
In recent years, the Internet of Things (IoT), which has gained significant popularity, can be considered a prototype of ubiquitous computing. Multiple small and inexpensive Internet devices are widely distributed in various places in daily life, serving users through interconnected methods. Computer devices will no longer rely solely on command lines and graphical interfaces for human-computer interaction; they can interact with users in a more natural and invisible manner. This type of user interface is referred to as “Natural User Interface” (NUI). NUI is more of a concept that is considered “natural” relative to graphical user interfaces, advocating that users do not need to learn or use auxiliary devices like mice and keyboards. Microsoft’s gaming control device Kinect has a classic slogan: You are the controller. Humans can intuitively interact with computers through multimodal interaction.
The term “modality” was proposed by German physiologist Helmholtz as a biological concept, referring to the channels through which organisms receive information via sensory organs and experience. For example, humans have visual, auditory, tactile, gustatory, and olfactory modalities. Studies have shown that the proportions of how humans perceive information through these modalities are 83%, 11%, 3.5%, 1.5%, and 1%, respectively. Multimodality refers to the fusion of multiple senses, while multimodal interaction refers to humans communicating with computers through multiple channels, such as sound, body language, information carriers (text, images, audio, video), and the environment, fully simulating the way people interact with each other.

Visual and Auditory
Let’s first look at the visual and auditory aspects of multimodality. The total proportion of information obtained through visual and auditory means is 94%, and they are the two channels currently used in popular GUI (Graphical User Interface) and VUI (Voice User Interface).
1) Dimensions
If asked what the essential difference between vision and hearing is, I believe it lies in the different dimensions of information transmission. The information received by the eyes is determined by four dimensions of time and space; however, the information received by the ears can only be determined by the time dimension (though the ears can perceive the direction and frequency of sound, these factors are not decisive). The eyes can observe space back and forth to acquire information; the ears can only receive information unidirectionally. Without other functional aids, it is impossible to replay information from a few seconds ago.
The time dimension determines the amount of information received; it is unidirectional, linear, and cannot be paused. The amount of information the ears can receive in a short time is very limited. For example, if a person could stop time, sound would not propagate during this static period, and no information would exist. Another notion is that during static time, sound would remain in a current state, such as “tick,” making it just noise to humans.
Information received by the ears is solely determined by time, while the eyes are quite different. Even in a short time, the eyes can acquire a large amount of information from space. The information from space is determined by two factors: 1) dynamic or static; 2) three-dimensional space or two-dimensional plane. In the absence of other reference comparisons, the stillness of an object can simulate the stillness of time, allowing humans to gather information from stationary objects. The combination of time and space can greatly enrich information, as spending one minute observing dynamic objects around provides far more information than spending a year looking at the same static page.
2) Comparison of Information Reception
The amount of information received visually is far greater than that received auditorily. An excellent responder on Zhihu in the field of neuroscience and brain science pointed out that the upper limit of information received by the brain through the eyes is 100Mbps, while the upper limit through the cochlea is 1Mbps. To put it simply, the amount of information received visually can reach 100 times that of auditory reception.
Although the above conclusion has not been officially confirmed, we can make a simple comparison. Within the scope of comprehension, a person can read text at a speed of 500 to 1000 words per minute, while speaking can reach 200 to 300 words per minute. Therefore, visual reading can yield 2 to 5 times more information than auditory reception. When comprehension exceeds the limit, it requires time for reflection, leading to a sharp decline in the amount of information received.
If images are used as information carriers, visual reading of information in images far exceeds auditory reception by 5 times. The eyes also have a unique feature: they can simultaneously see three different places in one second through scanning.
TactileSense
Although the amount of information received through touch is less than that through vision and hearing, it is much more complex than either. Tactile sense refers to the sensations experienced by receptors distributed on the skin in response to external stimuli such as temperature, humidity, pressure, and vibration, which trigger reactions like hot and cold, moist and dry, soft and hard, and movement. We feel various objects through touch and store various data in our brains about what we touch. For instance, in darkness, we can judge what an object is by touch. If we combine vision and see a spherical object but feel edges when touching it, this may conflict with our memory.

