Skip to content
⌈ Medical Bioinformatics ⌋ is a public account operated by the “Medical Genetics and Bioinformatics Research Group” at Central South University. The research group develops new tools, platforms, and databases for accurately interpreting gene variations and identifying candidate genes using bioinformatics, artificial intelligence, deep learning, etc., applying them to neuropsychiatric diseases represented by autism and Parkinson’s disease, exploring the essential laws and mechanisms of disease occurrence and development, providing scientific basis for precise prevention and treatment. At Medical Bioinformatics, we share group meeting papers, bioinformatics technologies, or insights weekly, and you can subscribe to any collection you are interested in. Additionally, you can also subscribe to our team’s published representative papers and the analysis tools and databases we developed that integrate disease phenotype data with genetic information. Our research group is continuously recruiting research assistants, postdoctoral researchers, technicians, and full-time researchers in the fields of bioinformatics, computer science, medical genetics, and biostatistics, and we also welcome outstanding undergraduates with relevant backgrounds to pursue graduate degrees in our research group. We look forward to your joining!
DNA is a helical structure composed of four bases, with four different bases forming stable base pairs. They are referred to by the first letters of their English names: A (ADENINE), T (THYMINE), G (GUANINE), and C (CYTOSINE).
More and more work is utilizing deep learning to classify or regress DNA sequences, but how can we encode DNA sequences into a vectorized input for deep learning? In other words, how do we convert a DNA “string” composed of A, C, G, T into the vector (matrix) format required by deep learning?
One-Hot Encoding
Each base (Adenine A, Cytosine C, Guanine G, Thymine T) is encoded into a fixed-length binary vector, where only one element is 1, indicating the presence of the base, and all other elements are 0.
For example, A can be encoded as [1, 0, 0, 0], C can be encoded as [0, 1, 0, 0], and so on:
A: [1, 0, 0, 0] C: [0, 1, 0, 0] G: [0, 0, 1, 0] T: [0, 0, 0, 1]
Thus, a DNA sequence of length L can be transformed into a 4*L matrix.
However, in most cases, the lengths of the DNA sequences participating in training are different; yet deep learning models require consistent matrix sizes as input. If the length differences are not significant, the cutting & padding method can be used; if the length differences are large, one-hot encoding may not be suitable.
K-mer Encoding
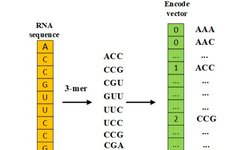
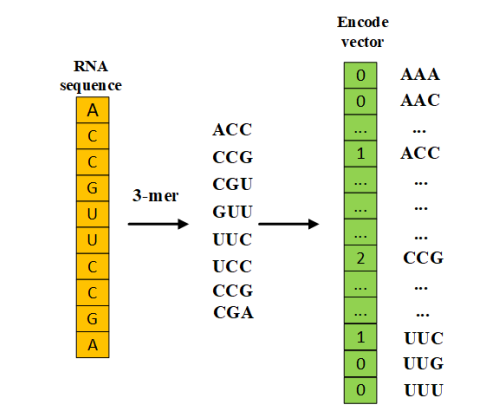
A k-mer refers to the iterative division of reads into sequences containing K bases. Generally, a read of length L can be divided into L-K+1 k-mers. For example, the sequence “ATCGAAATG” of length 9 can be split using the 3-mer method, resulting in ATC, TCG, CGA, GAA, AAA, AAT, ATG, a total of 9-3+1=7 k-mers.
After obtaining the number or frequency of k-mers, the variable-length DNA sequence can be mapped to a fixed-dimensional vector. For instance, for the above sequence, using 3-mer segmentation, the total number of 3-mers is 4 cubed, which is 64. A 64-dimensional vector can be used to record the frequency, count, etc., of each k-mer.
The k-mer feature encoding method loses the original order, positional information of the DNA sequence, and the interactions between k-mers.
Figure 1: K-mer Encoding Method (3-mer)
2.1 K-mer Encoding – Improved – Subsequence Embedding Method
In a paper published in Briefings In Bioinformatics titled DeepLncLoc: a deep learning framework for long non-coding RNA subcellular localization prediction based on subsequence embedding, a subsequence embedding representation method was proposed:
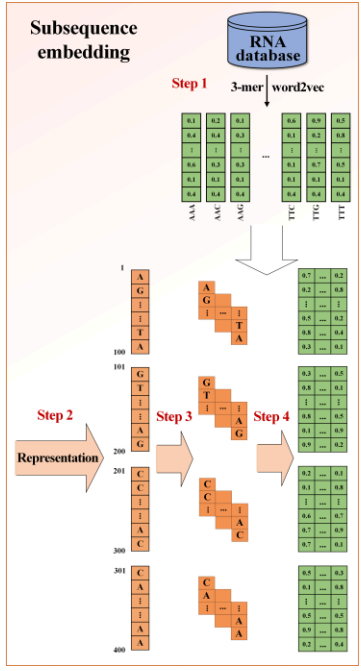
The main idea of this method is to split lncRNA sequences into several contiguous subsequences without overlap, then extract the patterns of each subsequence; finally, combine these patterns to obtain the complete representation of the lncRNA sequence. This can maintain the sequential information.
