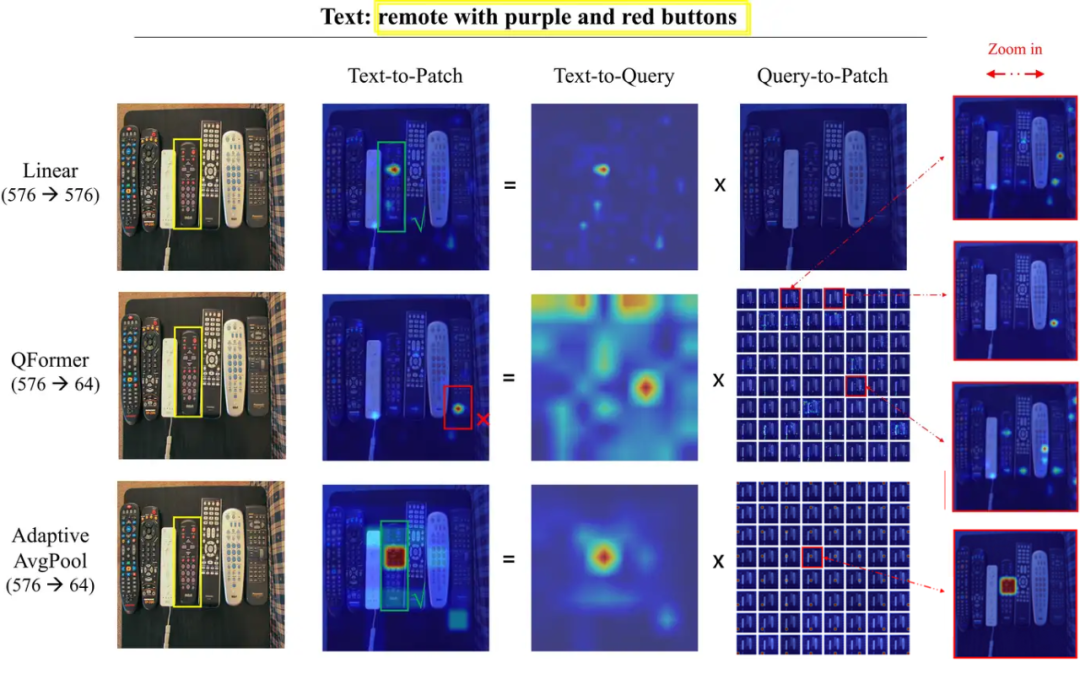
We visualized the outputs of Q-former trained in MLLM in DeCo, confirming that Q-former indeed compresses at the visual semantic level. The following image visualizes the outputs of the trained Q-former in MLLM, highlighting the relevance matrix of each query token relative to the original image patches. We can see that 576 image tokens are compressed into 64 query tokens, with each query token responsible for different visual concepts, including different objects, attributes, and backgrounds.

▲ Visualization of 64 query tokens
Issues with Q-former
Issue 1: As a visual semantic extractor, Q-former is very difficult to learn well. This difficulty is not directly related to its parameter count; for example, using a lightweight 2-layer Q-former is also very hard to learn well. For instance, in our experiments, we replaced the MLP in the identical framework of LLaVA with a lightweight 2-layer Q-former (initialized with parameters from BLIP-2), and the experimental results still showed a significant drop.
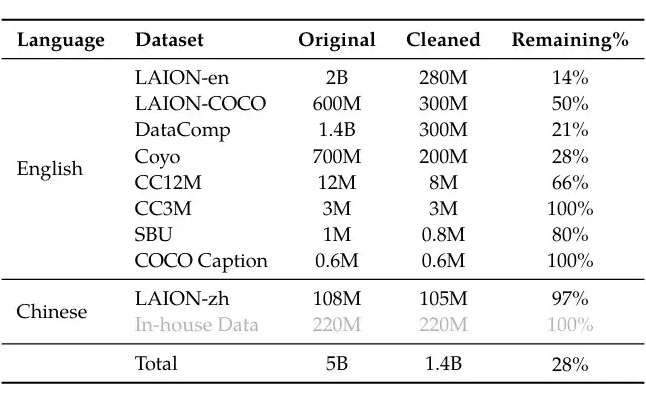
We suspect that the 558K+665K level of data used by LLaVA is insufficient to learn Q-former well, but simply adding CC12M data or other datasets did not improve results either. The process of data allocation, hyperparameter adjustment, and so on greatly increases the difficulty of learning a good MLLM, making it very complex. Considering that the Qwen-VL-Chat series still performs strongly, we do not deny the upper limit of a good Q-former, but it is indeed not straightforward or efficient in training. Here is a chart from the Qwen-VL paper showing the data used:
Issue 2: Due to its difficulty in learning, Q-former can easily become a bottleneck in MLLM, losing important visual information.
For example, through the above visualization of 64 query tokens, the visual concepts learned by the query tokens may be: 1) sparse, containing only limited visual concepts, and 2) redundant, where different query tokens express the same visual concepts, as seen with the red and green boxed query tokens being duplicates. The work by Honeybee also pointed out that the original Q-former structure loses the spatial position information of images, etc. The loss of visual information in Q-former will propagate to the LLM, which is irreversible.