In virtual reality, the simultaneous coordination of all five senses is the ultimate goal of technology. Without tactile feedback, the experience feels less real and natural. For example, in fighting games, there is no feedback whether the enemy is hit or if the player is hit, resulting in a lack of realism in the gaming experience. Virtual reality control systems should simulate interactions with the surrounding environment as naturally as possible. Similarly, future human-computer interactions will occur more in physical spaces, where humans want to genuinely feel entities. Augmented reality technology needs to convert virtual digital information into tactile sensations because touch is the only way we can feel entities in a real environment.
In the real world, technology companies hope to simulate various material textures through deformation and vibration, known as virtual haptic technology. Previously, a virtual reality glove called Gloveone appeared on the crowdfunding site Kickstarter. This glove incorporates many small motors that use different frequencies and intensities of vibrations to match visual effects. Similarly, there is a glove called HandsOmni developed by Rice University, which uses small air sacs to simulate touch through inflation and deflation, achieving better results than motors, but it remains in the early stages of development.

Olfaction
In the book “Superordinary Psychology,” it is mentioned that olfaction is the only sense that transmits information without passing through the thalamus, directly sending stimuli to various glands in the brain related to emotions and instinctive responses, such as the amygdala (managing emotions like anger and fear, desires, and hunger), the hippocampus (managing long-term memory and spatial awareness), the hypothalamus (managing sexual desires and impulses, growth hormone and hormone secretion, adrenaline secretion), and the pituitary gland (managing various endocrine hormones and acting as the brain’s commander). Thus, olfaction is the most direct sense capable of evoking instinctive behaviors and emotional memories in humans.

Despite this, there are relatively few startups focusing on olfactory solutions. One such company is FeelReal, which launched a crowdfunding campaign on Kickstarter in 2015. FeelReal introduced the NirvanaHelmet and VR Mask, consisting of a head-mounted display and mask, which can provide richer sensory stimulation, such as scents, water mist, vibrations, wind, and simulated heat, offering users a new sensory experience. So far, the FeelReal team has pre-produced dozens of scents frequently appearing in movies and games, and developed a cartridge that can hold seven different scent generators, set inside the mask. Unfortunately, FeelReal failed to meet its crowdfunding goal on Kickstarter, and the product is still listed as “pre-order” on its official website.
In Hangzhou, there is a company called “Kingdom of Smells” that focuses on digital olfactory technology development. Currently, this company decodes, encodes, transmits, and releases smells, breaking the barriers of time and space to restore the scents of substances according to programmed instructions. It is reported that the Kingdom of Smells has cataloged over 100,000 scents and decoded thousands, including everyday scents from food, flowers, gasoline, and other common odors, as well as unique scents from geographically restricted environments. The decoded scents are placed in a “scent box,” which releases smells in a fitting manner based on the scenario, controlling the proportion, combination effects, and timing through microelectromechanical systems.
After analyzing how humans receive information and the supporting technologies behind it, we will next analyze how humans convey information through sound, body language, and information carriers, and what stage the supporting technologies have reached.
Conveying Information Through Sound
With the development of artificial intelligence, voice recognition technology has rapidly advanced. Chapter 1 has detailed the introduction of voice recognition technology, so it will not be elaborated here. When expressing intentions, humans primarily rely on language, accent, grammar, vocabulary, tone, and speed, and in different scenarios, the user’s tone may change with emotions, causing the same statement to convey different intentions.
Intelligent emotion recognition is key for devices with voice interaction capabilities to respond to users and engage in meaningful conversations. As early as 2012, an Israeli startup called Beyond Verbal invented a series of voice emotion recognition algorithms that can analyze emotions such as anger, anxiety, happiness, or satisfaction based on changes in speaking style and pitch. The algorithm can currently identify 11 categories of 400 complex emotions. In recent years, Amazon’s Alexa team and Apple’s Siri team have also focused on researching voice emotion recognition. Apple’s latest HomePod advertisement, Welcome Home, used a similar approach to express Siri’s intelligent recommendations: after a long day, the female protagonist returns home exhausted and asks Siri to play music on HomePod. Suddenly, magical things happen: music plays, and the protagonist feels empowered, allowing her to open another space and dance freely. The advertisement effectively showcases HomePod’s role as a “switch” for emotional transformation, receiving unanimous praise from the international advertising community.

Machines need to not only understand what users want to express but also identify who is speaking. This is where “voiceprint recognition” in the field of biometrics plays a crucial role. This technology distinguishes a speaker’s identity based on voice parameters reflecting their physiological and behavioral characteristics in the speech waveform. Apple, Amazon, and Google have successively employed voiceprint recognition in their products, effectively determining different users’ voices and responding accordingly.
Voiceprint recognition will become the best identity verification method for voice human-computer interaction, effectively reducing operational processes in certain application scenarios. For example, during the ordering process, if voiceprint recognition is used as the authentication method, saying “Order the same takeout as last night” could complete the entire ordering and payment process. Without voiceprint recognition, the payment stage might still require fingerprint or facial recognition on a smartphone, making it very cumbersome to use.