1. Use the gensim library to learn the k-mer representation vectors of all lncRNA sequences in the database.
2. For a given lncRNA, divide it into m subsequences, each of length L.
3. According to the k value in step 1, encode each subsequence using k-mer features.
4. Find the pre-trained vector for each k-mer, then combine these vectors into a matrix as the representation of the subsequence.
2.2 K-mer Encoding – Improved – GP-GCN Framework (Sequence Graph Model)
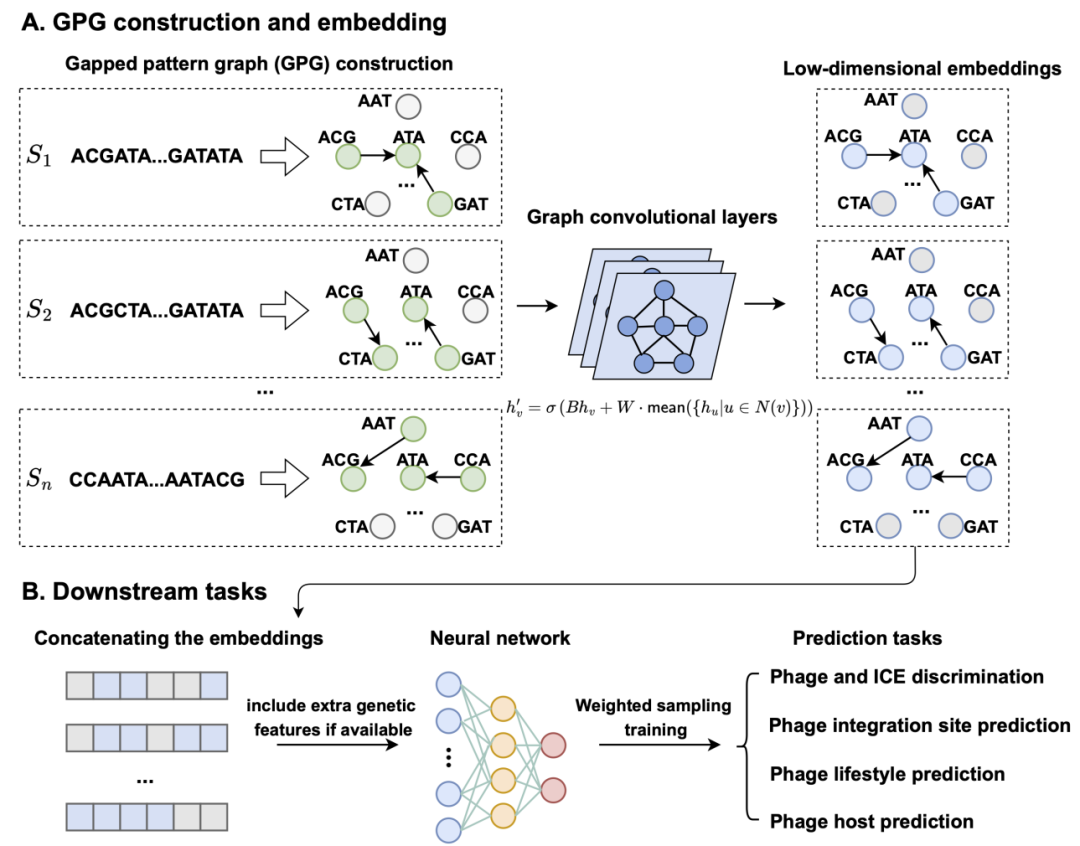
GP-GCN encodes DNA sequences into a graph model:
① For a DNA sequence S, it can be transformed into a graph. The nodes of the graph correspond to k-mers, and the edges correspond to the interactions between k-mers. The features of the nodes are the frequencies of the k-mers; the features of the edges are the frequencies of the two k-mers appearing together.
② Graph embedding uses graph convolutional networks for message passing, aggregating the information of k-mers through the information preserved on the edges.
③ Next, all k-mer embeddings are combined, connected to a regular fully connected layer (it can also be reduced dimensionally using a convolutional neural network), forming a complete neural network for downstream analysis.