▲ Query tokens boxed with the same color are duplicates. This redundancy appears in different images.
Issue 3: In MLLM, the visual semantic extraction of Q-former is redundant. In the DeCo work, we decoupled the semantic alignment flow between the image and text modalities in MLLM, as shown in the figure below. We found that after multimodal alignment, the LLM itself is a very good visual semantic extractor. Essentially, the features obtained after mapping through a linear layer or MLP layer are still patch-level visual features, not semantic-level ones. The strong performance of models along the LLaVA route also confirms that LLMs can effectively extract visual semantics to generate textual responses.
Therefore, the pre-extraction of visual semantics by Q-former is actually redundant: letting Q-former first perform a visual semantic extraction to obtain visual concepts, and then allowing the LLM to perform another round of semantic extraction based on these visual concepts according to the input text question is quite “roundabout”. Following the idea of “let professionals do professional work,” it is more reasonable to let the powerful LLM handle semantic-level understanding and extraction in MLLM, rather than spending significant effort and cost to learn a good Q-former.
▲ The loss of visual semantics in Q-former propagates to the LLM, leading to errors in the final text-to-patch semantic alignment.
Thus, the core idea of DeCo is: to reduce the number of image tokens, there is no need to use a difficult-to-learn visual semantic extractor like Q-former; a simple downsampling at the patch level can reduce the token count, i.e., Decoupling Token Compression from Semantic Abstraction (DeCo). One of the most common downsampling methods is 2D adaptive pooling.
Compared to Q-former, the benefits of Adaptive pooling are: 1) the pooling operation is parameter-free, and after mapping the visual feature dimensions with an MLP, it converges quickly in training, being concise and efficient without requiring a lot of training data; 2) The 2D operation based on kernel and stride (similar to CNN convolutional kernels) can retain the spatial information of the image. For more details, please refer to our paper.
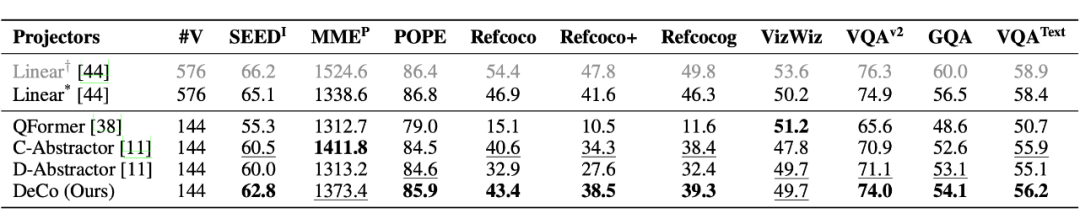
In comparative experiments, we used exactly the same experimental settings and the same compression ratio (576 image tokens -> 144 query tokens). Compared to the original Q-former and the enhanced locality-aware Q-former (i.e., C-Abstractor and D-Abstractor proposed in Honeybee), the DeCo method shows advantages in efficiency and performance.
Other Points Worth Discussing:
The core of DeCo is to discard the Q-former as a semantic compressor and simply downsample at the Patch-level or even at the more primitive pixel-level to reduce the number of image tokens. Its idea is not limited to Average Pooling; we have just demonstrated through analysis and experiments that average pooling is a very good downsampling method.
For image tokens, Q-former compresses at the visual semantic level and may lose semantic information, while adaptive pooling essentially performs a dense downsampling at the patch level, which may lose the original patch information.
At different compression ratios, the information loss of both methods represents a trade-off. In common compression requirements, such as using 144 tokens to represent an image, adaptive pooling performs quite well. At the same time, it has a significant advantage in training efficiency and does not require a large amount of training data. In implementation, you can directly call the PyTorch function torch.nn.AdaptiveAvgPool2d, which is simple and convenient.
Regarding the experimental setup, we mainly trained under relatively limited training resources (LLaVA’s settings), where average pooling performed excellently. When training resources are abundant (more data, more GPUs), referring to the conclusions of MM1, Q-former does not have an advantage over average pooling either.
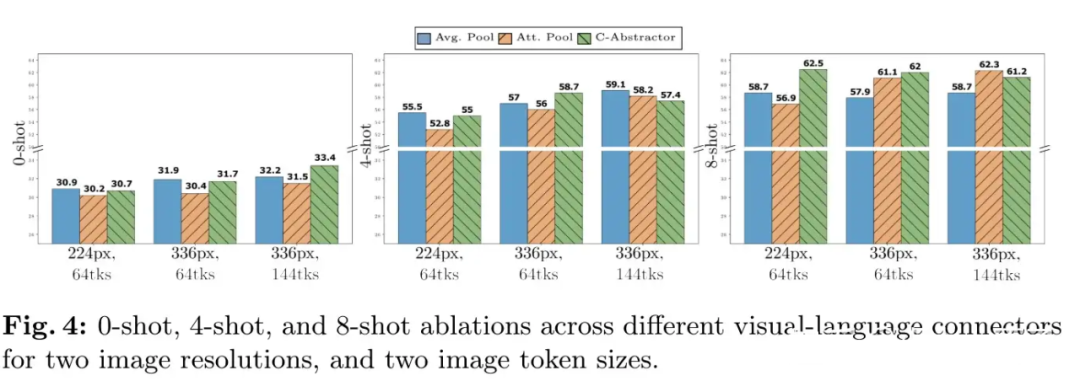
▲ The Att Pool in the figure is the Q-former structure
In video understanding tasks (multiple images) or scenarios with high-resolution images, the sequence of tokens on the visual side will be very long. In this case, using average pooling can significantly reduce the number of tokens compared to MLP. Currently, DeCo and PLLaVA have mainly validated the simplicity and efficiency of average pooling in the spatial dimension, but there has not been sufficient exploration in the temporal dimension.

Scan the QR code to add the assistant on WeChat
About Us