At the same time, due to the convenience of voice interaction, there may be significant issues in smart home design. For example, if an intruder illegally enters a residence and the voice control system does not restrict the speaker’s identity, anyone would have access to the smart monitoring system. An intruder could easily issue commands to shut down the monitoring system, which is very dangerous. Voiceprint recognition can effectively solve this problem. If the identity of the intruder cannot be recognized, when they attempt to engage in voice interaction, the voice control system should trigger alarms and other security measures to ensure residents’ safety.
Conveying Information Through Body Language
Humans rely heavily on body language during communication. Without body language, communication would be exceedingly difficult and laborious. Body language is a silent language; we can understand a person’s current emotions, attitudes, and character through facial expressions, eye contact, and body movements. American psychologist Edward Hall stated in his book “Silent Language”: “The meanings conveyed by silent language are far more numerous and profound than those conveyed by spoken language, as spoken language often hides most, if not all, of the intended meaning.”
Facial expressions are the primary means of expressing emotions. Most research currently focuses on six main emotions: anger, sadness, surprise, happiness, fear, and disgust. There are many open-source projects for facial expression recognition available online, such as FaceClassification on GitHub, which is based on the Keras CNN model and OpenCV for real-time facial detection and expression classification. When tested with real data, the accuracy of expression recognition only reached 66%, but the results were poor when recognizing expressions like laughter and surprise, which are similar in interpretation for computers. In human-computer interaction, user expression recognition can be used not only to understand users’ emotional feedback but also to manage speaking turns in conversations. For example, if the machine detects a user’s expression suddenly changing to anger, it needs to consider whether the process should continue.

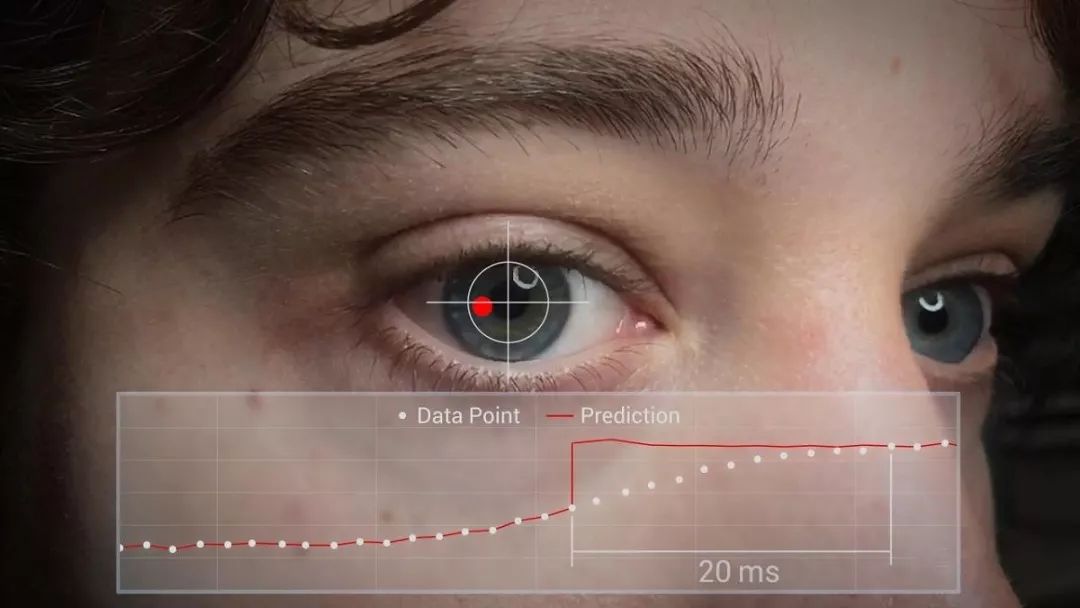
Sometimes, a single glance can convey what a person wants to express, which is why the eyes are referred to as the “windows to the soul.” The eyes are one of the research directions in human-computer interaction. The direction of gaze, duration of gaze, pupil dilation and contraction, and blink frequency all have different interpretations. In 2012, a company called The Eye Tribe, founded by four Danish PhD students, developed eye-tracking technology that can capture images using the front camera of smartphones or tablets and analyze them using computer vision algorithms. The software can locate the position of the eyes, estimate where you are looking on the screen, and even pinpoint very small icons. This eye-tracking technology is expected to replace finger control on tablets or smartphones in the future.
In human-computer interaction, eye-tracking technology will help computers understand where users are looking, optimizing the navigation structure of applications and games, making the entire user interface clearer and more concise. For example, elements like maps and control panels can be hidden when users are not paying attention and only displayed when users glance at the edges, enhancing the immersive experience of the entire game. Oscar Werner, vice president of TobiiPro, a company specializing in eye-tracking technology, believes: “The next generation of PC interaction based on eye-tracking will combine touch screens, mice, voice control, and keyboards, significantly improving the efficiency and intuitiveness of computer operations. Gaze precedes any physical action. Based on eye tracking, more “intelligent” user interaction methods will surely emerge.” For VR devices centered on immersive experiences, eye-tracking technology is key to the next generation of VR headsets. The aforementioned The Eye Tribe has already been acquired by Facebook, and this technology will be utilized in Oculus.
Body movements involve interdisciplinary research across cognitive science, psychology, neuroscience, brain science, and behavioral science. Many details are included, and even the position of each finger can convey different information, making it challenging for computers to understand human body movements.
In body recognition, the most famous example is Microsoft’s 3D motion-sensing camera, Kinect, which features instant dynamic capture, image recognition, microphone input, and voice recognition. Kinect does not require any controllers; it can capture players’ movements in three-dimensional space using just a camera. Unfortunately, Microsoft confirmed in 2017 that it would stop producing new Kinect sensors.