Embedding Representation of DNA Sequences (Word2Vec → DNA2Vec)
Word2Vec is a type of language model used to generate word vectors and is widely applied in natural language processing. Patrick Ng from Cornell University developed the dna2vec software, which is based on Word2Vec. Unlike other methods that apply Word2Vec to DNA sequences, dna2vec generalizes variable-length k, using human genome sequences as the learning corpus to embed k-mers into a 100-dimensional continuous vector space.
The training of dna2vec includes four stages:
(1) Separating genes into long, non-overlapping DNA segments;
(2) Transforming long DNA segments into overlapping variable-length k-mers;
(3) Using a double-layer neural network to conduct unsupervised training on the aggregated embedding model;
(4) Decomposing the aggregated model by k-mer length.
Specific Implementation Method of dna2vec:
Given a DNA sequence S, by sliding a window of length k over S, the sequence S is transformed into overlapping fixed-length k-mers. For example, TAGACTGTC is transformed into 5 k-mers: {TAGAC, AGACT, GACTG, ACTGT, CTGTC}.
In the case of variable length, dna2vec samples k from a discrete uniform distribution uniform (klow, khigh) to determine the size of each window. For example, k∈{3,4,5} k-mers can be sampled as {TAGA, AGA, GACT, ACT, CTGTC}.
Given a DNA sequence S of length n, S=(S1,S2,S3,…,Sn), Si∈{A,G,C,T}, S is transformed into n ̃ k-mers (n ̃=n−k_high+1):
f(S)=(S_1:k_1,S_2:2+k_2,…,S_n ̃:n ̃+k_n ̃)
Where, k_i~Uniform(k_low,k_high), S_a:b represents (S_a,…,S_b)
Figure 2: Variable Length K-mer Sequence Segmentation
3.1 Practical Applications of dna2vec
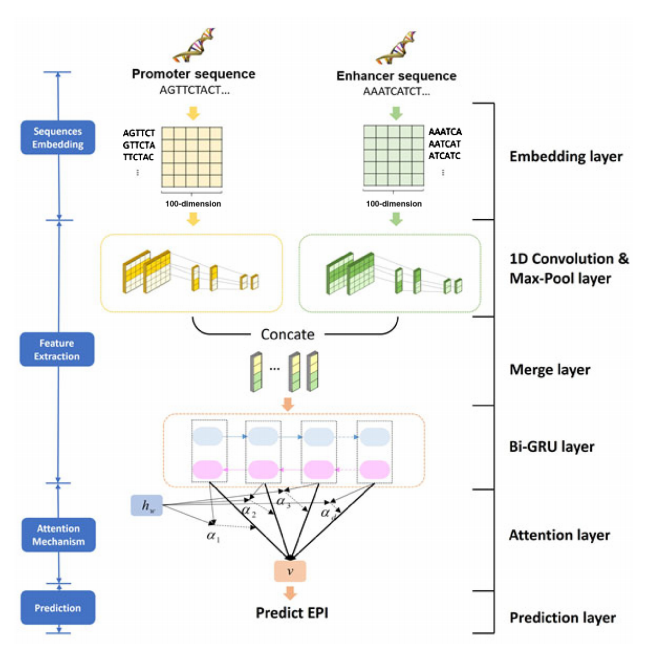
In 2020, a paper published in Briefings In Bioinformatics titled Identifying enhancer–promoter interactions with neural network based on pre-trained DNA vectors and attention mechanism adopted the dna2vec encoding method, using pre-trained DNA vectors from the human genome to encode enhancers and promoters, establishing a universal model with transferability that can predict interactions between enhancers and promoters in various cell lines.
Conclusion
The combination of DNA sequences with neural networks for prediction or regression tasks is currently a popular research direction. There are various methods for vectorizing or matricizing DNA sequences, and different representation methods should be adopted for different task types, considering multiple factors:
① Local features and global features: Some tasks may require capturing local features in the sequence, such as domains or motifs, while others may need to consider global features, such as information from the entire coding region.
② Data types: Genomic data, protein-coding sequences, transcriptome data, etc., different lengths and types of DNA data may require different representation methods.
If you like us, don’t forget to follow us. In addition to sharing records of JC Lab activities, we will also share more useful content in the future. Remember to click ⌈ Like ⌋ and ⌈ View ⌋!
Editor-in-Chief | Li Jincheng
Reviewed by | Xiong Jiayi
Master’s student in Computer Technology, Class of 2022, School of Information Science and Engineering, Hunan University
Focus on automated interpretation of gene variations in gene deep learning
Click ⌈ Read Original ⌋ to visit the research group’s official website