Gesture recognition has two excellent hardware products. One is the well-known Leap Motion, which can track users’ ten fingers with 0.01mm precision in a 150° field of view, allowing your hands to move freely in virtual space as they would in the real world. The other is the MYO armband, which detects the bioelectric changes in muscles when users move their arms, monitoring gestures by combining physical actions. MYO is highly sensitive; for instance, the action of making a fist can be detected even without exerting force. Sometimes, you might feel that your fingers have not yet started to move, but MYO has already sensed it. This is because MYO detects the bioelectric signals generated by the brain controlling muscle movements before your fingers begin to move.


Professor Yaser Sheikh from Carnegie Mellon University’s Robotics Institute leads a team developing a computer system that can read body language from head to toe, capable of real-time tracking and recognizing multiple actions and gestures in large crowds, including facial expressions and hand gestures, even the movements of each person’s fingers. In June and July 2017, this project open-sourced the core facial and hand recognition source code on GitHub, named OpenPose. The open-sourcing of OpenPose has attracted thousands of users to participate in its improvement. Anyone can use it to build their own body tracking system as long as it is not for commercial purposes. Body language recognition opens up new ways for human-computer interaction, but the overall understanding of body language remains complex, and how computers can semanticize and understand body language is still a technical bottleneck.

Conveying Information Through Information Carriers
In addition to on-site communication, humans also communicate through four media: text, images, audio, and video, all of which carry unstructured data that is difficult for computers to understand. At the 2018 Baidu AI Developer Conference, Baidu Senior Vice President Wang Haifeng announced Baidu Brain 3.0 and stated that its core is “multimodal deep semantic understanding,” encompassing the semantics of data, knowledge, and understanding of images, videos, sounds, and speech. Visual semanticization enables machines to move from seeing to understanding images and videos, recognizing people, objects, and scenes while capturing their behaviors and relationships. By extracting structured semantic knowledge in a time-ordered, digital, and structured manner, it ultimately combines with fields and scenarios for intelligent reasoning and application in industry. In human-computer interaction, computers understanding unstructured data helps them comprehend users, thereby optimizing personalized recommendations and human-computer interaction processes, enhancing the overall efficiency and experience of products.
Conclusion
In summary, current computer devices can adequately see users’ body movements and hear their language, but they still cannot comprehend or understand the underlying semantics. When interactions occur in three-dimensional physical spaces, the context can dynamically change based on the task and its background, leading to the same input having different semantics. In the short term, weak artificial intelligence cannot effectively address “semantics,” and “semantics” will become an unavoidable topic in the field of human-computer interaction in the coming years. Designers need to learn how to better weigh and handle “semantics” in the presence of artificial intelligence.


Year-End Procurement Season Promotions, How Data Can Assist Product Design?丨Sharing from JD Cloud Design Team
Xiaomi Design Director Nandil:Using Xiao Ai Speaker to Demonstrate the Core of Smart Product Experience Chain
